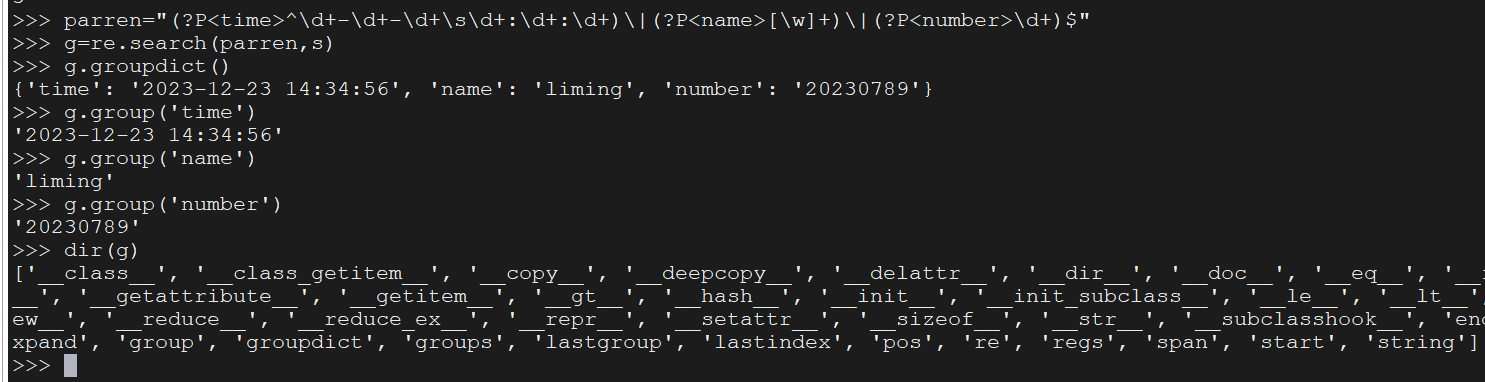
import re
s="2023-12-23 14:34:56|liming|20230789"
parren="(?P<time>^\d+-\d+-\d+\s\d+:\d+:\d+)\|(?P<name>[\w]+)\|(?P<number>\d+)$"
g=re.search(parren,s)
>>> g.groupdict()
{'time': '2023-12-23 14:34:56', 'name': 'liming', 'number': '20230789'}
>>> g.group('time')
'2023-12-23 14:34:56'
>>> g.group('name')
'liming'
>>> g.group('number')
'20230789'
![]()
样例2
astr1 = 'AAbb aabb'
astr2 = 'aabb aabb'
astr3 = 'aabb ccbb'
for s in astr1,astr2,astr3:
result = re.match(r'(?i)(?P<pattern>[\w]+) (?P=pattern)',s)
if result != None:
print('{} match result is {}'.format(s,result.group()))
else:
print('{} match Nothing'.format(s))
#AAbb aabb match result is AAbb aabb
#aabb aabb match result is aabb aabb
#aabb ccbb match Nothing
#可以看到(?P<pattern>)可以用来标记一些模糊的模式,然后在同一个正则表达式中,我们可以通过(?P=pattern)来复用之前的内容,这就是它们两个的用法区别,一个用于标记,一个用于在同一个正则表达式中复用,
特别提醒:同一个正则表达式
样例3
astr = 'aabb aacc aadd'
result = re.sub(r'(?i)aa(?P<pattern>[\w]+)',r'bb\g<pattern>',astr)
print('{} has been substituted to {}'.format(astr,result))
#aabb aacc aadd has been substituted to bbbb bbcc bbdd
#不同的表达式中复用

 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号