

java实现wordCount的map
打开IDEA,File——new ——Project,新建一个项目
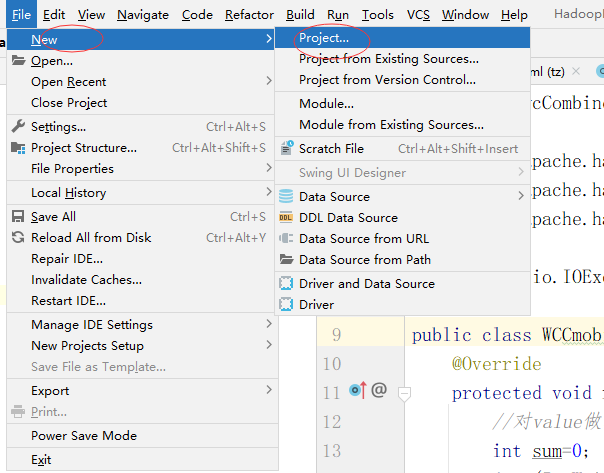
我们已经安装好了maven,不用白不用
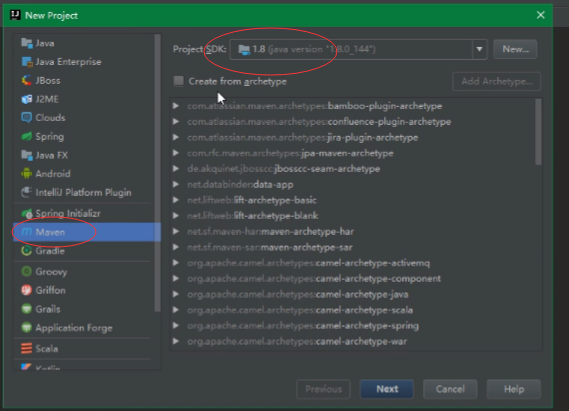
这里不要选用骨架,Next。在写上Groupid,Next。
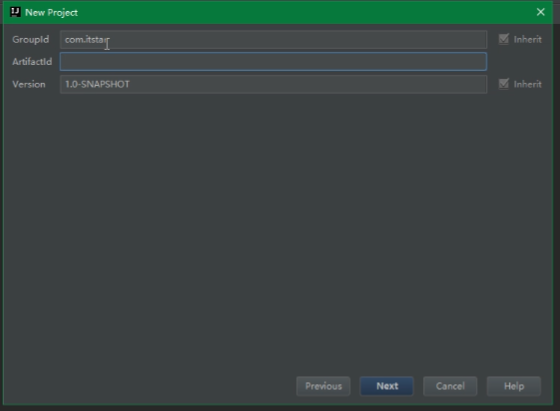
写上项目名称,finish。ok。
一个项目就建好了,他长这样:
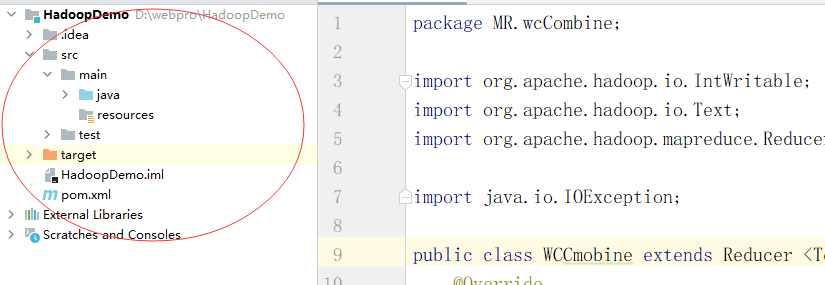
新建的项目要配置一下maven。毕竟我们马上就要用它。然后导入依赖
打开pom.xml
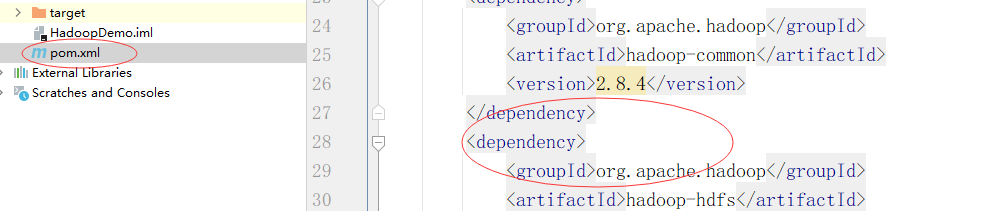
不愿意一个一个敲的话,可以使用cv大法。
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
等待下载的时候我们可以创建项目了。打开src——main——java,右键Package,我们在这里新建一个package。我们在这里包里面写一个wordcount的案例
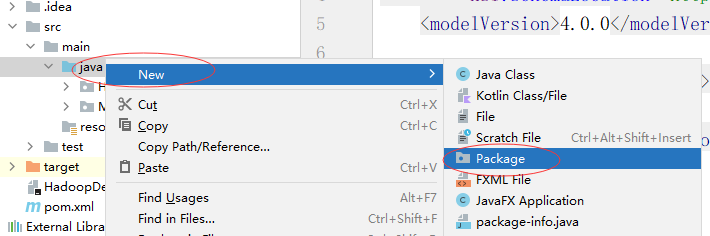
名字就叫MR
 .
.
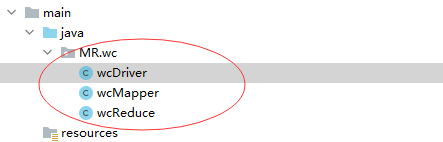
mr下再建一个包:wc。如图:

在wc下新建一个java类:wcMapper。这个类负责读取单词,生成map(键值对)
再创建一个wcReduce类。这个类负责聚合,把key相同的数据放到一起,并且累加value。
再创建一个wcDriver类,驱动类主要用于关联Mapper 和 Reducer 以及 提交整个程序。就像这样:
在写代码之前,我们先看一个mapreduce编程规范:
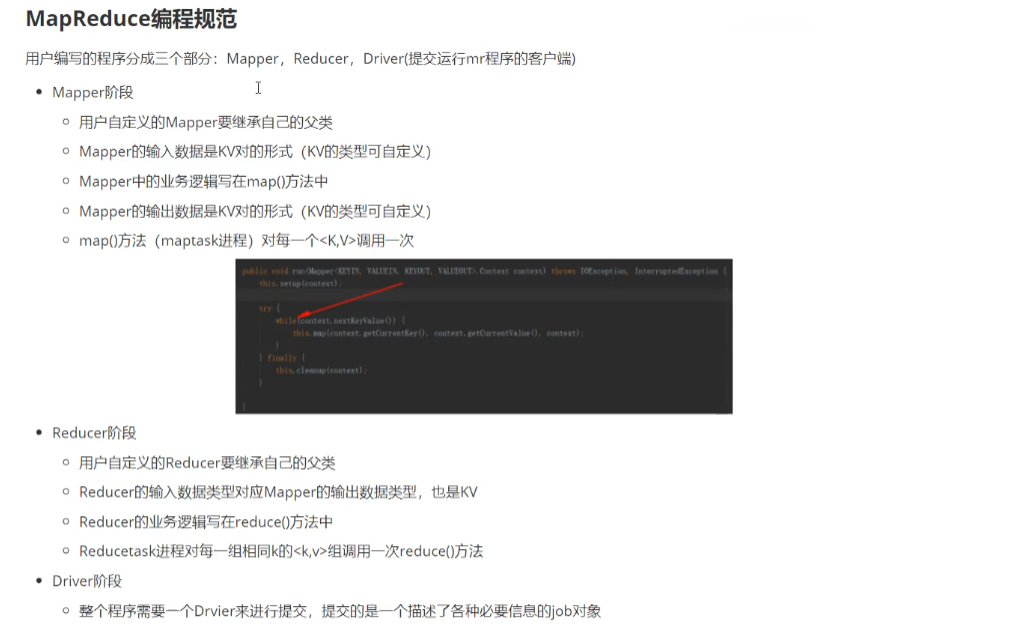
继续看代码,我们先写wcMapper类
package MR.wc;
/**
* 按行读取数据,拆成一个一个的单词
* */
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**继承Mapper类,这个类要是hadoop.mapreduce.Mapper
* 这里有一个泛型, Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>KEYIN,VALUEIN 规定数据是以什么类型进入map程序(MR程序提供了几种类型)
* KEYIN这个参数表示读取文件的行数,一般是数字类型。由于是文件可能会很大,一般不用int,而是用long
* VALUEIN这个参数表示读取数据的格式,也就是单词的格式,这里就是字符串
* 我们的对象要在节点之间通过网络传输,就需要序列化。但是java的序列化是一个重量级序列化框架,一个对象被序列化后,会附带很多额外的信息
* (各种校验信息,header,继承体系等),不便于在网络中高效传输。所以hadoop开发了一套序列化机制(writable),精简,高效
*
*
*/
public class wcMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
Text ko=new Text();
IntWritable vo=new IntWritable(1);//value值默认为1
//重写map方法,key跟value是我们读取进来的数据,数据处理玩以后就放到congtext(上下文)里面
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//读取到的这一行数据先转成String类型
String line = value.toString();
//按照空格切分单词
String[] words = line.split(" ");
//处理数据
for (String word : words) {
//keyout设置成单词
ko.set(word);
//通过上下把处理好的数据写出
context.write(ko,vo);
}
}}
到这里,map这个过程就写完了,这个过程就实现了按行读取数据,并且把单词转化成了key,value的形式,给每个单词的value值标成了1,然后通过上下文把数据写出,在wc这个程序中,实际上就是把这个key,value传给了wcRecude。让reduce过程去按照key聚合value。
常用java类型对应的HadoopWritable类型:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号