

你应该懂的AI大模型(十一)之 LoRA
LoRA 是什么
传统的大模型微调往往需要更新全部模型参数,这不仅消耗海量计算资源,还容易陷入过拟合陷阱。LoRA 另辟蹊径,采用 “低秩分解” 策略,在不改动原始模型权重的前提下,通过添加两个低秩矩阵(A 和 B)构建参数更新层。在训练过程中,仅对这两个低秩矩阵进行优化,使得可训练参数数量相比全量微调减少 99% 以上。例如,在 130 亿参数的 LLaMA 模型中应用 LoRA,新增可训练参数仅约 100 万,大幅降低了训练成本与部署门槛。
LoRA 的工作原理:低秩矩阵
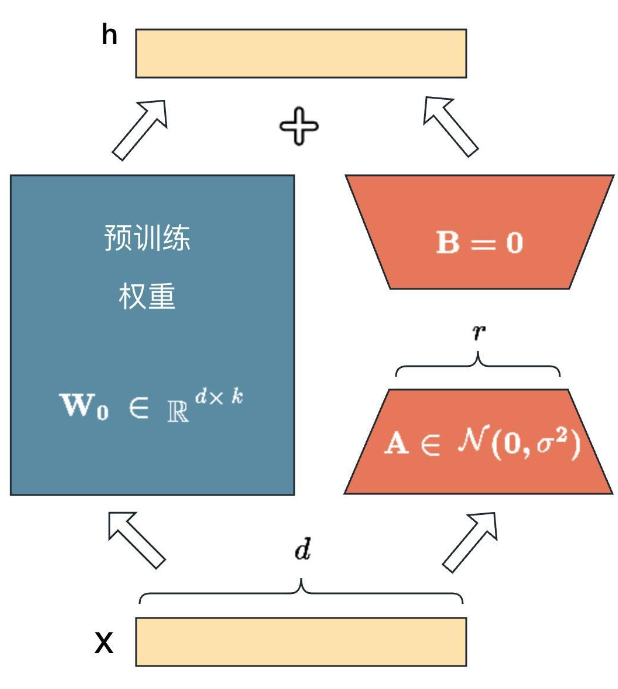
从技术实现角度看,LoRA 通过数学变换实现参数高效更新。假设预训练模型的权重矩阵为W∈Rd×k,LoRA 引入两个低秩矩阵A∈Rd×r和B∈Rr×k(其中r≪d,k),将权重更新量ΔW表示为ΔW=AB。训练时,冻结原始权重矩阵W,仅对 A 和 B 进行梯度更新;推理阶段,将更新后的ΔW与原始权重W合并(Wnew=W+ΔW),实现模型的快速适配。这种设计巧妙地在保持模型表达能力的同时,将计算复杂度降低至原来的min(d,k)r 。
LoRA 能做什么
-
垂直领域深度定制:在医疗、金融等专业领域,通过 LoRA 微调可使通用模型精准回答专业问题。例如,某三甲医院基于 LLaMA 模型训练医疗咨询 LoRA,仅用 2 万条病历数据,就实现了 90% 以上的常见病症问答准确率。
-
个性化内容生成:支持根据个人写作风格、业务话术进行模型定制。某电商平台利用 LoRA 训练商品推荐话术模型,使客服机器人回复转化率提升 35%。
-
多任务快速切换:基于同一基础模型,可训练多个 LoRA 模块应对不同任务。如新闻平台同时部署情感分析、事件分类、摘要生成三个 LoRA 模块,通过动态加载实现任务秒级切换。
LoRA 与 LLamaFactory
LLamaFactory 作为一站式大模型开发平台,将 LoRA 技术进行了深度集成与可视化封装。用户无需编写复杂代码,通过图形化界面即可完成 LoRA 微调全流程操作。平台内置的智能调优算法,可根据数据集特征自动推荐参数组合,使非专业开发者也能轻松训练出高性能模型。同时,LLamaFactory 提供的多场景模板(如客服、写作、翻译),进一步降低了 LoRA 的使用门槛。
在 LLamaFactory 中使用 LoRA
- 前期准备
-
数据准备:按平台要求整理数据集(支持 JSON/CSV 格式),确保数据标注规范。例如,训练法律问答模型时,需收集合同条款解读、法律案例分析等文本数据。
-
模型选择:在模型库中选择合适的 LLaMA 基础版本(7B/13B/30B),建议根据任务复杂度和计算资源进行选择。
- 创建微调任务
-
在 “模型训练” 模块选择 “LoRA 微调” 模式,上传数据集。
-
配置核心参数:设置学习率(推荐初始值1e−4)、训练轮数(小型数据集建议 5-10 轮)、批量大小(16-32)等。
- 训练与监控
-
点击 “启动训练” 后,通过实时仪表盘查看训练进度、损失曲线等指标。
-
若发现损失值波动异常,可使用平台提供的 “动态调参” 功能,实时调整学习率等参数。
- 模型评估与部署
-
训练完成后,利用平台内置的评估工具(准确率、BLEU 值等)进行效果验证。
-
一键部署至生产环境,支持 API 调用、Web 服务等多种集成方式。
为什么 LoRA 之后的模型需要做导出
-
方便存储与管理:在 LLamaFactory 平台完成 LoRA 微调的模型,若不导出,仅以项目形式存在于平台内。将模型导出为特定格式(如 Hugging Face 的模型格式),可以将其存储在本地服务器、云存储等位置,便于长期保存和统一管理。企业或开发者可能会针对不同业务场景训练多个 LoRA 模型,导出后可建立清晰的模型库,方便后续查找、复用和版本管理。
-
支持跨平台迁移:LLamaFactory 只是众多大模型开发平台之一,实际应用中,模型可能需要在不同的环境、框架或平台中使用。例如,企业可能将在 LLamaFactory 训练的模型迁移到自己搭建的生产服务器上,或者集成到其他第三方应用系统中。通过导出,模型可以脱离原平台的限制,在其他支持相应模型格式的环境中继续使用,实现跨平台部署和应用。
-
实现部署应用:导出后的模型是进行实际部署应用的前提。无论是部署到线上服务器,为用户提供智能问答、内容生成等服务,还是嵌入到移动应用、智能设备中,都需要先将模型导出为可被部署环境识别的格式。以聊天机器人为例,只有将 LoRA 微调后的模型导出,才能将其部署到聊天服务的后端服务器,与前端界面交互,真正为用户提供服务。
-
促进协作与共享:在团队协作开发项目中,模型导出便于团队成员之间共享成果。不同成员可能负责不同环节的工作,如数据标注、模型训练、部署运维等,通过导出模型,训练人员可以将成果分享给部署人员;在开源社区,开发者将 LoRA 微调后的模型导出并开源,能让其他开发者基于此进行二次开发,促进技术交流与创新。
LLamaFactory 中的 LoRA 参数详解

-
LoRA 秩 (Rank)
- 含义:LoRA 用两个低秩矩阵 (A 和 B) 来近似权重更新,秩就是这两个矩阵的秩 (r)。
- 作用:秩越小,可训练参数越少,计算开销越低;秩越大,模型表达能力越强,但参数量和计算量也会增加。
- 推荐值:常用值为 4、8、16,可根据模型大小和任务调整。
-
LoRA 缩放系数 (Alpha)
- 含义:缩放系数用于调整 LoRA 权重更新的幅度,公式为:ΔW = (A・B)/α。
- 作用:控制 LoRA 模块对原始模型的影响程度。较大的 alpha 使 LoRA 贡献更大,较小的 alpha 使微调更保守。
- 推荐值:通常与秩相同或为其倍数,如 8、16。
-
LoRA 随机丢弃 (Dropout)
- 含义:训练时随机丢弃一部分 LoRA 连接,防止过拟合。
- 作用:提高模型泛化能力,减少对特定特征的依赖。
- 推荐值:0.0 - 0.1,常用 0.05。
-
LoRA+ 学习率比例
- 含义:LoRA 参数的学习率与基础模型学习率的比例。
- 作用:LoRA 参数通常需要比基础模型更高的学习率,例如设为 10 表示 LoRA 学习率是基础学习率的 10 倍。
- 推荐值:5-20,根据具体任务调整。
-
使用 RSLoRA
- 含义:RSLoRA (Random Scale LoRA) 在训练时随机缩放 LoRA 权重,是对 LoRA 的改进。
- 作用:增强训练稳定性,提高微调效果,尤其在小数据集上表现更好。
-
使用 DoRA
- 含义:DoRA (Dynamic LoRA) 动态调整 LoRA 矩阵的秩,在训练过程中自适应改变模型容量。
- 作用:在保持低计算成本的同时,提高模型性能,特别适合资源受限的场景。
-
使用 PiSSA
- 含义:PiSSA (Pivoted Singular Value Approximation) 是一种初始化 LoRA 矩阵的方法。
- 作用:通过更高效的矩阵分解初始化,加速收敛并提高微调质量。
-
LoRA 作用模块
- 含义:指定哪些模块应用 LoRA 微调,例如只在注意力层或 MLP 层应用。
- 作用:可以针对性地微调模型的关键部分,减少参数量。
- 常见选择:只对注意力层的 query、key、value 矩阵应用 LoRA。
-
附加模块
- 含义:除了标准 LoRA 模块外,额外应用 LoRA 的模块。
- 作用:进一步扩展可训练参数范围,例如对输出层或 MLP 层也应用 LoRA,提高模型表达能力。
参数选择建议
- 小模型或资源有限:使用较低的秩 (4-8),较小的缩放系数 (8),启用 RSLoRA 或 DoRA。
- 大模型或复杂任务:使用较高的秩 (16),较大的缩放系数 (16-32),对更多模块应用 LoRA。
- 防止过拟合:使用 dropout (0.05),限制附加模块数量。
- 快速实验:从低秩 (4) 和中等缩放系数 (16) 开始,逐步调整。
-
作用:决定低秩矩阵的维度,直接影响模型表达能力与训练效率。
-
设置建议:简单任务(如情感分类)可设为 8-16;复杂任务(如代码生成)建议 24-32。例如,某代码平台训练代码补全 LoRA 时,将秩设为 28,在性能与资源消耗间取得最佳平衡。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号