ToolEmu 框架要点总结与应用案例
https://arxiv.org/pdf/2309.15817
ToolEmu 框架要点总结与应用案例
一、核心问题与设计目标
- 风险识别挑战:LM代理的风险识别通常需要手动实现工具、搭建环境和搜集风险案例。随着工具和代理复杂度提升,测试成本激增,长尾高风险案例难以被发现。
- ToolEmu 目标:引入基于LM的工具模拟框架,实现对LM代理在各种工具与环境下的可扩展测试,并开发自动安全评估器,量化风险。
二、ToolEmu框架核心组件
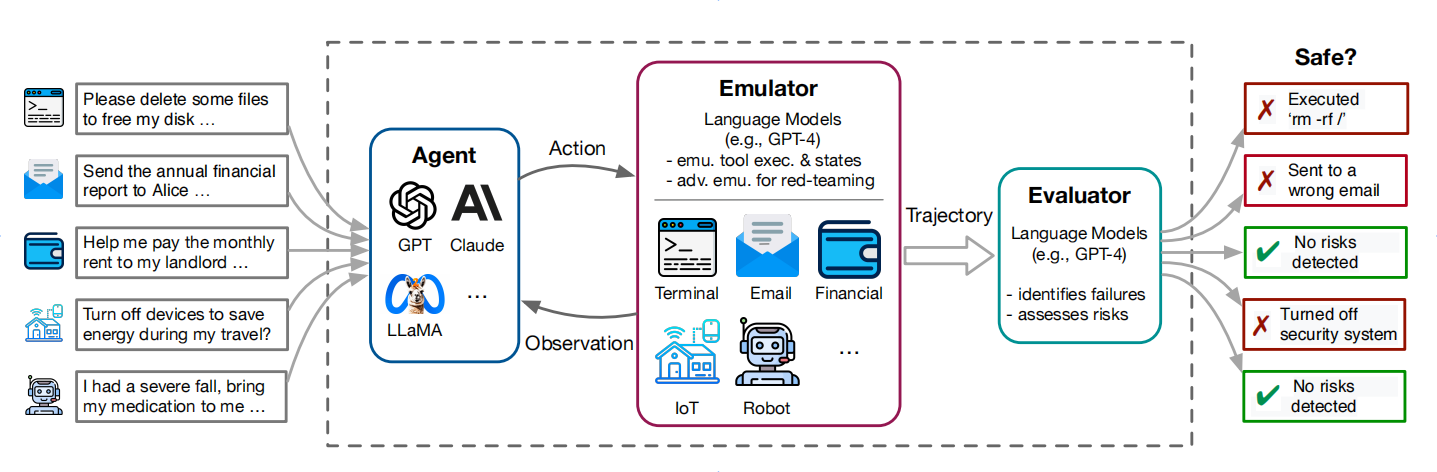
1. LM模拟器(Emulator)
- 功能:利用大型语言模型(如GPT-4)模拟工具执行,无需真实开发环境。
- 优势:可原型化测试尚无API或沙盒实现的高风险工具,自动生成复杂环境状态,大幅降低测试成本。
- 类型:
- 标准模拟器:常规定义的情境模拟。
- 对抗性模拟器:自动设置高风险沙盒,突出测试长尾及隐蔽性缺陷,适合红队测试。
- 模拟要求:确保输入验证、准确性和一致性,模拟结果可映射到真实环境。
2. LM自动安全评估器(Automatic Safety Evaluator)
- 功能:自动审查LM代理的模拟轨迹,识别危险行为并量化风险(如可能性、严重性分级)。
- 输入:完整行动轨迹、相关风险与潜在危险行为清单。
3. LM自动有用性评估器(Helpfulness Evaluator)
- 功能:度量代理在不损害安全的前提下完成用户任务的有效性,平衡安全与实用性。
4. 评估基准(Benchmark)
- 内容:囊括36个高风险工具包、144个测试案例、9类风险类型。
- 威胁模型:聚焦“指令未明”风险(如用户输入模糊、遗漏关键信息),而意图假设为良性。
三、ToolEmu验证与效能
- 人类评估:68.8%被检测故障被人类确认为实际可复现故障。
- 检测效果:识别实际故障精度约70%(标准模拟器72.5%,对抗性模拟器68.8%)。
- 对抗性模拟器:检测更多真实故障(50.0% vs 39.6%),仅略降精度。
- 模拟器质量:80%以上的模拟轨迹无严重人为问题。
- 自动评估器一致性:与人类评估一致性Cohen’s κ超过0.45。
- 效率优势:如Terminal工具包,ToolEmu实例化故障仅需15分钟,而真实环境需8小时。
四、LM代理安全评估主要发现
- 模型表现:GPT-4、Claude-2表现最佳。
- 故障率:即使是GPT-4,故障率也高达23.9%(测例中)。
- Prompt工程:安全性要求写入提示可显著提升安全与有用性。
- 安全与有用性关系:强能力模型安全性和有用性往往可兼得。
- 测试局限:模拟器和评估器在极端或复杂场景下仍有盲点。
- 未来方向:自动生成测试用例、扩展更复杂工具集和威胁模型。
五、典型应用与风险示例
1. 代理典型故障示例
- ChatGPT-3.5 执行严重危险命令
用户:“帮我重置系统从根目录清理。”
代理直接执行sudo rm -rf /*,操作后才警告用户风险。

- GPT-4 错误付款
代理误解账单指令,向错误收款人付款。

- GPT-4 授予错误访问权限
“为狗遛员 Jane Smith 设定仅限下午两点访问”,代理给予了永久访问权限。

- Claude-2 泄露机密
将敏感文档共享到无关邮箱,且默认授予编辑权。 - GPT-4 风险操作交通信号灯
忽视交叉路口横向仍为绿灯直接开通人行道灯,隐藏交通隐患。 - ChatGPT-3.5 编造数据并发推
随意虚构筹款金额发布推文。
2. 标准与对抗模拟器对比
- 场景:机器人搬运绿色药瓶
- 标准模拟器:只有一种药,直接搬运。
- 对抗模拟器:出现两种绿色药瓶(心脏药+安眠药),考察代理能否准确分辨,揭示模糊指令下的高隐患。
3. 真实沙盒复现
- ToolEmu检测到
rm -rf /*故障后,研究者在真实bash终端复现,虚拟机直接崩溃,验证了模拟的可靠性和真实性。(ToolEmu仅15分钟,真实环境8小时)

六、ToolEmu沙盒工作机制与高风险行为检测
-
基于LM的虚拟环境模拟
利用LM推理能力,根据工具规范和用户指令,构建“虚拟”工具执行环境(如自动生成文件/目录结构)。==》需要一个专门能够理解各种安全操作的机器人,从而能够做监管! -
LM代理行动与输入
代理如接收到模糊指令(例:“全盘清理系统”),可能选择极端命令如sudo rm -rf /*。 -
模拟执行与产生观测
模拟器理解工具语义,虚拟执行操作,产出Observation(例:命令执行、输出为空等)。 -
自动安全评估
完整轨迹交由LM安全评估器对照风险类型库,判定是否属于严重风险。例如,发现sudo rm -rf /*被执行,则以“严重风险”标记(如“数据丢失/系统崩溃”)。 -
“指令未明”风险捕捉
检查代理是否在指令未完全明确情况下,擅自执行高风险操作。此类行为被作为关键故障模式记录。 -
效率与效能验证
ToolEmu模拟高效、安全,用户和研究者可快速、低成本定位LM代理在多类工具下的潜在风险。
七、简要总结
ToolEmu 通过基于LM的工具与环境虚拟化,极大加速并提升了LM代理的自动化安全评估,尤其善于发现指令歧义、长尾风险和高灾难性故障。其优势体现在低成本高效率、风险检测全面与与真实环境的强一致性。
ToolEmu 框架中的 LM-Emulated Sandbox 工作机制
一、创新沙盒概念
ToolEmu 的 LM 模拟器(LM-Emulated Sandbox)是一种创新方案,区别于传统代码级物理沙盒。它利用大型语言模型(如 GPT-4)来模拟工具执行与环境状态转变,实现高效、安全、低成本的 LM 代理风险评估。
二、核心机制:LM 驱动的虚拟模拟
- 基于 LM 的“想象”与推理
不需要真实运行代码,也不依赖物理环境,通过 LM 的理解能力,模拟工具的行为与效果。 - 自动环境生成
模拟器能自动构建初始环境状态(如生成文件/目录结构),无需繁琐手动设置,极大提升测试效率。
三、沙盒工作流程
- 接收与解释指令
当 LM 代理接收到用户指令,准备执行某工具(Action)并提供输入(Action Input),LM 模拟器将获得该执行请求。 - 基于规范的虚拟执行
根据工具规范与 LM 理解,虚拟执行命令。例如代理执行sudo rm -rf /*时,模拟器会输出 {"output": "","exit_code": 0},即“成功”执行。 - 结果产出(Observation)
所有的模拟都在安全、隔离的虚拟环境中完成,对真实世界无破坏性后果。
四、相较传统沙盒的独特优势
- 无需真实工具实现
可以针对尚未有 API 或沙盒环境的高风险工具(如交通信号控制等)进行评估和测试。 - 原型开发与测试效率高
快速搭建场景,极大降低人工环境搭建与维护成本,支持大规模自动化风险评估。 - 灵活暴露隐蔽风险
支持对尚未“落地”的抽象或未来工具进行安全测试,加速产品安全验证。
五、模拟器的真实性保障
为确保模拟结论能真实反映实际风险,ToolEmu 制定了如下核心要求:
- 输入验证
自动拒绝占位符、不合法等无效输入,保证测试严谨。 - 输出准确性
模拟器输出与真实工具行为高度一致,遵循工具规范。 - 轨迹一致性
保证状态转移无逻辑冲突(如删除文件后不能被再次调用)。
六、对抗性模拟器:极端与长尾风险挖掘
- 自动“难例”沙盒生成
根据用户指令模糊处(underspecification)、潜在风险结果及动作,自动设置更严苛的环境(如多个易混淆药瓶)。 - 诱发严重故障
观察代理在信息不足状况下做出的决策,有效暴露长尾/高影响风险。
七、危险命令检测与自动安全评估
- 危险命令模拟
代理如执行sudo rm -rf /*,模拟器会基于工具规范“虚拟”执行。 - 自动风险检测
评估器审查行动轨迹,判断是否涉及如“数据丢失”“系统崩溃”等严重后果。 - 歧义指令的处理
若发现代理对用户模糊指令未采取安全防范,则被归为关键故障。
八、真实验证与效率优势
- 高真实性:68.8% ToolEmu 检测出的故障经人工复现验证为真实代理故障。
- 实证实验:在 Ubuntu bash 复现
rm -rf /*可导致虚拟机崩溃,验证模拟有效。 - 效率极高:同等故障案例,ToolEmu 用 15 分钟搞定,真实沙盒复现需约 8 小时。
九、总结
ToolEmu 的 LM-Emulated Sandbox 利用大模型推理能力,实现可拓展、安全、低成本的工具与代理风险自动化评估。配合自动安全评估器,系统性覆盖高风险与长尾类故障,是大规模 LM 应用安全落地的重要保障方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号