CNN 卷积神经网络
LeNet
由 Yann LeCun 发明的著名的 LeNet.
原版中激活函数用的都是 $\mathrm{sigmoid}$, 现在看来用 $\mathrm{ReLU}$ 或 $\mathrm{tanh}$ 也许会更合适.

Fashion - mnist 数据集的识别
数据下载
def gener():
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="./data", train=True, transform=trans, download=False)
mnist_test = torchvision.datasets.FashionMNIST(root="./data", train=False, transform=trans, download=False)
return mnist_train, mnist_test
$\mathrm{root}$ :下载路径
$\mathrm{train}$ :是否是训练数据
$\mathrm{transform}$: 将数据类型变为 $\mathrm{torch}$
$\mathrm{download}$ 表示是否需要重新下载(如果下载过就记为 $\mathrm{False}$ )
test_data.test_data 是一个 $(10000, 28, 28)$ 的 $\mathrm{tensor}$
test_data.test_labels 是测试标签.
Dataloader 打包
train_dataloader = DataLoader(dataset = train_data, batch_size = 4, shuffle=True)
打包训练数据,其中 $\mathrm{batch_size}$ 是每次训练时塞入的训练数据个数.
默认一次遍历是要把全部数据遍历完的(即 15000 批次,每批次 3 个)
使用 GPU 训练
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
net.apply(init_weights)
net = net.to(device)
在训练时会使用的矩阵后面加上 $\mathrm{.to(device)}$ 即可.
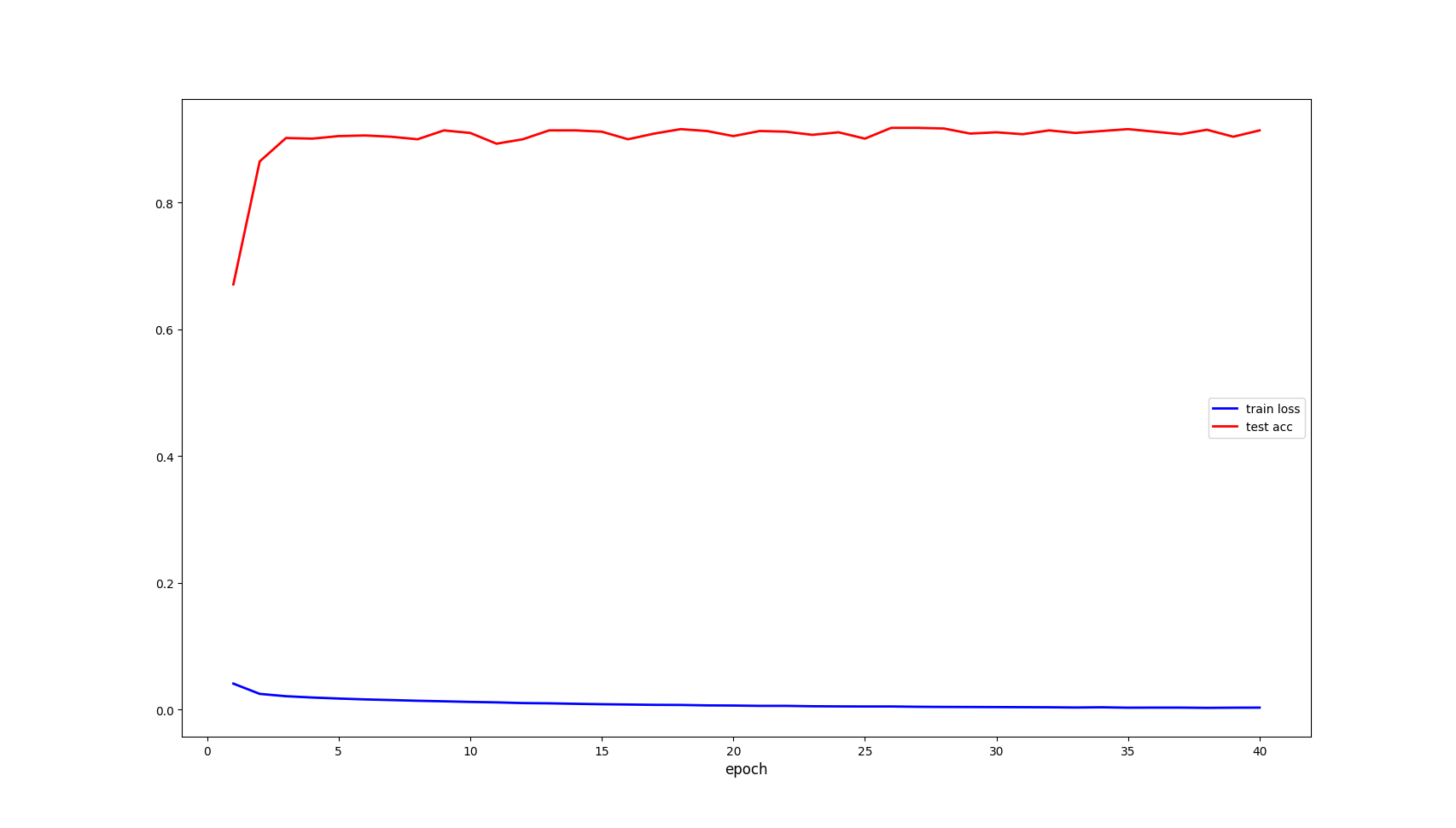
训练效果:
完整代码
# Dropout
# batch - norm
# Adam optimizer
import torch
from torch import nn
import d2l
import torchvision
import matplotlib.pyplot as plt
from torchvision import transforms
from torch.utils.data import DataLoader
def Draw_Line(x1, y1, x3, y3):
# 设置线宽
plt.plot(x1, y1, linewidth = 2, color = 'blue', label = 'train loss')
plt.plot(x3, y3, linewidth = 2, color = 'red', label = 'test acc')
plt.xlabel("epoch", fontsize = 12)
plt.legend()
plt.show()
def gener():
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="./data", train=True, transform=trans, download=False)
mnist_test = torchvision.datasets.FashionMNIST(root="./data", train=False, transform=trans, download=False)
return mnist_train, mnist_test
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
# LeNet
net = nn.Sequential(
nn.Conv2d(in_channels = 1, out_channels = 6, kernel_size = 5, padding = 2),
nn.BatchNorm2d(6),
nn.ReLU(),
nn.Dropout(0.5),
nn.MaxPool2d(kernel_size = 2, stride = 2),
nn.Conv2d(in_channels = 6, out_channels = 30, kernel_size = 5),
nn.BatchNorm2d(30),
nn.ReLU(),
nn.Dropout(0.5),
nn.MaxPool2d(kernel_size = 2, stride = 2),
nn.Flatten(),
nn.Linear(30 * 5 * 5, 120),
nn.BatchNorm1d(120),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(120, 84),
nn.BatchNorm1d(84),
nn.ReLU(),
nn.Linear(84, 10)
)
# 获取 fashion - mnist 数据集
# 训练数据已经自动归一到 (0,1) 区间了.
train_data, test_data = gener()
train_dataloader = DataLoader(dataset = train_data, batch_size = 100, shuffle=True)
test_x = torch.unsqueeze(test_data.test_data, dim = 1).type(torch.FloatTensor)[:2000] / 255.0
test_y = test_data.test_labels[:2000]
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
net.apply(init_weights)
net = net.to(device)
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr = 0.0075)
epoch = 40
train_loss, test_acc, ep = [], [], []
for st in range(epoch):
ep.append(st + 1)
sum = 0
for i, batch_sample in enumerate(train_dataloader):
train_x = batch_sample[0].to(device)
label = batch_sample[1].to(device)
optimizer.zero_grad()
output = net(train_x)
loss = loss_func(output, label)
sum += loss.item()
loss.backward()
optimizer.step()
if i % 2000 == 0:
print(st + 1, i + 1, loss.item())
if i > 8000:
break
train_loss.append(sum / 8000)
net.eval()
test_x = test_x.to(device)
test_y = test_y.to(device)
y_hat = net(test_x)
pred_y = torch.max(y_hat, 1)[1].data.squeeze()
print("accuracy: " + str((1000 - (test_y[:1000] != pred_y[:1000]).int().sum()).item() / 1000))
test_acc.append((1000 - (test_y[:1000] != pred_y[:1000]).int().sum()).item() / 1000)
Draw_Line(ep, train_loss, ep, test_acc)
AlexNet

著名的 AlexNet, 网络框架还是非常大且复杂的,十分消耗 $GPU$.
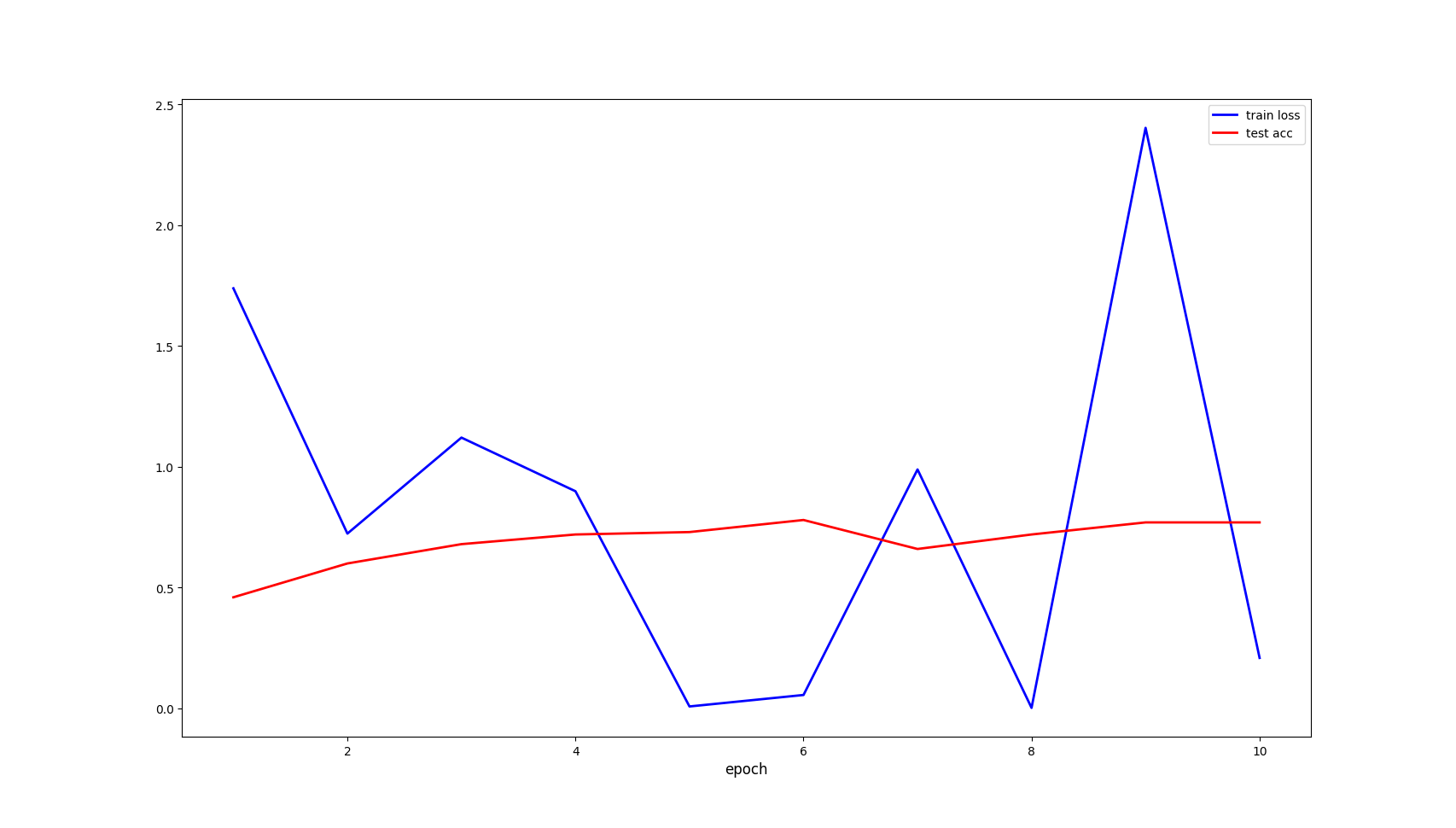
训练效果:(由于运行太慢,没有跑太多组数据)
训练代码:
import torch, gc
from torch import nn
import d2l
import torchvision
import matplotlib.pyplot as plt
from torchvision import transforms
from torch.utils.data import DataLoader
print(torch.__version__)
def Draw_Line(x1, y1, x3, y3):
# 设置线宽
plt.plot(x1, y1, linewidth = 2, color = 'blue', label = 'train loss')
plt.plot(x3, y3, linewidth = 2, color = 'red', label = 'test acc')
plt.xlabel("epoch", fontsize = 12)
plt.legend()
plt.show()
def gener():
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="./data", train=True, transform=trans, download=False)
mnist_test = torchvision.datasets.FashionMNIST(root="./data", train=False, transform=trans, download=False)
return mnist_train, mnist_test
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
def Train_Network(net, train_dataloader, test_x, test_y, LR = 0.00075, epoch = 20):
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
net.apply(init_weights)
net = net.to(device)
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr = LR)
train_loss, test_acc, ep = [], [], []
for st in range(epoch):
ep.append(st + 1)
lst = 0
for i, batch_sample in enumerate(train_dataloader):
train_x = batch_sample[0].to(device)
label = batch_sample[1].to(device)
optimizer.zero_grad()
output = net(train_x)
loss = loss_func(output, label)
lst = loss.item()
loss.backward()
optimizer.step()
if i % 2000 == 0:
print(st + 1, i + 1, loss.item())
if i > 6000:
break
train_loss.append(lst)
test_x = test_x.to(device)
test_y = test_y.to(device)
y_hat = net(test_x)
pred_y = torch.max(y_hat, 1)[1].data.squeeze()
test_acc.append((100 - (test_y[:100] != pred_y[:100]).int().sum()).item() / 100)
Draw_Line(ep, train_loss, ep, test_acc)
net = nn.Sequential(
nn.Conv2d(1, 96, kernel_size = 11, stride = 4, padding = 99),nn.ReLU(),
nn.MaxPool2d(kernel_size = 3, stride = 2),
nn.Conv2d(96, 256, kernel_size = 5, padding = 2), nn.ReLU(),
nn.MaxPool2d(kernel_size = 3, stride = 2),
nn.Conv2d(256, 384, kernel_size = 3, padding = 1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size = 3, padding = 1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size = 3, padding = 1), nn.ReLU(),
nn.MaxPool2d(kernel_size = 3, stride = 2),
nn.Flatten(),
nn.Linear(6400, 4096), nn.ReLU(),
# nn.Dropout(p = 0.5),
nn.Linear(4096, 4096), nn.ReLU(),
# nn.Dropout(p = 0.5),
nn.Linear(4096, 10)
)
train_data, test_data = gener()
train_dataloader = DataLoader(dataset = train_data, batch_size = 1, shuffle=True)
test_x = torch.unsqueeze(test_data.test_data, dim = 1).type(torch.FloatTensor)[:200] / 255.0
test_y = test_data.test_labels[:200]
Train_Network(net, train_dataloader, test_x, test_y, 0.001, 10)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号