28-python验证码识别、爬虫技术、信息收集以及python调用awvs
1、复习python如何识别验证码
环境:使用 ddddocr 库:pip install ddddocr
-
基础ocr识别能力:
主要用于识别单行文字,即文字部分占据图片的主体部分,例如常见的英数验证码等,本项目可以对中文、英文(随机大小写or通过设置结果范围圈定大小写)、数字以及部分特殊字符。
# example.py import ddddocr ocr = ddddocr.DdddOcr() image = open("example.jpg", "rb").read() result = ocr.classification(image) print(result)对于部分透明黑色png格式图片得识别支持:
classification方法 使用png_fix参数,默认为Falseocr.classification(image, png_fix=True)注意:只需初始化一次ddddocr,即执行
ocr = ddddocr.DdddOcr() -
示例
在根路径下准备好,要识别的验证码图片 index.png

执行,成功识别
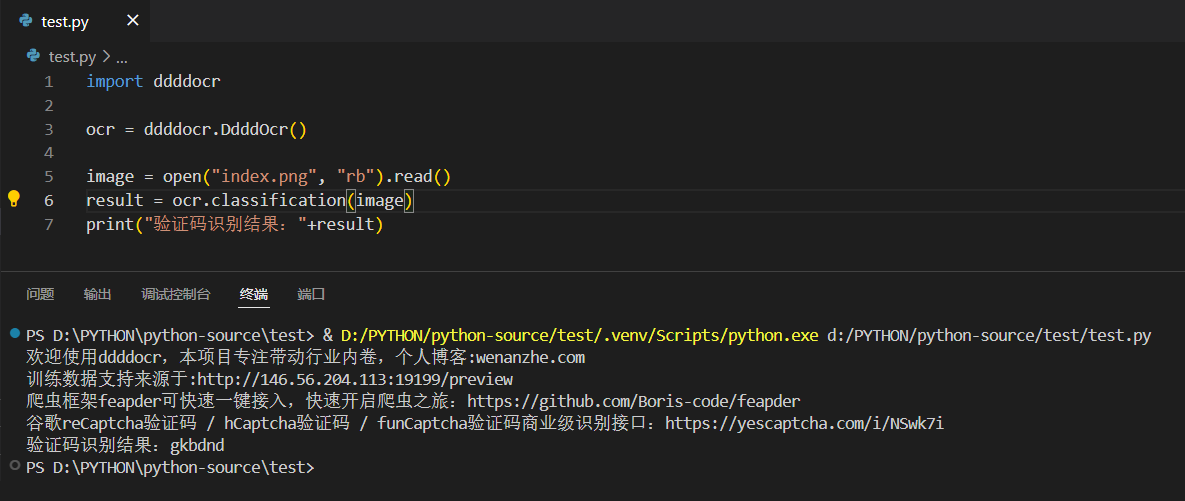
2、复习bs4库的常见用法,如何通过bs4库查找网页中的特定标签
概述:BeautifulSoup是Python的一个HTML/XML解析库,主要用于从网页中抓取数据。它提供简单的函数处理导航、搜索和修改解析树。
-
使用方法
-
安装:
pip install beautifulsoup4 -
导入:
from bs4 import BeautifulSoup -
创建对象:
soup = BeautifulSoup(html_content, 'html.parser')常用解析器:
html.parser(Python内置)、lxml(速度快)、html5lib(容错性好)
-
-
查找特定标签的方法
-
直接访问标签
soup.title # 获取第一个<title>标签 soup.head # 获取第一个<head>标签 soup.p # 获取第一个<p>标签 -
查找所有特定标签
# 查找所有<a>标签 all_links = soup.find_all('a') -
根据属性查找标签
# 查找 class 为 "example" 的所有 <div> 标签 div_tags = soup.find_all('div', class_='example') -
查找嵌套标签
# 查找 <div> 标签下的所有 <p> 标签 div_tag = soup.find('div') p_tags = div_tag.find_all('p') for p in p_tags: print(p.text) -
使用CSS选择器查找标签
# 使用 CSS 选择器查找所有 class 为 "example" 的 <div> 标签 div_tags = soup.select('div.example')
-
3、复习selenium爬虫的基本使用,复现登录dvwa的实验
概述:Selenium爬虫是一种利用 Selenium 框架模拟浏览器行为来抓取网页数据的爬虫技术。
环境:selenium 库:pip install selenium、ChromeDriver 和 Chrome 浏览器。
-
基本使用
-
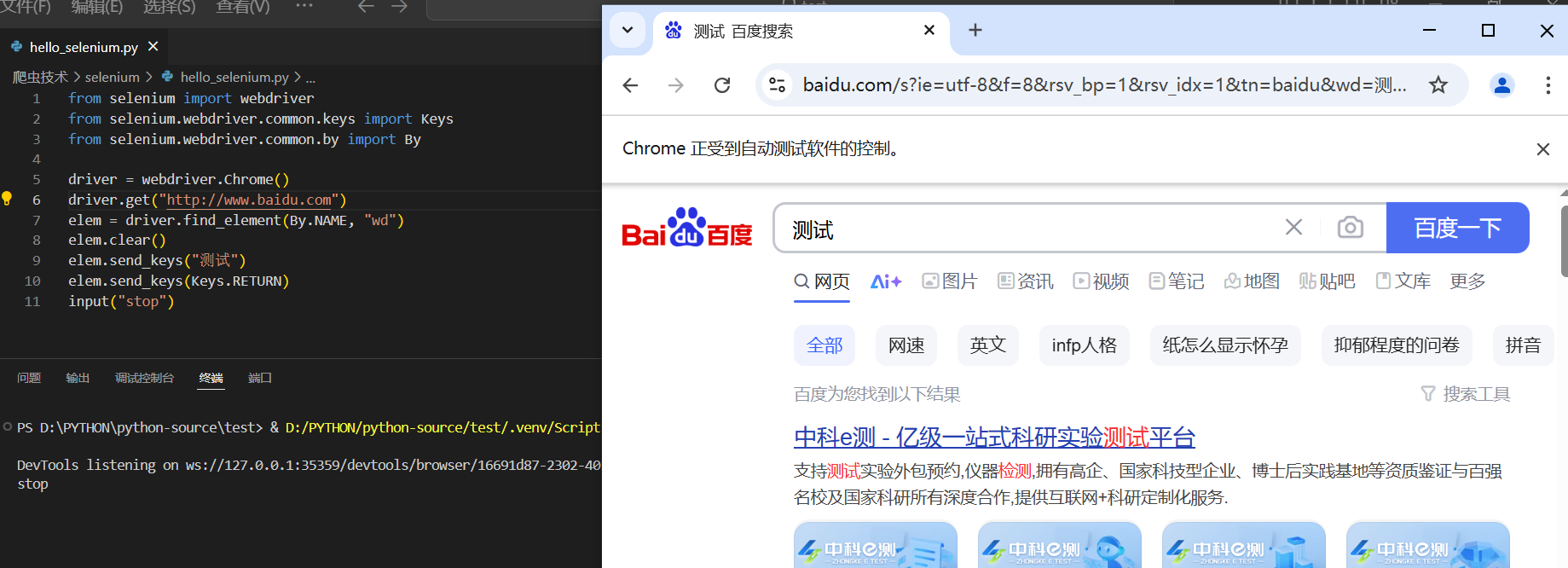
打开百度并搜索测试
from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get("http://www.baidu.com") #打开网站 elem = driver.find_element(By.NAME, "wd") #查找到输入框 elem.clear() #清空输入框内容 elem.send_keys("测试") #输入“测试” elem.send_keys(Keys.RETURN) #回车 input("stop") #停止关闭窗口运行结果如下图:
-
-
复现登录 dvwa
-
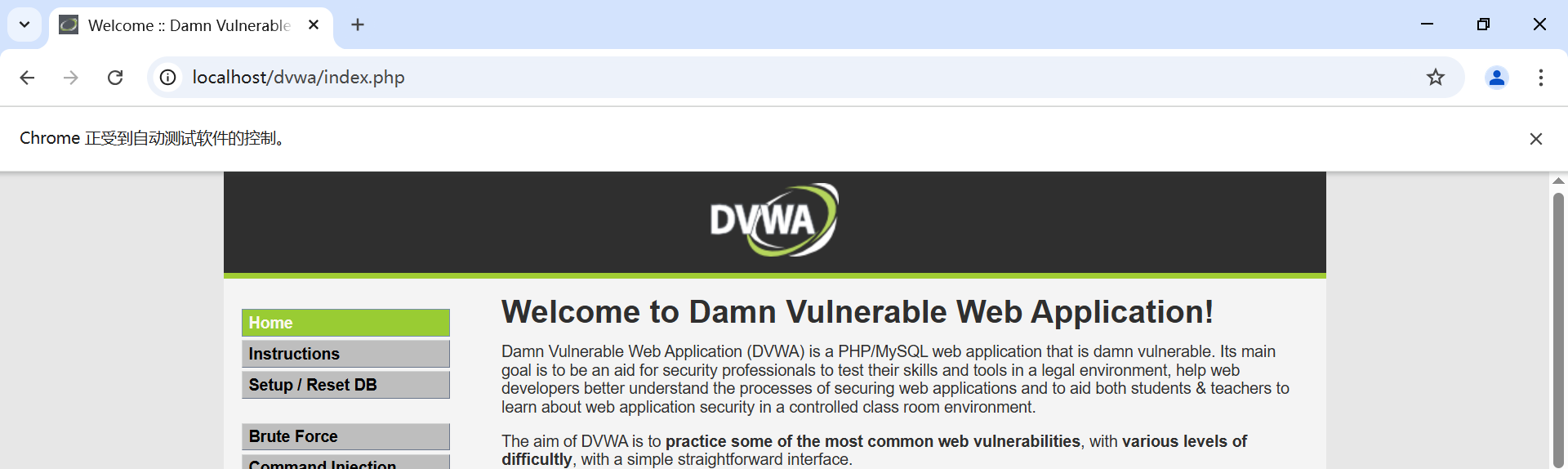
使用小皮开启DVWA:http://localhost/dvwa/
-
查看 DVWA 源码 找到用户名与密码输入框的标签
name="username",另⼀个name="password",xpath 地址(右键 > 检查 > copy > copy xpath)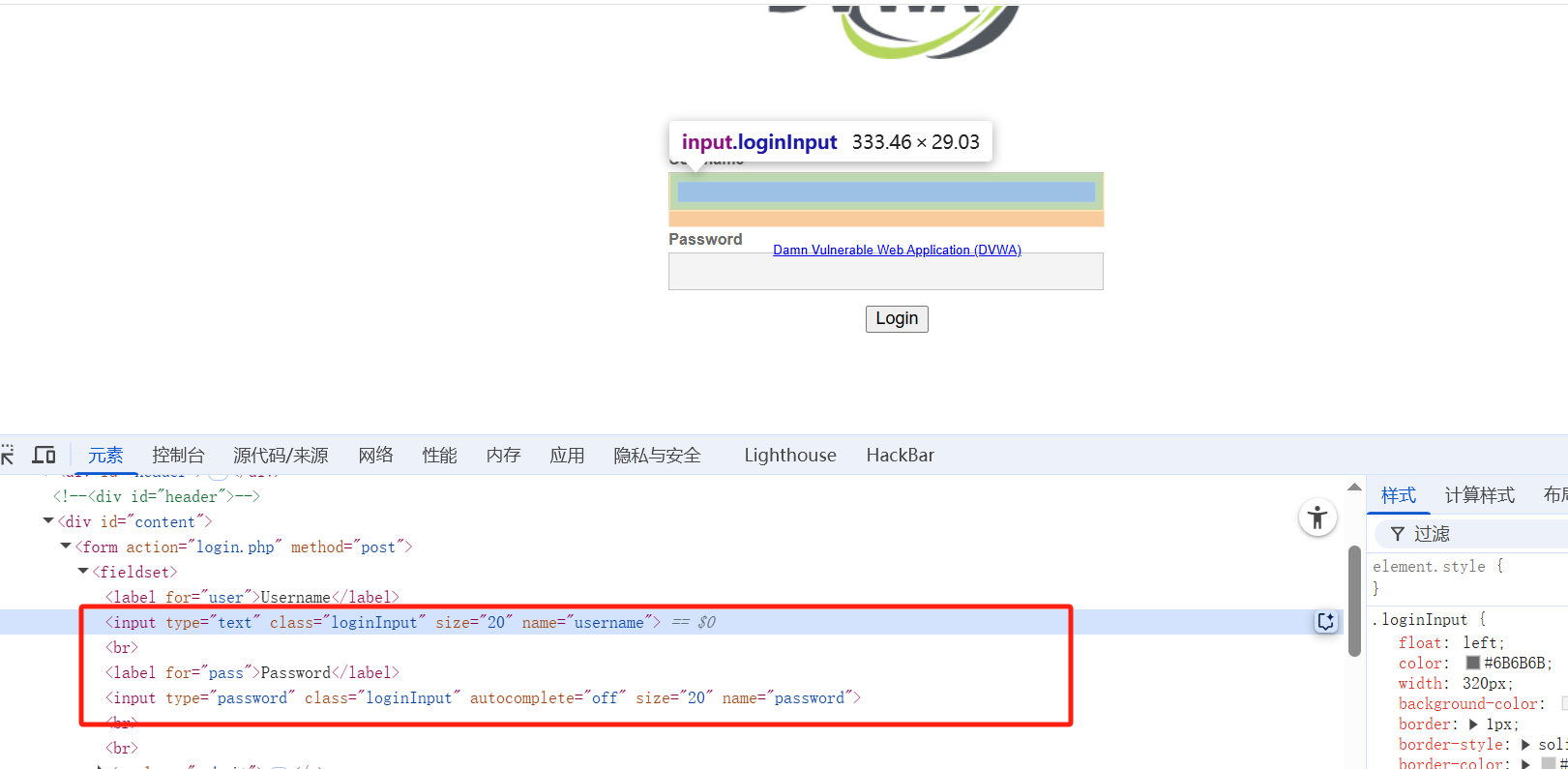
-
代码实现
-
通过程序定位标签
#实现方法1:XPATH user_elem = driver.find_element(By.XPATH, '//*[@id="content"]/form/fieldset/input[1]') pass_elem = driver.find_element(By.XPATH, '//*[@id="content"]/form/fieldset/input[2]') #实现方法2 user_elem = driver.find_element(By.NEAM,"username" ) pass_elem = driver.find_element(By.XPATH,"password") -
入输账号密码
# 清空节点默认值 user_elem.clear() # 清空节点默认值 pass_elem.clear() # 设置username标签节点内容为 admin user_elem.send_keys("admin") # 设置password标签节点内容为 password pass_elem.send_keys("password") -
点击登录
# 获取登陆按钮节点 //*[@id="content"]/form/fieldset/p/input login_butten_elem = driver.find_element(By.XPATH, '//*[@id="content"]/form/fieldset/p/input') # 点击登陆按钮 login_butten_elem.click()根据以上逻辑,完整代码如下
from selenium import webdriver from selenium.webdriver.common.by import By print("Start Magedu Selenium Test Project....") driver = webdriver.Chrome() # 设置访问的地址 driver.get("http://localhost/dvwa/") # 使⽤XPATH⽅式获取html标签节点,此处为获取 input 标签中名称为 username 的节点 #user_elem = driver.find_element(By.XPATH, "//input[@name='username']") user_elem = driver.find_element(By.XPATH, '//*[@id="content"]/form/fieldset/input[1]') # 获取input标签,名称为password的节点 #pass_elem = driver.find_element(By.XPATH, "//input[@name='password']") pass_elem = driver.find_element(By.XPATH, '//*[@id="content"]/form/fieldset/input[2]') # 清空节点默认值 user_elem.clear() # 清空节点默认值 pass_elem.clear() # 设置username标签节点内容为 admin user_elem.send_keys("admin") # 设置password标签节点内容为 password pass_elem.send_keys("password") # 获取登陆按钮节点 login_butten_elem = driver.find_element(By.XPATH, '//*[@id="content"]/form/fieldset/p/input') # 点击登陆按钮 login_butten_elem.click() # 打印User-Agent print(driver.execute_script("return navigator.userAgent")) print(driver.get_cookie("PHPSESSID")) input() # 关闭浏览器环境 driver.close()
-
-
运行实现结果
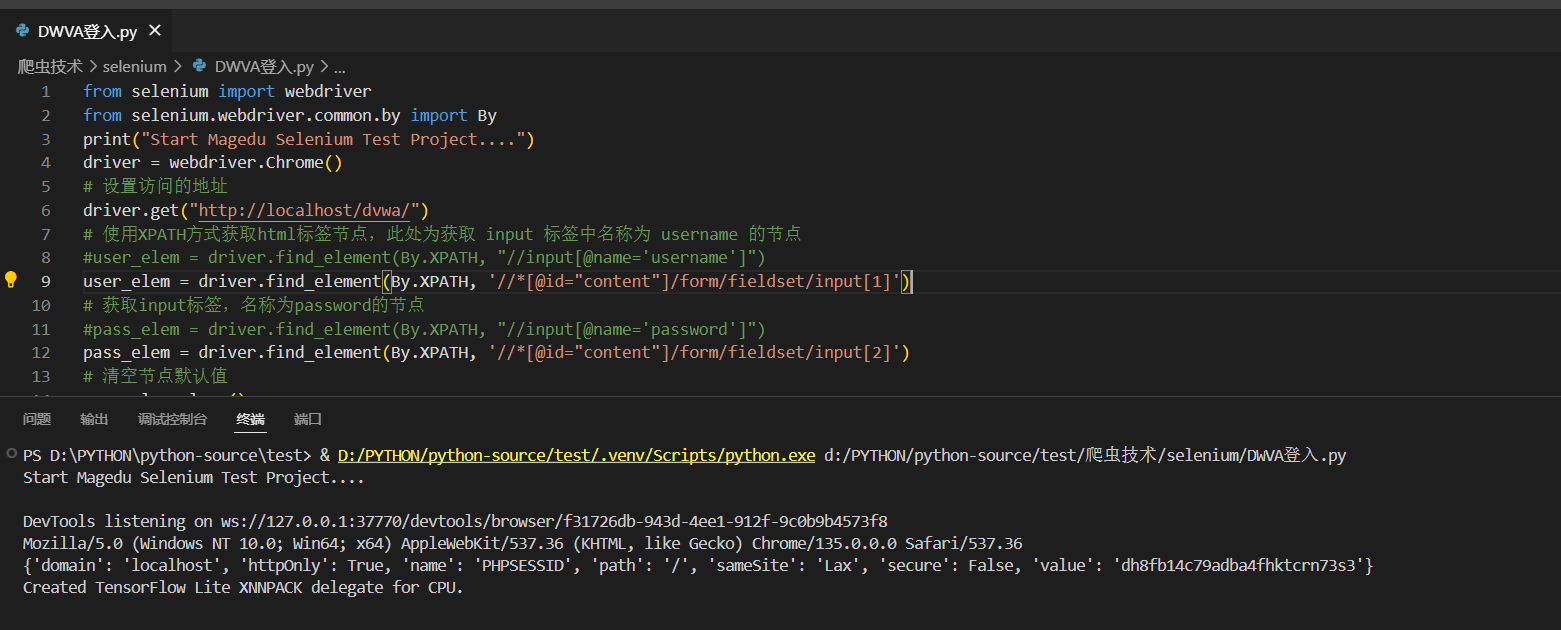
-
4、了解scrapy爬虫的使用以及rad爬虫基本用法
scrapy爬虫
概述:Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
-
使用
安装:
pip install Scrapy-
示例:
新建项目:在开始爬取之前,必须创建⼀个新的Scrapy项目。进入自定义的项目录中,运行下列命令:
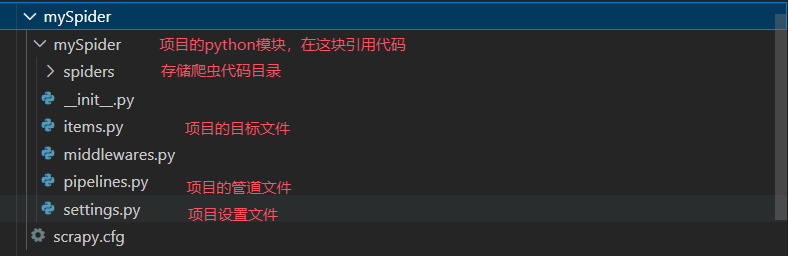
scrapy startproject mySpider其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,目录结构如下:
创建完成后便可以开始编写爬虫项目
-
rad爬虫
概述:rad,全名 Radium ,名字来源于放射性元素——镭, 从一个URL开始,辐射到一整个站点空间。
环境:下载rad、新版本的chrome
-
基本用法
rad -t http://example.com需要手动登录的情况
rad -t http://example.com -wait-login将爬取基本结果导出为文件
rad -t http://example.com -text-output result.txt以上命令会将爬取到的URL输出到result.txt中 格式为
Method URL例:GET http://example.com导出完整请求
rad -t http://example.com -full-text-output result.txt导出完整请求为JSON
rad -t http://example.com -json result.json与xray联动
-
社区版:设置上级代理为xray监听地址 运行xray:
xray webscan --listen 127.0.0.1:7777 --html-output proxy.html运行rad:
rad -t http://example.com -http-proxy 127.0.0.1:7777 -
高级版对 rad 进行了深度融合,下载后可以一键使用:
xray webscan --browser-crawler http://example.com --html-output vuln.html
-
5、复习httpx工具、指纹识别工具的具体用法,识别出magedu.com采用的建站模板
httpx 工具
概述:httpx 是一个高效的 HTTP 工具包,支持多线程探测(如 Web 服务器、URL 等测试),在保证结果可靠性的同时提升速度。
-
使用方法(安装 httpx)
httpx -h:查看所有参数用法-
基本探测
httpx -title -status-code -tech-detect -u www.baidu.com-title:显示网站标题-sc,-status-code:显示网站状态码-td,-tech-detect:显示基于 wappalyzer 的探测网站指纹-u:检测目标URL地址 -
端口探测
httpx -title -status-code -tech-detect -p 80,443,8080 -probe -u www.baidu.com-probe:显示探测状态 -
C段探测
httpx -u 192.168.153.1/24 -mc 200 -sc -title 1-mc,-match-code:匹配返回状态码
-
-
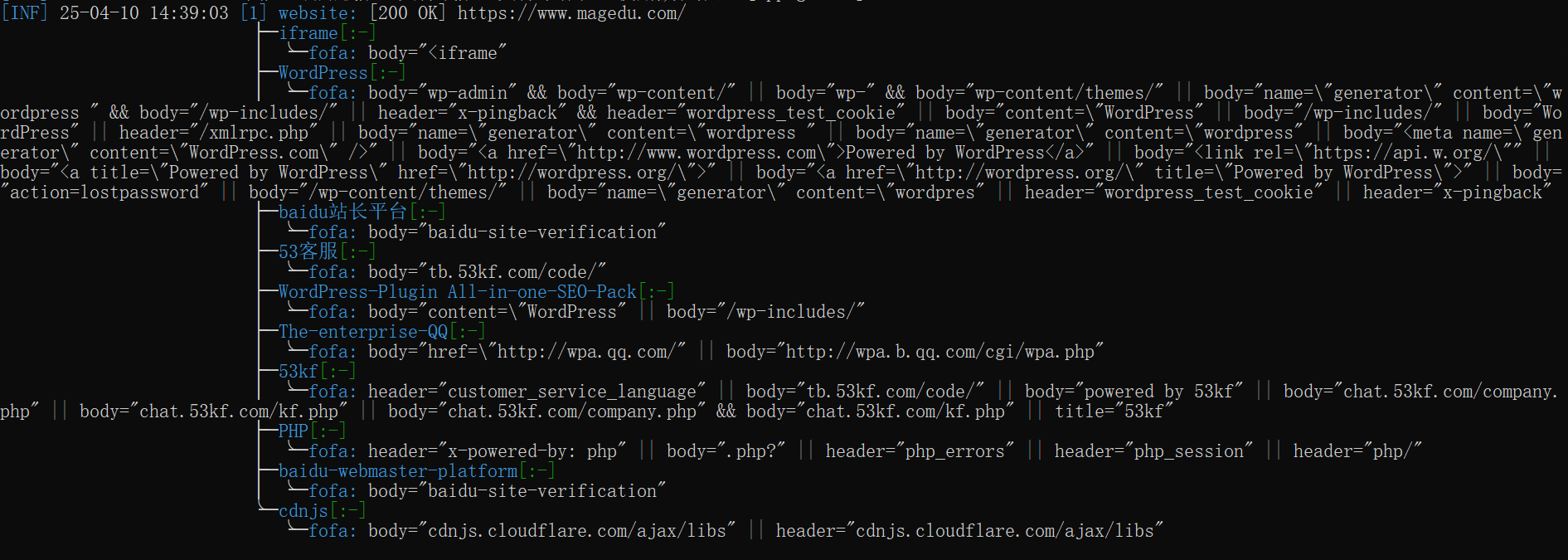
识别magedu.com采用的建站模板
httpx -td -u magedu.com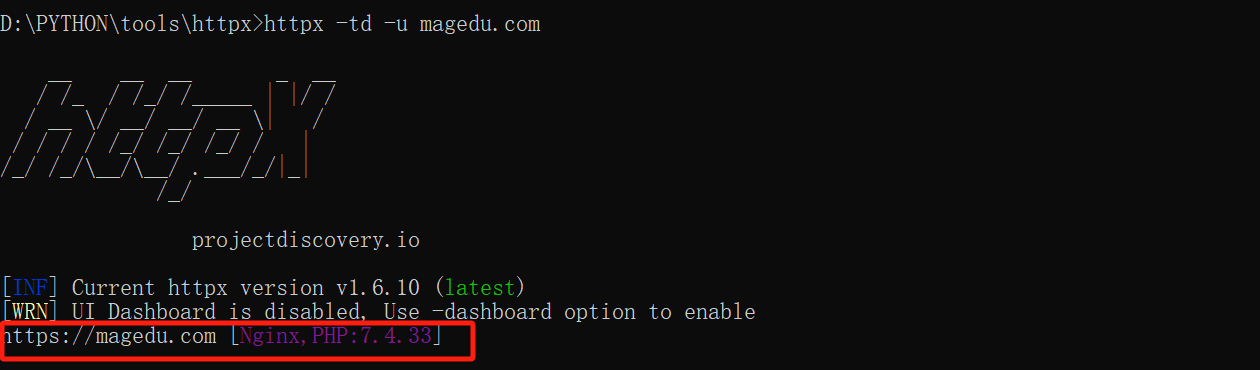
指纹识别工具
-
TideFinger
概述:TideFinger,一个开源的指纹识别小工具,使用了传统和现代检测技术相结合的指纹检测方法,让指纹检测更快捷、准确
-
使用方法(安装TideFinger)
-
安装第三方依赖
pip install -r requirements.txt -
使用
python TideFinger.py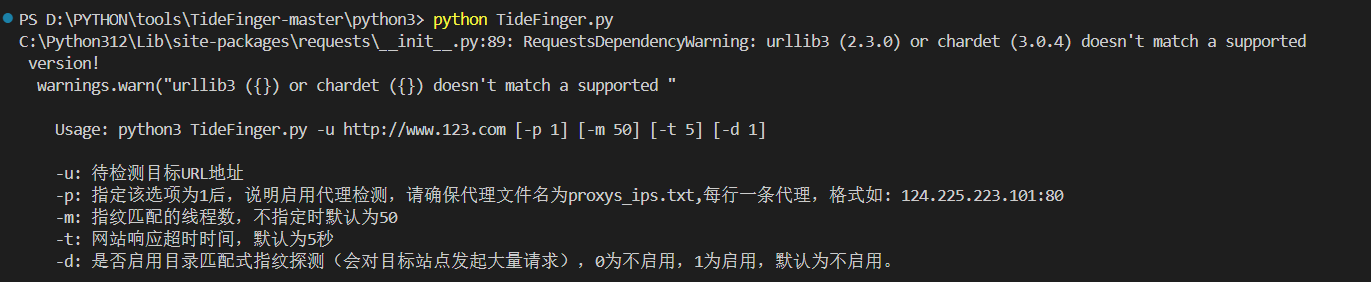
-
-
识别magedu.com采用的建站模板
python TideFinger.py -u https://www.magedu.com -d 1
-
-
xapp
6、复习使用python调用awvs的方法及代码实现
-
安装启动awvs
docker pull secfa/docker-awvs docker run -d -p 3443:3443 --cap-add LINUX_IMMUTABLE --name awvs secfa/docker-awvs -
下载调用awvs的python源码
-
对源码进行基础配置
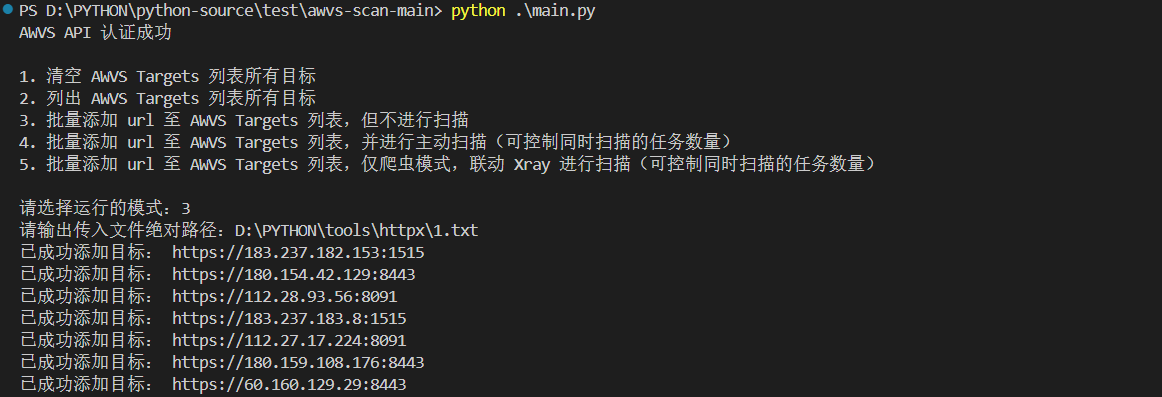
# api api_key = "xxxxxxxxxxxxxxx" #下面信息在Administrator > Profile 模块可以看见 # 填写 AWVS 主⻚ URL awvs_url = "https://10.0.0.151:13443/" # 填写 AWVS 登陆账户 email awvs_email = "admin@admin.com" -
运行脚本,测试选择模式3
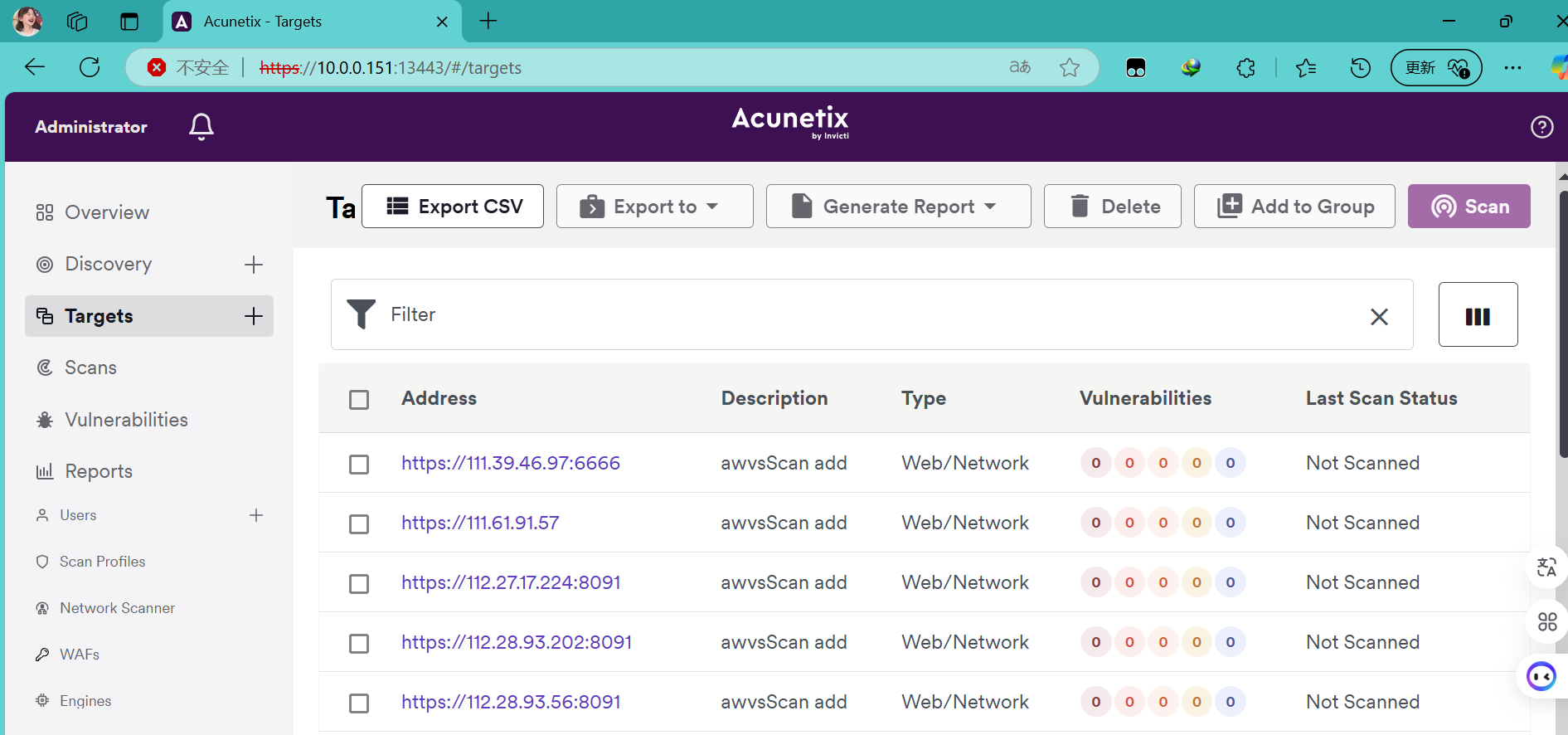
回到awvs,发现添加成功,代码实现成功

 浙公网安备 33010602011771号
浙公网安备 33010602011771号