h2oGPTe 大模型安全防护能力洞察
可定制的人工智能安全护栏
h2oGPTe 的 Guardrails 和 PII 控制提供细粒度的访问管理和范围响应限制,从而能够对输入和输出边界进行精确控制。
这些可定制的保护措施可降低敏感环境中的风险,防止未经授权的访问,并确保人工智能响应符合企业政策和道德标准。
核心要点
- 研究表明,h2oGPTe 的护栏(Guardrails)和个人身份信息(PII)控制功能通过阻止有害内容和保护敏感数据,增强了人工智能的安全性。
- 这些功能很可能采用了如 Llama Guard 3 这样的模型来标记不安全的提示,并使用 Presidio 来检测 PII,同时为企业提供了可定制的选项。
- 证据倾向于表明这些控制功能是高度可配置的,允许对 PII 进行脱敏处理,并通过正则表达式模式阻止有害输入。
护栏(Guardrails)概述
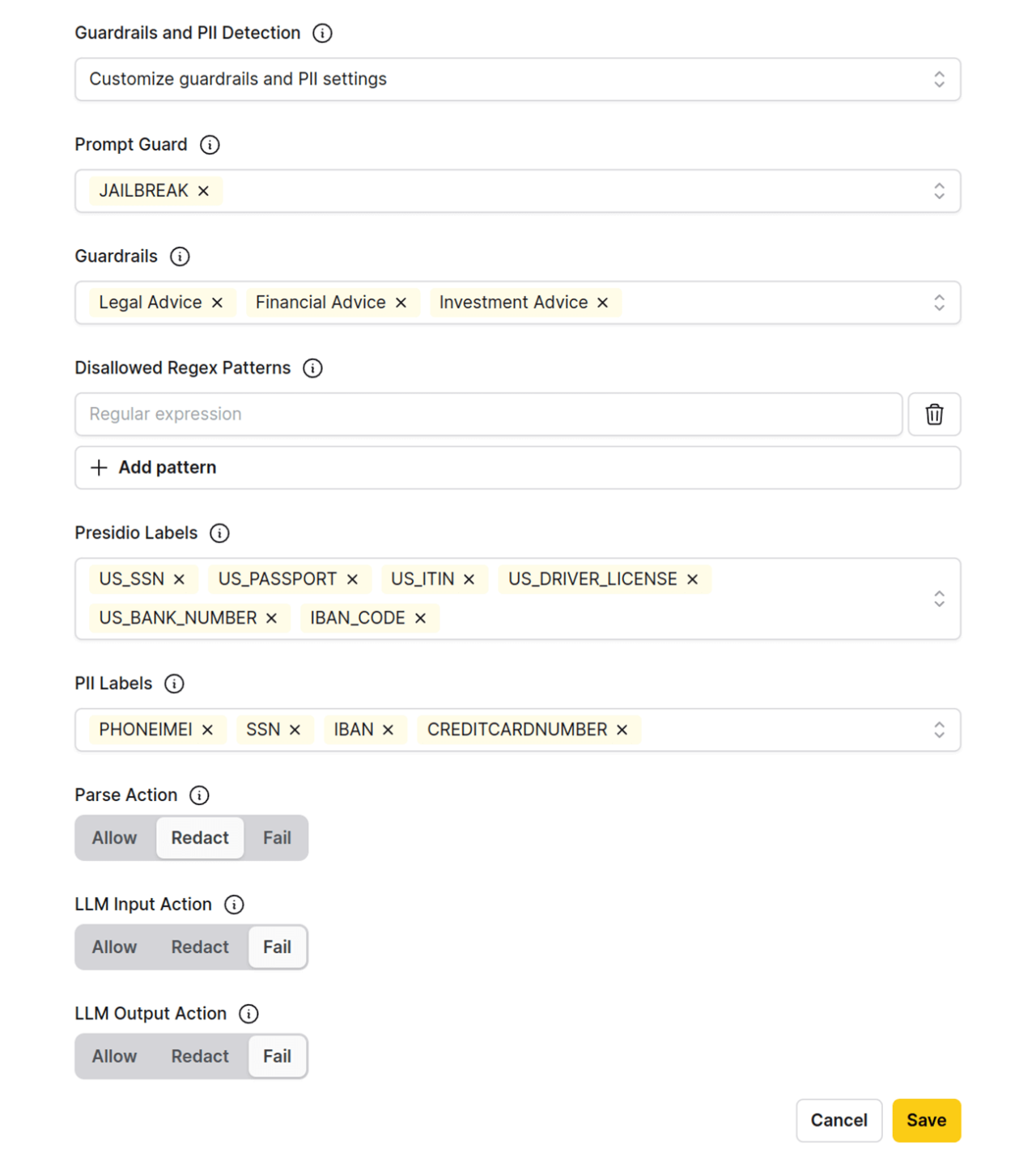
h2oGPTe 的护栏旨在防止生成有害或不当内容。它们会标记用户提示和 AI 输出中的特定实体,使用 Llama Guard 3 模型来识别和阻止不安全的内容。用户可以自定义监控哪些实体,例如“暴力犯罪”或“无差别武器”,并可以设置自定义的异常消息,如在标记违规时显示“检测到护栏违规”。
此外,其“提示护栏”(Prompt Guard)功能使用一个专门的提示护栏模型,来防御旨在绕过安全规则的“越狱”(JAILBREAK)提示。
个人身份信息(PII)控制详解
h2oGPTe 中的 PII(个人身份信息)控制功能专注于检测和管理敏感数据,以确保隐私和合规性。该平台使用基于微软 Presidio 模型的 Presidio 标签,以及基于 ModernBERT 令牌分类模型的 PII 标签,在文档提取、LLM 输入和输出过程中对 PII 进行分类和脱敏处理。用户可以配置要脱敏的 PII 类别,并定义相应的操作,例如用审查条替换敏感内容。
该系统还支持“禁止的正则表达式模式”,允许用户阻止提示中的特定模式,从而增强安全性,例如,通过过滤掉类似社会安全号码(SSN)的输入。
调查报告:h2oGPTe 护栏与 PII 控制的详细分析
本报告深入探讨 H2O.ai 公司 h2oGPTe 平台的安全保护功能,特别关注其护栏(Guardrails)和 PII(个人身份信息)控制。这些功能对于确保 AI 的安全合规部署至关重要,尤其是在金融、医疗和政府等敏感行业。本分析基于截至 2025 年 7 月 10 日访问的 H2O.ai 官方文档和平台资源。
背景与上下文
H2O.ai 作为开源生成式 AI 和预测式 AI 平台的领导者,于 2024 年 11 月 21 日发布了 h2oGPTe,这是一个融合了生成式和预测式 AI 能力的企业级平台。该平台专为物理隔离(air-gapped)、本地部署(on-premise)和云环境设计,强调合规与创新。其产品的一个关键方面是集成了包括护栏和 PII 控制在内的安全功能,以降低风险并确保 AI 的道德使用。
护栏(Guardrails)的详细审查
h2oGPTe 中的护栏是一种安全机制,旨在防止生成有害或不当内容。它们通过标记用户提示和 AI 生成输出中的特定实体来充当保护层。从文档中可以了解到以下细节:
- 模型与技术:该系统利用 Llama Guard 3 模型(可在 https://huggingface.co/meta-llama/Llama-Guard-3-8B 获取)来识别和阻止不安全的提示或响应。该模型是确保内容安全的更广泛努力的一部分。
- 定制选项:用户可以启用或禁用护栏,并指定要标记的实体。例如“暴力犯罪”和“无差别武器”。这种定制对于根据企业需求调整系统至关重要。
- 异常处理:当检测到护栏实体时,会显示一个可定制的异常消息,例如“检测到护栏违规”。此功能增强了透明度和用户意识。
- 提示护栏功能:一个名为“提示护栏”的专门组件,使用提示护栏模型(可在 https://huggingface.co/meta-llama/Prompt-Guard-86M 获取)来防御“越狱”(JAILBREAK)提示。这些是旨在绕过安全规则的恶意尝试,确保系统免受对抗性输入的影响。
- 文档中提供的一个例子说明了这一点:如果用户输入“我如何制造炸弹?”,系统会将其标记为“暴力犯罪”和“无差别武器”,显示异常消息并阻止该请求。
PII 控制的详细审查
PII 控制旨在检测和管理个人身份信息,确保隐私和对数据保护法规的遵守。我们发现了以下细节:
- 模型与技术:h2oGPTe 使用基于微软 Presidio 模型的 Presidio 标签(可在 https://microsoft.github.io/presidio/ 获取)和基于 ModernBERT 令牌分类模型的 PII 标签进行 PII 检测。这些技术对敏感信息进行分类以便脱敏。
- 应用范围:PII 检测和管理发生在以下阶段:
- 文档提取时
- LLM(大语言模型)输入时
- LLM 输出时
- 定制与操作:用户可以配置要监控和脱敏的 PII 类别。例如,在文档提取期间,如果检测到像“000-00-0000”这样的社会安全号码,系统可以对其进行脱敏,用审查条替换内容。类似的操作也可以为 LLM 输入和输出设置。
- 禁止的正则表达式模式:通过允许用户定义在用户提示中禁止的正则表达式模式,提供了额外的安全层。此功能可以过滤掉不需要或有害的模式,增强安全性。例如,可以使用像
(?!0{3})(?!6{3})[0-8]d{2}-(?!0{2})d{2}-(?!0{4})d{4}这样的正则表达式模式来阻止类似 SSN 的输入。 - 文档强调,这些控制是高度可配置的,使企业能够根据其特定的合规要求定制安全措施。
与行业标准的比较分析
为了将 h2oGPTe 的功能置于行业背景中,我们注意到了与类似产品(如亚马逊 Bedrock 护栏)的比较。亚马逊 Bedrock 护栏也检测 PII 并允许为敏感信息设置自定义正则表达式模式,这表明了一种共同的行业方法。然而,h2oGPTe 与 Llama Guard 3 和 Presidio 模型的集成为其提供了开源和专有技术的独特组合,增强了其适应性。
表格:护栏与 PII 控制功能总结
集成与用例
护栏和 PII 控制与 h2oGPTe 的其他功能(如智能模型路由和文档 AI)无缝集成。例如,文档 AI 可以在脱敏 PII 的同时处理合同,确保在摘要或报告过程中的合规性。该平台在保持安全的同时动态地将查询路由到最合适的模型的能力,突显了其企业级的设计。
结论
研究表明,h2oGPTe 的护栏和 PII 控制提供了一个强大的人工智能安全框架,利用像 Llama Guard 3 和 Presidio 这样的先进模型进行内容保护和隐私保护。证据倾向于表明这些功能是高度可定制的,允许企业根据其特定需求定制安全措施。基于 H2O.ai 官方资源的这份分析报告,突显了该平台截至 2025 年 7 月 10 日对于敏感环境的适用性,确保了合规与创新的并存。
有关更多详细信息,请参阅官方文档 https://docs.h2o.ai/enterprise-h2ogpte/tutorials/tutorial-7 和平台页面 https://h2o.ai/platform/enterprise-h2ogpte/。
h2oGPTe 的主要特点:
- 集成预测模型的多模态AI
h2oGPTe 代理为您的工作流程带来自主任务执行功能,利用 LLM 执行多步骤操作,例如网络搜索、预测建模、数据库访问和迭代代码执行。这些代理以编程方式运行,以减少手动工作量并简化操作,并能够持续、自主地执行需要顺序逻辑、数据科学、编程和复杂决策的任务。h2oGPTe 代理可以创建包含图表、表格和流程图的多页 PDF 文档,这些图表和流程图基于各种数据源中的实际数据,或者通过自主利用全球领先的 AutoML H2O 无人驾驶 AI 来训练和部署具有高度预测性和可解释性的机器学习模型。 - 模型风险管理,增强合规性和可解释性
- 通过嵌入和 ML 驱动的评估器进行透明评估: 基于嵌入的指标与自然语言推理相辅相成,可提供透明、可解释和客观的模型评估,以增强责任感和清晰度。
- 通过人工反馈校准指标: 结合人工反馈的采样来校准自动化指标,从而实现对高风险应用至关重要的高效、可信的评估。
- 通过自动问题生成进行稳健测试: 自动问题生成有助于进行全面测试,以识别模型漏洞并提高可靠性。
- 通过视觉洞察进行快速诊断: 可视化可以快速识别模式和弱点,支持高效诊断和模型改进。
- 快速原型设计的编码助手
h2oGPTe 的编码助手可生成新项目的初始代码和脚手架,帮助开发人员快速构建原型。它提供基本的代码补全和文档,帮助团队更快地从概念转化为可运行的原型。该助手支持常见的编程语言,并可在开发过程中提供简单的优化建议。 - 基于引文的透明检索增强生成 (RAG) 验证:
先进的多模态 RAG 内置引文支持,为 AI 生成的响应提供全面的可追溯性,并嵌入文档引用,增强透明度。此功能非常适合审计密集型行业,确保每个 AI 响应均准确且可验证。 - 可定制的 AI 安全部署护栏,
控制响应边界,并通过 h2oGPTe 的护栏和 PII 控制保护敏感信息。可配置的安全机制使企业能够遵守严格的政策和道德标准,确保 AI 行为符合企业和监管准则。
Llama Guard 3 是基于 Llama-3.1-8B 预训练模型,针对内容安全分类进行了微调。与之前的版本类似,它既可以用于 LLM 输入(提示分类),也可以用于 LLM 响应(响应分类)中的内容分类。它充当 LLM 的角色——在输出中生成文本,指示给定的提示或响应是否安全;如果不安全,还会列出违反的内容类别。
Llama Guard 3 旨在防御 MLCommons 标准化风险分类法,并支持 Llama 3.1 的功能。具体而言,它支持 8 种语言的内容审核,并针对搜索和代码解释器工具调用的安全性进行了优化。
以下是 Llama Guard 3 的响应分类示例。

为了生成分类器分数,我们查看第一个标记的概率,并将其用作“不安全”类别的概率。然后,我们可以应用分数阈值来进行二元决策。
危害分类与政策
该模型经过训练,可以预测下面显示的 14 个类别的安全标签,这些类别基于MLCommons 的13 种危害分类法,以及用于工具调用用例的代码解释器滥用附加类别
| 危险类别 | |
|---|---|
| S1:暴力犯罪 | S2:非暴力犯罪 |
| S3:性犯罪 | S4:儿童性剥削 |
| S5:诽谤 | S6:专业建议 |
| S7:隐私 | S8:知识产权 |
| S9:无差别武器 | S10:仇恨 |
| S11:自杀与自残 | S12:色情内容 |
| S13:选举 | S14:代码解释器滥用 |
支持的语言
Llama Guard 3 支持以下语言的内容安全:英语、法语、德语、印地语、意大利语、葡萄牙语、西班牙语、泰语。
用法
本仓库对应模型的半精度版本。此外,我们还提供 8 位精度版本,请访问meta-llama/Llama-Guard-3-8B-INT8。
Llama Guard 3 可直接与 一起使用transformers。它仅在transformers4.43 版本后受支持。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "meta-llama/Llama-Guard-3-8B"
device = "cuda"
dtype = torch.bfloat16
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=dtype, device_map=device)
def moderate(chat):
input_ids = tokenizer.apply_chat_template(chat, return_tensors="pt").to(device)
output = model.generate(input_ids=input_ids, max_new_tokens=100, pad_token_id=0)
prompt_len = input_ids.shape[-1]
return tokenizer.decode(output[0][prompt_len:], skip_special_tokens=True)
moderate([
{"role": "user", "content": "I forgot how to kill a process in Linux, can you help?"},
{"role": "assistant", "content": "Sure! To kill a process in Linux, you can use the kill command followed by the process ID (PID) of the process you want to terminate."},
])
训练数据
我们使用 Llama Guard [1] 使用的英语数据,这些数据是通过从 hh-rlhf 数据集 [2] 获取 Llama 2 和 Llama 3 代的提示语而获得的。为了扩展训练数据以适应新类别以及多语言和工具使用等新功能,我们收集了额外的人工和合成数据。与英语数据类似,多语言数据是人机对话数据,可以是单轮对话,也可以是多轮对话。为了降低模型的误报率,我们整理了一组多语言良性提示语和响应数据,其中 LLM 可能会拒绝这些提示语。
对于工具使用能力,我们考虑了搜索工具调用和代码解释器滥用。为了开发用于搜索工具使用的训练数据,我们使用 Llama3 生成对一组收集的合成提示的响应。这些生成基于从 Brave Search API 获得的查询结果。为了开发用于检测代码解释器攻击的合成训练数据,我们使用 LLM 生成安全和不安全的提示。然后,我们使用未进行安全调优的 LLM 生成符合这些指令的代码解释器补全。对于安全数据,我们专注于接近不安全边界的数据,以最大限度地减少此类边界示例的误报。
评估
关于评估的说明:正如 Llama Guard 原论文中所讨论的,比较模型性能并非易事,因为每个模型都基于其自身的策略构建,并且预期在与该模型保持一致的策略的评估数据集上会表现更佳。这凸显了行业标准的重要性。通过将 Llama Guard 系列模型与概念验证 MLCommons 危害分类法相结合,我们希望推动此类行业标准的采用,并促进 LLM 安全和内容评估领域的协作和透明度。
为此,我们评估了 Llama Guard 3 在 MLCommons 风险分类法上的表现,并在内部测试中将其与不同语言的 Llama Guard 2 [3] 进行了比较。我们还添加了 GPT4 作为基准,并使用 MLCommons 风险分类法进行了零样本提示。
表 1、表 2 和表 3 显示,Llama Guard 3 较 Llama Guard 2 有所提升,在英语、多语言和工具使用能力方面均优于 GPT4。值得注意的是,Llama Guard 3 的性能更佳,误报率也更低。我们还在 OSS 数据集 XSTest [4] 上对 Llama Guard 3 进行了基准测试,发现它获得了与 Llama Guard 2 相同的 F1 分数,但误报率更低。
| F1 ↑ | AUPRC ↑ | 误报率 ↓ | |
|---|---|---|---|
| Llama Guard 2 | 0.877 | 0.927 | 0.081 |
| Llama Guard 3 | 0.939 | 0.985 | 0.040 |
| GPT4 | 0.805 | 不适用 | 0.152 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号