

hadoop伪分布式搭建
1,下载Hadoop安装包我用的2.8.4版本,上传到Linux上面(跟之前上传jdk文件一样)
2,解压安装包:tar -zxvf 文件名

3,修改一下权限:

4,进入到Hadoop配置文件下面:
输入命令:cd hadoop-2.8.4/etc
输入命令:cd hadoop
在这里配置一个伪分布式。
输入命令:vim core-site.xml
修改配置文件如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata101:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.8.4/data/tmp</value>
</property>
</configuration>
输入命令:vim hdfs-site.xml
修改配置文件:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata102:50090</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
输入命令:vim yarn-site.xml
修改配置文件如下:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata102</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
输入命令:cp mapred-site.xml.template mapred-site.xml --复制一个模板文件,重命名
打开配置文件:vim mapred-site.xml
修改配置文件如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>bigdata101:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdata101:19888</value>
</property>
</configuration>
5,输入命令:echo $JAVA_HOME,找到jdk安装目录
输入命令:vim hadoop-env.sh
配置java_home

6,输入命令:vim yarn-env.sh
修改文件:

7,输入命令:vim mapred-env.sh

8,配置Hadoop环境变量:vim /etc/profile
设置如下:
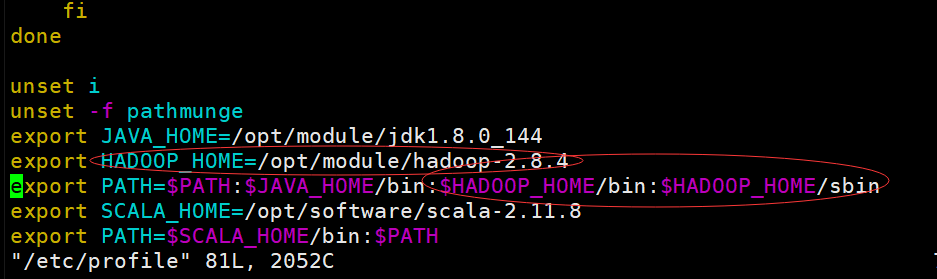
9,输入命令:source /etc/profile
10,输入命令:hdfs namenode -format,格始化hdfs。
11,启动Hadoop:start-dfs.sh,由于还没有设置免密登录,这里我们要手动输入密码。
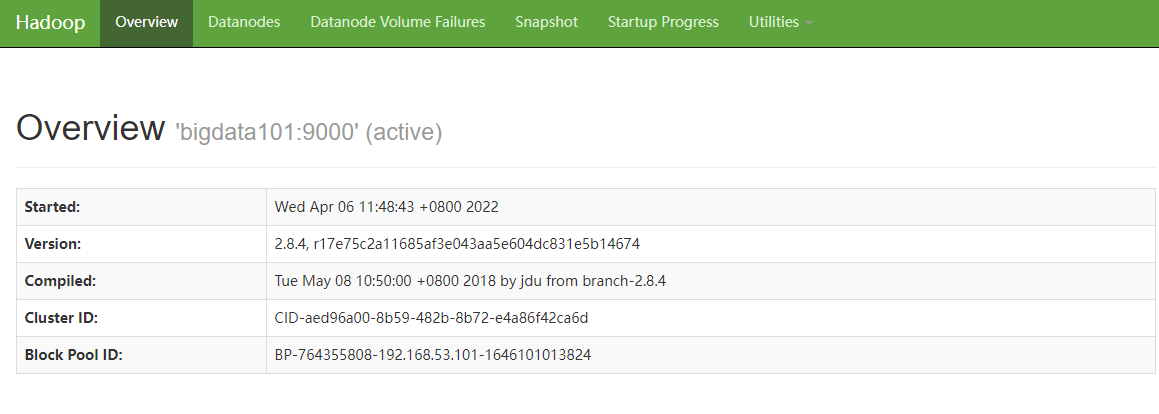
启动成功以后,我们打开浏览器,输入地址值:http://192.168.53.101:50070/
出现以下页面,说明Hadoop安装成功了:
12,此时伪分布式已经搭建好了,试试能不能用,进入到我们自己常用的文件下:cd /opt/bigdata/
vim a.txt
写点数据进去,然后保存退出。
先学习一个hdfs命令:hdfs -put a.txt / 或者 hadoop fs -put a.txt /
13,回到浏览器,
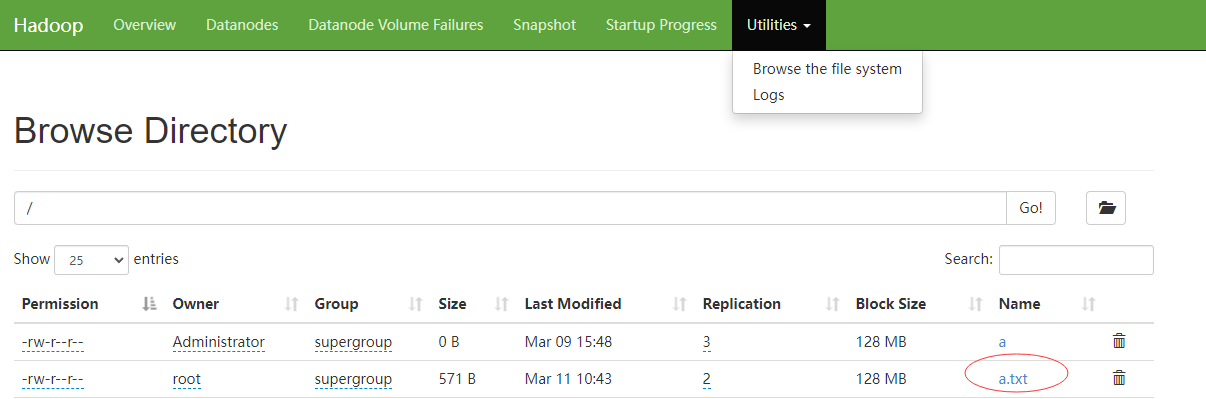
发现刚才在Linux上的文件,已经上传到Hadoop上面了。
在这里,我们修改了很多配置文件,有的配置文件需要修改,有的文件不该也行,但是为了后续的进一步搭建分布式集群和一些不稳定的软件之间的冲突,我们就全部给他配置一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号