
MySQL索引及sql优化
一、MySQL Binlog日志
Binlog是记录所有数据库表结构变更以及表数据修改的二进制日志,不会记录SELECT和SHOW这类操作。Binlog日志是以事件形式记录,还包含语句所执行的消耗时间。开启Binlog日志有以下两个最重要的使用场景。
主从复制:在主库中开启Binlog功能,这样主库就可以把Binlog传递给从库,从库拿到Binlog后实现数据恢复达到主从数据一致性。
数据恢复:通过mysqlbinlog工具来恢复数据。
Binlog文件操作:
Binlog状态查看
show variables like 'log_bin';
使用show binlog events命令
show binary logs; //等价于show master logs; show master status; show binlog events; show binlog events in 'mysqlbinlog.000001';
使用mysqlbinlog 命令
mysqlbinlog "文件名" mysqlbinlog "文件名" > "test.sql"
使用 binlog 恢复数据,mysqldump:定期全部备份数据库数据。mysqlbinlog可以做增量备份和恢复操作。
//按指定时间恢复 mysqlbinlog --start-datetime="2020-04-25 18:00:00" --stopdatetime=" 2020-04-26 00:00:00" mysqlbinlog.000002 | mysql -uroot -p1234 //按事件位置号恢复 mysqlbinlog --start-position=154 --stop-position=957 mysqlbinlog.000002 | mysql -uroot -p1234
二、MySQL索引原理
2.1 索引分类
普通索引:普通字段建立的索引,没有任何限制。
CREATE INDEX <索引的名字> ON tablename (字段名);
ALTER TABLE tablename ADD INDEX [索引的名字] (字段名);
CREATE TABLE tablename ( [...], INDEX [索引的名字] (字段名) );
唯一索引:索引字段的值必须唯一,但允许有空值 。在创建或修改表时追加唯一约束,就会自动创建对应的唯一索引。
CREATE UNIQUE INDEX <索引的名字> ON tablename (字段名);
ALTER TABLE tablename ADD UNIQUE INDEX [索引的名字] (字段名);
CREATE TABLE tablename ( [...], UNIQUE [索引的名字] (字段名) ;
主键索引:特殊的唯一索引,不允许有空值。在创建或修改表时追加主键约束即可,每个表只能有一个主键。
CREATE TABLE tablename ( [...], PRIMARY KEY (字段名) );
ALTER TABLE tablename ADD PRIMARY KEY (字段名);
复合索引:在多个列上建立索引,这种索引叫做组复合索引(组合索引)。
CREATE INDEX <索引的名字> ON tablename (字段名1,字段名2...);
ALTER TABLE tablename ADD INDEX [索引的名字] (字段名1,字段名2...);
CREATE TABLE tablename ( [...], INDEX [索引的名字] (字段名1,字段名2...) );
聚集索引:B+Tree的叶子节点存放主键索引值和行记录就属于聚集索引;如果索引值和行记录分开存放就属于非聚集索引。聚集索引索引项的顺序与表中记录的物理顺序保持一致,一张表最多建立一个聚集索引,因为真实的物理顺序只能有一种。
全文索引:查询操作在数据量比较少时,可以使用like模糊查询,但是对于大量的文本数据检索,效率很低。如果使用全文索引,查询速度会比like快很多倍。
CREATE FULLTEXT INDEX <索引的名字> ON tablename (字段名);
ALTER TABLE tablename ADD FULLTEXT [索引的名字] (字段名);
CREATE TABLE tablename ( [...], FULLTEXT KEY [索引的名字] (字段名) ;
全文索引语法
select * from user where match(name) against('aaa');
全文索引使用注意事项:1)全文索引必须在字符串、文本字段上建立。2)全文索引字段值必须在最小字符和最大字符之间的才会有效。(innodb:3-84;myisam:4-84)3)全文索引字段值要进行切词处理,按syntax字符进行切割,例如b+aaa,切分成b和aaa 4)全文索引匹配查询,默认使用的是等值匹配,例如a匹配a,不会匹配ab,ac。如果想匹配可以在布尔模式下搜索a*。
select * from user where match(name) against('a*' in boolean mode);
2.2 索引原理
索引是物理数据页存储,在数据文件中(InnoDB,ibd文件),利用数据页(page)存储。索引可以加快检索速度,但是同时也会降低增删改操作速度,索引维护需要代价。
B+Tree结构:1)非叶子节点不存储data数据,只存储索引值,这样便于存储更多的索引值 2)叶子节点包含了所有的索引值和data数据 3)叶子节点用指针连接,提高区间的访问性能
2.3 索引分析与优化
MySQL 提供了一个 EXPLAIN 命令,它可以对 SELECT 语句进行分析,并输出 SELECT 执行的详细信息,供开发人员有针对性的优
EXPLAIN SELECT * from user WHERE id < 3;
select_type: ①SIMPLE表示查询语句不包含子查询或union ②PRIMARY表示此查询是最外层的查询 ③UNION表示此查询是UNION的第二个或后续的查询 ④DEPENDENT UNION UNION中的第二个或后续的查询语句,使用了外面查询结果 ⑤UNION RESULT UNION的结果 ⑥SUBQUERY:SELECT子查询语句 ⑦DEPENDENT SUBQUERY:SELECT子查询语句依赖外层查询的结果。
type:效率依次越来越强。①ALL:表示全表扫描,性能最差 ②index:表示基于索引的全表扫描,先扫描索引再扫描全表数据 ③range表示使用索引范围查询。使用>、>=、<、<=、in等等 ④ref表示使用非唯一索引进行单值查询 ⑤eq_ref一般情况下出现在多表join查询,表示前面表的每一个记录,都只能匹配后面表的一行结果。⑥const表示使用主键或唯一索引做等值查询,常量查询 ⑦NULL:表示不用访问表,速度最快。
possible_keys: 表示查询时能够使用到的索引。注意并不一定会真正使用,显示的是索引名称。
key:表示查询时真正使用到的索引,显示的是索引名称。
rows:MySQL查询优化器会根据统计信息,估算SQL要查询到结果需要扫描多少行记录。原则上rows是越少效率越高,可以直观的了解到SQL效率高低。
Extra:①Using where表示查询需要通过索引回表查询 ②Using index表示查询需要通过索引,索引就可以满足所需数据。③Using filesort表示查询出来的结果需要额外排序,数据量小在内存,大的话在磁盘,因此有Using filesort建议优化。④Using temprorary查询使用到了临时表,一般出现于去重、分组等操作。
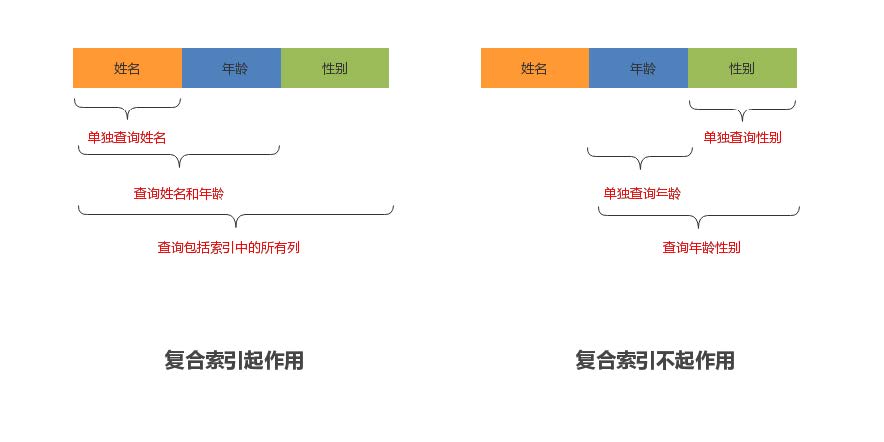
2.4 最左前缀原则
复合索引使用时遵循最左前缀原则,最左前缀顾名思义,就是最左优先,即查询中使用到最左边的列,那么查询就会使用到索引,如果从索引的第二列开始查找,索引将失效。
2.5 LIKE查询
MySQL在使用Like模糊查询时,索引是可以被使用的,只有把%字符写在后面才会使用到索引。
2.6 NULL查询
含有NULL的列上可以使用索引。对MySQL来说,NULL是一个特殊的值,不能使用=,<,>这样的运算符,对NULL做算术运算的结果都是NULL,count时不会包括NULL行等,NULL比空字符串需要更多的存储空间等。最好设置NOT NULL,并给一个默认值,比如0和 ‘’ 空字符串等, where语句尽量避免null值判断,可能会导致全表扫描。
2.7 索引与排序
Explain分析SQL,结果中Extra属性显示Using filesort,表示使用了filesort排序方式,需要优化。如果Extra属性显示Using index时,表示覆盖索引,效率较高。
分析样例:
ORDER BY 子句索引列组合满足索引最左前缀, 效率高。
explain select id from user order by id; //对应(id)、(id,name)索引有效
WHERE子句+ORDER BY子句索引列组合满足索引最左前缀, 效率高。
explain select id from user where age=18 order by name; //对应(age,name)索引
对索引列同时使用了ASC和DESC, 效率低。
explain select id from user order by age asc,name desc; //对应(age,name)索引
WHERE子句和ORDER BY子句满足最左前缀,但where子句使用了范围查询(例如>、<、in等), 效率低。
explain select id from user where age>10 order by name; //对应(age,name)索引
ORDER BY或者WHERE+ORDER BY索引列没有满足索引最左前缀, 效率低。
explain select id from user order by name; //对应(age,name)索引
使用了不同的索引,MySQL每次只采用一个索引,ORDER BY涉及了两个索引, 效率低。
explain select id from user order by name,age; //对应(name)、(age)两个索引
WHERE子句与ORDER BY子句,使用了不同的索引, 效率低。
explain select id from user where name='tom' order by age; //对应(name)、(age)索引
WHERE子句或者ORDER BY子句中索引列使用了表达式,包括函数表达式
explain select id from user order by abs(age); //对应(age)索引
三、慢查询优化
运行如下命令查看慢查询日志信息
perl mysqldumpslow.pl -t 5 -s at C:\ProgramData\MySQL\Data\OAK-slow.log
3.1 添加索引
select * from student where age=18 and name like '张%'; (全表扫描),效率低。
优化后: alter table student add index(age,name); //追加age,name索引, 效率高。
常见加索引的字段:where 字段、组合索引(最左前缀), on 俩边, 排序, 分组统计。
3.2 分页查询优化
select * from user limit 10000,100; 从数据库第一条记录开始扫描,越往后查询越慢,效率低。
优化后:select * from user where id>= (select id from user limit 10000,1) limit 100; 使用了id做主键比较(id>=),并且子查询使用了覆盖索引进行优化。
3.3 SELECT指明字段
SELECT * 增加很多不必要的消耗;减少了使用覆盖索引的可能性;
3.4 不用or 用 union
or 只有所有的字段都有索引才会走索引, 改为union all有索引的字段查询效率高。能用union all 不要用union。
select * from user where name = 'brook' or userid= '10064' 只有userid有索引不会走索引
优化后: select * from user where name = 'brook' union all select * from user where userid= '10064' userid索引会生效
3.5 in 和 exists
exists那么外层表为驱动表先被访问,如果是in, 那么先执行子查询。所以in适合外表大内表小的情况。Exists适合于外表小内表大的情况。利用小表驱动大表, 连接次数会以小表为准。 in 操作能避免则避免,in后边的元素控制在1000个以内。如果是连续的数值可以用between and。
3.6 不要在where子句中的"="左边进行函数、算术运算或其他表达式运算,否则系统将可能无法使用索引
select id from user where score/2=100 应该为:select id from user where score = 100*2
3.7 不使用count(列名), 使用count(*)。count(*)会统计为NULL的行, 而count(列名)不会统计此列为NULL值的行。
3.8 分页代码查询逻辑时,若count为0直接返回,避免执行后面的分页语句。尽量避免向客户端返回大量数据,如数据太大,需考虑业务是否合理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号