Hadoop数据切片基本原理
数据切片问题:
先给不懂得同学解释一下概念:
数据块Block:是HDFS物理数据块,一个大文件丢到HDFS上,会被HDFS切分成指定大小的数据块,即Block
数据切片:数据切片是逻辑概念,只是程序在输入数据的时候对数据进行标记,不会实际切分磁盘数据
Mapper的数量是由切片数量,解释如下
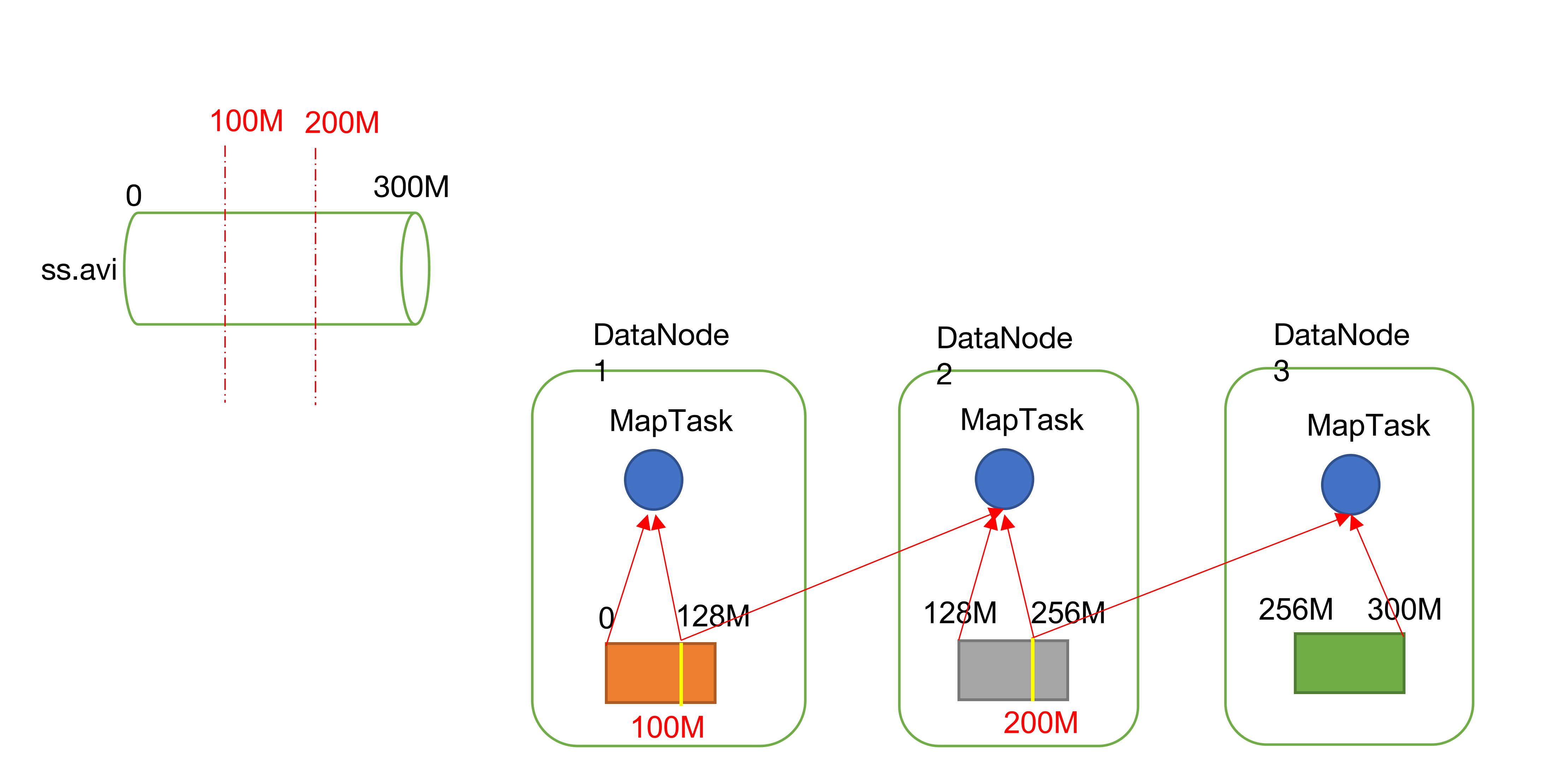
切片1: 假设文件大小为300M,切片大小为100M,BlockSize为128M,则第一个Block会被切成100M + 28M,100M给DataNode1上的MapTask,剩余的28M需要跨网络传输给DataNode2,同理,DataNode2的Block也需要切分,不过切分需要加上DataNode1剩余的28M,也就是DataNode2需要切分72M,加上28M才是DataNode2上MapTask所需的数据,以此类推,也就解释了下图的示意,这种情况最根本的问题就是大数据计算场景中,集群节点之间需要占用大量的网络IO和磁盘IO,计算效率会大大降低。
切片2: 假设文件依旧300M,但切片的大小SplitSize=BlockSize,则每一个Block就正好是一个MapTask所需数据,不需要切分Block,也就没有节点间的数据传输,效率就回很高,示例如下:
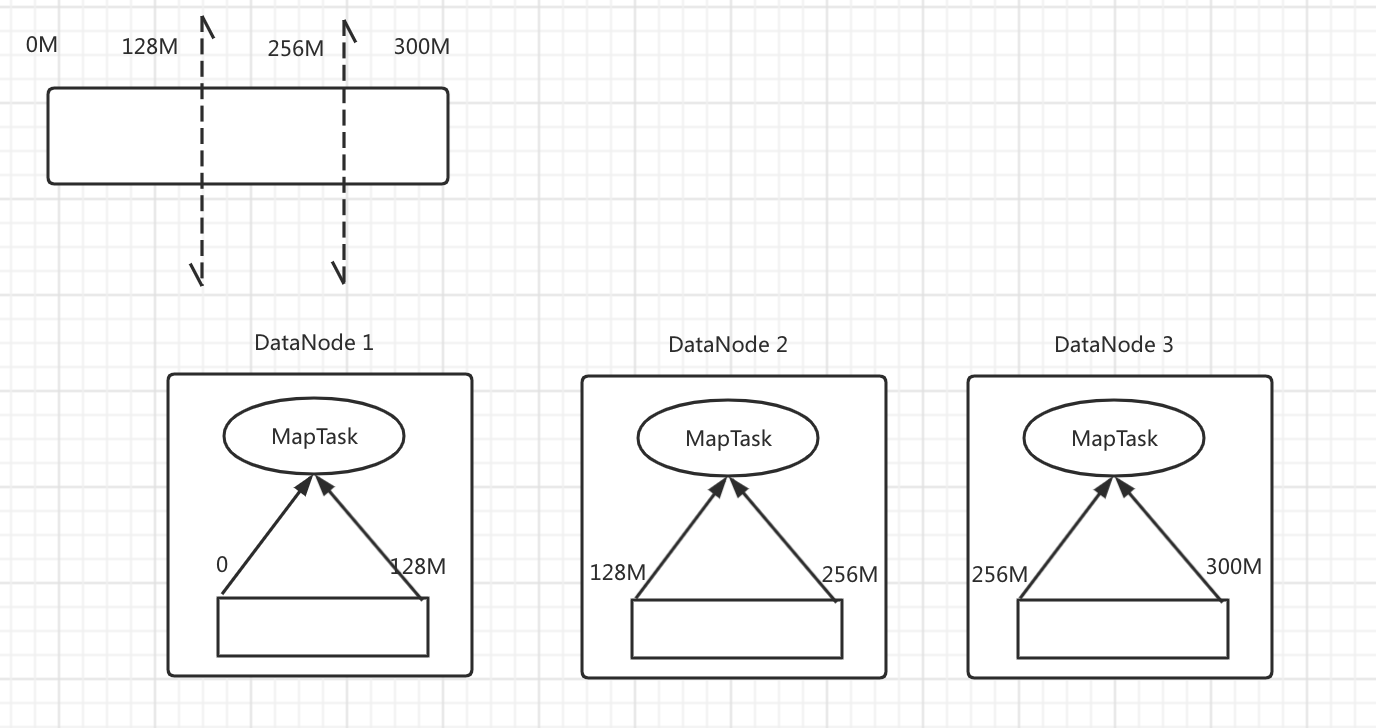
所以:
1. 一个Job的Map阶段并行度,也就是Mapper的数量是由提交Job时数据的切片数量决定
2. 每一个Split切片都会分配给一个MapTask并行实例处理
3. 默认情况下SplitSize=BlockSize
4. 切片时不考虑整体数据集,而是逐个针对每一个文件单独切片(比如Job的数据集是一个目录下的三个文件,这时切片不会把三个文件加在一起然后做切片,而是直接对每一个文件单独切片。还用300M那个文件举例,在SplitSize=BlockSize情况下, 如图所示为三个Mapper,若再加一个30M的文件,这个30M的文件不会在DataNode3的MapTask上运行,而是会在另一个DataNode4上的MapTask上执行)
以上也就是最基本的MapTask并行度的决定因素,这也就是Mapper数量不能手动指定数量,而是需要计算数据集的大小和切片,乃至DataNode的块大小,综合这些因素最后确定的,源码解释看下一篇

 浙公网安备 33010602011771号
浙公网安备 33010602011771号