
hadoop基础
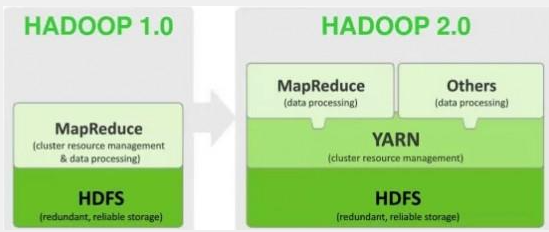
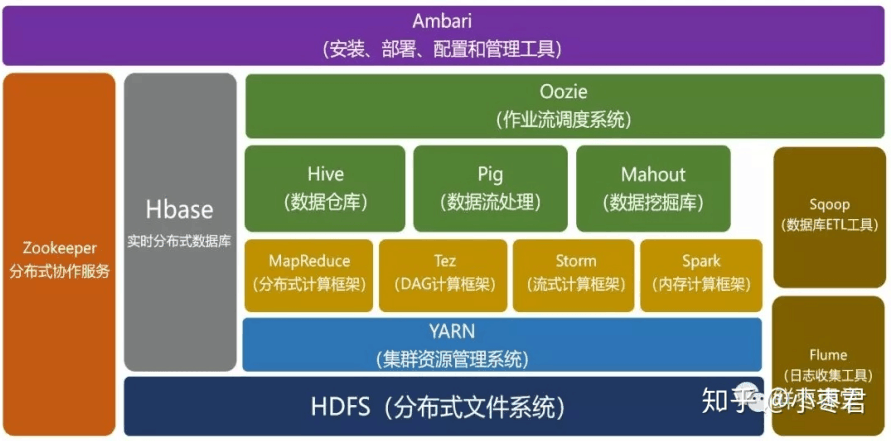
1.hadoop架构
2.HDFS操作
创建文件夹: hadoop fs -mkdir -p 文件的位置和名字
创建文件: hadloop fs -touchz 文件的位置和名字
上传lunix到hadoop中:hadoop fs -put lunix文件的位置和名字 hdfs文件的位置和名字
从hadoop下载到lunix: hadoop fs -get hdfs文件位置和名字 lunix文件位置和名字
修改文件权限:hadoop fs -chmod 777 hdfs文件位置和名字
删除hdfs文件和文件夹: hadoop fs -rm -r hdfs文件位置和名字
查看hadoop文件大小: hadoop fs -du -s hdfs文件位置和名字
3.block size
hdfs中,hadoop1.x默认使用64M的大小进行存储,hadoop2.x默认使用128M的大小进行存储。在文件存储时每个文件默认保存三份。
4.hadoop核心组件
namenode:名称节点,负责和客户端进行通讯
secondaryNameNode:辅助名称节点,收集计算机集群中,每台机器的状态,然后将收集到的数据传送给namenode
datanode:数据节点,存储数据的节点
5.hdfs读取数据

读取步骤解读:
①:客户端携带需要读取文件的路径向namenode发送请求
②:namenode返回有这个文件的datanode节点信息列表
③:客户端向datanode发送读取文件的申请
④:datanode返回ok表示可以读取文件
⑤:客户端开始读取文件,datanode将读取的内容返回
6.写入数据
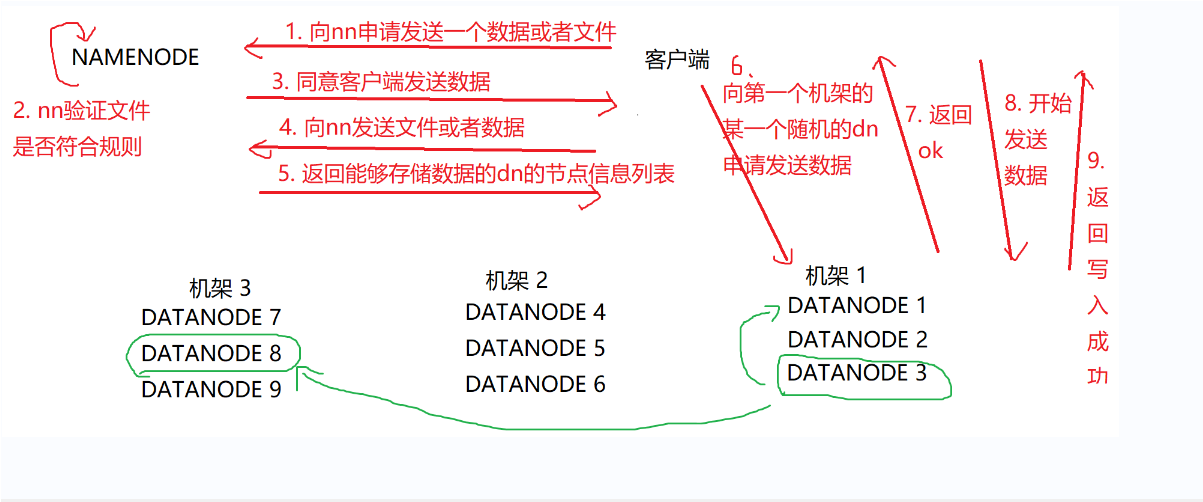
写入数据解读:
①:客户端发送文件到namenode的申请
②:namenode验证文件是否符合规则,同意客户端的数据发送,返回可以存取数据的datanode节点列表信息
③:客户端向随机的datanode发送数据的申请
④:datanode返回ok确认可以写入数据,客户端开始发送数据
7.yarn的核心组件
resourceManager:scheduler(定时调用器)applicationManager(应用管理器)nodeManager applicationMaster
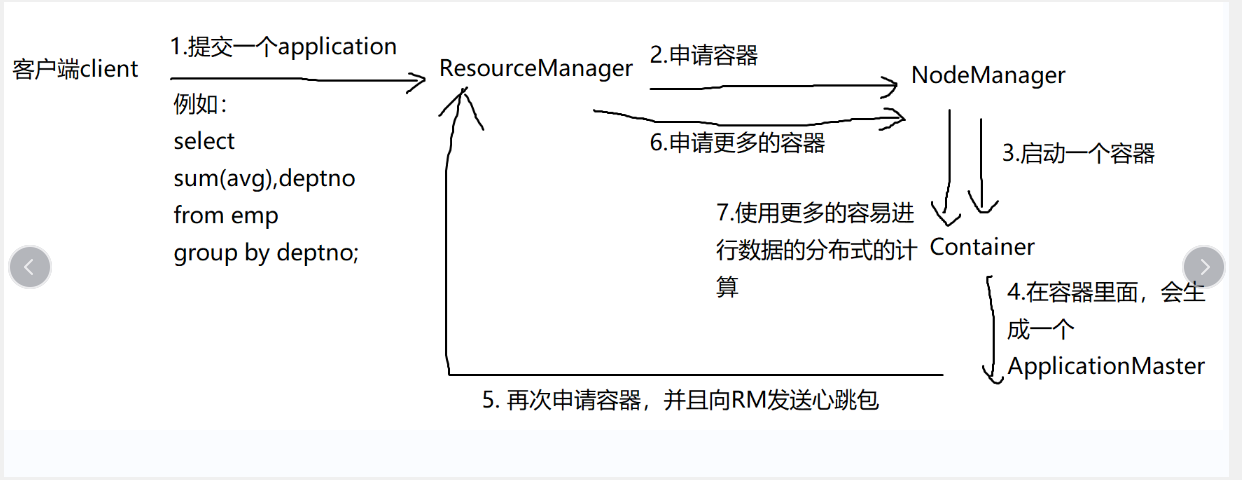
yarn原理解读
①客户端发送一个计算请求到resourceManager
②resourceManager根据所需资源消耗去nodeManager申请容器
③由container启动一个容器,并且在容器中生成一个applicationmaster
④applicationmaster会向resourceManager发送心跳包,用来监视当前app的运行情况
8.mapreduce工作流程
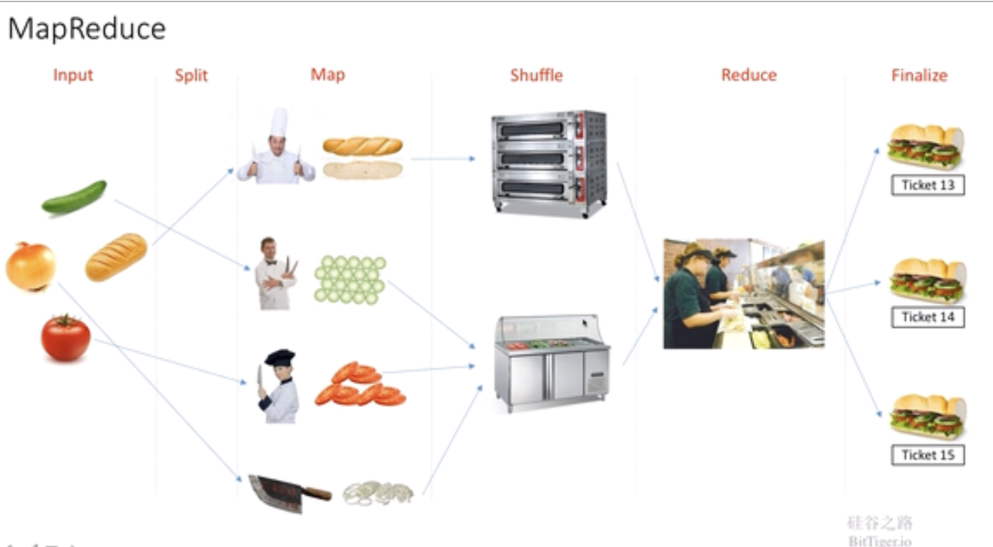
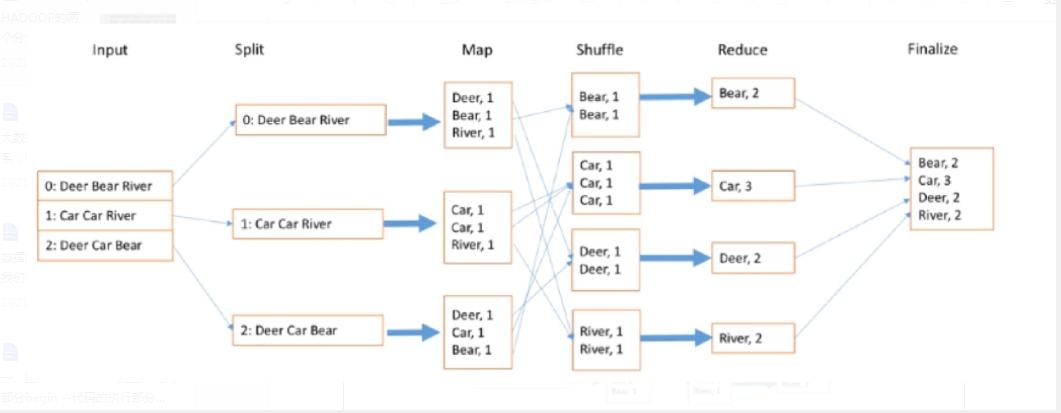
input:读取数据
split:分配数据给map
map:对数据进行拆分
shuffle:对数据本身进行计算
reduce:对计算结果进行合并
finalize:对数据进行统一展示
shuffle过程:
1.将数据读取到缓存
2.从缓存中读取数据,对数据进行分区排序
3.将数据进行基本的聚合写入磁盘
4.从硬盘中抓取数据
5.对数据进行排序和聚合

 浙公网安备 33010602011771号
浙公网安备 33010602011771号