第二次作业:卷积神经网络 part 2
一、MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
论文阅读总结:
传统卷积神经网络内存需求大、运算量大,会导致诸多不便。谷歌针对这一系列问题提出一类有效的模型MobileNets。主要原理是将卷积核进行分解,实现有效的减少网络参数。
Depthwise(DW)卷积与Pointwise(PW)卷积,合起来被称作Depthwise Separable Convolution(参见Google的Xception),该结构和常规卷积操作类似,可用来提取特征,但相比于常规卷积操作,其参数量和运算成本较低。所以在一些轻量级网络中会碰到这种结构如MobileNet。
常规卷积操作
对于一张5×5像素、三通道彩色输入图片(shape为5×5×3)。经过3×3卷积核的卷积层(假设输出通道数为4,则卷积核shape为3×3×3×4),最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5×5),如果没有则为尺寸变为3×3。
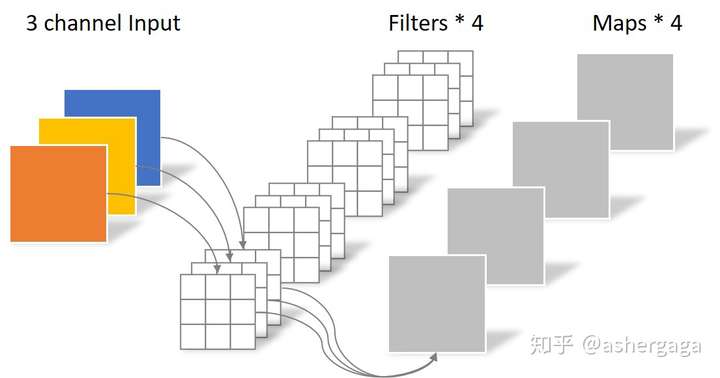
此时,卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算:
N_std = 4 × 3 × 3 × 3 = 108
Depthwise Separable Convolution
Depthwise Separable Convolution是将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。
Depthwise Convolution(大大减少了运算量和参数量)
不同于常规卷积操作,Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。上面所提到的常规卷积每个卷积核是同时操作输入图片的每个通道。
同样是对于一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,不同于上面的常规卷积,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。
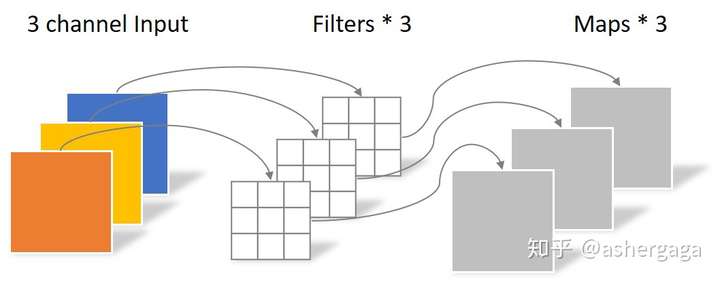
其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:
N_depthwise = 3 × 3 × 3 = 27
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
Pointwise Convolution
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。如下图所示。
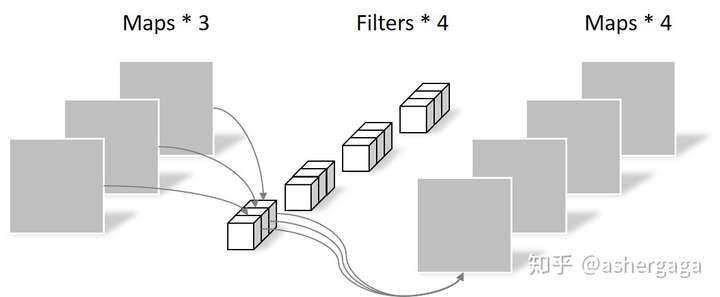
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:
N_pointwise = 1 × 1 × 3 × 4 = 12
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同。
参数对比
回顾一下,常规卷积的参数个数为:
N_std = 4 × 3 × 3 × 3 = 108
Separable Convolution的参数由两部分相加得到:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39
相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
卷积神经网络(CNN)已经普遍应用在计算机视觉领域,并且已经取得了不错的效果。
Depthwise separable convolution
MobileNet的基本单元是深度级可分离卷积(depthwise separable convolution),其实这种结构之前已经被使用在Inception模型中。深度级可分离卷积其实是一种可分解卷积操作(factorized convolutions),其可以分解为两个更小的操作:depthwise convolution和pointwise convolution,如图1所示。Depthwise convolution和标准卷积不同,对于标准卷积其卷积核是用在所有的输入通道上(input channels),而depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说depthwise convolution是depth级别的操作。而pointwise convolution其实就是普通的卷积,只不过其采用1x1的卷积核。图2中更清晰地展示了两种操作。对于depthwise separable convolution,其首先是采用depthwise convolution对不同输入通道分别进行卷积,然后采用pointwise convolution将上面的输出再进行结合,这样其实整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。
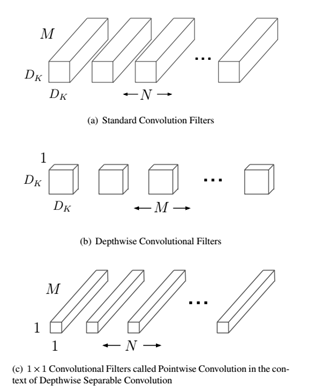
图1 Depthwise separable convolution
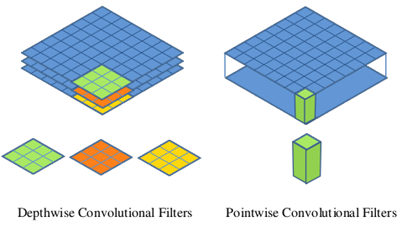
图2 Depthwise convolution和pointwise convolution
这里简单分析一下depthwise separable convolution在计算量上与标准卷积的差别。假定输入特征图大小是 ,而输出特征图大小是
,其中
是特征图的width和height,这是假定两者是相同的,而和指的是通道数(channels or depth)。这里也假定输入与输出特征图大小(width and height)是一致的。采用的卷积核大小是尽管是特例,但是不影响下面分析的一般性。对于标准的卷积
,其计算量将是:
而对于depthwise convolution其计算量为: ,pointwise convolution计算量是:
,所以depthwise separable convolution总计算量是:
可以比较depthwise separable convolution和标准卷积如下:
一般情况下 比较大,那么如果采用3x3卷积核的话,depthwise separable convolution相较标准卷积可以降低大约9倍的计算量。其实,后面会有对比,参数量也会减少很多。
MobileNet网络结构
前面讲述了depthwise separable convolution,这是MobileNet的基本组件,但是在真正应用中会加入batchnorm,并使用ReLU激活函数,所以depthwise separable convolution的基本结构如图3所示。
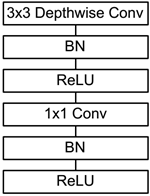
图3 加入BN和ReLU的depthwise separable convolution
MobileNet的网络结构如表1所示。首先是一个3x3的标准卷积,然后后面就是堆积depthwise separable convolution,并且可以看到其中的部分depthwise convolution会通过strides=2进行down sampling。然后采用average pooling将feature变成1x1,根据预测类别大小加上全连接层,最后是一个softmax层。如果单独计算depthwise
convolution和pointwise convolution,整个网络有28层(这里Avg Pool和Softmax不计算在内)。我们还可以分析整个网络的参数和计算量分布,如表2所示。可以看到整个计算量基本集中在1x1卷积上,如果你熟悉卷积底层实现的话,你应该知道卷积一般通过一种im2col方式实现,其需要内存重组,但是当卷积核为1x1时,其实就不需要这种操作了,底层可以有更快的实现。对于参数也主要集中在1x1卷积,除此之外还有就是全连接层占了一部分参数。
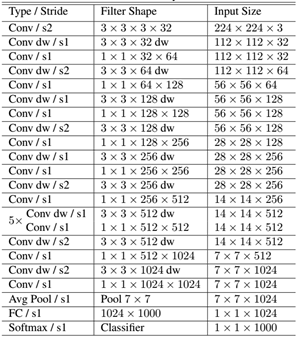
表1 MobileNet的网络结构
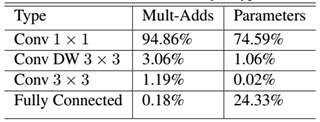
表2 MobileNet网络的计算与参数分布
MobileNet到底效果如何,这里与GoogleNet和VGG16做了对比,如表3所示。相比VGG16,MobileNet的准确度稍微下降,但是优于GoogleNet。然而,从计算量和参数量上MobileNet具有绝对的优势。
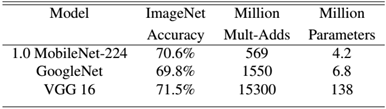
表3 MobileNet与GoogleNet和VGG16性能对比
MobileNet瘦身
前面说的MobileNet的基准模型,但是有时候你需要更小的模型,那么就要对MobileNet瘦身了。这里引入了两个超参数:width multiplier和resolution multiplier。第一个参数width multiplier主要是按比例减少通道数,该参数记为 ,其取值范围为(0,1],那么输入与输出通道数将变成
和
,对于depthwise separable convolution,其计算量变为:
因为主要计算量在后一项,所以width multiplier可以按照比例降低计算量,其是参数量也会下降。第二个参数resolution multiplier主要是按比例降低特征图的大小,记为 ,比如原来输入特征图是224x224,可以减少为192x192,加上resolution multiplier,depthwise separable convolution的计算量为:
要说明的是,resolution multiplier仅仅影响计算量,但是不改变参数量。引入两个参数会给肯定会降低MobileNet的性能,具体实验分析可以见paper,总结来看是在accuracy和computation,以及accuracy和model size之间做折中。
代码练习:
创建 MobileNetV1 网络
32×32×3 ==>
32×32×32 ==> 32×32×64 ==> 16×16×128 ==> 16×16×128 ==>
8×8×256 ==> 8×8×256 ==> 4×4×512 ==> 4×4×512 ==>
2×2×1024 ==> 2×2×1024
接下来为均值 pooling ==> 1×1×1024
最后全连接到 10个输出节点
class MobileNetV1(nn.Module): # (128,2) means conv planes=128, stride=2 cfg = [(64,1), (128,2), (128,1), (256,2), (256,1), (512,2), (512,1), (1024,2), (1024,1)] def __init__(self, num_classes=10): super(MobileNetV1, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(32) self.layers = self._make_layers(in_planes=32) self.linear = nn.Linear(1024, num_classes) def _make_layers(self, in_planes): layers = [] for x in self.cfg: out_planes = x[0] stride = x[1] layers.append(Block(in_planes, out_planes, stride)) in_planes = out_planes return nn.Sequential(*layers) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.layers(out) out = F.avg_pool2d(out, 2) out = out.view(out.size(0), -1) out = self.linear(out) return out
模型训练
for i, (inputs, labels) in enumerate(trainloader): inputs = inputs.to(device) labels = labels.to(device) # 优化器梯度归零 optimizer.zero_grad() # 正向传播 + 反向传播 + 优化 outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 输出统计信息 if i % 100 == 0: print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item())) print('Finished Training')
模型测试
total = 0 for data in testloader: images, labels = data images, labels = images.to(device), labels.to(device) outputs = net(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy of the network on the 10000 test images: %.2f %%' % ( 100 * correct / total))
Accuracy of the network on the 10000 test images: 77.85 %
二:MobileNetV2: Inverted Residuals and Linear Bottlenecks
论文阅读:
主要的亮点改进就是加入了Inverted Residuals(倒残差结构)和Linear Bottlenecks。
MobileV2与V1的区别
下图是MobileNetV2与MobileNetV1的区别:
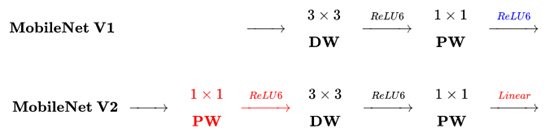
主要区别有两点:
(1)Depth-wise convolution之前多了一个1*1的“扩张”层,目的是为了提升通道数,获得更多特征;
(2)最后不采用Relu,而是Linear,目的是防止Relu破坏特征。
MobileNet V1 的主要问题: 结构非常简单,但是没有使用RestNet里的residual learning;另一方面,Depthwise Conv确实是大大降低了计算量,但实际中,发现不少训练出来的kernel是空的。
MobileNet V2 的主要改动一:设计了Inverted residual block
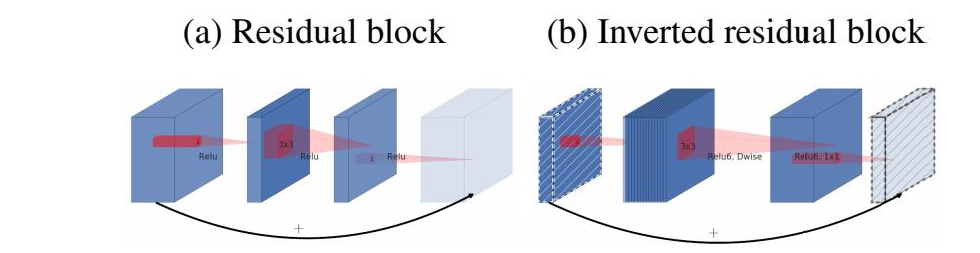
ResNet中的bottleneck,先用1x1卷积把通道数由256降到64,然后进行3x3卷积,不然中间3x3卷积计算量太大。所以bottleneck是两边宽中间窄(也是名字的由来)。
现在我们中间的3x3卷积可以变成Depthwise,计算量很少了,所以通道可以多一些。所以MobileNet V2 先用1x1卷积提升通道数,然后用Depthwise 3x3的卷积,再使用1x1的卷积降维。作者称之为Inverted residual block,中间宽两边窄。
MobileNet V2 的主要改动二:去掉输出部分的ReLU6
在 MobileNet V1 里面使用 ReLU6,ReLU6 就是普通的ReLU但是限制最大输出值为 6,这是为了在移动端设备 float16/int8 的低精度的时候,也能有很好的数值分辨率。Depthwise输出比较浅,应用ReLU会带来信息损失,所以在最后把ReLU去掉了(注意下图中标红的部分没有ReLU)。
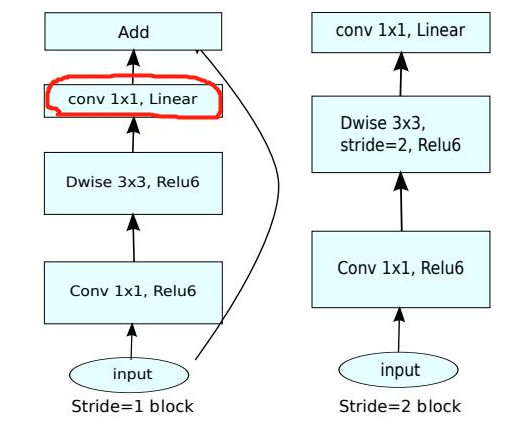
MobileNetV2网络
MobileNetV2网络结构如下:

网络的性能如下:

代码练习:
创建 MobileNetV2 网络( CIFAR10 是 32*32)
class MobileNetV2(nn.Module): # (expansion, out_planes, num_blocks, stride) cfg = [(1, 16, 1, 1), (6, 24, 2, 1), (6, 32, 3, 2), (6, 64, 4, 2), (6, 96, 3, 1), (6, 160, 3, 2), (6, 320, 1, 1)] def __init__(self, num_classes=10): super(MobileNetV2, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(32) self.layers = self._make_layers(in_planes=32) self.conv2 = nn.Conv2d(320, 1280, kernel_size=1, stride=1, padding=0, bias=False) self.bn2 = nn.BatchNorm2d(1280) self.linear = nn.Linear(1280, num_classes) def _make_layers(self, in_planes): layers = [] for expansion, out_planes, num_blocks, stride in self.cfg: strides = [stride] + [1]*(num_blocks-1) for stride in strides: layers.append(Block(in_planes, out_planes, expansion, stride)) in_planes = out_planes return nn.Sequential(*layers) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.layers(out) out = F.relu(self.bn2(self.conv2(out))) out = F.avg_pool2d(out, 4) out = out.view(out.size(0), -1) out = self.linear(out) return out
模型训练
for epoch in range(10): # 重复多轮训练 for i, (inputs, labels) in enumerate(trainloader): inputs = inputs.to(device) labels = labels.to(device) # 优化器梯度归零 optimizer.zero_grad() # 正向传播 + 反向传播 + 优化 outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 输出统计信息 if i % 100 == 0: print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item())) print('Finished Training')
模型测试
correct = 0 total = 0 for data in testloader: images, labels = data images, labels = images.to(device), labels.to(device) outputs = net(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy of the network on the 10000 test images: %.2f %%' % ( 100 * correct / total))
Accuracy of the network on the 10000 test images: 82.13 %
准确率比V1明显提高
三、HybridSN: Exploring 3-D–2-DCNN Feature Hierarchy for Hyperspectral Image Classification
论文阅读:
此篇论文相较于上两篇较简单,主要是构建了一个混合网络解决高光谱图像分类问题,首先用 3D卷积,然后使用 2D卷积来实现。
仅使用2D-CNN或3D-CNN分别存在缺失通道关系信息或模型非常复杂等缺点。这也阻碍了这些方法在高光谱图像上取得更好的精度。主要原因是高光谱图像是体积数据,也有光谱维数。仅凭2D-CNN无法从光谱维度中提取出具有良好鉴别能力的feature maps。
定义 HybridSN 类
模型的网络结构为如下图所示:
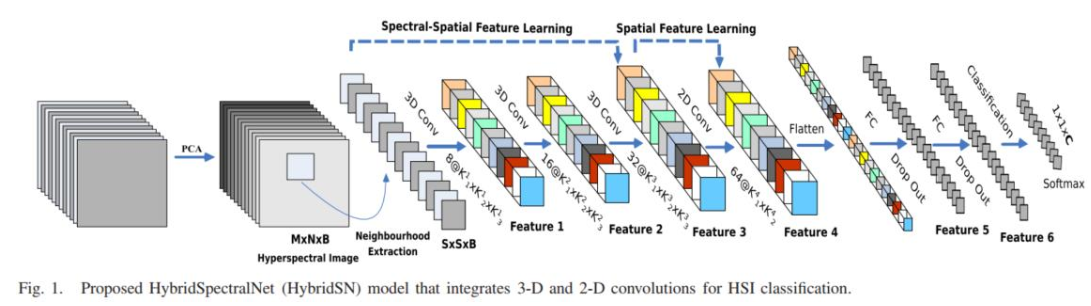
三维卷积部分:
- conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==>(8, 24, 23, 23)
- conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
- conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
接下来要进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
接下来是一个 flatten 操作,变为 18496 维的向量,
接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout,
最后输出为 16 个节点,是最终的分类类别数。

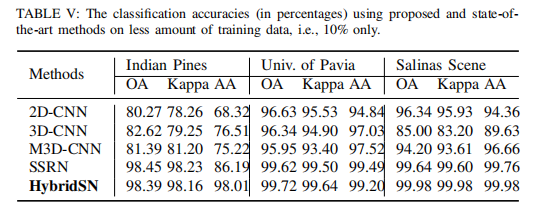
使用SVM、2D-CNN、3D-CNN对一个示例高光谱图像的分类图如图所示。M3D-CNN, SSRN和HubridSN方法。SSRN和hybrid的分类图质量明显优于其他方法。在SSRN和hybrid中,hybrid在小段内生成的地图要优于SSRN。
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 网络放到GPU上 net = HybridSN().to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=0.001) # 开始训练 total_loss = 0 for epoch in range(100): for i, (inputs, labels) in enumerate(train_loader): inputs = inputs.to(device) labels = labels.to(device) # 优化器梯度归零 optimizer.zero_grad() # 正向传播 + 反向传播 + 优化 outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() total_loss += loss.item() print('[Epoch: %d] [loss avg: %.4f] [current loss: %.4f]' %(epoch + 1, total_loss/(epoch+1), loss.item())) print('Finished Training')
模型测试
count = 0 # 模型测试 for inputs, _ in test_loader: inputs = inputs.to(device) outputs = net(inputs) outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1) if count == 0: y_pred_test = outputs count = 1 else: y_pred_test = np.concatenate( (y_pred_test, outputs) ) # 生成分类报告 classification = classification_report(ytest, y_pred_test, digits=4) print(classification)
precision recall f1-score support
0.0 1.0000 0.9268 0.9620 41
1.0 0.9835 0.9253 0.9535 1285
2.0 0.9293 0.9853 0.9565 747
3.0 0.9534 0.8638 0.9064 213
4.0 0.9929 0.9609 0.9766 435
5.0 0.9569 0.9467 0.9518 657
6.0 1.0000 1.0000 1.0000 25
7.0 0.9795 1.0000 0.9896 430
8.0 0.7500 0.6667 0.7059 18
9.0 0.9454 0.9897 0.9671 875
10.0 0.9753 0.9824 0.9788 2210
11.0 0.9380 0.9625 0.9501 534
12.0 0.9944 0.9514 0.9724 185
13.0 0.9659 0.9956 0.9805 1139
14.0 0.9815 0.9193 0.9494 347
15.0 0.9342 0.8452 0.8875 84
accuracy 0.9653 9225
macro avg 0.9550 0.9326 0.9430 9225
weighted avg 0.9657 0.9653 0.9651 9225
准确率为96.53%

 浙公网安备 33010602011771号
浙公网安备 33010602011771号