Kafka进阶知识(一)
Kafka吞吐量大,延迟低,高可用,都是怎么实现的?废话不多说,往下看
关于kafka的基础概念相关的问题比如基本的架构原理,搭建等等我就不讲了,我讲一些比这些稍微底层一点的东西,有大牛发现不当之处请评论区指正
1. 高吞吐,低延迟的实现
应该先讲低延迟,如果延迟高的话吞吐量是上不去的。低延迟的实现简单概括为以下几点:
- 顺序写:这个顺序写的客观条件就是hadoop生态圈的核心就是廉价机器组成巨大规模的集群,所以基本都是机械硬盘,顺序写的速度能达到600M/s,随即写只有大概100KB/s,差距如此巨大的根本原因就是顺序写省去了磁盘磁头寻址的时间,随机写的大量时间都消耗在了寻址时间,所以慢
-
二分查找(绝对重点):
大多数操作系统使用页缓存(Page Cache)来实现内存映射,而目前几乎所有的操作系统都使用 LRU(Least Recently Used)或类似于 LRU 的机制来管理页缓存。Kafka 写入索引文件的方式是在文件末尾追加写入,而几乎所有的索引查询都集中在索引的尾部。所以LRU 机制是非常适合 Kafka 的索引访问场景的。不过有些小问题,当 Kafka 在查询索引的时候,原版的二分查找算法并没有考虑到缓存的问题,因此很可能会导致一些不必要的缺页中断(Page Fault)。此时,Kafka 线程会被阻塞,等待对应的索引项从物理磁盘中读出并放入到页缓存中。下面我举个例子来说明一下这个情况。假设 Kafka 的某个索引占用了操作系统页缓存 13 个页(Page),如果待查找的位移值位于最后一个页上,也就是 Page 12,那么标准的二分查找算法会依次读取页号 0、6、9、11 和 12,具体的推演流程如下所示:(此段落引用自极客时间Kafka相关文章,侵删)

通常来说,一个页上保存了成百上千的索引项数据。随着索引文件不断被写入,Page #12 不断地被填充新的索引项。如果此时索引查询方都来自 ISR 副本或 Lag 很小的消费者,那么这些查询大多集中在对 Page #12 的查询,因此,Page #0、6、9、11、12 一定经常性地被源码访问。也就是说,这些页一定保存在页缓存上。后面当新的索引项填满了 Page #12,页缓存就会申请一个新的 Page 来保存索引项,即 Page #13。现在,最新索引项保存在 Page #13 中。如果要查找最新索引项,原版二分查找算法将会依次访问 Page #0、7、10、12 和 13。此时,问题来了:Page 7 和 10 已经很久没有被访问过了,它们大概率不在页缓存中,因此,一旦索引开始征用 Page #13,就会发生 Page Fault,等待那些冷页数据从磁盘中加载到页缓存。根据国外用户的测试,这种加载过程可能长达 1 秒。
2,高可用
一个名为test的topic,在4节点的集群上面有3个分区,每个分区2副本,下面如图所示:
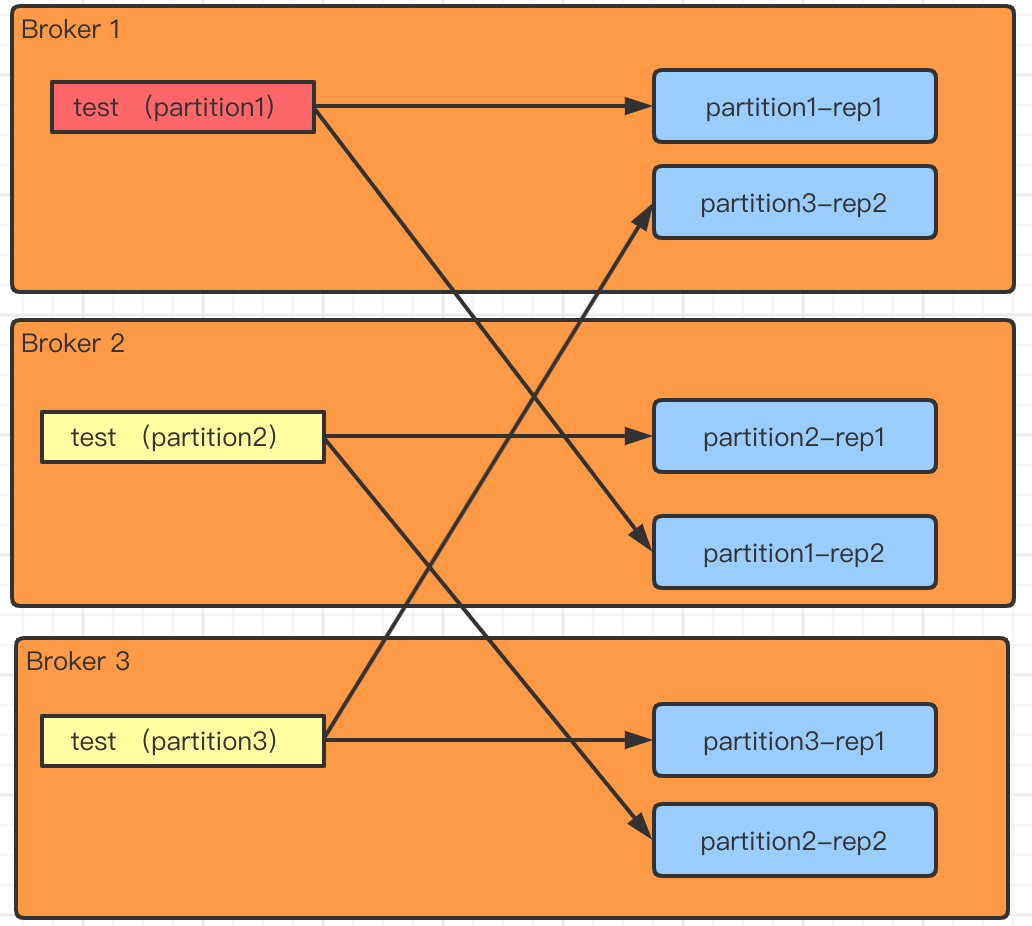
简而言之,分区是用来提高并发的,副本才是真正保证高可用的,副本之间需要同步,比如红色的为leader分区,leader后面有两个副本,一个broker1,一个broker2,当然生产环境一般是三副本这里就不写broker3了,leader负责读写,副本负责同步leader,这里就引入了osr和isr两个概念,就是“是(isr)否(osr)在与Leader同步状态ok的队列里面”,如果在isr里,那leader挂掉之后据从isr内选举新leader,如果某一个副本可能网络原因同步很慢,就会被踢出isr进入osr;反之,若osr内的副本同步跟上了leader,则加入到isr内,为后续leader意外挂掉的选举做备选,暂且写这么多,概念就不阐述太多了,百度google大把人写的比我详细

 浙公网安备 33010602011771号
浙公网安备 33010602011771号