

layernorm和batchnorm的区别——一个是行归一化一个是列归一化,一个是对输出激活归一化,一个主要是对输入归一化
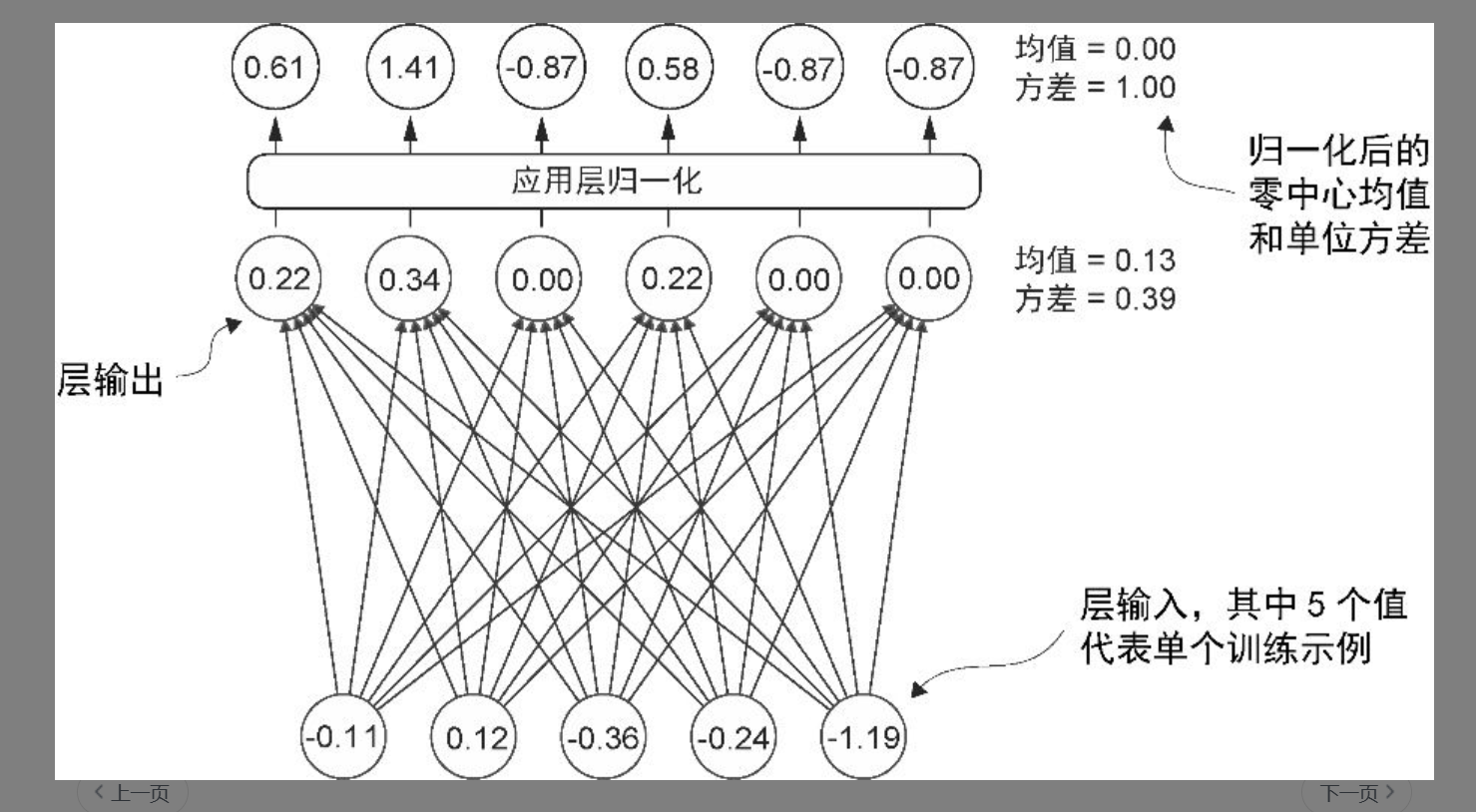
层归一化
非常好的问题!你提到的“为什么层归一化(Layer Normalization, LN)是对激活输出归一化,而不是像输入归一化那样对**特征维度(列)**归一化”,其实抓住了层归一化与批归一化(BatchNorm)等归一化方法之间的关键差别。我们可以一步步来解释这个设计选择的原理。
🧩 一、背景:不同归一化方式的比较
首先,几种常见归一化的“归一化轴”不同:
| 方法 | 计算均值/方差的维度 | 运行时依赖的批次 | 基本思想 |
|---|---|---|---|
| BatchNorm | 对同一特征维度(列) across batch | 依赖 batch | 让同一特征在不同样本间分布稳定 |
| LayerNorm | 对同一个样本的所有特征(行内) | 不依赖 batch | 让每个样本内部的激活分布稳定 |
| InstanceNorm / GroupNorm | 介于两者之间 | 局部 feature maps 内归一化 | 多用于 CNN |
🧠 二、为什么 层归一化(LayerNorm) 是按行(即单样本内)归一化?

这意味着它把单个样本自己的各个特征维度归一化,使得输出这一维向量的内部分布标准化。
💡 三、为什么这么做有意义?
-
Transformer不像CNN那样有空间局部性,也不像BatchNorm依赖批次统计。
每个 token(或序列位置)都是独立计算的,没有“图像邻域”信息。
所以对每个 token 自己的特征维度做标准化最合理。 -
稳定每个样本的激活分布
层归一化是在激活(即神经元输出)上操作,目的是让每一层的输出分布稳定,避免某些维度激活值过大导致梯度爆炸或消失问题。 -
不依赖 batch 大小
如果用 BatchNorm,批次统计量会因为 batch size 太小而不稳定。
GPT-2 等模型常在小批次或序列长度可变的情况下工作(尤其推理时单样本),因此 LN 是更好的选择。
⚙️ 四、直观理解:“为什么不按列(特征)统一归一化?”
如果你按列对所有样本归一化,那就相当于做了 BatchNorm:每列的均值和方差在 batch 维上统计。
但在 Transformer 中:
- 一个 batch 里的样本可以是完全不同的句子、上下文或 token;
- 它们的特征分布可能完全不同。
所以按列归一化会把不同样本的分布“混在一起”,破坏模型的表达稳定性。
而 LayerNorm 的逻辑是:
“我不关心别人样本的分布,我只让我自己的特征分布稳定。”
🔍 五、总结一句话:
| 问题 | 解释 |
|---|---|
| 为什么层归一化用在激活输出,而不是输入? | 因为它要稳定网络层内部的非线性输出分布,使得梯度传播更平滑。 |
| 为什么按行(样本维)归一化,而不是按列? | 因为它关注单个样本内部特征的整体平衡,不依赖批次统计,也不跨样本混合信息。 |
帮你画一个直观的示意图,对比 Batch Normalization(批归一化) 和 Layer Normalization(层归一化) 在作用维度上的区别。
(我会用一个简单的矩阵例子来展示它们求均值/方差时所覆盖的维度。)
🧮 示例输入矩阵
假设有一个小批次输入 XX:
| 样本 (batch) | 特征1 | 特征2 | 特征3 |
|---|---|---|---|
| 样本A | 1.0 | 2.0 | 3.0 |
| 样本B | 4.0 | 5.0 | 6.0 |
| 样本C | 7.0 | 8.0 | 9.0 |
⚙️ Batch Normalization(批归一化)
📊 按列(特征维)归一化:
- 对每一列(特征)在整个 batch 上计算均值和方差。
- 举例:
- 特征1: (1 + 4 + 7) / 3 = 4
- 特征2: (2 + 5 + 8) / 3 = 5
- 特征3: (3 + 6 + 9) / 3 = 6
归一化区域如下(按列):
特征1 ↓ 特征2 ↓ 特征3 ↓ 也就是说,所有样本共享同一列的分布统计。
这就是为什么它依赖 batch 的大小与分布。
⚙️ Layer Normalization(层归一化)
📈 按行(单样本内部)归一化:
- 对同一个样本的所有特征(整行)计算自己的均值与方差。
- 举例:
- 样本A: (1+2+3)/3 = 2
- 样本B: (4+5+6)/3 = 5
- 样本C: (7+8+9)/3 = 8
归一化区域如下(按行):
→ 样本A → [1, 2, 3]
→ 样本B → [4, 5, 6]
→ 样本C → [7, 8, 9]
也就是说,每个样本独立地让自己的特征分布标准化。
这样它在不同 batch 大小或推理阶段都仍然稳定。
🌈 对比直观总结
| 属性 | BatchNorm | LayerNorm |
|---|---|---|
| 归一化方向 | 按列(跨样本) | 按行(单个样本内部) |
| 是否依赖 batch | ✅ 是 | ❌ 否 |
| 统计范围 | 同一特征 across batch | 同一样本 across features |
| 常用于 | CNNs, 图像 | Transformer, NLP, RNN |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号