RAG 细粒度越权访问
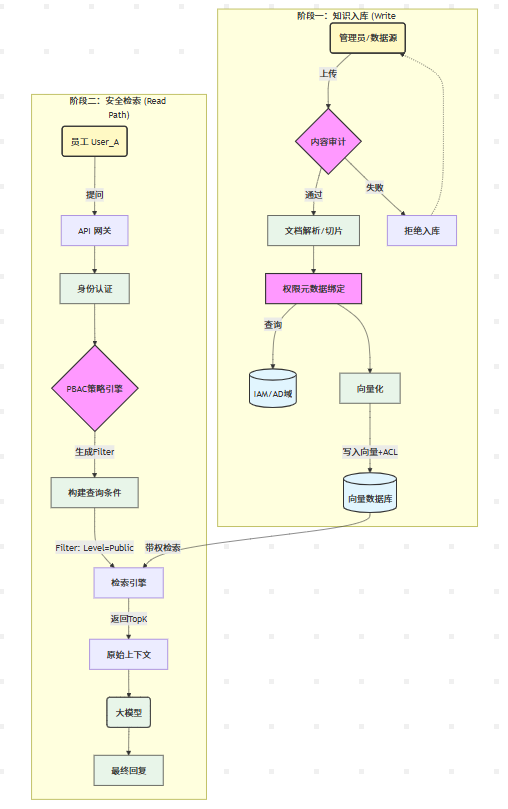
先总体思路,然后再拆成 RAG 召回阶段 和 LLM 生成阶段 的控制流程,「PBAC + 向量级 ACL + 动态脱敏」。
一、整体原则:权限前移 + 全链执法 + 最小暴露
RAG 场景要做到 CEO 密级文档普通员工问不到/看不到,关键是:
-
在向量检索阶段就做权限过滤:
- 不让未授权用户的 Query 去命中敏感文档 embedding。
- 检索结果中,不应该出现任何用户无权访问的 chunk。
-
在 LLM 生成阶段再做一次审计/脱敏:
- 防御 prompt 注入、越权提问、以及系统侧 bug。
- 让 LLM 只能基于“已授权的上下文”回答,而不能主动暴露更多。
-
文档级 + Chunk 级 + 字段级 多层控制:
- CEO 文档不仅整体受控,还可以在同一文档内对部分段落/字段做动态脱敏。
二、索引阶段:为「细粒度访问控制」打基础
1. 文档和 Chunk 元数据设计
每个被拆成向量的 chunk 都要挂上完备的权限元数据,至少包括:
doc_id: 文档 IDchunk_id: chunk IDowner: 文档所有者(如 ceo_user_id)classification: 密级(如 PUBLIC/INTERNAL/SECRET/CEO_ONLY)department: 部门allowed_roles: 角色列表(如 ["CEO", "Board", "HR_Director"])allowed_users: 显式白名单用户 IDpbac_policy_id: 绑定的 PBAC 策略(例如“仅直属上级可见”、“仅本项目组”)need_mask_fields: 需要脱敏的字段列表(如 ["phone", "salary"])
核心:向量库里每一条 embedding 都带一份可用于访问控制的结构化元数据。
2. PBAC(Policy Based Access Control)模型
可以抽象出统一策略语言,例如(伪):
{
"policy_id": "CEO_DOC_ACCESS",
"effect": "allow",
"resource": "doc:ceo/*",
"condition": {
"anyOf": [
{ "user.role": "CEO" },
{ "user.role": "Board" },
{ "user.id": "ceo_assistant_id" }
]
}
}
- 给 CEO 文档打标签:
pbac_policy_id = "CEO_DOC_ACCESS" - 系统只存标签到 chunk 元数据里,实际决策由 PBAC 引擎负责。
三、RAG 检索阶段:向量级 ACL
1. 查询前先做一次「权限上下文构建」
用户发来问题时,先拿到一个统一的用户上下文对象:
{ "user_id": "u_123", "roles": ["EMPLOYEE"], "departments": ["R&D"], "attributes": { "grade": "P6", "manager": "u_999", "region": "CN" } } 2. 在向量检索时强制带上过滤条件
以典型向量库为例(Milvus / Qdrant / Elasticsearch vector):
- 根据用户上下文,计算出允许访问的资源条件表达式,例如:
( classification in ["PUBLIC", "INTERNAL"] AND department in ["ALL", "R&D"] ) AND NOT (classification = "CEO_ONLY") 或 PBAC 先算出一组 allowed_policy_id:
pbac_policy_id in ["PUBLIC_DOC", "INTERNAL_DOC_FOR_R&D"] - RAG 检索伪流程:
# 1. 向量化 query
q_vec = embed(query)
# 2. 根据用户构造 filter
acl_filter = build_acl_filter(user_context)
# 3. 向量检索 + ACL filter
results = vector_store.search(
vector=q_vec,
top_k=50,
filter=acl_filter # 真正关键的一步
)
# 4. 只把已过滤的 results 传给 LLM
这样:CEO_ONLY 的 chunk 在向量检索时根本不会被看到,普通员工问再多也搜不到。
3. 向量级 ACL 的「最小暴露」技巧
- Chunk 尽量细颗粒度:
- 把敏感内容拆在单独 chunk 里,给更高密级;
- 同一文档不同段落可以绑定不同
classification。
- 不在向量空间中泄漏 Label:
- 权限信息放在元数据,不参与 embedding;
- 防止“CEO”字眼导致类 CEO 文档都靠得很近,被侧向推断。
四、动态脱敏:字段级 / 片段级保护
即使通过 ACL 过滤后,还有两类信息需要处理:
- 同一文档中,部分字段/句子要脱敏(如薪资、手机号、证件号)
- LLM 生成回答时,不能输出超出用户权限的细节
1. 内容侧脱敏(检索结果 → 上下文)
在把检索到的 chunk 传给 LLM 之前,做一层「脱敏处理器」:
def mask_chunk_text(chunk, user_context):
# 根据密级 + PBAC 决定是否需要脱敏
if chunk.classification == "HIGH_SECRET" and not user_is_privileged(user_context):
return "[内容已隐藏:您无权查看此密级信息]"
text = chunk.text
# 字段级脱敏规则(正则 + 标注)
if "salary" in chunk.need_mask_fields:
text = re_salary_mask(text)
if "phone" in chunk.need_mask_fields:
text = re_phone_mask(text)
# ... 其他规则
return text
所有送入 LLM 的上下文统一走这层函数。
即:向量库给的是“原文”,RAG 中间层按用户权限生成“可见版本”。
2. LLM 侧「回答级」脱敏 / 越权防护
再在 prompt 设计上加一层安全约束:
(1)系统 Prompt 中明确授权边界
示例(简化):
你只能基于提供的「已授权资料」进行回答。
对于任何机密级别高于用户权限的内容:
- 不要推测或编造。
- 若用户提问涉及此类内容,请回答「根据您的访问权限,我无法提供该信息」。
并将用户权限信息也传给 LLM:
"security_context": {
"user_roles": ["EMPLOYEE"],
"max_classification": "INTERNAL"
}
(2)对「敏感意图」做检测
在送 LLM 之前,对用户 query 和预生成的 answer 进行一次安全检测:
- Query 侧:识别这是不是在问高密级内容
- Answer 侧:用规则或一个小模型审查有没有出现不该出现的关键信息(如特定项目代号、个人隐私数据)
这一步主要是兜底——防 prompt 注入和策略缺陷。
五、结合「PBAC + 向量级 ACL + 动态脱敏」的端到端流程
以「普通员工问:公司今年的营收目标是多少?」为例:
-
认证 & 构造用户上下文
- SSO / IAM 返回:user_id = 1001, roles = ["EMPLOYEE"], dept = "R&D"。
-
PBAC 引擎求出可访问策略集合
- 如:
PUBLIC_DOC,INTERNAL_DOC_FOR_R&D - CEO 的策略
CEO_DOC_ACCESS不在其中。
- 如:
-
RAG 检索(向量级 ACL)
- 查询:
pbac_policy_id in ["PUBLIC_DOC", "INTERNAL_DOC_FOR_R&D"] - 结果:只会返回公开或内部摘要,不会命中 CEO 级别的详细财务报表 chunk。
- 查询:
-
动态脱敏处理
- 对包含「具体数字」「员工名单」的 chunk 做掩码或模糊描述(如只给区间或同比增幅)。
-
LLM 生成
- 系统 prompt 告诉模型:
- 用户最高密级 = INTERNAL;
- 不得给出 CEO_ONLY 文档或 HIGH_SECRET 的细节。
- 模型基于脱敏后的上下文生成概略回答,比如:
今年公司的营收目标较去年有两位数增长,具体数值未对全体员工公开。
- 系统 prompt 告诉模型:
-
输出前再审查(可选)
- 用规则或小模型扫描回答里有没有泄露 CEO only 信息标记词。
六、内鬼注入虚假知识:如何防?
你顺带提到的「内鬼注入虚假知识」,在 RAG 里主要是:
- 往语料库塞假文档,或者篡改已有文档。
可用的手段:
-
索引管道接入 DLP / 审核流程
- 只有特定角色(如知识管理员)才能把文档送进 RAG 语料。
- 文档入库前做签名、来源验证、双人复核。
-
文档不可篡改 / 版本化 + 签名
- 存对象存储 + HASH + 审计日志。
- 每个 chunk 元数据记录
version、hash和creator_id,被修改就强制重审。
-
回答时暴露信息来源
- 在回答后附上“参考来源:文档 A v3,更新人:张三,更新时间 2025-11-01”。
- 员工可以看到信息链路,有利于发现异常。
七、如果只关注「CEO 文档不被普通员工看到」,最小实现方案
在你现有架构里,如果只想先快速实现这一条,可以按下面的「MVP 级」栈来:
-
向量库维度
- 每个 chunk 增加字段:
min_role(如 "EMPLOYEE" / "MANAGER" / "CEO")。 - CEO 文档 chunk:
min_role = "CEO"。
- 每个 chunk 增加字段:
-
检索时过滤
def build_acl_filter(user_roles):
# 简化:角色等级映射
level = max(role_level[r] for r in user_roles) # EMPLOYEE=1, MANAGER=2, CEO=3
return f"min_role_level <= {level}"
- LLM 层加个兜底 prompt
- 告诉模型:
- 你的上下文已过滤过权限;
- 如果用户显式问“CEO 专用内容”,就礼貌拒绝。
- 告诉模型:
这套很容易上线,但要进一步严密,就按前面 PBAC + 脱敏方式逐步迭代。
思考:RAG网关本质上和数据库防火墙做访问控制一样,有一套自己的权限管理机制。因为可以感知sql。自己维护acl更合适。
数据库防火墙一般是做什么?数据库防火墙(Database Firewall)一般是用来在「访问数据库这一层」做安全防护的,它的核心目的就是:拦住异常/恶意的数据库访问请求,防止数据被非法查询、篡改或泄露。
可以分几块来理解它都做什么:
1. 访问控制(谁能访问什么)
数据库本身有权限控制,但数据库防火墙会在「外层」再加一层:
- 限制哪些应用 / IP / 帐号可以访问哪些库、哪些表
- 控制允许执行的操作:
- 只允许
SELECT,不允许UPDATE/DELETE- 只允许读某些字段(比如不允许查明文手机号、身份证号)
- 可以按业务场景、时间段做策略:
- 非工作时间禁止运维远程访问
- 某些敏感表只允许通过指定应用访问,不允许开发直接连
作用:就算数据库账号泄漏了,也不一定能随便查/删数据。
2. SQL 安全检测与拦截(防 SQL 注入等)
数据库防火墙最常见的功能之一:检测并拦截恶意 SQL:
- 识别常见 SQL 注入特征
OR 1=1UNION SELECT; DROP TABLE- 利用注释符号
--、/* ... */拼接的注入语句- 检查 SQL 复杂度,限制高风险操作
- 禁止
DROP TABLE、TRUNCATE TABLE- 大范围
UPDATE、DELETE(无 WHERE 条件或全表扫描)拦截或告警- 基于白名单/模板:
- 只允许符合预设 SQL 模板的语句,其他一律拦截或人工审批
- 对参数化 SQL 友好,防止拼接 SQL 被注入
3. 行为审计与记录(谁在干什么)
数据库防火墙通常会详细记录所有访问和操作,用于审计和追溯:
- 记录内容:
- 用户/账号、来源 IP、应用名
- 执行的 SQL、影响的表/行
- 执行时间、执行结果(成功/失败)
- 用途:
- 合规审计:满足监管要求(金融、医疗、政务等)
- 事后追踪:谁在什么时候查过哪些数据、改过什么数据
- 运维排错:定位哪个操作导致了数据异常
一般支持报表、检索、告警(比如短时间内大量导出数据会告警)。
4. 敏感数据保护(防大规模泄露)
针对敏感数据(如身份证号、手机号、银行卡号等),数据库防火墙可以:
- 识别并标记敏感表/字段
- 对敏感数据访问做加强控制:
- 只有指定角色/应用可查询
- 超出一定查询量告警或阻断(比如一次性导出几万条)
- 有的产品支持脱敏展示:
- 对非授权用户返回脱敏结果(如
138****0000)- 或仅允许模糊查询,而非精确值查询
5. 防止大规模误操作或恶意操作
对于 DBA 或应用误操作、脚本 bug 等,数据库防火墙可以:
- 做一些「刹车」:
- 禁止无 WHERE 的
DELETE/UPDATE- 限制单条 SQL 影响的行数、执行时间
- 大表结构变更需要人工确认或走审批
- 特权账号监控:
- 对
root/sysdba等敏感账号的操作重点审计和告警- 异常时间的高危操作(凌晨批量删表)立刻预警
6. 统一安全策略与隔离
在大型企业里,数据库种类多(MySQL、Oracle、PostgreSQL、SQL Server…):
- 数据库防火墙可以作为统一入口:
- 所有数据库访问都先过防火墙,再到具体数据库
- 统一进行安全策略下发、审计、报表
- 与其它安全设施联动:
- WAF / 堡垒机 / SIEM 等系统联动告警
- 将高危行为推送到安全运营平台统一分析
7. 部署方式(了解一下概念即可)
常见部署模式:
- 旁路监控:只抓包/镜像流量,做审计、告警,不阻断
- 串联代理:作为数据库代理,对 SQL 进行实时检测并可阻断(最常见)
- 透明网关:在网络层透明接入,对上游应用透明
总结一句话
数据库防火墙 = 数据库层的「WAF + 审计 + 行为控制」,主要负责:
- 控访问:谁能访问什么数据、能干什么操作
- 防攻击:拦截 SQL 注入等恶意或高危 SQL
- 做审计:记录并分析所有访问行为,方便合规与追责
- 保护数据:特别是敏感数据和大规模数据导出/删除
如果你方便说一下应用场景(比如是互联网业务、内部办公系统、金融/政务系统,还是个人学习),我可以帮你更具体地说下:
- 什么时候「值得上数据库防火墙」
- 选型时要注意哪些功能点和指标。
访问控制(谁能访问什么) 数据库本身有权限控制,但数据库防火墙会在「外层」再加一层: 限制哪些应用 / IP / 帐号可以访问哪些库、哪些表 控制允许执行的操作: 只允许 SELECT,不允许 UPDATE / DELETE 只允许读某些字段(比如不允许查明文手机号、身份证号) 可以按业务场景、时间段做策略: 非工作时间禁止运维远程访问 某些敏感表只允许通过指定应用访问,不允许开发直接连 ==》他是如何做到的啊 按理说不是数据库本身做的嘛?他可以感知权限???关键点在于:数据库防火墙在数据库“外面”截获请求,再“转发/拒绝”,它不需要直接改数据库权限,但可以“站在路口”控制谁能进去、进去以后能干什么。
可以分几层来理解它是怎么做到的:
1. 它靠什么“看见”请求?
数据库防火墙一般有两种常见部署方式:
代理模式(最常见)
应用不再直接连数据库,而是连防火墙:
- 原来:
应用 -> 数据库- 现在:
应用 -> 数据库防火墙 -> 数据库这样:
- 登录时的用户名、密码、客户端 IP、端口等,它都能看到
- 之后每一条 SQL 它都能完整解析、分析、改写、决定是否转发
透明网关 / 内联设备
部署在网络中间(例如透明网关、旁路+重定向),对上游基本透明,但底层仍然是解码数据库协议,分析 SQL,然后转发或丢弃。核心:它能完整解析数据库协议(MySQL、PostgreSQL、Oracle 等),看到:
- 连接是谁发的(来源 IP、用户)
- 连接要连哪个库
- 每一条 SQL 的内容:
SELECT ... FROM tableX WHERE ...
2. “限制哪些应用/IP/账号访问哪些库/表”是怎么做的?
典型做法:
通过连接信息识别“是谁”
- 来源 IP / 端口
- 登录账号(数据库用户)
- 有时还能通过应用设置一个固定的
app_name/ 连接串特征来识别“哪个系统”做一套自己的“访问策略表”(类似 ACL)
比如配置规则:
条件(谁) 允许访问什么 限制 来源 IP 在 10.1.1.0/24 且用户 app1只允许访问 DB order_db的表t_order不允许 DELETE、UPDATE用户 dev禁止访问 prod_db所有表全拒绝 来源 IP 非内网网段 仅允许只读查询 禁止 DML/DDL 当有连接/SQL 经过时:
- 防火墙解析:这是谁发来的、访问哪个库、执行什么语句
- 和规则一条条匹配
- 不符合规则就:
- 直接拒绝连接
- 或只拦截这条 SQL,返回错误给客户端(数据库本人根本没看到)
所以它不用“感知数据库的权限”,而是在数据库之前搞了一套“自己定义的权限规则”。
3. “只允许 SELECT,不允许 UPDATE / DELETE”是怎么做的?
因为它能解析 SQL,所以:
- 拿到一条语句,比如:
UPDATE user SET phone = 'xxx' WHERE id = 1;- SQL 解析器会分出:
- 类型:
UPDATE- 目标表:
user- 影响字段:
phone- 套规则判断:
- 如果该账号 / 来源 IP / 业务只允许
SELECT- 那么检测到
UPDATE就直接拦截,返回一个错误(比如模拟数据库错误码)同理可以做:
- 禁止
DELETE没有WHERE条件- 禁止对某些表执行任何写操作
- 限制对某些字段做更新(比如不能更新余额为负数等,这是高级玩法)
4. “只允许读某些字段(比如不允许查明文手机号、身份证号)”怎么实现?
数据库防火墙也能做到“字段级”的规则,原理类似:
- 解析 SQL:
SELECT id, name, phone, id_card FROM user WHERE ...- 知道:
- 表:
user- 字段列表:
id, name, phone, id_card- 查规则:
- 对于这个用户 / IP / 系统:
- 允许查
id, name- 不允许查
phone, id_card- 不同产品的处理方式可能不同:
- 直接拦截整条 SQL(返回错误)
- 或进行“改写”:把
phone, id_card从 SELECT 列表中删掉,再转发到数据库(更复杂,高级产品才有)有的厂商会结合“敏感字段标记”:提前标注哪些字段是敏感的,然后策略里只写“普通开发账号不能查敏感字段”。
5. “按时间段禁止运维访问 / 只允许指定应用访问敏感表”怎么做?
同样基于“谁 + 什么时候 + 访问什么”:
时间维度:
- 每条 SQL 到达防火墙时,防火墙有系统时间
- 策略里可以写:
- 账号
dba1在 9:00–18:00 可以全权访问- 在 18:00–次日 9:00,只能读,不能写;或者完全禁止
只允许通过指定应用访问敏感表:
关键在于区分“这个用户是通过哪儿来的”:
- 开发自己用 Navicat / DBeaver 连库:
- 通常是个人电脑 IP、直连、防火墙能识别为“非业务应用”
- 线上业务系统访问:
- 来自业务应用服务器的 IP 段
- 或连接串中带有固定的应用名
- 策略示例:
- 来源 IP 属于应用服务器网段 + 用户
app_prod:
- 可以访问
user_info敏感表- 其他来源 IP(如办公网、VPN 段):
- 禁止访问
user_info敏感表,不管你用啥账号这样就能做到你问的那句:“某些敏感表只允许通过指定应用访问,不允许开发直接连”。
6. 那数据库自身权限和防火墙是什么关系?
可以这么理解:
- 数据库权限:
在“屋子里面”的门锁
- 账号能访问哪些库/表、能否
SELECT/INSERT/UPDATE/DELETE- 由 DBA 在 DB 里配置
- 数据库防火墙:
在“楼下大门”的保安
- 决定这个人/这台机器能不能进这栋楼、能去哪几层
- 就算你有屋里的钥匙,门卫不让你进楼,你也进不去
实践中常见做法:
- 在数据库里保守配置权限:
就算绕过防火墙,权限也不会太大。- 在防火墙里再加更细粒度、按场景的控制:
- 按时间段
- 按来源 IP
- 按 SQL 模板
- 按敏感字段、敏感表
- 审计也更多是防火墙来做:因为它能看到所有流量,而且不依赖单个数据库厂商的审计能力。
7. 回到你问的那句:“他可以感知权限???”
严格说:
- 它不一定去读取数据库内部的权限表(有些厂商会集成,但不是必须)
- 更多是:
- 它自己“看见”了请求的所有上下文(IP、账号、SQL 内容)
- 再基于自己维护的策略,做一套“独立于数据库权限之外的控制”
所以:
- “权限感知” = 流量级别的上下文感知,而不是直接窥探数据库内部权限配置。
- 一些高端产品会做“权限同步”(从 DB 拉用户/角色/权限信息),然后让策略配置更直观,但底层控制仍是:拦/放 SQL。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号