100行代码实现加权负载均衡算法(WRR)
轮询算法round-robin是很基础的负载均衡算法,实际应用中wrr更为常见,但一般不需要自己实现,因为一般需要rr的场景,都已经在基础设施层面进行了支持,比如lvs或nginx通过配置即可实现,但业务上偶尔也需要自己实现负载均衡,所以有必要了解一下其技术原理。
谈到wrr的应用场景,一般是服务器配置存在差异时,比如集群里有一个2C4G和一个4C8G,那么我们希望4C8G能承担更多的业务请求。或者是,我们希望通过无条件的流量分发,在集群的一台机器上小范围的导入一些流量进行一些实验。我碰到的场景是,在网关层面对业务方的集群迁移进行支持,也属于第二种场景。
原理
权重可以看做期望目标出现的概率,比如两个节点A、B,权重分别是100和50,那么等于在说,我们期望66.7%的请求由A处理,剩余33.3%的请求由B处理。
一种比较挫的实现方式,是将所有节点按照权重比例分布在一个离散的区间内,比如1-100,然后使用随机数生成100以内的自然数,如果随机数0<x<=66就由A处理请求,如果66<x<=100就由B处理请求。这种方法看似实现容易,但致命缺陷是依赖随机数的有效性,而大部分场景我们使用的都是伪随机数。此外集群数量伸缩时,会出现精度问题。
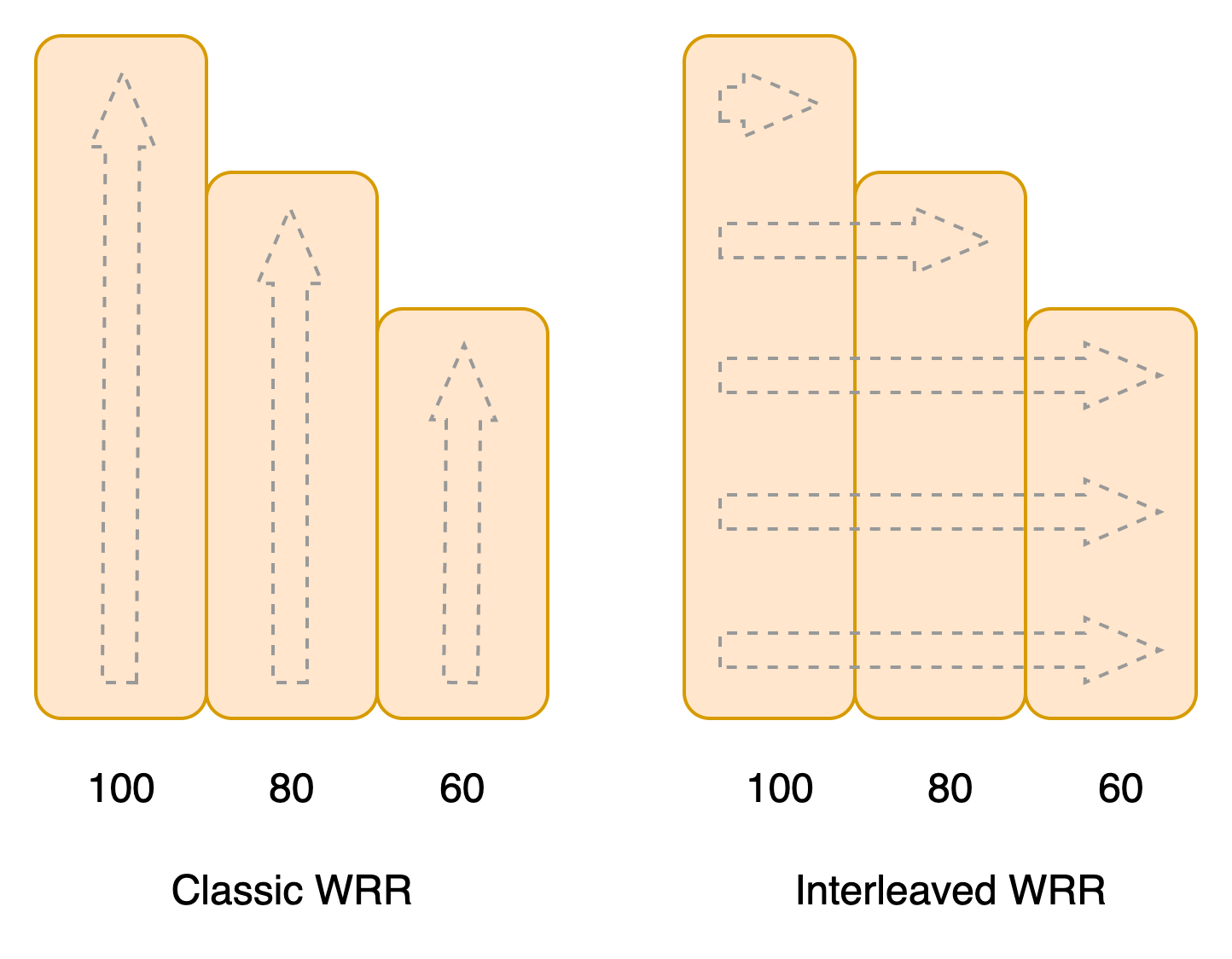
在wiki中提供了两种wrr的实现方式,分别是classic wrr和interleaved wrr,简称为WRR和IWRR,他们的区别可以通过下图来了解一下。
-
WRR
初始权重水位c设置为0,外循环遍历所有的节点,内循环遍历当前节点的水位值,如果权重水位c在该值内,则使用当前节点处理请求,同时c值递增。直到c大于当前节点的权重值,重置c为0,再对下一个节点执行内循环。 -
IWRR
外循环递增水位值,内循环遍历所有节点,如果当前水位值低于节点权重值,则由当前节点处理请求。遍历完所有节点后,递增水位值后再对所有节点进行遍历。
![]()
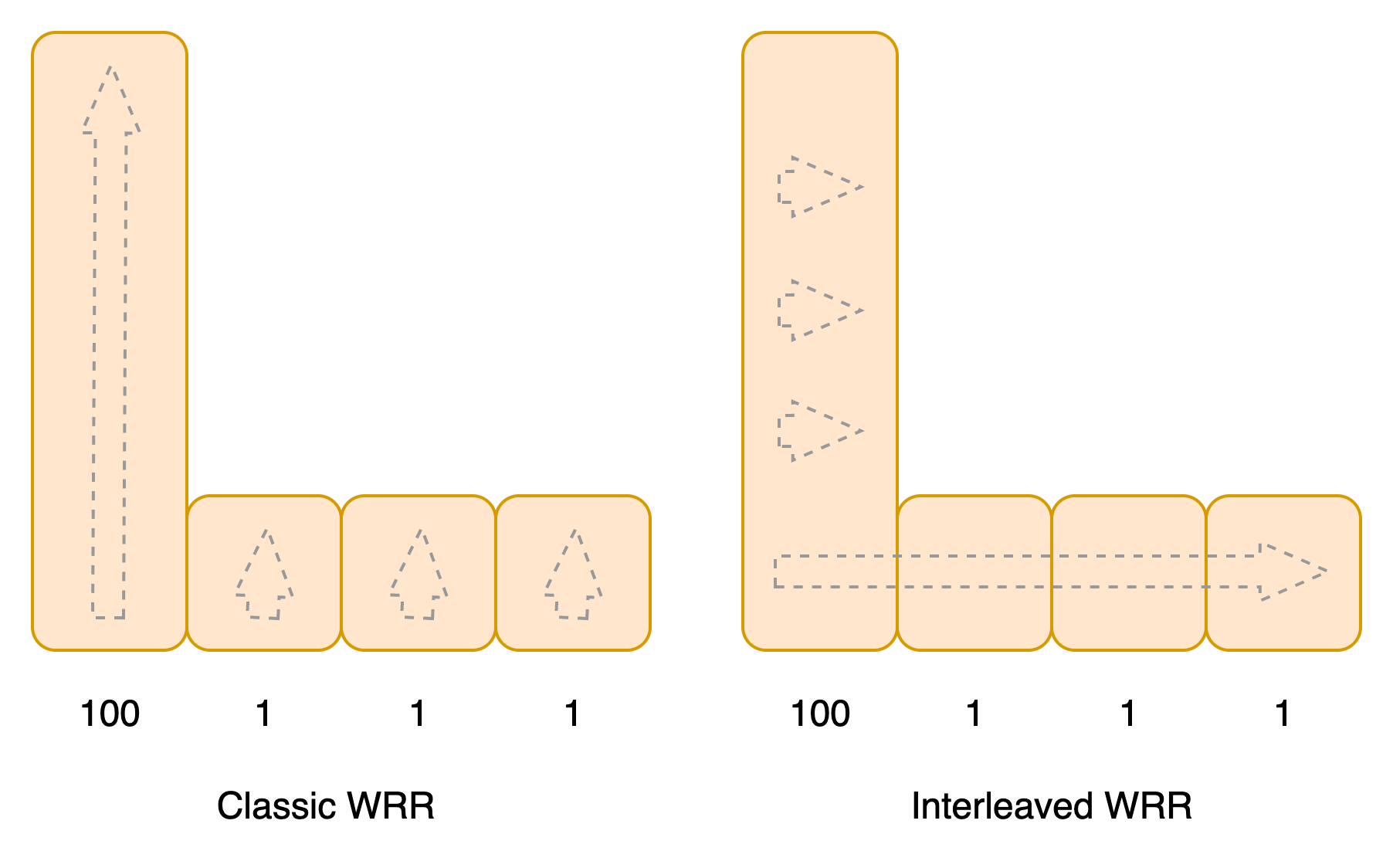
通过对比可以发现,如果集群中的节点权重相近,且值都比较高,则使用IWRR会明显的避免节点负载的尖刺情况,节点越多越明显。但这种情况会随着节点权重差异的增加而消退。极端假设集群中有一个节点权重是100,其他节点权重都是1,那么IWRR和WRR的效果是一样的。
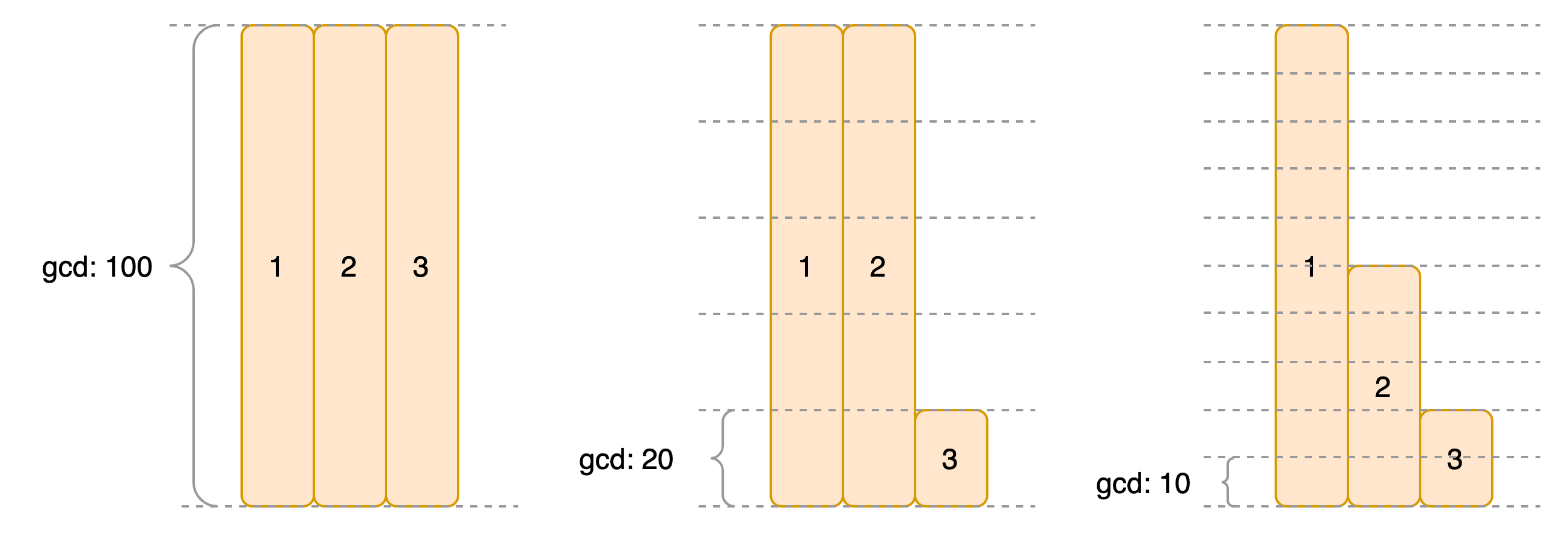
此外,在IWRR的实践中,一般会用集群内节点权重值的最大公约数(gcd),来作为外循环水位值的递增步长,这样可以减轻少量权重较低节点的摆动。比如集群内有4个权重为100的节点ABCD,1个权重为20的节点E,当步长为1时,节点E会在开始的20个周期内执行20次,然后在剩下的80个周期内无事可做。如果使用gcd来作为步长,最多隔5个周期就会处理一次请求。
实践
这里用go实现了一个类IWRR的负载均衡器,区别在于横向扫描的方向是自顶向下的
package balancer
import (
"errors"
)
var (
ErrSuccess = error(nil)
ErrNoTarget = errors.New("no target to run")
)
type ITarget interface {
Call() error // 实际工作负载方法
Weight() int // 当前target权重
}
type Balancer struct {
targets []ITarget // 目标集
maxweight int // 当前集群中的最大权重
current int // 当前权重水位
stride int // 权重步长(最大公约数)
index int // 当前目标索引
}
func (b *Balancer) AddTarget(t ITarget) {
// 更新目标集
b.targets = append(b.targets, t)
// 更新步长
b.stride = t.Weight()
b.maxweight = t.Weight()
for _, v := range b.targets {
b.stride = b.gcd(b.stride, v.Weight())
// 保存目标集中最大权重值
if v.Weight() > b.maxweight {
b.maxweight = v.Weight()
}
}
// 更新当前水位
b.current = b.maxweight
// 更新当前索引位置
b.index = 0
}
func (b *Balancer) Call() error {
if len(b.targets) == 0 {
return ErrNoTarget
}
// 查找满足当前权重水位的target
i := b.index
for {
// 取得target对象
target := b.targets[i]
i++
if target.Weight() >= b.current {
target.Call()
break
}
if i == len(b.targets) {
// 重置索引、降低水位
i, b.current = 0, b.current-b.stride
if b.current <= 0 {
// 重置当前水位
b.current = b.maxweight
}
}
}
if i == len(b.targets) {
// 重置索引、降低水位
i, b.current = 0, b.current-b.stride
if b.current <= 0 {
// 重置当前水位
b.current = b.maxweight
}
}
b.index = i
return ErrSuccess
}
// 辗转相除求最大公约数
func (b *Balancer) gcd(m, n int) int {
if n == 0 {
return m
}
return b.gcd(n, m%n)
}
使用方法如下:这里创建了三个节点,权重分别是100、50、20,期望的分布是10:5:2,所以在后面的循环里打印了17次。
package main
import (
"bournex/weightbalance/balancer"
"fmt"
)
// 虚构的集群目标节点
type Target struct {
name string
weight int
}
// 虚构的执行过程
func (t Target) Call() error {
fmt.Printf("%s", t.name)
return nil
}
// 获取当前目标的权重值
func (t Target) Weight() int {
return t.weight
}
func main() {
var (
x = Target{name: "A", weight: 100}
y = Target{name: "B", weight: 50}
z = Target{name: "C", weight: 20}
b balancer.Balancer
)
if err := b.Call(); err != nil {
fmt.Println(err.Error())
}
b.AddTarget(x)
b.AddTarget(y)
for i := 0; i < 17; i++ {
b.Call()
}
fmt.Println()
b.AddTarget(z)
for i := 0; i < 17; i++ {
b.Call()
}
fmt.Println()
}
执行输出如下
# ./app
no target to run
AABAABAABAABAABAA
AAAAAABABABABCABC
第一行打印由于还没有添加Target,所以当前集群没有可以执行任务的节点,输出error内容"no target to run"。
第二行是节点AB处理负载的情况,以AAB为模式循环处理请求。满足100:50的负载均衡需求。
第三行是添加了节点Z的结果,总共输出17次,A10次,B5次,C2次
作为对比,如果采用1替换gcd作为步长实现IWRR,则它的模式是这样的:
ABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABC
ABABABABABABABABABABABABABABABABABABABABABABABABABABABABABAB
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
可以看到,C要隔很久才会再次出现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号