MapReduce入门
先贴一战mr流程图,新手朋友不要看见这个图就头晕,我们后续会使用java API实现几个案例,帮助我们更好的理解各个环节,比如切片,文件读取,Map,combine,Reduce,shuffle等等。案例写完以后相信对mr流程会有一个比较深刻的理解。
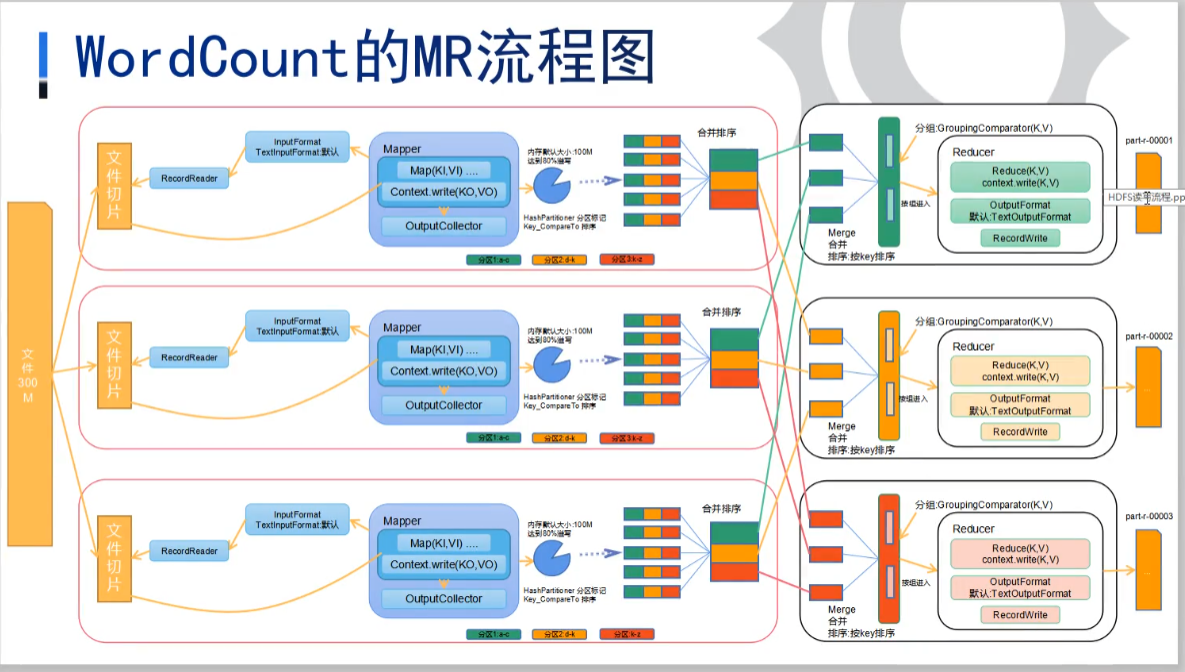
具体的太理论的东西没什么好讲的,我们这里比较偏重于实操。
比如一个文档,里面有这么几个单词,我们要用代码实现统计各个单词数量的。
这个文档长这样:

比如这里有一个很大的文档,里面有很多英语单词,我要看看那些单词使用频率高,我就要统计这里面各个单词出现的次数,既然要用代码实现,那些把手指头伸出来准备数手指头的同学先把手缩回去,我们就不数手指头了。实际文件长这样:.
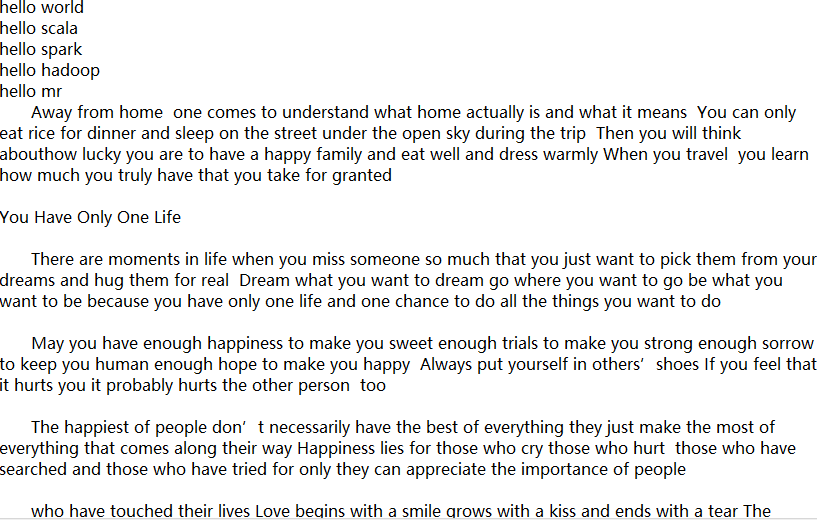
好了,不扯淡了,继续。既然要用代码实现,那我们就先整理一下思路:
首先我们要读取这个文件(不要跟我说要先创建文件之类的话,我们现在说的是mr的大体框架)
1,读取数据。按行读取数据。第一行,有hello和world两个单词,第二行有hello和Scala两个单词等等等等。
2,按空格切分数据。比如第一行,我们得到两个单词:hello和world。
3,将两个单词放到一个map集合中map("hello",1),map("world",1)这个map的key就是一个单词,value就是1,表示这个单词出现了一次。以前五行为例,就得到了这么一个玩意儿:

4,现在我们把相同key的数据统计到一起,并且累加value值
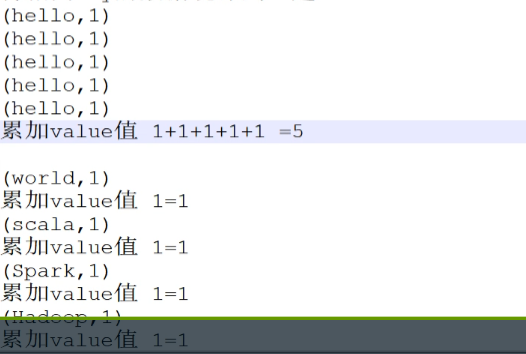
实际上就是两部,分(map),合(reduce)两个。有点天下大势,合久必分,分久必合的意思啊。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号