

ChatGPT简介
背景
去年12月1日openAI发布了自然语言生成模型chatGPT,一个可以基于用户输入文本自动生成回答的人工智能,也就是智能聊天机器人。它有着赶超人类的自然对话程度以及逆天的学识。不论是夸人、讲笑话、讲相声、续写故事、甚至成为自己的互联网嘴替都是可以在相似程度和口吻上和人类高度一致。
当然在实际工作上它也是有着极高的生产效率,不论是实际工作,解释概念,查询菜谱,查询代码甚至编程问题,比如找出代码中的bug,或者写出某些程序,都是可以完成。这种快问快答的直观交互方式,远超大部分引擎。除此之外在其他方面,产品文档、检讨书、年终总结、招聘策划、自我介绍、求职信、拒绝信、辞职信等都可以有很高的利用价值。
-
所以为什么chatGPT会有这么出色的表现?
-
它的聊天能力,文学能力,编程能力到底有多强?
-
它会取代搜索引擎吗?
ChatGPT到底是什么
ChatGPT是一款通用的自然语言生成模型,其中GPT是Generative Pretrained Transformer的简称,也就是生成型预训练变换模型,传统的语言模型的工作方式是对语言文本进行概率建模用来预测下一段输出内容的概率,形式上非常类似小时候玩的文字接龙游戏
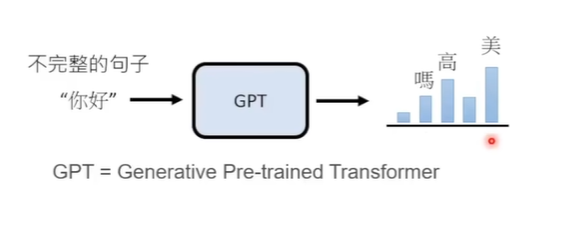
这一次之所以能有如此之大的反响,很大程度上是因为他在语言能力上的显著提升
ChatGPT相对于其他的聊天机器人,有哪些显著提升
-
对用户实际意图的理解,不用和机器人来回兜圈子
-
出色的上下文衔接能力,不仅能够问一个相对复杂的问题,而且可以通过不断追加提问的方式,让他不断地改进回答内容,最终达到用户的理想效果。
-
对知识和逻辑的理解能力,对一个问题不仅能够很好的回答,同时对这个问题的各种细节追问,也可以很好的回答出来
ChatGPT和openAI今年一月份发布的另一个模型instructGPT是非常接近的姊妹关系,两个模型的训练过程也非常接近,因此可以作为非常可靠的参考
instructGPT对比上一代GPT3
-
71%-88%的情况下更加符合人类喜好
-
编造回答的概率从41%下降到21%,也就是被问到不知道的问题时instructGPT只有21%的概率会编造回答
-
产生胡言乱语的情况的概率减小了25%
所以instructGPT相对于上一代可以提供更加真实可靠的回答,其回答内容也更加符合人类喜好
ChatGPT的发展过程
ChatGPT是intructGPT的姊妹版本,也就是针对于intructGPT做出了一些调整

同样是来自于transformer架构上的分支,BERT和GPT的一大不同,来自于他们transformer具体结构的区别。
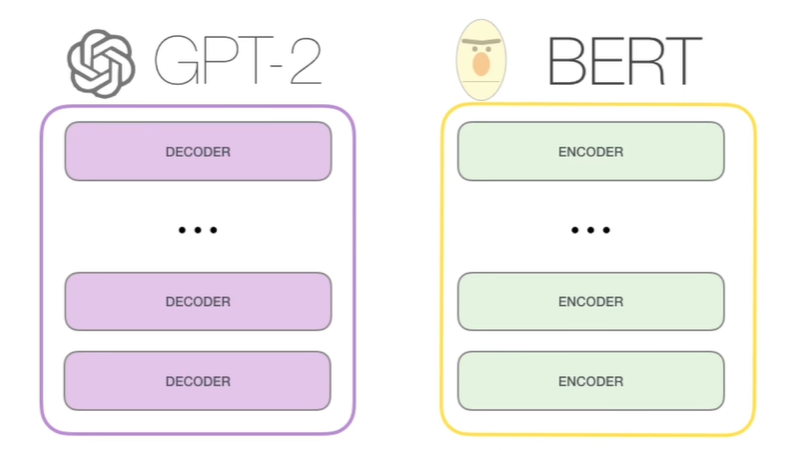
BERT使用的是transformer的encoder组件,encoder组件在计算某个位置时,会关注它左右两侧的上下文信息
GPT使用的是transformer的decoder组件,decoder组件在计算某个位置时,只关注它左侧的上文信息
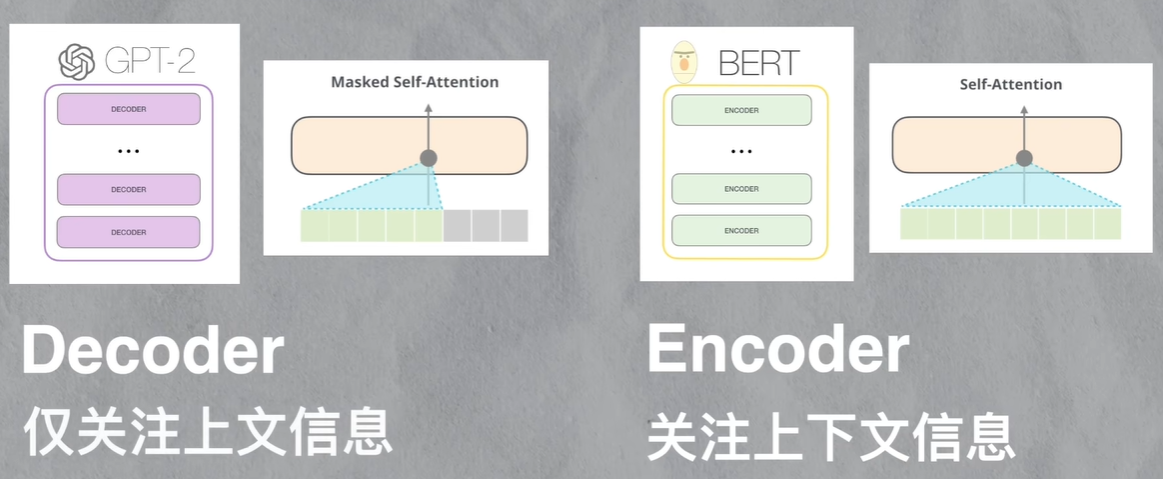
通俗一些来讲,BERT在结构上对上下文的理解会更强,更适合嵌入式的表达(完形填空式的任务)。GPT在结构上更适合只有上文,不知道下文的任务(聊天)
模型量级提升
从GPT到GPT-2再到GPT-3,openAI将模型参数从1.17亿提升到了15亿个,之后又进一步提升到了1750亿个,以至于GPT-3比以前同类型的模型,参数量增加了10倍以上,训练数据量也从5GB暴力提升到45TB,在方向上**openAI没有追求模型在特定类型任务上的表现,而是不断地增强模型的泛化能力(应对各种没有见过的问题的能力)
基于人类反馈的强化学习
从GPT3到intructGPT的一个有趣改进来自于引入了人类的反馈,用openAI论文的说法是,在intructGPT之前,大部分大规模语言模型的目标,都是基于上一个输出片段,预测下一个输出片段,但这个目标和用户意图是不一致的,用户的意图是让语言模型有效并且安全地遵循用户的指令
为了达到对用户意图的理解,他们引入了标记人员,通过标记人员的人工标记,来训练出一个反馈模型,这个反馈模型,实际上就是一个模仿人类喜好,用来给GPT-3的结果来打分的模型,之后再用这个反馈模型再去训练GPT-3
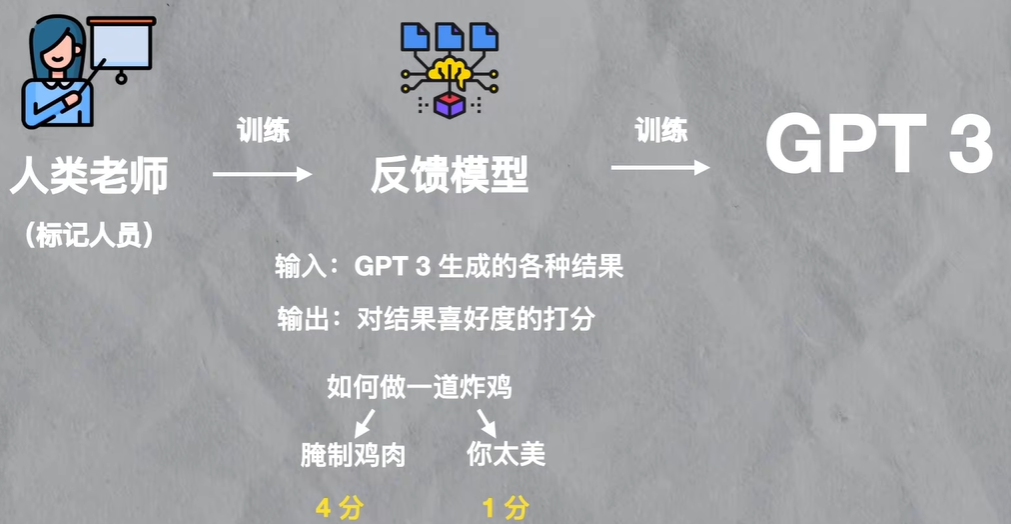
这个反馈模型,就相当于被抽象出来的人类意志,可以用来激励GPT-3的训练,这整个训练方法就被叫做基于人类反馈的强化学习
至此可以发下openAI一直在追求的几个特点:
-
只有上文的decoder结构:这种结构训练出来的模型更加适合问答模式
-
通用模型:openAI一直避免在早期架构和训练阶段,就针对某个特定的行业做调优,这也上GPT-3有着很强的通用和泛化能力
-
巨量的数据和巨量的参数,让语言模型涵盖了人类生活中会涉及的几乎所有的自然语言和编程语言
上下文对话的原理
语言模型生成回答的方式,其实是基于一个个的token(粗略地理解为一个个单词),所以ChatGPT生成的一句话的回答,其实是从第一个词开始,重复把问出的问题以及当前生成的所有内容,再做为下一次的输入,再生成下一个token,直到生成完整的回答。

既然一句话是基于前面所有的上文一个个词生成的,那同样的原理,也可以把之前的对话作为下一次问题的输入,这样下一次的回答,就可以包含之前对话的上下文,chatGPT的上下玩大概是4000个token。
文章笔记来自于b站主:不说话的白菜

 浙公网安备 33010602011771号
浙公网安备 33010602011771号