Self Organizing Maps (SOM): 一种基于神经网络的聚类算法,本质上感觉和kmeans迭代没啥区别
自组织映射神经网络本质上是一个两层的神经网络,包含输入层和输出层(竞争层)。输入层模拟感知外界输入信息的视网膜,输出层模拟做出响应的大脑皮层。输出层中神经元的个数通常是聚类的个数,代表每一个需要聚成的类。训练时采用“竞争学习”的方式,每个输入的样例在输出层中找到一个和它最匹配的节点,称为激活节点,也叫winningneuron;紧接着用随机梯度下降法更新激活节点的参数;同时,和激活节点临近的点也根据它们距离激活节点的远近而适当地更新参数。这种竞争可以通过神经元之间的横向抑制连接(负反馈路径)来实现。
使用SOM进行flower聚类:见https://blog.csdn.net/okfu_DL/article/details/88796838 效果:
迭代1000轮,放上结果图![在这里插入图片描述]()

可见,分类效果已经初步达到。后期提高效果可以选择更好的CNN模型提取特征,或者多个CNN模型做特征融合。适当的调整学习率和迭代轮次,应该可以进一步提升分类结果。
如下部分转自:https://www.cnblogs.com/sylvanas2012/p/5117056.html
自组织映射神经网络, 即Self Organizing Maps (SOM), 可以对数据进行无监督学习聚类。它的思想很简单,本质上是一种只有输入层--隐藏层的神经网络。隐藏层中的一个节点代表一个需要聚成的类。训练时采用“竞争学习”的方式,每个输入的样例在隐藏层中找到一个和它最匹配的节点,称为它的激活节点,也叫“winning neuron”。 紧接着用随机梯度下降法更新激活节点的参数。同时,和激活节点临近的点也根据它们距离激活节点的远近而适当地更新参数。
所以,SOM的一个特点是,隐藏层的节点是有拓扑关系的。这个拓扑关系需要我们确定,如果想要一维的模型,那么隐藏节点依次连成一条线;如果想要二维的拓扑关系,那么就行成一个平面,如下图所示(也叫Kohonen Network):
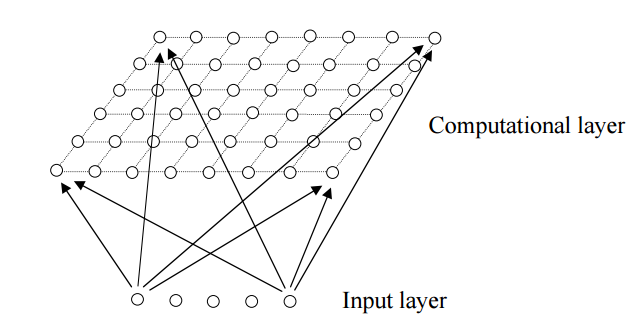
既然隐藏层是有拓扑关系的,所以我们也可以说,SOM可以把任意维度的输入离散化到一维或者二维(更高维度的不常见)的离散空间上。 Computation layer里面的节点与Input layer的节点是全连接的。
拓扑关系确定后,开始计算过程,大体分成几个部分:
1) 初始化:每个节点随机初始化自己的参数。每个节点的参数个数与Input的维度相同。
2)对于每一个输入数据,找到与它最相配的节点。假设输入时D维的, 即 X={x_i, i=1,...,D},那么判别函数可以为欧几里得距离:

3) 找到激活节点I(x)之后,我们也希望更新和它临近的节点。令S_ij表示节点i和j之间的距离,对于I(x)临近的节点,分配给它们一个更新权重:

简单地说,临近的节点根据距离的远近,更新程度要打折扣。
4)接着就是更新节点的参数了。按照梯度下降法更新:

迭代,直到收敛。
与K-Means的比较
同样是无监督的聚类方法,SOM与K-Means有什么不同呢?
(1)K-Means需要事先定下类的个数,也就是K的值。 SOM则不用,隐藏层中的某些节点可以没有任何输入数据属于它。所以,K-Means受初始化的影响要比较大。
(2)K-means为每个输入数据找到一个最相似的类后,只更新这个类的参数。SOM则会更新临近的节点。所以K-mean受noise data的影响比较大,SOM的准确性可能会比k-means低(因为也更新了临近节点)。
(3) SOM的可视化比较好。优雅的拓扑关系图 。
参考文献:http://www.cs.bham.ac.uk/~jxb/NN/l16.pdf
在生物神经系统中,存在着一种侧抑制现象,即一个神经细胞兴奋之后,会对周围其余神经细胞产生抑制做用。这种抑制做用会使神经细胞之间出现竞争,其结果是某些获胜,而另外一些则失败。表现形式是获胜神经细胞兴奋,失败神经细胞抑制。自组织(竞争型)神经网络就是模拟上述生物神经系统功能的人工神经网络[3]。
自组织(竞争型)神经网络的结构及其学习规则与其余神经网络相比有本身的特色。在网络结构上,它通常是由输入层和竞争层构成的两层网络;两层之间各神经元实现双向链接,并且网络没有隐含层。有时竞争层各神经元之间还存在横向链接(注:上面说的特色只是根据传统网络设计来讲的通常状况,随着技术发展,尤为是深度学习技术的演进,我认为这种简单的自组织网络也会有所改变,好比,变得更深,或者引入time series概念)。在学习算法上,它模拟生物神经元之间的兴奋、协调与抑制、竞争做用的信息处理的动力学原理来指导网络的学习与工做,而不像多层神经网络(MLP)那样是以网络的偏差做为算法的准则。竞争型神经网络构成的基本思想是网络的竞争层各神经元竞争对输入模式响应的机会,最后仅有一个神经元成为竞争的胜者。这一获胜神经元则表示对输入模式的分类[3]。所以,很容易把这样的结果和聚类联系在一块儿。
二、竞争学习的概念与原理
一种自组织神经网络的典型结构:以下图,由输入层和竞争层组成。主要用于完成的任务基本仍是“分类”和“聚类”,前者有监督,后者无监督。聚类的时候也能够当作将目标样本分类,只是是没有任何先验知识的,目的是将类似的样本聚合在一块儿,而不类似的样本分离。

说到这里,通常的资料都会介绍一下欧式距离和余弦类似度
欧式距离:

余弦类似度:

很容易证实,当图中X与Xi都是模为1的单位向量时(其实不必定要1,只要是常数就行),欧氏距离等价于余弦类似度(距离最小类似度越大),而余弦类似度退化为向量内积。
竞争学习规则——Winner-Take-All网络的输出神经元之间相互竞争以求被激活,结果在每一时刻只有一个输出神经元被激活。这个被激活的神经元称为竞争获胜神经元,而其它神经元的状态被抑制,故称为Winner Take All。
那么如何寻找获胜神经元?首先,对网络当前输入模式向量X和竞争层中各神经元对应的权重向量Wj(对应j神经元)所有进行归一化,使得X和Wj模为1;当网络获得一个输入模式向量X时,竞争层的全部神经元对应的权重向量均与其进行类似性比较,并将最类似的权重向量判为竞争获胜神经元。前面刚说过,归一化后,类似度最大就是内积最大:
![]()
也就是在单位圆(2D状况)中找到夹角最小的点。

知道哪一个神经元获胜后就是神经元的输出和训练调整权重了:

所以,总结来讲,竞争学习的步骤是:(1)向量归一化(2)寻找获胜神经元(3)网络输出与权值调整步骤(3)完成后回到步骤1继续训练,直到学习率衰减到0。学习率处于(0,1],通常随着学习的进展而减少,即调整的程度愈来愈小,神经元(权重)趋于聚类中心。
为了说明状况,用一个小例子[2]









 浙公网安备 33010602011771号
浙公网安备 33010602011771号