


[Data Structure & Algorithm] 图 + 图的存储 + 图的遍历
图
- G = (V,E)
- V - 顶点
- E - 边(弧)
- 无向图 E =
- 完全无向图 - 有n(n-1)/2条边的无向图
- 顶点v的度 - 关联与该顶点的变得数目
- 连通图 - 任意两个不同的顶点之间都有路径
- 连通分量 - 极大连通子图
- 最小生成树 - 极小连通图
- 包含图中的全部顶点
- 有且仅有n-1条边 - 必要非充分条件
- 有向图 E =
- 弧头 - 目标结点;弧尾 - 起始结点
- 完全有向图 - 有n(n-1)条边(弧)的有向图
- 顶点v的度 = 入度(以该顶点为终点的边的数目)+ 出度(以该顶点为始点的边的数目)
- 强连通图 - 任意两个不同的顶点vi和vj,都存在从vi到vj,和从vj到vi的路径
- 强连通分量 - 极大强连通子图
- 生成森林
- 由若干棵有向树组成,包含全部顶点,但只有足以构成若干棵不相交的有向树的弧
- 路径
- 路径的长度 - 路径上边的数目
- 简单路径 - 路径上的每个顶点均不相同
- 环 - 路径的第一个顶点和最后一个顶点相同
图的存储
-
数组表示法 - 邻接矩阵
![]()
(网络图片 - 来源)- 如果顶点vi和vj之间存在边,则A[i][j] = 1
- 缺点 - 矩阵的存储
- 如果直接采用二维数组存储 - 空间浪费
- 如果采用压缩存储 - 图的运算变得复杂
- 对于无向图的性质
- 其邻接矩阵为对称矩阵
- 顶点vi的度 - 邻接矩阵中第i行(或者第i列)元素之和
- 对于有向图的性质
- 时间复杂度O(n+n2+e) = O(n2)

链式存储
-
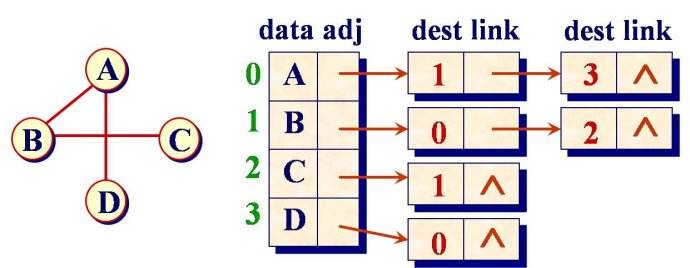
邻接表法
![]()
(网络图片 - 来源)- 结点
- 头结点 - 数据域|链域(指向链表中第一结点)
- 表结点 - 邻接点域(如邻接点序号)|链域(指向下一条边的顶点)|数据域(边的相关信息,如权值)
- 顶点表 - 头节点组成的表头向量
- 无向图
- 邻接表 - 边表
- n个头节点,2e个表结点
- 顶点vi的度 - 第i个链表中的结点数
- 有向图
- 邻接表 - 出边表
- n个头节点,e个表结点
- 顶点vi的度
- 出度 - 第i个链表中的结点数
- 入度
- 遍历整个邻接表 - 所有邻接点域为i的结点数
- 建立逆邻接表 - 得到入边表
- 结点
-
十字链表法 - 有向图
- 结点
- 顶点结点 - 数据域|链域(指向该顶点为弧头的第一个弧结点)|链域(指向该顶点为弧尾的第一个弧结点)
- 弧结点 - 数据域(尾域-弧尾顶点在图中的位置)|数据域(头域-弧头顶点在图中的位置)|链域(指向与本结点具有相同弧头的下一条弧)|链域(指向与本结点具有相同弧尾的下一个结点)
- 特点
- 容易求得顶点的出度和入度
- 维护成本高
- 结点
-
邻接多重表 - 无向图
- 结点
- 顶点结点 - 数据域|链域(指向第一条依附于该顶点的边)
- 边结点 - 标志域(标记该条边是否被搜索过)|数据域(顶点1)|链域(指向下一条依附于顶点1的边)|数据域(顶点2)|链域(指向下一条)|数据域
- 与邻接表比较
- 结点
| 边的表示 | 存储空间 | |
| 邻接表 | 两个结点 | 不考虑标志域,两者相同 |
| 邻接多重表 | 一个结点 |
图的遍历
- 深度优先遍历 DFS(Depth-first Search)
- 基本思想
- 选择某一顶点
- 访问此顶点,以及所有未曾访问过的,与其由路径相通的顶点
- 如果此时还有顶点没有访问到,再从1开始重复,直至所有顶点均被访问到
- 针对不同的存储方式
- 基本思想
| 时间复杂度 | 唯一确定序列的条件 | |
| 邻接表 | O(n+e) | 只有给出了邻接表的内容和初始出发点,才能唯一确定 |
| 邻接多重表 | O(n2) | 总是唯一 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号