Linux内核学习——进程管理
Linux 内核源码版本:6.6LTS
进程和程序
- 程序可以理解为数据结构+算法,是一堆指令集合
- 进程是一段执行中的程序
- 进程是操作系统分配cpu、内存等资源的基本单位
- 进程是用来实现多进程并发执行的一个实体,实现对CPU 的虚拟化,让每个进程都感觉拥有一个CPU。实现这个CPU虚拟化的核心技术是上下文切换以及进程调度。
进程结构体
进程是操作系统中调度的一个实体,需要对进程所必须拥有的资源做一个抽象,这个抽象描述称为进程控制块(Process Control Block,PCB)。这些信息包括:
- 进程的运行状态
- 程序计数器:记录当前进程运行到哪条指令
- CPU寄存器:主要是为了保存当前运行的上下文
- CPU调度信息
- 内存管理信息
- 统计信息
- 文件相关信息
在Linux内核中,使用struct task_struct数据结构描述进程控制块,使用task_list链表来保存所有进程描述符,task_struct定义在include/linux/sched.h。
task_struct数据结构很大,内容大致分成以下几类:
- 进程的属性
- 进程之间的关系
- 进程调度相关信息
- 内存相关信息
- 文件管理相关信息
- 信号相关信息
- 资源限制相关信息
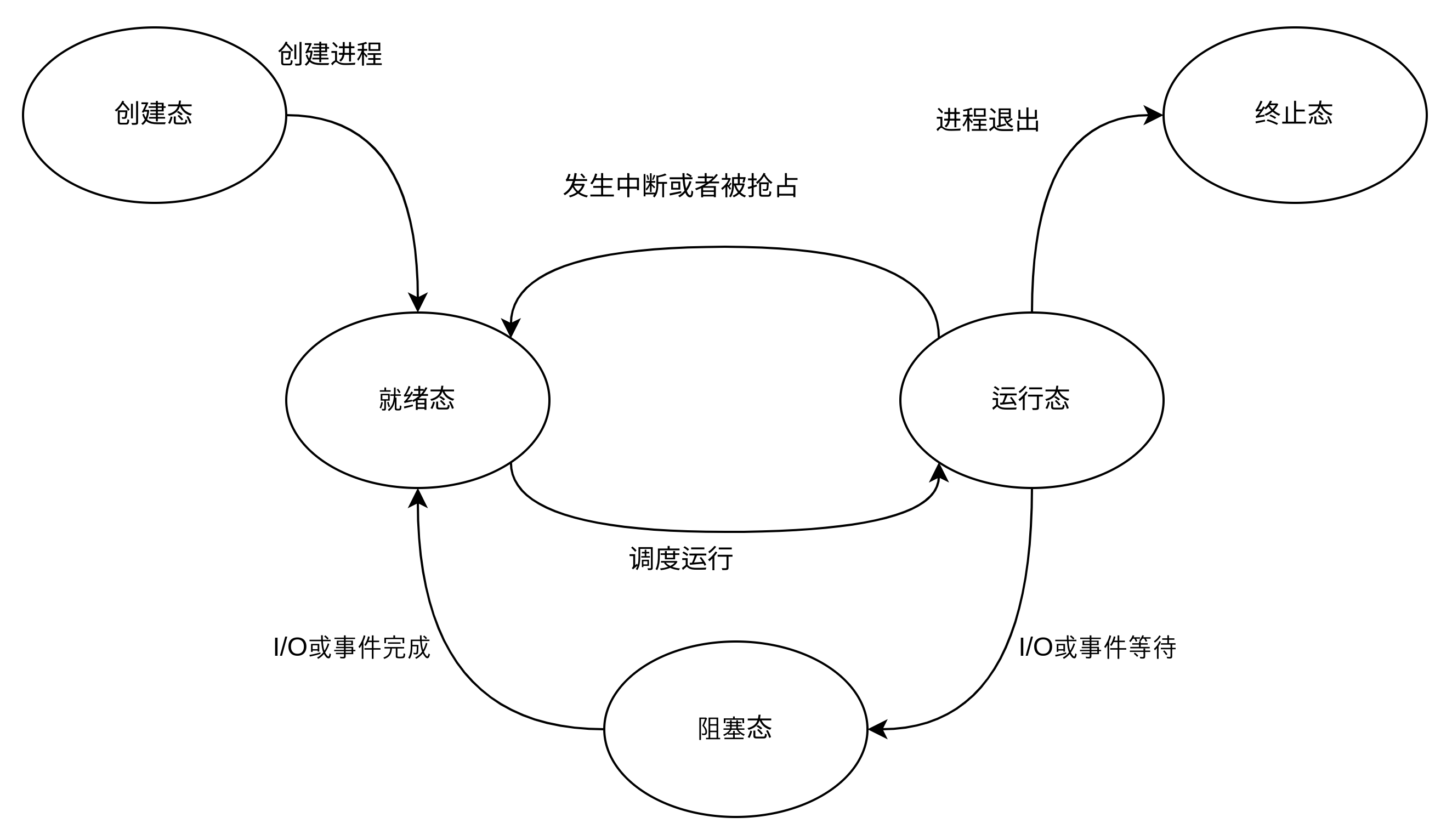
一个典型的进程状态:
写时复制:
写时复制(copy on write,COW)技术就是父进程在创建子进程时,不需要复制进程地址空间的内容给子进程,只需要复制父进程的进程地址空间的页表给子进程,这样父子进程就共享了相同的地址空间。当父子进程有一方需要修改某个物理页面的内容时,会发生写保护的缺页异常,然后才把共享页面的内容复制出来,从而让父子进程拥有各自的副本。
进程的创建
使用fork函数创建子进程,子进程会从父进程那里继承整个进程地址空间,包括进程上下文、进程堆栈、内存信息、打开的文件描述符、进程优先级、根目录、资源限制、控制终端等。
子进程和父进程又有以下区别:
- PID不一样
- 子进程不会继承父进程的内存方面的锁,比如mlock
- 子进程不会继承父进程的一些定时器,比如setitimer、alarm、timer_create
在比较新的内核(6.6LTS)中,fork、vfork、clone系统调用定义:
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
struct kernel_clone_args args = {
.exit_signal = SIGCHLD,
};
return kernel_clone(&args);
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
SYSCALL_DEFINE0(vfork)
{
struct kernel_clone_args args = {
.flags = CLONE_VFORK | CLONE_VM,
.exit_signal = SIGCHLD,
};
return kernel_clone(&args);
}
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
{
struct kernel_clone_args args = {
.flags = (lower_32_bits(clone_flags) & ~CSIGNAL),
.pidfd = parent_tidptr,
.child_tid = child_tidptr,
.parent_tid = parent_tidptr,
.exit_signal = (lower_32_bits(clone_flags) & CSIGNAL),
.stack = newsp,
.tls = tls,
};
return kernel_clone(&args);
}
他们最终都是调用kernel_clone,通过传入的不同参数区别。
clong-flags标志位定义在include/uapi/linux/sched.h:
/*
* cloning flags:
*/
#define CSIGNAL 0x000000ff /* signal mask to be sent at exit */
#define CLONE_VM 0x00000100 /* set if VM shared between processes */
#define CLONE_FS 0x00000200 /* set if fs info shared between processes */
#define CLONE_FILES 0x00000400 /* set if open files shared between processes */
#define CLONE_SIGHAND 0x00000800 /* set if signal handlers and blocked signals shared */
#define CLONE_PIDFD 0x00001000 /* set if a pidfd should be placed in parent */
#define CLONE_PTRACE 0x00002000 /* set if we want to let tracing continue on the child too */
#define CLONE_VFORK 0x00004000 /* set if the parent wants the child to wake it up on mm_release
在创建子进程时启用linux内核的完成机制。wait_for_completion()会使父进程进入睡眠等待,直到子进程调用execv或exit释放虚拟内存资源 */
#define CLONE_PARENT 0x00008000 /* set if we want to have the same parent as the cloner */
#define CLONE_THREAD 0x00010000 /* Same thread group? */
#define CLONE_NEWNS 0x00020000 /* New mount namespace group */
#define CLONE_SYSVSEM 0x00040000 /* share system V SEM_UNDO semantics */
#define CLONE_SETTLS 0x00080000 /* create a new TLS for the child */
#define CLONE_PARENT_SETTID 0x00100000 /* set the TID in the parent */
#define CLONE_CHILD_CLEARTID 0x00200000 /* clear the TID in the child */
#define CLONE_DETACHED 0x00400000 /* Unused, ignored */
#define CLONE_UNTRACED 0x00800000 /* set if the tracing process can't force CLONE_PTRACE on this clone */
#define CLONE_CHILD_SETTID 0x01000000 /* set the TID in the child */
#define CLONE_NEWCGROUP 0x02000000 /* New cgroup namespace */
#define CLONE_NEWUTS 0x04000000 /* New utsname namespace */
#define CLONE_NEWIPC 0x08000000 /* New ipc namespace */
#define CLONE_NEWUSER 0x10000000 /* New user namespace */
#define CLONE_NEWPID 0x20000000 /* New pid namespace */
#define CLONE_NEWNET 0x40000000 /* New network namespace */
#define CLONE_IO 0x80000000 /* Clone io context */
/* Flags for the clone3() syscall. */
#define CLONE_CLEAR_SIGHAND 0x100000000ULL /* Clear any signal handler and reset to SIG_DFL. */
#define CLONE_INTO_CGROUP 0x200000000ULL /* Clone into a specific cgroup given the right permissions. */
/*
* cloning flags intersect with CSIGNAL so can be used with unshare and clone3
* syscalls only:
*/
#define CLONE_NEWTIME 0x00000080 /* New time namespace */
进程的产生有多种方式,基本过程:
- 首先复制其父进程的环境配置
- 在内核中建立进程结构
- 将结构插入到进程列表
- 分配资源给此进程
- 复制父进程的内存映射信息
- 管理文件描述符和链接点
- 通知父进程
内核线程
内核线程(Kernel Thread)其实就是独立运行在内核空间的进程,它和普通用户进程的区别在于内核线程没有独立的进程地址空间,它只能运行在内核空间,和普通进程一样参与到系统的调度中。
进程的终止
进程终止有两种方式:
- 主动终止
- 从main函数返回,链接程序会自动添加对exit的系统调用
- 主动调用exit系统调用(包括
exit/_exit/abort)
- 被动终止
- 收到一个自己不能处理的信号
- 在内核态执行时产生了一个异常
- 收到SIGKILL等终止信号
孤儿进程
参考 孤儿进程与僵尸进程
僵尸进程
参考 孤儿进程与僵尸进程
进程的出生和演化
0号进程
进程0是指Linux内核初始化阶段从无到有创建的一个内核线程,他是所有进程的祖先,其是通过静态变量init_task预先设置好的init/init_task.c:
/*
* Set up the first task table, touch at your own risk!. Base=0,
* limit=0x1fffff (=2MB)
*/
struct task_struct init_task
#ifdef CONFIG_ARCH_TASK_STRUCT_ON_STACK
__init_task_data
#endif
__aligned(L1_CACHE_BYTES)
= {
#ifdef CONFIG_THREAD_INFO_IN_TASK
.thread_info = INIT_THREAD_INFO(init_task),
.stack_refcount = REFCOUNT_INIT(1),
#endif
.__state = 0,
.stack = init_stack,
.usage = REFCOUNT_INIT(2),
.flags = PF_KTHREAD,
.prio = MAX_PRIO - 20,
.static_prio = MAX_PRIO - 20,
.normal_prio = MAX_PRIO - 20,
.policy = SCHED_NORMAL,
.cpus_ptr = &init_task.cpus_mask,
.user_cpus_ptr = NULL,
.cpus_mask = CPU_MASK_ALL,
.nr_cpus_allowed= NR_CPUS,
.mm = NULL,
.active_mm = &init_mm,
.restart_block = {
.fn = do_no_restart_syscall,
},
.se = {
.group_node = LIST_HEAD_INIT(init_task.se.group_node),
},
.rt = {
.run_list = LIST_HEAD_INIT(init_task.rt.run_list),
.time_slice = RR_TIMESLICE,
},
.tasks = LIST_HEAD_INIT(init_task.tasks),
#ifdef CONFIG_SMP
.pushable_tasks = PLIST_NODE_INIT(init_task.pushable_tasks, MAX_PRIO),
#endif
#ifdef CONFIG_CGROUP_SCHED
.sched_task_group = &root_task_group,
#endif
.ptraced = LIST_HEAD_INIT(init_task.ptraced),
.ptrace_entry = LIST_HEAD_INIT(init_task.ptrace_entry),
.real_parent = &init_task,
.parent = &init_task,
.children = LIST_HEAD_INIT(init_task.children),
.sibling = LIST_HEAD_INIT(init_task.sibling),
.group_leader = &init_task,
RCU_POINTER_INITIALIZER(real_cred, &init_cred),
RCU_POINTER_INITIALIZER(cred, &init_cred),
.comm = INIT_TASK_COMM,
.thread = INIT_THREAD,
.fs = &init_fs,
.files = &init_files,
#ifdef CONFIG_IO_URING
.io_uring = NULL,
#endif
.signal = &init_signals,
.sighand = &init_sighand,
.nsproxy = &init_nsproxy,
.pending = {
.list = LIST_HEAD_INIT(init_task.pending.list),
.signal = {{0}}
},
.blocked = {{0}},
.alloc_lock = __SPIN_LOCK_UNLOCKED(init_task.alloc_lock),
.journal_info = NULL,
INIT_CPU_TIMERS(init_task)
.pi_lock = __RAW_SPIN_LOCK_UNLOCKED(init_task.pi_lock),
.timer_slack_ns = 50000, /* 50 usec default slack */
.thread_pid = &init_struct_pid,
.thread_group = LIST_HEAD_INIT(init_task.thread_group),
.thread_node = LIST_HEAD_INIT(init_signals.thread_head),
#ifdef CONFIG_AUDIT
.loginuid = INVALID_UID,
.sessionid = AUDIT_SID_UNSET,
#endif
#ifdef CONFIG_PERF_EVENTS
.perf_event_mutex = __MUTEX_INITIALIZER(init_task.perf_event_mutex),
.perf_event_list = LIST_HEAD_INIT(init_task.perf_event_list),
#endif
#ifdef CONFIG_PREEMPT_RCU
.rcu_read_lock_nesting = 0,
.rcu_read_unlock_special.s = 0,
.rcu_node_entry = LIST_HEAD_INIT(init_task.rcu_node_entry),
.rcu_blocked_node = NULL,
#endif
#ifdef CONFIG_TASKS_RCU
.rcu_tasks_holdout = false,
.rcu_tasks_holdout_list = LIST_HEAD_INIT(init_task.rcu_tasks_holdout_list),
.rcu_tasks_idle_cpu = -1,
.rcu_tasks_exit_list = LIST_HEAD_INIT(init_task.rcu_tasks_exit_list),
#endif
#ifdef CONFIG_TASKS_TRACE_RCU
.trc_reader_nesting = 0,
.trc_reader_special.s = 0,
.trc_holdout_list = LIST_HEAD_INIT(init_task.trc_holdout_list),
.trc_blkd_node = LIST_HEAD_INIT(init_task.trc_blkd_node),
#endif
#ifdef CONFIG_CPUSETS
.mems_allowed_seq = SEQCNT_SPINLOCK_ZERO(init_task.mems_allowed_seq,
&init_task.alloc_lock),
#endif
#ifdef CONFIG_RT_MUTEXES
.pi_waiters = RB_ROOT_CACHED,
.pi_top_task = NULL,
#endif
INIT_PREV_CPUTIME(init_task)
#ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN
.vtime.seqcount = SEQCNT_ZERO(init_task.vtime_seqcount),
.vtime.starttime = 0,
.vtime.state = VTIME_SYS,
#endif
#ifdef CONFIG_NUMA_BALANCING
.numa_preferred_nid = NUMA_NO_NODE,
.numa_group = NULL,
.numa_faults = NULL,
#endif
#if defined(CONFIG_KASAN_GENERIC) || defined(CONFIG_KASAN_SW_TAGS)
.kasan_depth = 1,
#endif
#ifdef CONFIG_KCSAN
.kcsan_ctx = {
.scoped_accesses = {LIST_POISON1, NULL},
},
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
.softirqs_enabled = 1,
#endif
#ifdef CONFIG_LOCKDEP
.lockdep_depth = 0, /* no locks held yet */
.curr_chain_key = INITIAL_CHAIN_KEY,
.lockdep_recursion = 0,
#endif
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
.ret_stack = NULL,
.tracing_graph_pause = ATOMIC_INIT(0),
#endif
#if defined(CONFIG_TRACING) && defined(CONFIG_PREEMPTION)
.trace_recursion = 0,
#endif
#ifdef CONFIG_LIVEPATCH
.patch_state = KLP_UNDEFINED,
#endif
#ifdef CONFIG_SECURITY
.security = NULL,
#endif
#ifdef CONFIG_SECCOMP_FILTER
.seccomp = { .filter_count = ATOMIC_INIT(0) },
#endif
};
EXPORT_SYMBOL(init_task);
start_kernel()上来就会运行 set_task_stack_end_magic(&init_task)创建初始进程。init_task是静态定义的一个进程,也就是说当内核被放入内存时,它就已经存在,它没有自己的用户空间,一直处于内核空间中运行,并且也只处于内核空间运行。
void start_kernel(void)
{
char *command_line;
char *after_dashes;
set_task_stack_end_magic(&init_task);
...
}
1号进程
1号进程kernel_init是在内核初始化的后期,通过rest_init函数新建:
// init/main.c
void start_kernel(void)
{
...
/* Do the rest non-__init'ed, we're now alive */
arch_call_rest_init();
...
}
// init/main.c
void __init __weak __noreturn arch_call_rest_init(void)
{
rest_init();
}
// init/main.c
noinline void __ref __noreturn rest_init(void)
{
struct task_struct *tsk;
int pid;
rcu_scheduler_starting();
/*
* We need to spawn init first so that it obtains pid 1, however
* the init task will end up wanting to create kthreads, which, if
* we schedule it before we create kthreadd, will OOPS.
*/
pid = user_mode_thread(kernel_init, NULL, CLONE_FS);
...
}
最后调用 kernel_clone创建
// kernel/fork.c
/*
* Create a user mode thread.
*/
pid_t user_mode_thread(int (*fn)(void *), void *arg, unsigned long flags)
{
struct kernel_clone_args args = {
.flags = ((lower_32_bits(flags) | CLONE_VM |
CLONE_UNTRACED) & ~CSIGNAL),
.exit_signal = (lower_32_bits(flags) & CSIGNAL),
.fn = fn,
.fn_arg = arg,
};
return kernel_clone(&args);
}
2号进程
2号进程kthreadd是内核创建完1号进程后,内核通过kernel_thread创建出来的:
// init/main.c
noinline void __ref __noreturn rest_init(void)
{
...
pid = kernel_thread(kthreadd, NULL, NULL, CLONE_FS | CLONE_FILES);
...
}
0号进程演变为idle
在创建完1号和2号进程后,0号进程最终走到了do_idle
// init/main.c
noinline void __ref __noreturn rest_init(void)
{
...
/*
* The boot idle thread must execute schedule()
* at least once to get things moving:
*/
schedule_preempt_disabled();
/* Call into cpu_idle with preempt disabled */
cpu_startup_entry(CPUHP_ONLINE);
}
void cpu_startup_entry(enum cpuhp_state state)
{
current->flags |= PF_IDLE;
arch_cpu_idle_prepare();
cpuhp_online_idle(state);
while (1)
do_idle();
}
进程调度
Scheduler
进程可以分为两类:
- CPU消耗型(CPU-Bound)
- I/O消耗型(I/O-Bound)
调度器有必要在系统吞吐率和系统响应性方面作出一些妥协和平衡。
进程优先级
进程的优先级在task_struct数据结构中使用以下几个成员描述:
struct task_struct {
...
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
...
}
- static_prio:静态优先级,在进程启动时分配,可以通过nice或者sched_setscheduler等系统调用修改它
- normal_prio:基于static_prio和调度策略计算出来的优先级,在创建进程时继承父进程的normal_prio。对于普通进程,normal_prio等同于static_prio;对于实时进程,会根据rt_priority重新计算
- prio:保存进程的动态优先级,是调度类考虑的优先级
- rt_priority:实时进程的优先级
普通进程优先级:100-139
实时进程优先级:0-99
Deadline进程优先级:-1
时间片
时间片表示进程在被抢占和调度之前所能持续运行的时间。
调度算法
经典调度算法
多级反馈队列(Multi-level Feedback Queue, MLFQ)算法。
Linux \(O(n)\)调度算法
Linux \(O(1)\)调度算法
Linux CFS调度算法
EEVDF调度算法
“Earliest Eligible Virtual Deadline First” (EEVDF)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号