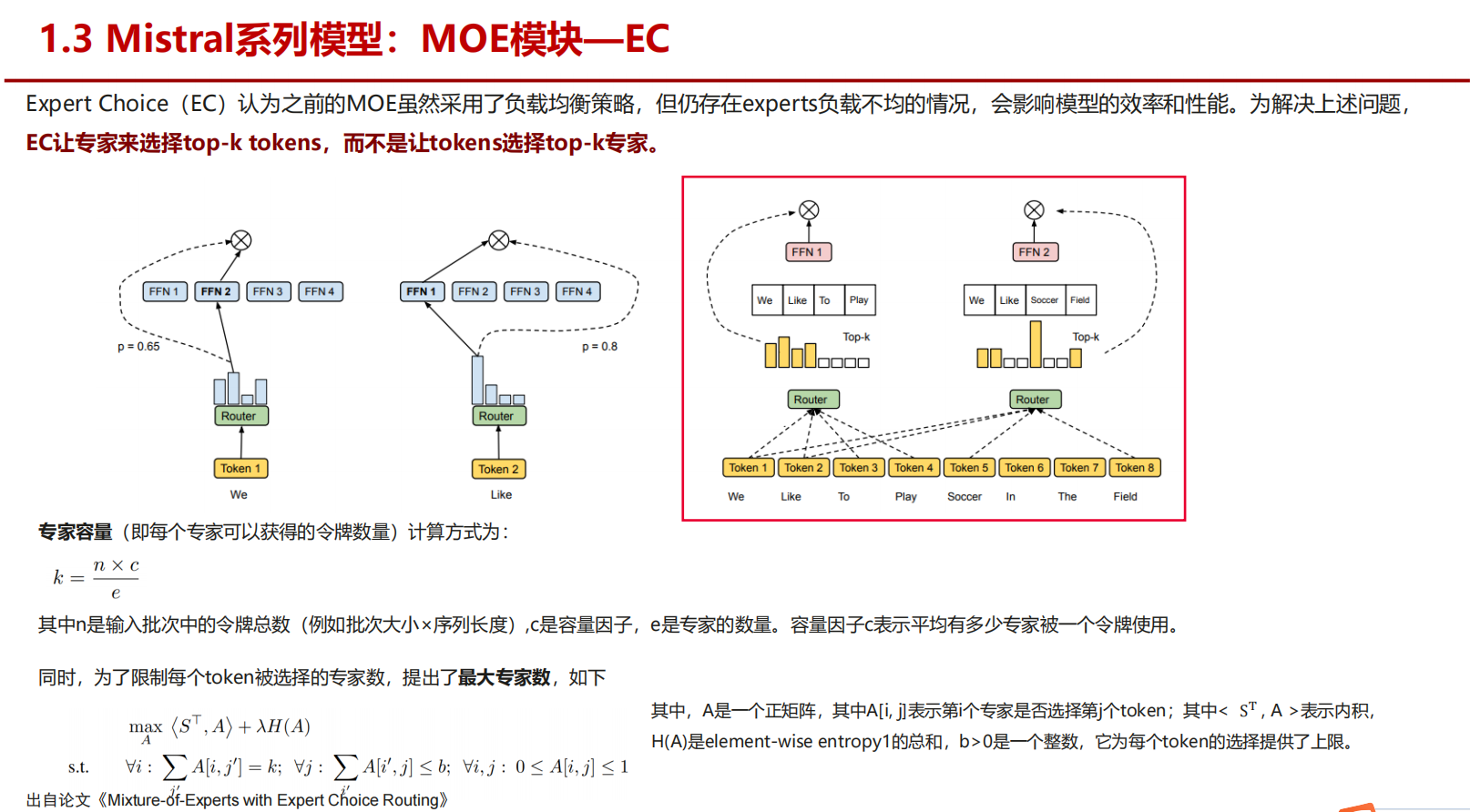
Mistral系列模型:MOE模块—EC是什么? 专家主动去一堆token里选择自己适合处理的token
这个问题非常有针对性——你提到的是 Mistral 系列模型 的 Mixture of Experts (MoE) 模块中的 EC(Expert Choice) 机制。下面我来系统解释一下它的原理和设计动机。
一、背景:Mistral 的 MoE 架构
Mistral(尤其是 Mixtral-8x7B 等模型)使用了 稀疏激活(Sparse Activation) 的 MoE 架构。
简单来说:
- 模型有多个“专家”(Experts),例如 8 个;
- 每个输入 token 只会被送到部分专家(例如 2 个);
- 这样可以在保持模型参数量大的同时,显著降低推理时的计算量。
二、什么是「EC:Expert Choice」机制?
通常,MoE 的路由(routing)方式有两种主要思路:
🧩 1. Token Choice(TC)
传统 MoE(如 Switch Transformer 或 GLaM)的路由是 Token-Centric:
- 每个 token 通过一个门控网络(router)计算出所有专家的得分;
- 然后选出 Top-k 个专家来处理这个 token。
这种方法的特点:
- 每个 token 自主选择专家;
- 不同专家可能工作负载不平衡(有的专家被选得多,有的很少)。
⚙️ 2. Expert Choice(EC)
Expert Choice 则是反过来的思路:
- 由“专家”自己来选择要处理哪些 token。
- 每个专家都会计算 token 的路由得分,但由专家挑选“最适合自己”的若干 token。
换句话说:
- TC 是「token 选专家」;
- EC 是「专家选 token」。
三、EC 的工作机制(简化流程)
假设模型有 <span class="katex"><span class="katex-mathml">E<span class="katex-html"><span class="base"><span class="strut"><span class="mord mathnormal">E 个专家、每个专家最多可处理 <span class="math math-inline"><span class="katex"><span class="katex-mathml">C<span class="katex-html"><span class="base"><span class="strut"><span class="mord mathnormal">C 个 token。
-
计算得分矩阵
Router 计算出每个 token 与每个专家之间的匹配得分(logits)。
得到一个大小为 <span class="katex"><span class="katex-mathml">(tokens,E)<span class="katex-html"><span class="base"><span class="strut"><span class="mopen">(<span class="mord text"><span class="mord">tokens<span class="mpunct">,<span class="mspace"><span class="mord mathnormal">E<span class="mclose">) 的矩阵。 -
专家选取 token(Expert Chooses Tokens)
每个专家从所有 token 中选出得分最高的 <span class="katex"><span class="katex-mathml">C<span class="katex-html"><span class="base"><span class="strut"><span class="mord mathnormal">C 个 token。 -
执行前向计算
各专家在各自选定的 token 上执行前向传播(FFN)。 -
聚合
最后将各专家的输出按原 token 顺序拼接回去。
四、EC 相比 TC 的优势
| 维度 | Token Choice | Expert Choice |
|---|---|---|
| 负载均衡 | 可能不均衡 | 更自然均衡(每个专家上限相同) |
| 路由冲突 | 有可能:多个 token 抢同一专家资源 | 无冲突(专家主动挑选) |
| 计算分布 | 随 token 分布波动 | 更稳定 |
| 通信模式 | token → 专家(多→多) | 专家从全局挑选 token(相对集中) |
Mistral 官方论文中指出,Expert Choice 在分布式训练和推理时通信成本更低、负载更均衡,这正是 Mistral 系列选择它的原因。
五、总结一句话
在 Mistral 的 MoE 模块中,EC(Expert Choice)是一种由专家“选择”要处理哪些 token 的稀疏激活机制,主要目的是提升计算负载均衡性和通信效率,相对传统的「token 选专家」方案具有更好的可扩展性。
如果你愿意,我还可以画一张简单的对比图(TC vs EC 路由流程),或是写一个伪代码片段来说明 EC 的具体执行逻辑。你希望我继续展示哪种?
好的 👍 我给你画一个清晰简化的示意图,对比 Token Choice (TC) 和 Expert Choice (EC) 的路由逻辑。
(以下是文本图解,方便直接阅读;如果你想要图像版,我也能帮你生成可视化。)
🧩 对比图:Token Choice vs. Expert Choice
1️⃣ Token Choice(传统方式:Token 选 Expert)
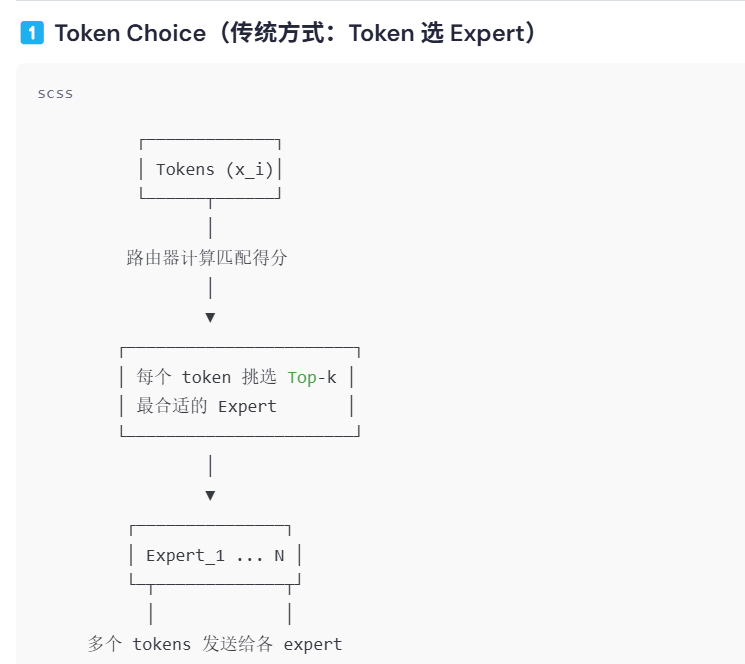
📌 特点:
- 每个 token 主动选择专家;
- 容易出现 某些专家负载过高(有偏)的问题;
- 通信方向:token → expert。
2️⃣ Expert Choice(Mistral方式:Expert 选 Token)
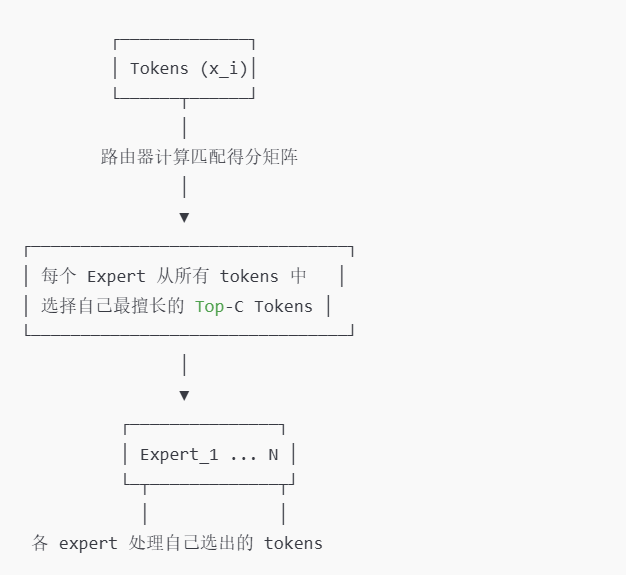
- 每个专家“主动”挑选 token;
- 更容易实现 负载均衡;
- 通信方向:expert ← tokens;
- Mistral 的 MoE 模块使用这种 EC 策略。
✅ 总结对比
| 维度 | Token Choice | Expert Choice |
|---|---|---|
| 主动方 | Token | Expert |
| 负载均衡 | 较弱(可能拥挤) | 强(每个专家限额) |
| 通信模式 | 发送方向多样 | 结构更规则 |
| 应用 | 早期 MoE(如 Switch Transformer) | Mistral, Mixtral 等新一代模型 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号