B站已缓存视频批量重命名python
目录
首先祝大家五一快乐
一、起因
最近手机在B站下载了30多G的电影和视频合集,以便在没网的时候看,后来又把下载的视频导出到电脑上了,不过视频文件夹全部是数字,看不到真实的视频名称,很麻烦,就想着用python给批量重命名一下。
我的代码部分仅供参考,自己使用的时候需要根据自己的文件结构分析一下,作出一些修改,不过思路还是可以参考的。
最终结果如下
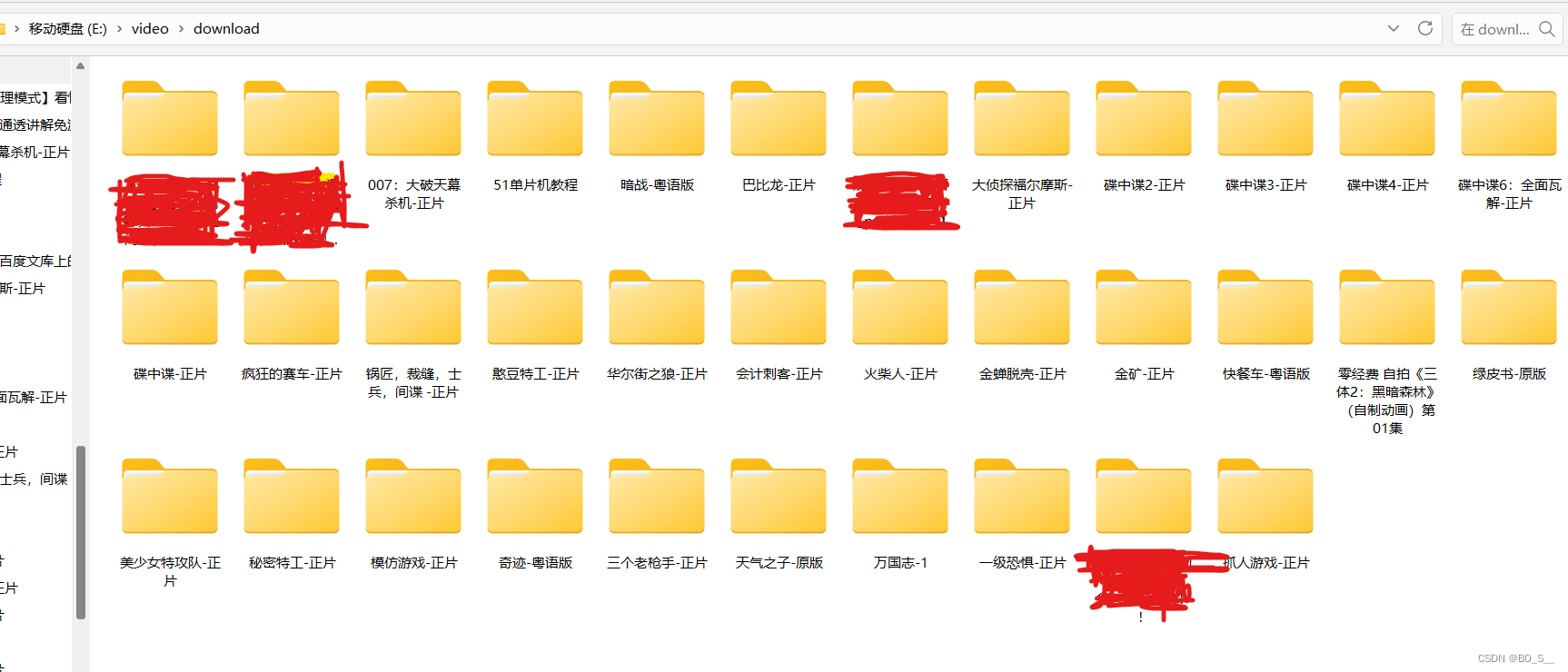
红色的是B站下载的一些UP的视频,觉得可能会没,所以就保存下来了
由于文章是修改完写的,所以修改前的图没有,只能上个手机上的图了
修改前的手机截图

二、说明
B站缓存的视频(我只有安卓手机,所以下面所说的关于手机部分均表示安卓手机)在
内部存储/Android/data/tv.danmaku.bili/download/
里面,直接把download文件夹复制到电脑
三、修改电影部分代码说明
警告:对本地文件进行操作,使用前要认真分析,因为代码执行后文件名一旦被修改,是不可逆的,如果分析错了,可能文件名就变成另一种乱码了,不过只要文件在,就还可以再用代码继续修改
1.修改普通电影文件以及文件名
import json, os def get_folder_name(rootdir="E:\\video\download\\"): """获取指定目录下的所有文件夹(不包含子文件夹)名字,并返回一个列表""" list = os.listdir(rootdir) folder_list = [] for i in range(len(list)): folder_list.append(rootdir + list[i]) print(f"已存储{len(folder_list)}个路径,例如:{folder_list[0]}") return folder_list folder_list1 = get_folder_name()# 这里我文件夹第一个是合集,所以我修改成了从1开始for i in range(1, len(folder_list1)): folder_list2 = get_folder_name(rootdir=folder_list1[i] + "\\") # 里面也包含了文件的绝对路径 folder_list3 = get_folder_name(rootdir=folder_list2[0] + "\\") try: # 先获取正确的文件名 with open(folder_list2[0] + "\\entry.json", 'r', encoding='utf-8') as f: str = json.loads(f.read()) true_name = str["title"] + "-" + str["ep"]["index"] f.close() # 修改文件名 # 先修改音频和视频名 os.rename(folder_list3[0] + "\\audio.m4s", folder_list3[0] + "\\" + true_name + ".aac") os.rename(folder_list3[0] + "\\video.m4s", folder_list3[0] + "\\" + true_name + ".flv") # 最后修改文件夹名 os.rename(folder_list1[i], "E:\\video\\download\\" + true_name) except: pass
2.修改合集文件
# 修改文件要注意,真实文件名不包含绝对路径,使用时要注意# 警告:系统文件操作需谨慎,一旦错误可能丢失文件# 提示:为避免意外发生,修改文件部分已注释掉,根据使用情况自行修改import json, os def get_folder_list(rootdir="E:\\video\download\\合集1\\"): """获取指定目录下的所有文件夹(不包含子文件夹)以及文件名字,并返回一个列表""" dbtype_list = os.listdir(rootdir) folder_list = [] for i in range(len(dbtype_list)): folder_list.append(rootdir + dbtype_list[i]) print(f"已存储{len(folder_list)}个路径,例如:{folder_list[0]}") return folder_list def get_new_filename(folder_list): """打开指定路径列表下的entry.json文件并读取page_data""" real_name_list = [] for i in range(len(folder_list)): with open(folder_list[i] + "\\entry.json", 'r', encoding='utf-8') as f: str = json.loads(f.read()) real_name_list.append(str['page_data']['download_subtitle']) f.close() print(f'获取了{len(real_name_list)}个真实文件名,例如:{real_name_list[0]}') return real_name_list def renamefiles(folder_list,real_name_list): """重命名文件为正确的名字,参数分别为路径列表(视频文件目录的上一级目录),真实文件名列表""" """1这一块用来重命名视频合集,合集内有很多文件,每个视频都有视频文件和声音文件,先注释掉""" # for i in range(len(folder_list)): # rootf = folder_list[i] + "\\64\\" # old_name1 = rootf + "video.m4s" # old_name2 = rootf + "audio.m4s" # new_name1 = rootf + real_name_list[i] + ".flv" # new_name2 = rootf + real_name_list[i] + ".aac" # os.rename(old_name1,new_name1) # os.rename(old_name2,new_name2) print("合集重命名完成") """2这部分用来重命名非合集文件的单个文件夹,可能会报错,不建议使用这部分代码""" # for i in range(len(folder_list)): # old_name = folder_list[i] # new_name = real_name_list[i] # # if old_name != new_name: # # os.rename(old_name,new_name) # print("文件夹重命名完成")if __name__ == "__main__": """注意,真实文件名不带绝对路径,使用时请自行添加""" folderlist = get_folder_list() realname = get_new_filename(folderlist) #renamefiles(folderlist,realname)
四、分析
这两部分代码有很多共同之处,主要代码如下:
1.获取指定目录下的文件和文件夹列表
folder_list = os.listdir(path)
如果只想要文件夹名称,不要文件名称,可医用os.path.isdir(path)来判断,当然,在这个程序里面我没有使用这个判断,而是直接获取了目录和文件名,这样方便地打开指定文件读取文件内容。
2.获取视频文件的真实名称
with open(folder_list[i] + "\\entry.json", 'r', encoding='utf-8') as f: str = json.loads(f.read()) real_name_list.append(str['page_data']['download_subtitle']) f.close()
这个表示打开文件夹里面的 entry.json 文件,因为B站的视频真实名就存放在里面,我需要把它读取出来,并修改视频和音频文件名。
代码里面的
str = json.loads(f.read())
f.read() 表示读取文件 f 的所有内容。若 f 是一个已经打开的文件对象,那么这一行代码会将文件指针移到文件的开头,然后返回文件的所有内容,即一个字符串。
json.loads() 则是将 JSON 格式的字符串转换为 Python 中的数据结构。其中,json 是 Python 标准库中的一个模块,提供了许多处理 JSON 数据的方法,例如 loads() 方法就是将 JSON 字符串解析成 Python 对象的方法。
3.修改文件名
os.rename(old_name,new_name)
old_name和new_name分别表示想要修改的文件路径,想要修改成新名称的文件路径,注意两个都是路径,都是字符串,在字符串里面要使用转义字符两个\\才能表示一个\。一般来说修改后文件跟源文件是在同一个路径下,如果不同,就会把修改名称后的文件移动到你所指定的路径下,如果new_name只包含名称,则会移动到当前python文件目录下。
五、总结
先获取目录,再获取真实名称,再对文件进行重命名,注意路径
运行代码前要检查代码是否正确,根据自己的文件结构进行修改,必要时检查一下自己的json文件,看看里面的结构是怎么样的。
希望能对大家有所帮助吧,我也只是一个初学者,记录一下自己的学习过程,锻炼自己解决实际问题的能力。
2023.12.11更新B站客户端解码
B站windows客户端视频解码
import osimport json # 只获取文件夹的列表,已排除单个文件 def get_folder_list(rootdir): return [os.path.join(rootdir, name) for name in os.listdir( rootdir) if os.path.isdir(os.path.join(rootdir, name))] def fix_m4s(target_path: str, output_path: str, bufsize: int = 256*1024*1024) -> None: assert bufsize > 0 with open(target_path, 'rb') as target_file: header = target_file.read(32) new_header = header.replace(b'000000000', b'') new_header = new_header.replace(b'$', b' ') new_header = new_header.replace(b'avc1', b'') with open(output_path, 'wb') as output_file: output_file.write(new_header) i = target_file.read(bufsize) while i: output_file.write(i) i = target_file.read(bufsize) folderList = get_folder_list("D:/Video/bilibili/")exist_transed_folder_list = get_folder_list("D:/Video/Trans/") # 获取所有已转换的文件的文件名exist_transed_video_list = [os.path.splitext(f)[0] for folder in exist_transed_folder_list for f in os.listdir( folder) if f.endswith('.mp3') or f.endswith('.mp4')] count = 0 # 计数用all = len(folderList) - len(exist_transed_folder_list)for folder in folderList: print(folder) # 当前操作的目录 # 找到所有的m4s文件 m4s_files = [folder+'/' + file for file in os.listdir(folder) if file.endswith('.m4s')] # 读取videoinfo信息 with open(folder+'/.videoInfo', 'r', encoding='utf-8') as f: videoinfo = json.loads(f.read()) bvid = videoinfo["bvid"] p = videoinfo["p"] tabName = videoinfo["tabName"] output_dir = "D:/Video/Trans/" + bvid if not os.path.exists(output_dir): os.makedirs(output_dir) elif output_dir in exist_transed_folder_list: continue fix_m4s(m4s_files[0], output_dir + '/' + str(p) + '_' + tabName + '.mp4') fix_m4s(m4s_files[1], output_dir + '/' + str(p) + '_' + tabName + '.mp3')
核心代码是下面这三行,就是把.m4s文件以二进制形式打开,然后把开头的9个0删除,把$替换成空格,把avc1删除,方法是在B站视频看到的,核心代码是评论区的,我加工了一下。
# 核心代码new_header = header.replace(b'000000000', b'')new_header = new_header.replace(b'$', b' ')new_header = new_header.replace(b'avc1', b'')
文章知识点与官方知识档案匹配,可进一步学习相关知识
Python入门技能树首页概览415980 人正在系统学习中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号