

03.深度学习简介
01.定义一个function
深度学习和机器学习一样,也可以是三个步骤:第一,定义一个function,这个function就是一个Neural network。在机器学习简介中写到过,我们把多个逻辑回归前后链接在一起,之后把一个逻辑回归的单元称为一个神经元Neural,整个组合起来的网络结构就叫做神经网络Neural network,其中我们有很多逻辑回归,每一个逻辑回归都有自己的权重weight和自己的偏好bias,这些weight和bias集合起来就是这个network的参数parameter,这里用θ表示出来。
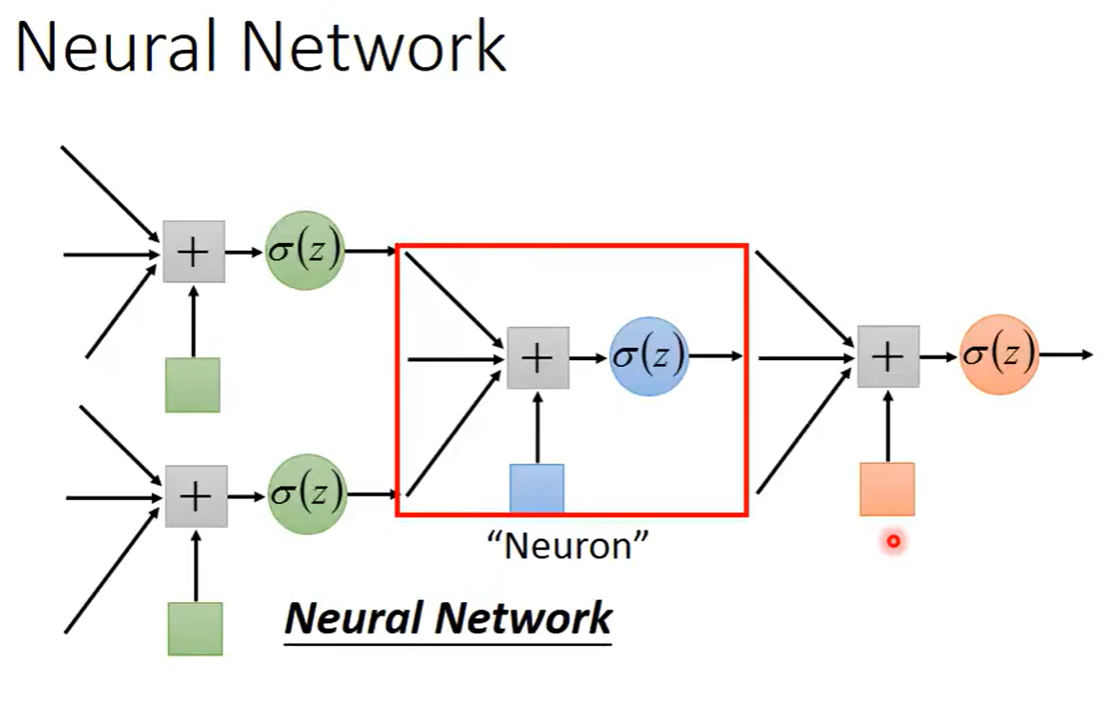
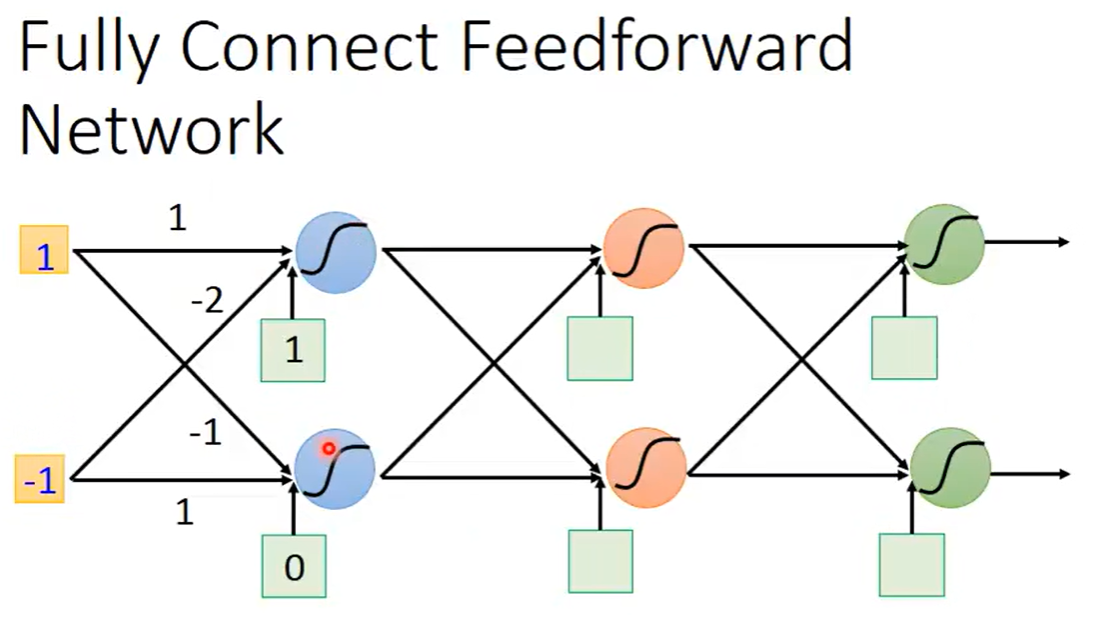
对于这些逻辑回归或这些神经元,我们的连接方法是自己手动设计的,最常见的连接方式是Fully Connected Feedforward Network(全连接前反馈网络),在这个网络中,可以把神经元排成一排排,每一个神经元都有一组weight一组bias,这个参数都是根据训练数据找出来的。
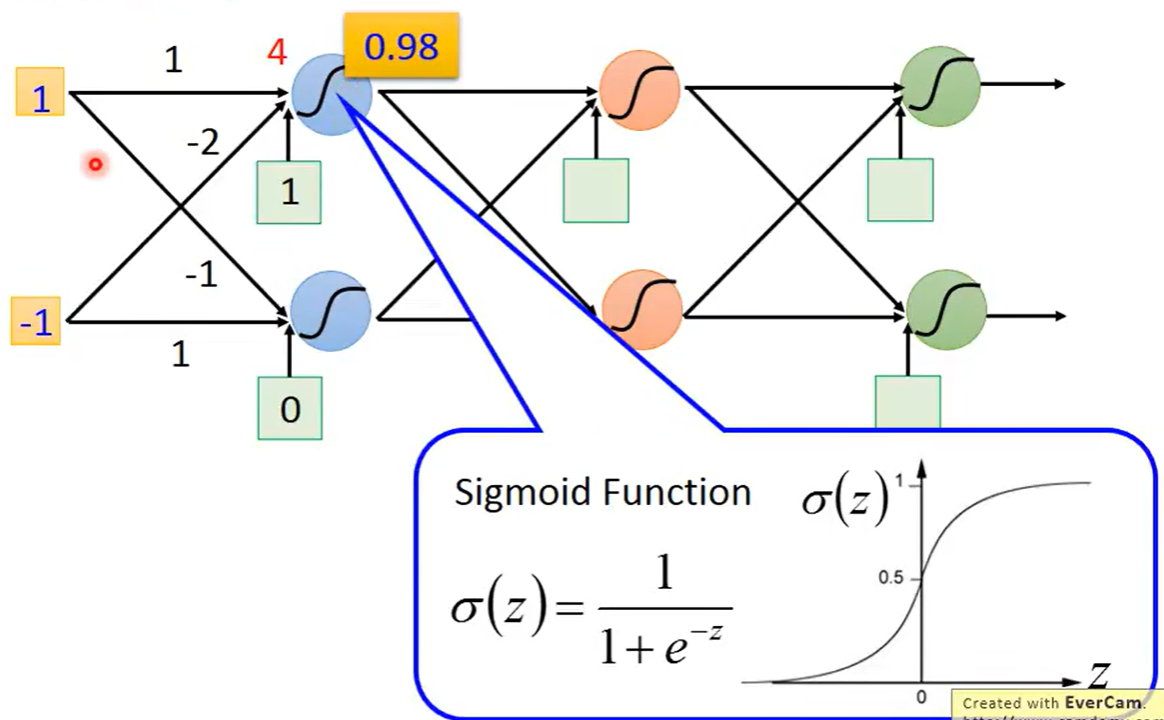
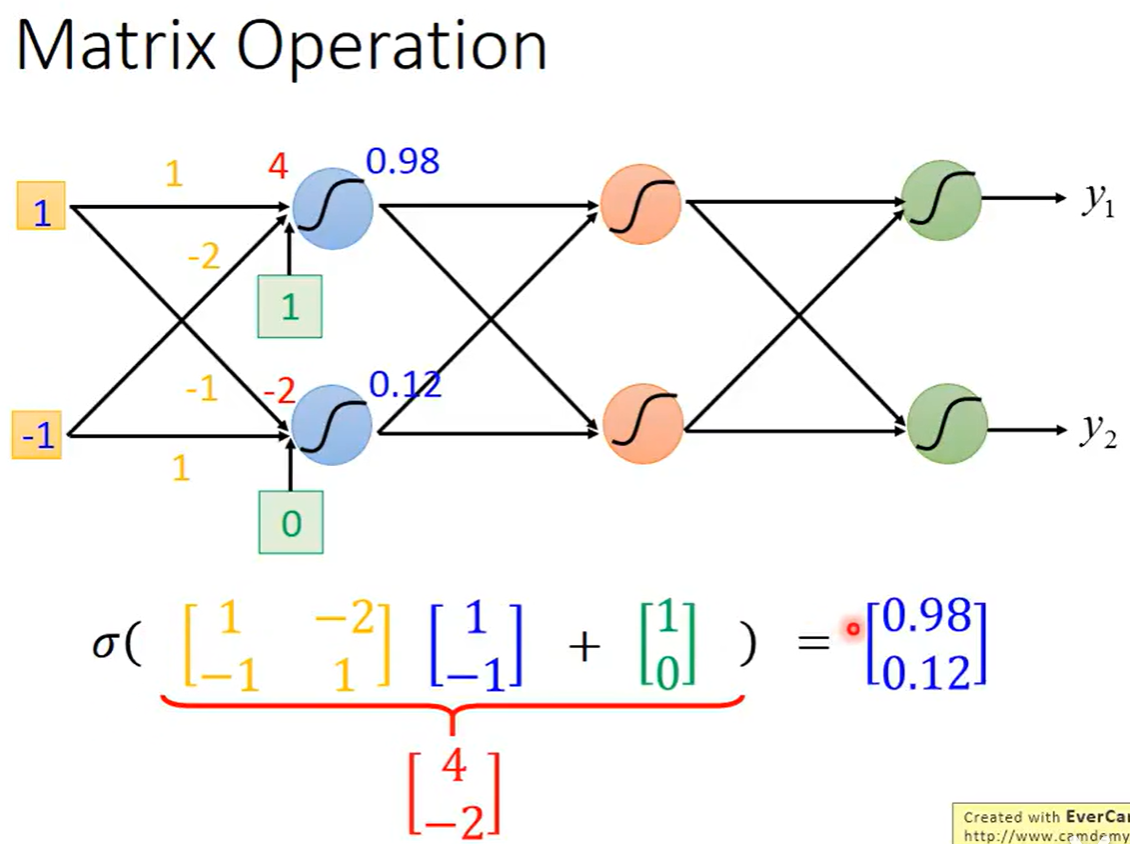
假设有一组输入是1和-1,第一个神经元的weigit分别是1和-2,bias是1,第二个神经元的weight是-1和1,bias是0,经过计算得到z=4,代入sigmoid函数得到为0.98,第二个神经元用同样的方式得到结果是0.12
假设每一个神经元的weight和bias都是已知的,我们就可以继续向前进行多层的计算,所以一个神经网络如果里面的参数我们都知道的话,这个神经网路就可以被看作是一个function,这样,输入input是一个变量,输出output是另一个变量
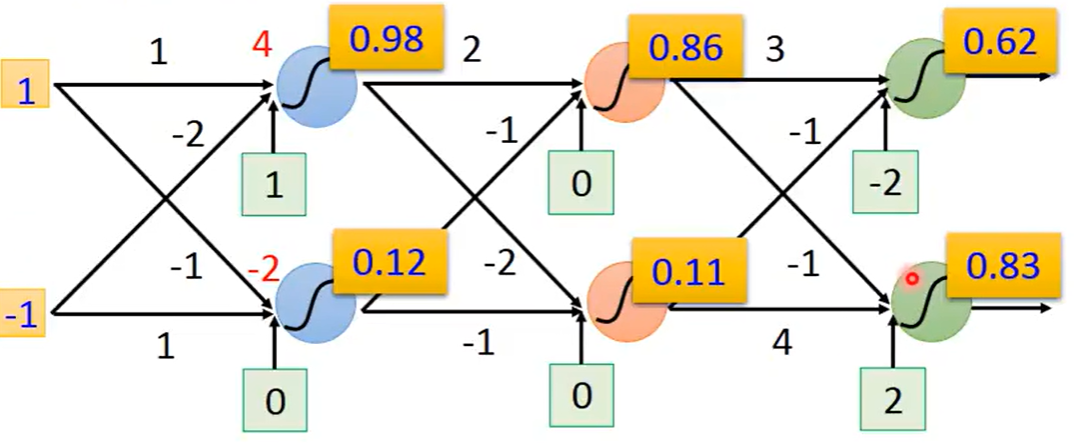
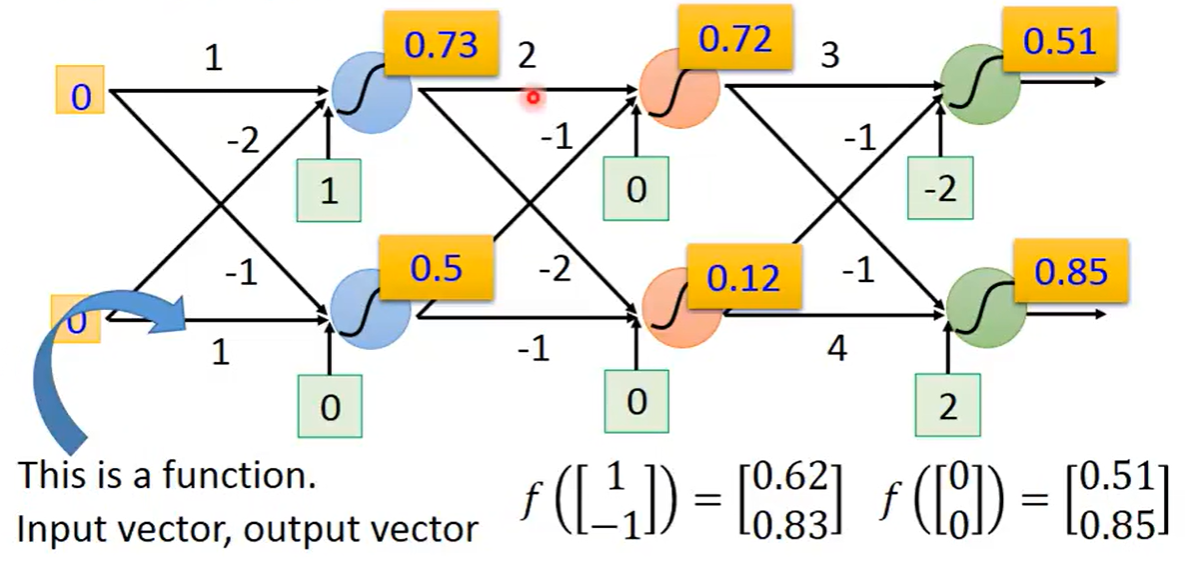
如果对于神经网络中的参数并不清楚,仅仅只知道这些神经元是如何连接在一起,这样子的一个神经网络结构,其实就是定义了一个function set,可以给这个网络设置不同的参数,它就可以变成不同的function,把这些可能的function结合起来,我们就得到了一个function set
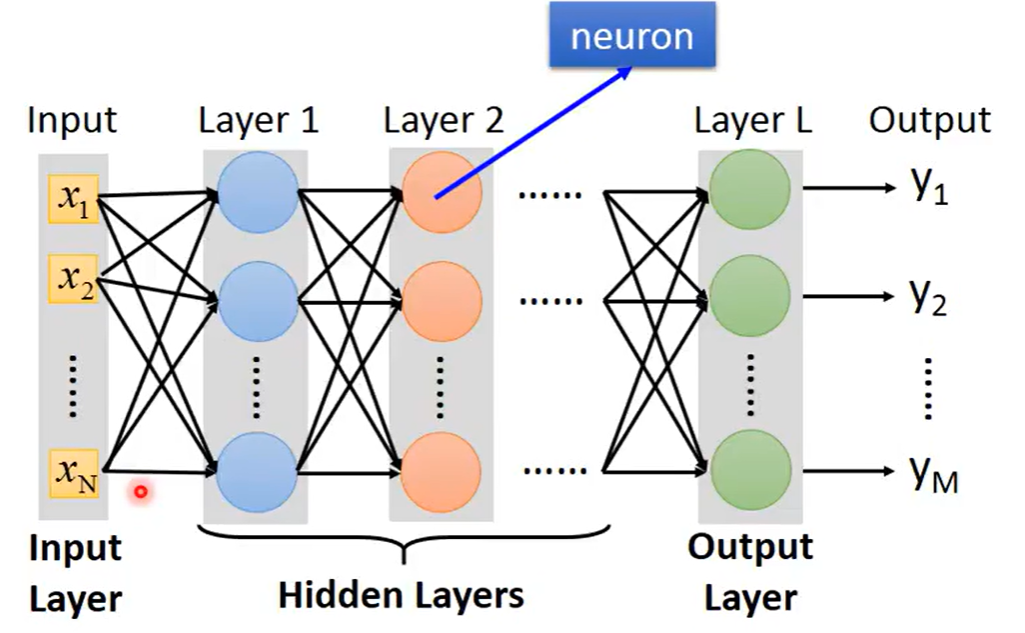
总体而言,我们可以把神经网络画成很多排的神经元,每一排中的神经元数目可能是很多成百上千个也可以,在层与层之间的神经元是两两相连的,比如第一排的output都会接给每一个第二层的神经元的input,整个神经网络主要可以分为输入层,输出层和隐藏层组成,所以深度学习的deep,表示有很多隐藏层才会叫deep
Matrix Operation(矩阵运算)
通过矩阵运算来表示神经元上发生的运算
将这种方式推广到一般,将每一排的所有weight写在一起,每一排的所有bias写在一起,之后假设每一个神经元的函数都是sigmoid函数,一层一层的迭代下去会得到最终结果,写成矩阵运算的好处就是,可以采用GPU进行
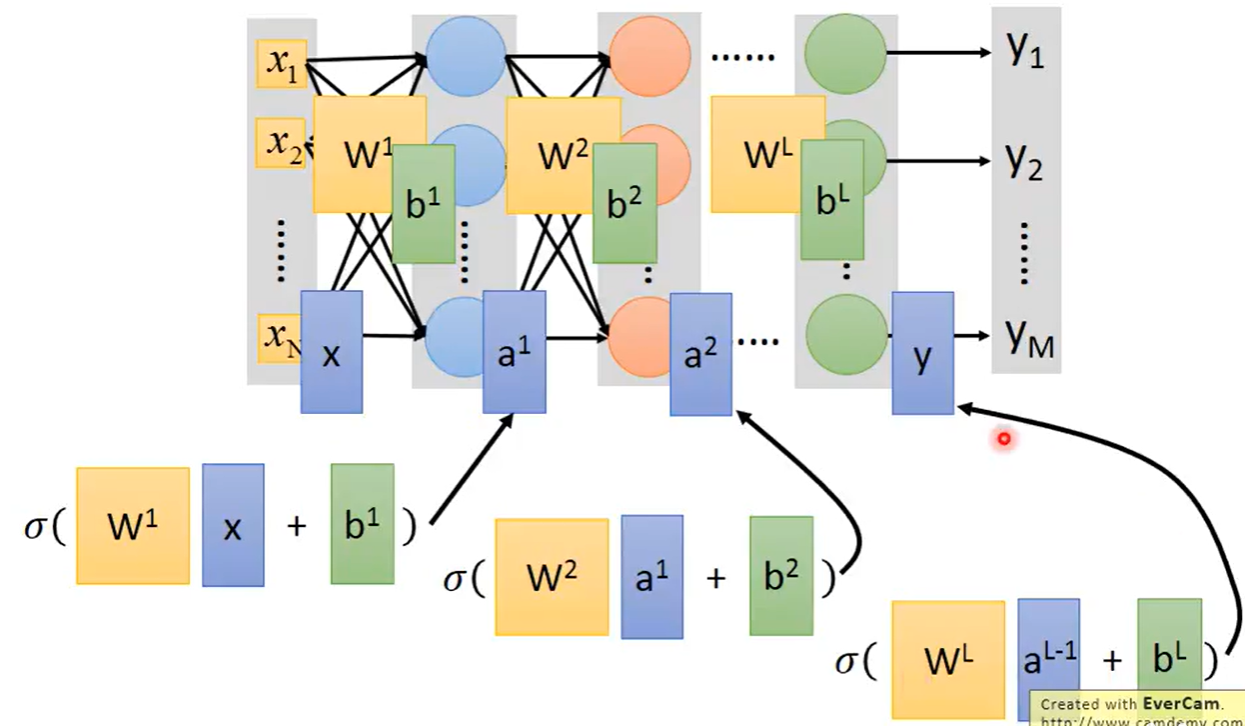
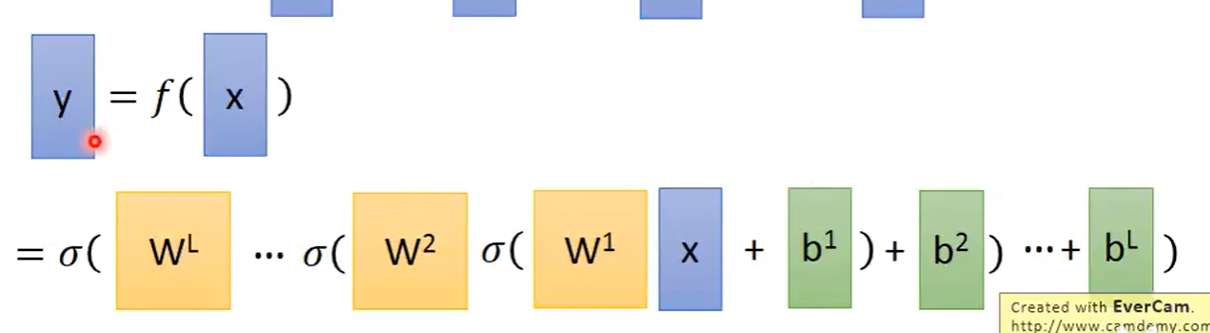
我们可以把输出层之前的部分看作是一个feature的extractor(特征提取器),它代替了我们需要进行手动做特征提取。
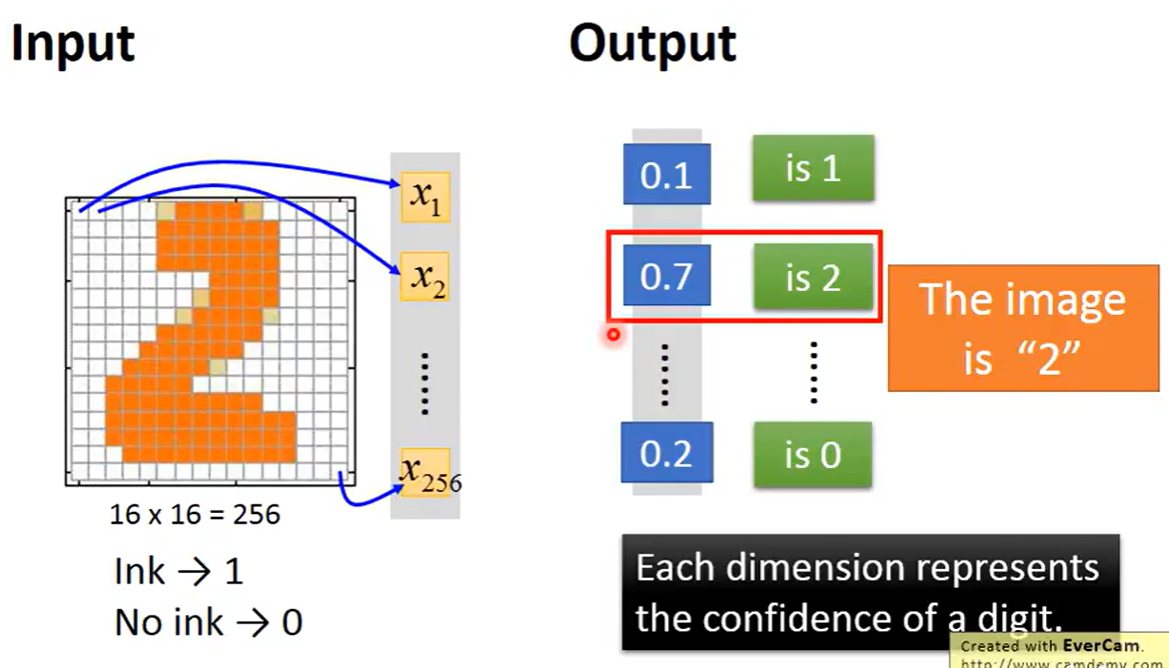
假设我们要分析一个16*16的像素的图片是什么数字,我们将其写成一个向量,表示这个图片,把涂黑的地方表示1没有涂黑的是0,假设我们的output是10维的,那么通过softmax进行分析之后可能的得到的10个结果表示的分别是0-9的概率是多大 。假设要进行这个实验的function输入是256维的向量,输出是10维的向量,这个function就是神经网络。
02.定义一个function的好坏
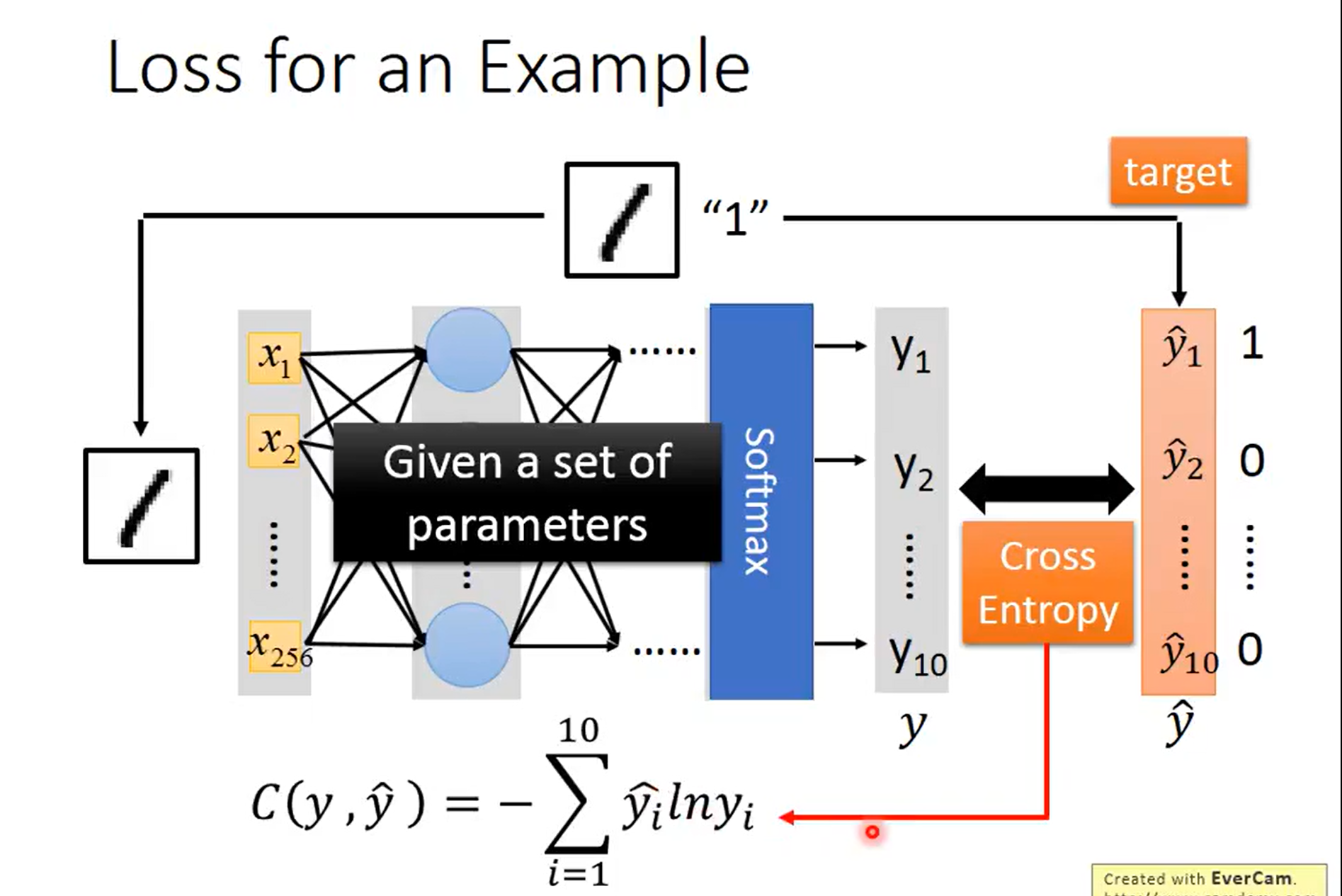
我们想要的是最终结果的预测概率中,在1的地方是1其余地方全为0,然而得到的结果不会这么理想,于是就计算得到的结果和实际的现实之间的差距
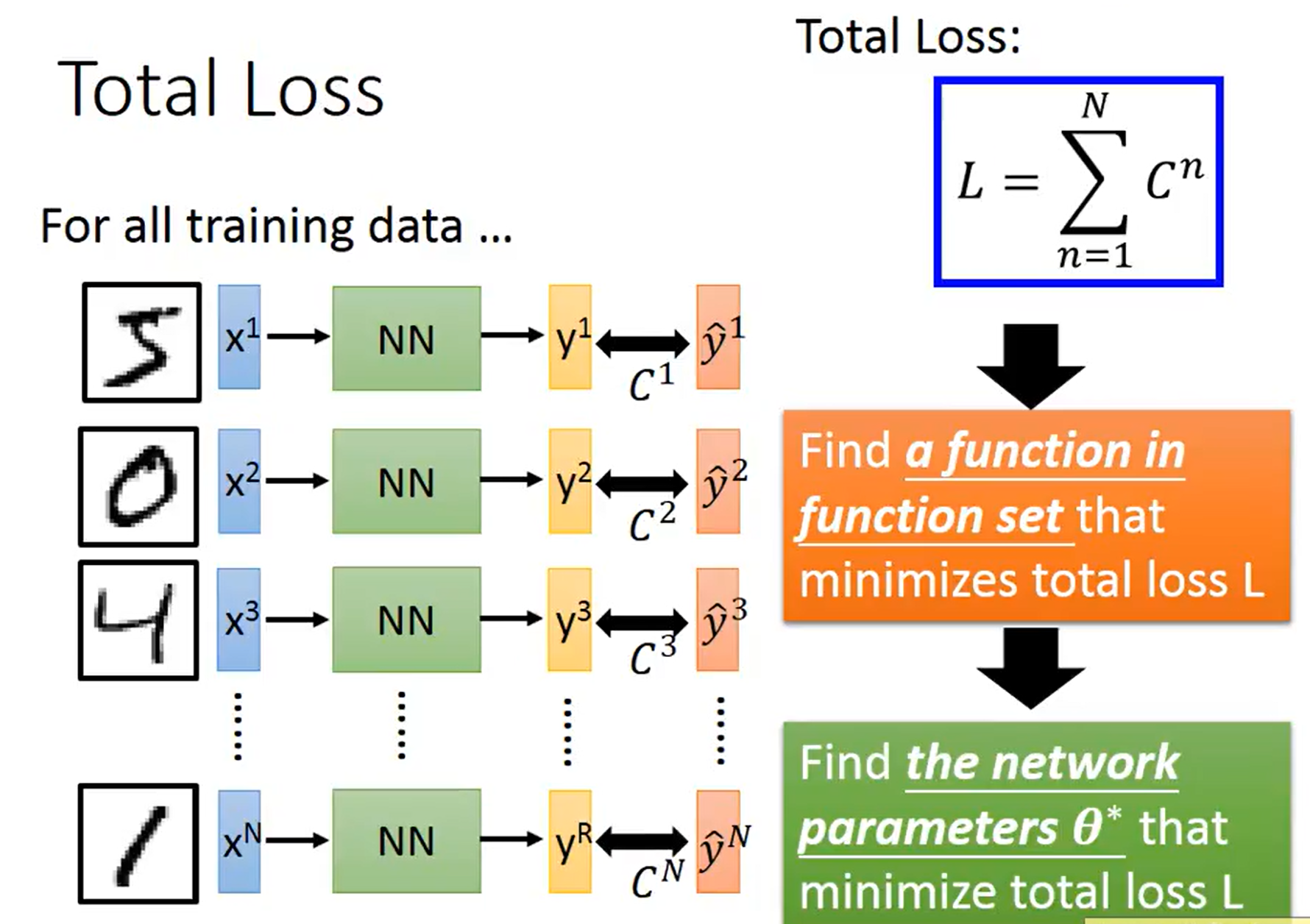
当然,在训练集中我们并不是只有一个数据,我们需要将每一个数据算出来的loss函数进行相加,最后得到一个total loss函数,然后我们的目标就成了找到一个function使得整个loss函数最小,也就是找到一组参数值让整个loss函数最小
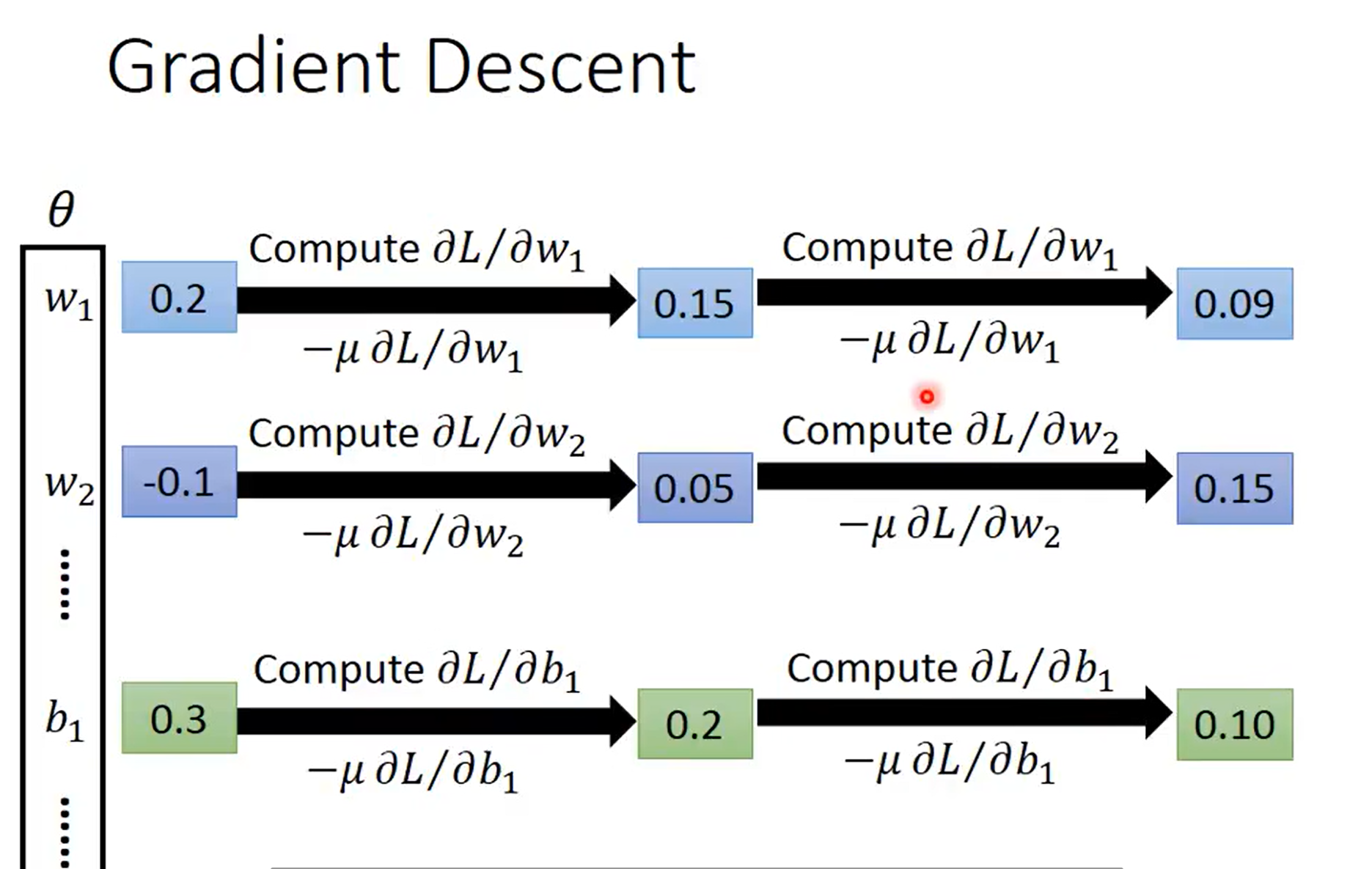
我们使用的方法,就是梯度下降,对每一个参数求偏微分,之后再同时更新这些参数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号