
numpy基础操作2
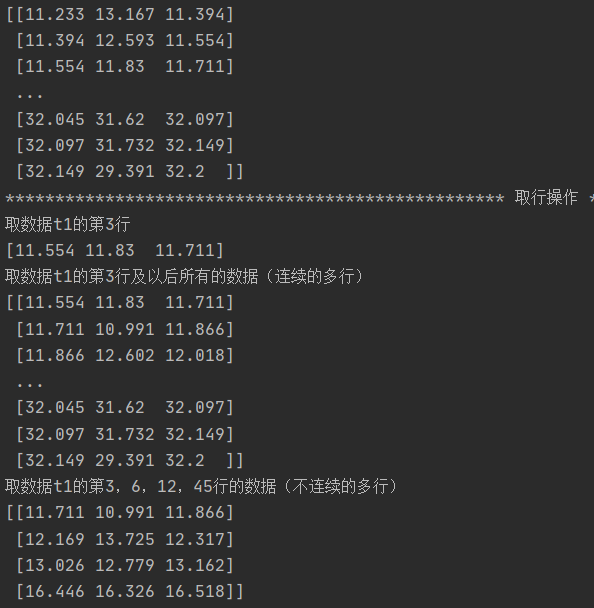
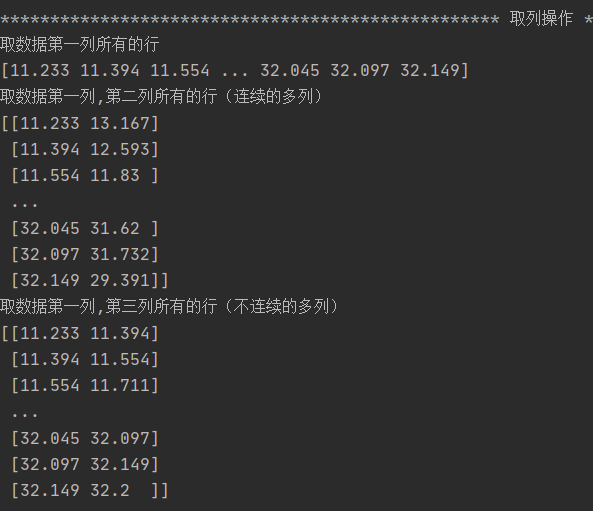
data_path = './data.csv' t1 = np.loadtxt(data_path,delimiter=',',skiprows=1) t2 = np.loadtxt(data_path, delimiter=',',skiprows=1,unpack=True) #unpack=True表示把原数据转置 print(t1) # print("*"*50,'转置后',"*"*50) # print(t2) #索引和切片 print("*" * 50, '取行操作', "*" * 50) print('取数据t1的第3行') print(t1[2]) print('取数据t1的第3行及以后所有的数据(连续的多行)') print(t1[2:]) print('取数据t1的第3,6,12,45行的数据(不连续的多行)') print(t1[[3,6,12,45]]) print("*" * 50, '取列操作', "*" * 50) print('取数据第一列所有的行') print(t1[:,0]) print('取数据第一列,第二列所有的行(连续的多列)') print(t1[:, 0:2]) print('取数据第一列,第三列所有的行(不连续的多列)') print(t1[:, [0,2]])
data_path = './data.csv' t1 = np.loadtxt(data_path,delimiter=',',skiprows=1) print(t1) print('********************把大于12的值替换成100******************') t1[t1>12] = 100 print(t1) print('********************把大于12的值替换成100,小于12的替换成0 ******************') t3 = np.where(t1>12,100,0) print(t3)
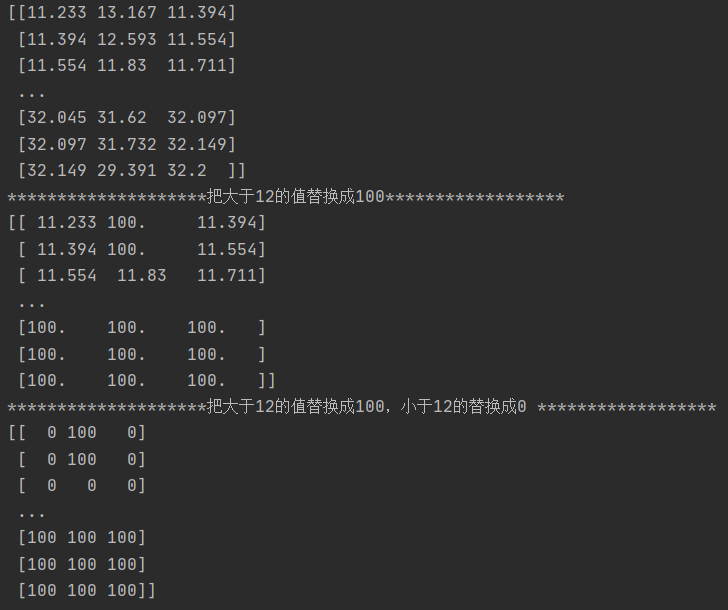
print('********************把大于15的值替换成15,小于12的替换成12 ******************') t3.clip(12,15) print(t3)
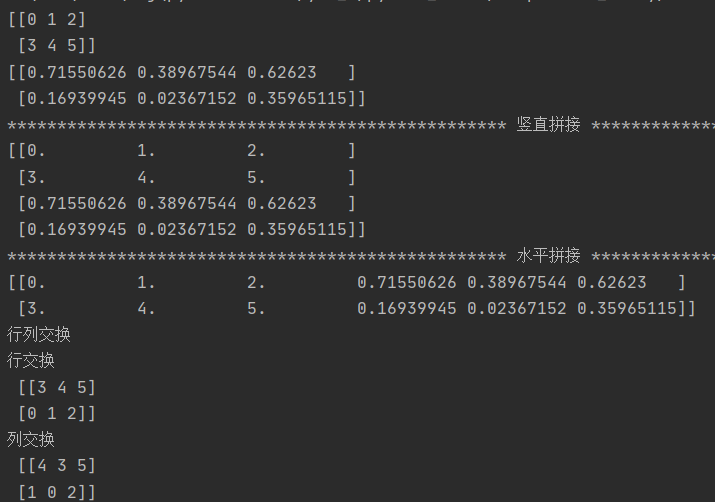
数组的拼接:
竖直拼接(vertically stack)和水平拼接(horizontally stack)
数组的行列交换:
a1 = np.arange(6).reshape(2,3) a2 = np.array([random.random() for i in range(6)]).reshape(2,3) print(a1) print(a2) print('*'*50,'竖直拼接','*'*50) a3 = np.vstack((a1,a2)) #竖直拼接,a1在上a2在下 print(a3) print('*' * 50, '水平拼接', '*' * 50) a4 = np.hstack((a1,a2)) print(a4) print('行列交换') a1[[0,1],:] = a1[[1,0],:] print('行交换\n',a1) a1[:,[0,1]] = a1[:,[1,0]] print('列交换\n', a1)
做一个练习题:

#加载数据集 US_PATH = './youtube_video_data/US_video_data_numbers.csv' GB_PATH = './youtube_video_data/GB_video_data_numbers.csv' US_DATA = np.loadtxt(US_PATH,delimiter=',',dtype=int) GB_DATA = np.loadtxt(GB_PATH,delimiter=',',dtype=int) #添加国家信息0表示美国,1表示英国 Zeros = np.zeros((US_DATA.shape[0],1)).astype(int) #把他转化为int类型,US_DATA.shape[0]行,1列 Ones = np.ones((GB_DATA.shape[0],1)).astype(int)##把他转化为int类型,GB_DATA.shape[0]行,1列 US_DATA = np.hstack((Zeros,US_DATA)) GB_DATA = np.hstack((Ones,GB_DATA)) #合并两个国家的数据 hebing_data = np.vstack((US_DATA,GB_DATA)) #打印验证 print(hebing_data) print(hebing_data.shape[0])
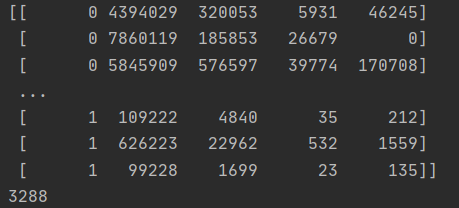
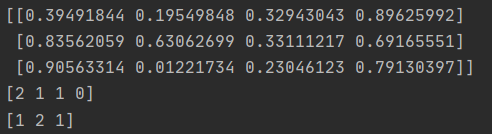
按照给定的轴的方向求出最大值和最小值的位置:
#给出最大值和最小值的位置 b1 = np.array([random.random() for i in range(12)]).reshape(3,4) print(b1) print(np.argmax(b1,axis=0)) print(np.argmin(b1,axis=1))
使用Numpy产生随机数
#使用Numpy产生随机数 #产生正数的随机数 t1 = np.random.randint(10,20,(4,5)) #产生10~20之间的随机正数,形状是4行5列 print(t1) t2 = np.random.uniform(10,20,(4,5)) #这个和randint唯一的区别就是这个产生的是小数 print(t2)
使用numpy随机种子,他的作用是保证每次产生的随机数又是一样的
#使用numpy随机种子,他的作用是保证每次产生的随机数又是一样的 np.random.seed(10) t1 = np.random.randint(10,20,(2,4)) print(t1)
copy()的作用:
np.random.seed(10) t1 = np.random.randint(10,20,(2,4)) t2 = t1 #t1变化t2就会变化 t3 = t1.copy()#t3和t1是相互独立

 浙公网安备 33010602011771号
浙公网安备 33010602011771号