概念和基础
kafka
kafka 是一个基于发布-订阅模型的消息系统,其中zookeeper用于检测崩溃,实现主题的发现,并且保持主题的生产和消费状态
api概述
| 1 | 2 |
|---|---|
| create/path data | 创建一个名为/path的znode节点 ,并且包含数据data |
| delete/path | 删除一个名为/path的znode |
| exist/path | 查看是否存在/path节点 |
| setData/path data | 设置名为/path的znode,数据为data |
| getData/path | 返回名为/path的znode的数据 |
| getChildren/path | 返回/path节点下的所有节点列表 |
节点类型
| 1 | 2 |
|---|---|
| 持久节点 | 一直存在,就是创建者没了他也有 |
| 临时节点 | 随着回话消失,client主动删除,不允许临时节点有子节点 |
| 有序节点 |
zk基础
监视和通知
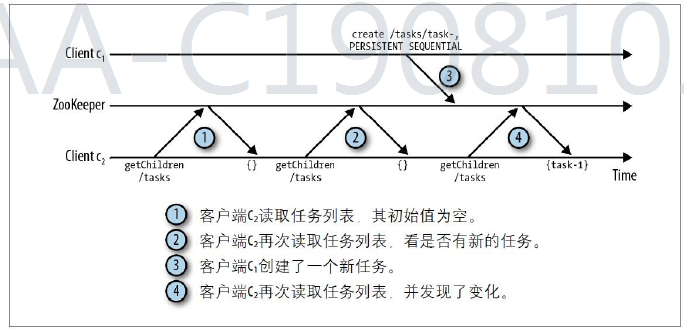
第二步是没有必要的
选择了基于通知(notification)的机制:客户端向ZooKeeper注册需要接收通知的
znode,通过对znode设置监视点(watch)来接收通知。监视点是⼀个单次
触发的操作,意即监视点会触发⼀个通知。为了接收多个通知,客户端必
须在每次通知后设置⼀个新的监视点。
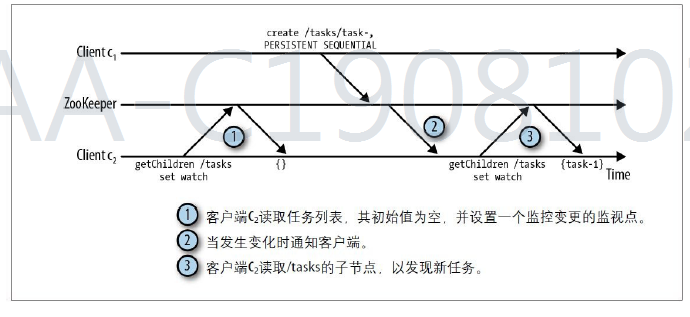
通知机制的⼀个重要保障是,对同⼀个znode的操作,先向客户端传送
通知,然后再对该节点进⾏变更
版本
每⼀个znode都有⼀个版本号,它随着每次数据变化⽽⾃增
两个API操作可以有条件地执⾏:setData和delete。这两个调⽤以版本号作为转⼊参
数,只有当转⼊参数的版本号与服务器上的版本号⼀致时调⽤才会成功。
zk架构
ZooKeeper服务器端运⾏于两种模式下:独⽴模式(standalone)和仲
裁模式(quorum)。
-
独立模式:有⼀个单独的服务器,ZooKeeper状态⽆法复制
-
仲裁模式:具有⼀组ZooKeeper服务器,我们称为ZooKeeper集合(ZooKeeper ensemble),它们之前可以进⾏状态的复制,并同时为服务于客户端的请求。
zk仲裁
法定人数:多数方案
主从应用
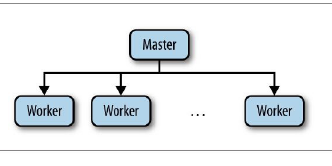
三个问题
- 主节点崩溃
- 从节点崩溃
- 通信故障
任务总结
- 主节点选举
这是关键的⼀步,使得主节点可以给从节点分配任务 - 崩溃检测
主节点必须具有检测从节点崩溃或失去连接的能⼒ - 组成员关系关系
主节点必须具有知道哪⼀个从节点可以执⾏任务的能⼒。
4.元数据管理
主节点和从节点必须具有通过某种可靠的⽅式来保存分配状态和执⾏
状态的能⼒。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号