

数据预处理--StandardScaler()
- 定义
sklearn中的StandardScaler()主要是去均值标准化,也就是均值为0,标准差为1的数据标准化处理。
均值公式:![]()
标准差公式:![]()
下面利用python实现一下:
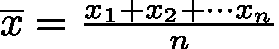
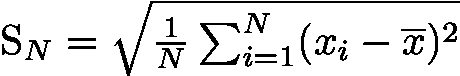
点击查看代码
import pandas as pd
from sklearn.preprocessing import StandardScaler
import numpy as np
data = np.array([[1, 2], [4, 4]])
mean = data.mean(axis=0)
move_mean = data-mean
std = np.std(data,axis=0)
score = move_mean / std
data
array([[1, 2],
[4, 4]])
mean
array([2.5, 3. ])
move_mean
array([[-1.5, -1. ],
[ 1.5, 1. ]])
std
array([1.5, 1. ])
score
array([[-1., -1.],
[ 1., 1.]])
- 使用sklearn标准库计算
点击查看代码
ss = StandardScaler()
ss.fit_transform(data)
- 验证一下
数据标准化有一个特性,就是新生成的数据的均值为0,标准方差为1
点击查看代码
new_data = ss.fit_transform(data)
new_data.mean(axis=0)
array([0., 0.])
np.std(new_data,axis=0)
array([1., 1.])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号