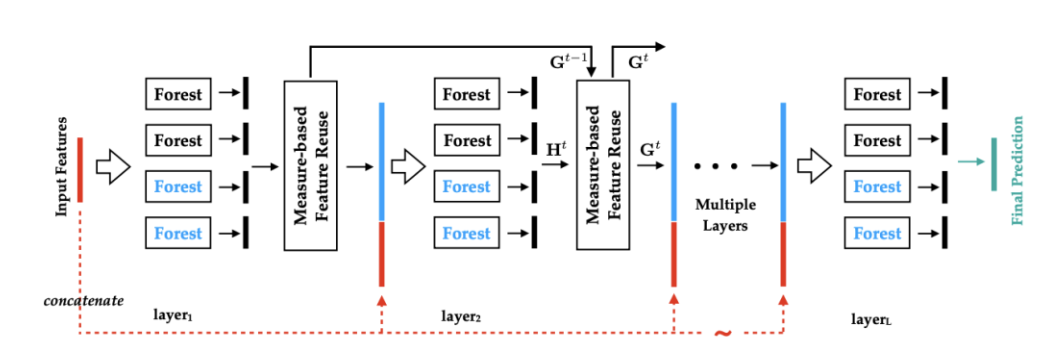
深度森林原理及实现——原来是借鉴了残差网络和highway的思想,将其用于树类算法
深度森林原理及实现
1 思想
1.1 作者周志华认为学习样本的差异性得到足够体现的时候,集成学习的效果会得到相应的提高。
1.2 多样的结构对集成学习是十分重要的。
1.3 Deep Forest 就是基于该想法来设计实现的。
2 介绍
Deep Forest是传统的森林在广度和深度上的一种集成。
2.1 在深度上集成的目的:提高分类能力
2.2 在广度上集成的目的:体现输入数据的差异性
3 深度学习与深度森林的关联:
3.1 深度学习最大的贡献是表征学习,发现更好的features。而后面用于分类(或其他任务)的function,往往也只是普通的softmax(或者其他一些经典而又简单的方法)而已。
3.2 所以,只要特征足够好,分类函数本身并不需要复杂。目前DL的成功,主要依靠神经网络对数据特征的强大表征能力,那么这种成功能否复刻到其他模型上呢?
3.3 南京大学的周志华老师尝试提出一种深度的tree模型,叫做gcForest,用文中的术语说,就是“multi-Grained Cascade forest”,多粒度级联森林。此外,还提出了一种全新的决策树集成方法,使用级联结构让 gcForest 做表征学习。
4 深度森林的整体架构
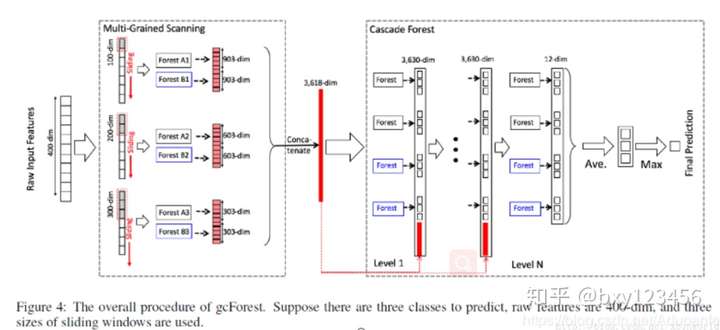 gcforest分类模型整体架构
gcforest分类模型整体架构
4.1 如上图所示,该深度森林用于三分类任务,主要有两部分构成:1)multi-Grained Scanning 2)Cascade Forest
4.2 multi-Grained Scanning:提取数据不同粒度的特征
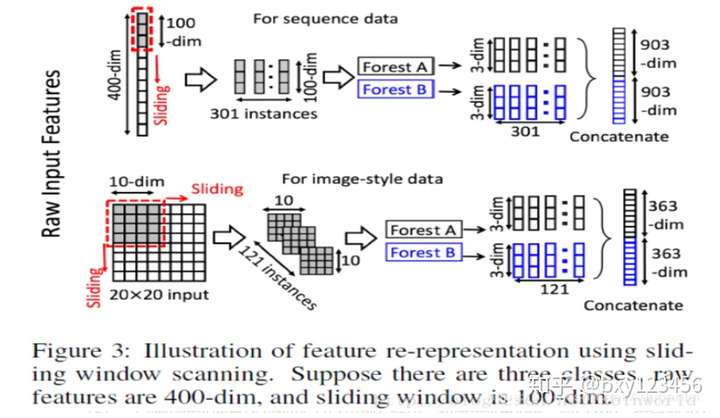
4.2.1 通过多个尺度的滑动窗口来获取input中的局部数值(不同于卷积操作,这里的窗口仅用于数值的获取,未进行数值的重新表示)。
4.2.2 将4.2.1处理得到的结果序列作为ForestA和ForestB的输入,由森林得出每个输入对应类别的概率。
4.2.3 将多个森林的多个结果进行拼接作为转换后的特征(用作Cascade Forest模块的输入)
4.3 Cascade Forest
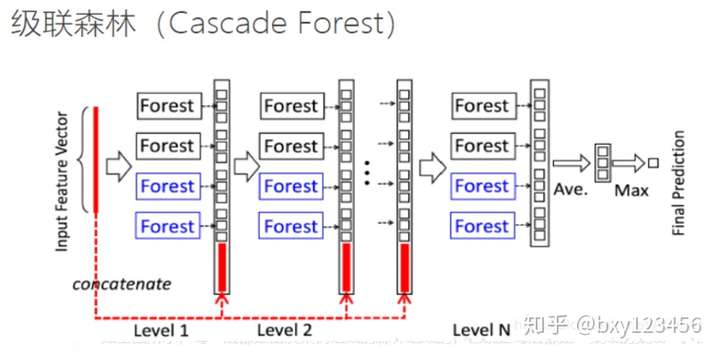
4.3.1 特点:
1)每一层都由多个森林集成得到。就森林而言,本身已经是一种决策树的集成的产物,因此,级联森林是一种集成的集成(即超集成)。
2)每一层有两种不同的森林构成:一种是完全随机森林,另外一种是随机森林。
4.3.2 工作流程:

5.查漏补缺(1 完全随机森林和随机森林)
5.1 完全随机森林:由多棵树组成,每棵树包含所有的特征,并且随机选择一个特征作为分裂树的分裂节点。一直分裂到每个叶子节点只包含一个类别或者不多于是个样本结束。
5.2 随机森林:同样有多棵树构成,每棵树通过随机选取Sqrt(特征总数)个特征 ,然后通过GINI分数来筛选分裂节点。
5.3 区别:两种森林的不同主要在于其特征空间的不同,完全随机森林是在完整的特征空间中随机选取特征来分裂,而普通随机森林是在一个随机特征子空间内通过gini系数来选取分裂节点。
6 级联森林的层数选择问题
6.1 gcForest中级联森林部分的level是自适应的,不用人工提前设定。
6.2 原理:
6.2.1 首先会在一级结束后做一个性能测试,然后再继续生成下一级,当扩展一个新的级后,整个级联的性能将在验证集上进行估计,如果没有显着的性能增益,训练过程将终止。
6.2.2 因此,gcForest能够通过适当的终止,来决定其模型的复杂度,这就使得相对于DNN,gcForest在即使面对小数据集的情况下一样使用,因为它的结构不依赖于大量的数据生成。
7 总结
7.1 gcForest可以处理不同规模的数据,具有更加稳定良好的学习性能。深度神经网络需要大规模的训练数据,而 gcForest 在仅有小规模训练数据的情况下也照常运转。
7.2 gcForest不需要设置超参数,通过在具体数据集上训练误差最小化来自动设定。实际上,在几乎完全一样的超参数设置下,gcForest在处理不同领域的不同数据时,也能达到极佳的性能。
7.3 相比于神经网络,深度森林的树结构具有更好的解释性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号