
LPF: A Language-Prior Feedback Objective Function forDe-biased Visual Question Answering
LPF: A Language-Prior Feedback Objective Function forDe-biased Visual Question Answering
相关工作
作者介绍了之前消除语言偏见模型,其主要分为两种:
- annotation-based methods
- non-annotation-based methods
前者需要大量的人工标注,并且最近的实验证明其精确度的提升仅仅来源于正则化的效果而不是恰当的视觉基础。后者则是通过一个纯问题的分支网络的训练进一步规范化模型,现有两种主要的方法:
- adversary-based(训练纯问题分支以防止问题编码器在对抗训练中捕获不需要的语言先验)
- ensemble-based(集成两个模型的预测,根据融合答案分布来进行训练)
作者认为,就算是比较小的损失,大量的累积起来一样会造成较大的损失,因此在进行消除语言偏见时应当重新平衡每个答案在总的VQA中,而不是简单的增加或减小每次的损失。
作者创新点及其贡献
创新点
作者通过纯问题分支网络或得语言偏见,根据语言的偏见在主网络中为每个训练样本分配动态权重,实现消除语言偏见的效果
贡献
- 作者所提出的语言先验反馈目标函数(LPF),当从不平衡的VQA数据集中学习时,该函数能自动将训练损失调整为一个平衡形式,并提出一个通用框架,利用纯问题分支计算不同答案的动态权重。
- 在VQA-CP v2数据集中强于基线网络,并能与当前最新的网络进行竞争。
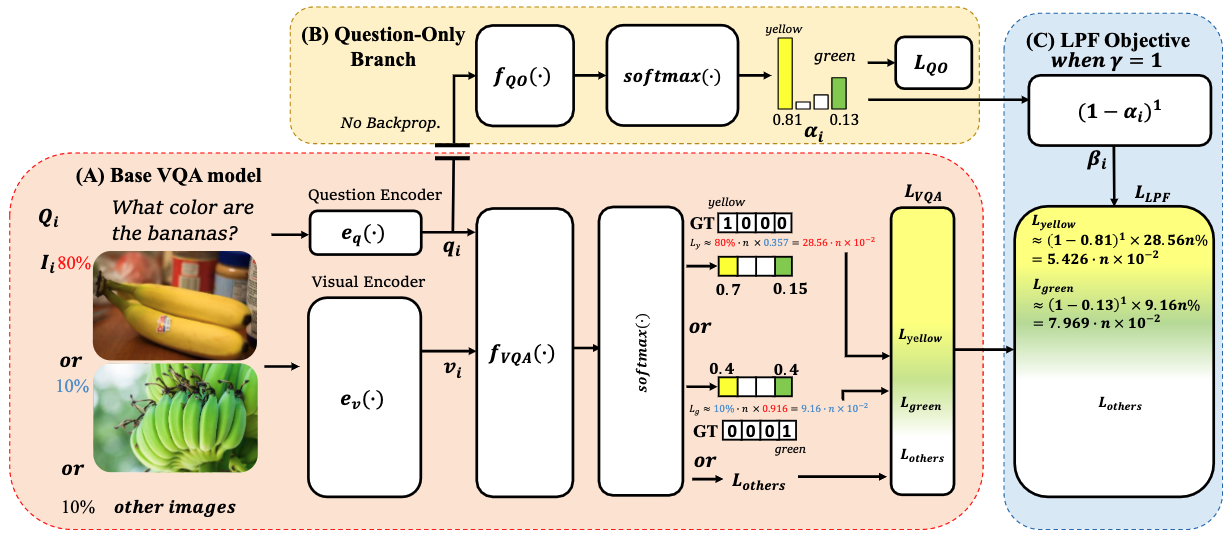
模型
通常VQA模型的损失函数
\[L_{QO}=-\frac{1}{N}∑_{i=1}^{N}log(softmax(f_{VQA}(v_i,q_i)))[a_i]
\]
纯问题模型
作者将经过LSTM或GRU等的问题编码器生成的问题嵌入经过由MLP层组成的网络得到文本偏见。
损失函数如下:
\[L_{QO}=-\frac{1}{N}∑_{i=1}^{N}log(softmax(f_{QO}(q_i)))[a_i]
\]
重塑VQA目标函数减少语言偏见
根据人工标记真实的答案和纯问题模型的softmax层输出计算\(a_i\)
\[a_i=softmax(f_{QO}(q_i))[a_i]=\frac{exp(f_{QO}(q_i))[a_i]}{∑_{j=1}^{|A|}exp(f_{QO}(q_i))[a_j]}
\]
通过\(a_i\)计算出形式化调制因子\(\beta_i\),其中\(\gamma\)为超参数:
\[\beta_i=(1-a_i)^\gamma,\gamma\geq0
\]
最后通过调制因子\(\beta_i\)控制损失函数的权重:
\[L_{LPF}=-\frac{1}{N}∑_{i=1}^{N}\beta_ilog(softmax(f_{VQA}(v_i,q_i)))[a_i]
\]
如下图所示,如果仅通过纯问题模型进行计算出来的答案,其\(a_i\)比较大,因此其\(\beta_i\)较小,使得其减小\(L_{LPF}\)的权重。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号