

机器学习算法GBDT
http://www-personal.umich.edu/~jizhu/jizhu/wuke/Friedman-AoS01.pdf
https://www.cnblogs.com/bentuwuying/p/6667267.html
https://www.cnblogs.com/ModifyRong/p/7744987.html
https://www.cnblogs.com/bentuwuying/p/6264004.html
1.简介
gbdt全称梯度下降树,在传统机器学习算法里面是对真实分布拟合的最好的几种算法之一,在前几年深度学习还没有大行其道之前,gbdt在各种竞赛是大放异彩。原因大概有几个,一是效果确实挺不错。二是即可以用于分类也可以用于回归。三是可以筛选特征。这三点实在是太吸引人了,导致在面试的时候大家也非常喜欢问这个算法。 gbdt的面试考核点,大致有下面几个:
- gbdt 的算法的流程?
- gbdt 如何选择特征 ?
- gbdt 如何构建特征 ?
- gbdt 如何用于分类?
- gbdt 通过什么方式减少误差 ?
- gbdt的效果相比于传统的LR,SVM效果为什么好一些 ?
- gbdt 如何加速训练?
- gbdt的参数有哪些,如何调参 ?
- gbdt 实战当中遇到的一些问题 ?
- gbdt的优缺点 ?
2. 正式介绍
首先gbdt 是通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的残差来达到将数据分类或者回归的算法。
- gbdt的训练过程
我们通过一张图片,图片来源来说明gbdt的训练过程:

图 1:GBDT 的训练过程
gbdt通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的。因为训练的过程是通过降低偏差来不断提高最终分类器的精度,(此处是可以证明的)。
弱分类器一般会选择为CART TREE(也就是分类回归树)。由于上述高偏差和简单的要求 每个分类回归树的深度不会很深。最终的总分类器 是将每轮训练得到的弱分类器加权求和得到的(也就是加法模型)。
模型最终可以描述为:
模型一共训练M轮,每轮产生一个弱分类器 T(x;θm)T(x;θm)。弱分类器的损失函数
Fm−1(x)Fm−1(x) 为当前的模型,gbdt 通过经验风险极小化来确定下一个弱分类器的参数。具体到损失函数本身的选择也就是L的选择,有平方损失函数,0-1损失函数,对数损失函数等等。如果我们选择平方损失函数,那么这个差值其实就是我们平常所说的残差。
-
- 但是其实我们真正关注的,1.是希望损失函数能够不断的减小,2.是希望损失函数能够尽可能快的减小。所以如何尽可能快的减小呢?
-
- 让损失函数沿着梯度方向的下降。这个就是gbdt 的 gb的核心了。 利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值去拟合一个回归树。gbdt 每轮迭代的时候,都去拟合损失函数在当前模型下的负梯度。
-
- 这样每轮训练的时候都能够让损失函数尽可能快的减小,尽快的收敛达到局部最优解或者全局最优解。
- gbdt如何选择特征?
gbdt选择特征的细节其实是想问你CART Tree生成的过程。这里有一个前提,gbdt的弱分类器默认选择的是CART TREE。其实也可以选择其他弱分类器的,选择的前提是低方差和高偏差。框架服从boosting 框架即可。
下面我们具体来说CART TREE(是一种二叉树) 如何生成。CART TREE 生成的过程其实就是一个选择特征的过程。假设我们目前总共有 M 个特征。第一步我们需要从中选择出一个特征 j,做为二叉树的第一个节点。然后对特征 j 的值选择一个切分点 m. 一个 样本的特征j的值 如果小于m,则分为一类,如果大于m,则分为另外一类。如此便构建了CART 树的一个节点。其他节点的生成过程和这个是一样的。现在的问题是在每轮迭代的时候,如何选择这个特征 j,以及如何选择特征 j 的切分点 m:
-
- 原始的gbdt的做法非常的暴力,首先遍历每个特征,然后对每个特征遍历它所有可能的切分点,找到最优特征 m 的最优切分点 j。
-
- 如何衡量我们找到的特征 m和切分点 j 是最优的呢? 我们用定义一个函数 FindLossAndSplit 来展示一下求解过程:

1 def findLossAndSplit(x,y):
2 # 我们用 x 来表示训练数据
3 # 我们用 y 来表示训练数据的label
4 # x[i]表示训练数据的第i个特征
5 # x_i 表示第i个训练样本
6
7 # minLoss 表示最小的损失
8 minLoss = Integet.max_value
9 # feature 表示是训练的数据第几纬度的特征
10 feature = 0
11 # split 表示切分点的个数
12 split = 0
13
14 # M 表示 样本x的特征个数
15 for j in range(0,M):
16 # 该维特征下,特征值的每个切分点,这里具体的切分方式可以自己定义
17 for c in range(0,x[j]):
18 L = 0
19 # 第一类
20 R1 = {x|x[j] <= c}
21 # 第二类
22 R2 = {x|x[j] > c}
23 # 属于第一类样本的y值的平均值
24 y1 = ave{y|x 属于 R1}
25 # 属于第二类样本的y值的平均值
26 y2 = ave{y| x 属于 R2}
27 # 遍历所有的样本,找到 loss funtion 的值
28 for x_1 in all x
29 if x_1 属于 R1:
30 L += (y_1 - y1)^2
31 else:
32 L += (y_1 - y2)^2
33 if L < minLoss:
34 minLoss = L
35 feature = i
36 split = c
37 return minLoss,feature ,split
-
- 如果对这段代码不是很了解的,可以先去看看李航第五章中对CART TREE 算法的叙述。在这里,我们先遍历训练样本的所有的特征,对于特征 j,我们遍历特征 j 所有特征值的切分点 c。找到可以让下面这个式子最小的特征 j 以及切分点c.
-
- gbdt 如何构建特征 ?

其实说gbdt 能够构建特征并非很准确,gbdt 本身是不能产生特征的,但是我们可以利用gbdt去产生特征的组合。在CTR预估中,工业界一般会采用逻辑回归去进行处理,在我的上一篇博文当中已经说过,逻辑回归本身是适合处理线性可分的数据,如果我们想让逻辑回归处理非线性的数据,其中一种方式便是组合不同特征,增强逻辑回归对非线性分布的拟合能力。
长久以来,我们都是通过人工的先验知识或者实验来获得有效的组合特征,但是很多时候,使用人工经验知识来组合特征过于耗费人力,造成了机器学习当中一个很奇特的现象:有多少人工就有多少智能。关键是这样通过人工去组合特征并不一定能够提升模型的效果。所以我们的从业者或者学界一直都有一个趋势便是通过算法自动,高效的寻找到有效的特征组合。Facebook 在2014年 发表的一篇论文便是这种尝试下的产物,利用gbdt去产生有效的特征组合,以便用于逻辑回归的训练,提升模型最终的效果。

图 2:用GBDT 构造特征
如图 2所示,我们 使用 GBDT 生成了两棵树,两颗树一共有五个叶子节点。我们将样本 X 输入到两颗树当中去,样本X 落在了第一棵树的第二个叶子节点,第二颗树的第一个叶子节点,于是我们便可以依次构建一个五纬的特征向量,每一个纬度代表了一个叶子节点,样本落在这个叶子节点上面的话那么值为1,没有落在该叶子节点的话,那么值为 0.
于是对于该样本,我们可以得到一个向量[0,1,0,1,0] 作为该样本的组合特征,和原来的特征一起输入到逻辑回归当中进行训练。实验证明这样会得到比较显著的效果提升。
- GBDT 如何用于分类 ?
首先明确一点,gbdt 无论用于分类还是回归一直都是使用的CART 回归树。不会因为我们所选择的任务是分类任务就选用分类树,这里面的核心是因为gbdt 每轮的训练是在上一轮的训练的残差基础之上进行训练的。这里的残差就是当前模型的负梯度值 。这个要求每轮迭代的时候,弱分类器的输出的结果相减是有意义的。残差相减是有意义的。
如果选用的弱分类器是分类树,类别相减是没有意义的。上一轮输出的是样本 x 属于 A类,本一轮训练输出的是样本 x 属于 B类。 A 和 B 很多时候甚至都没有比较的意义,A 类- B类是没有意义的。
我们具体到分类这个任务上面来,我们假设样本 X 总共有 K类。来了一个样本 x,我们需要使用gbdt来判断 x 属于样本的哪一类。
-

图三 gbdt 多分类算法流程
第一步 我们在训练的时候,是针对样本 X 每个可能的类都训练一个分类回归树。举例说明,目前样本有三类,也就是 K = 3。样本 x 属于 第二类。那么针对该样本 x 的分类结果,其实我们可以用一个 三维向量 [0,1,0] 来表示。0表示样本不属于该类,1表示样本属于该类。由于样本已经属于第二类了,所以第二类对应的向量维度为1,其他位置为0。
针对样本有 三类的情况,我们实质上是在每轮的训练的时候是同时训练三颗树。第一颗树针对样本x的第一类,输入为(x,0)(x,0)。第二颗树输入针对 样本x 的第二类,输入为(x,1)(x,1)。第三颗树针对样本x 的第三类,输入为(x,0)(x,0)
在这里每颗树的训练过程其实就是就是我们之前已经提到过的CATR TREE 的生成过程。在此处我们参照之前的生成树的程序 即可以就解出三颗树,以及三颗树对x 类别的预测值f1(x),f2(x),f3(x)f1(x),f2(x),f3(x)。那么在此类训练中,我们仿照多分类的逻辑回归 ,使用softmax 来产生概率,则属于类别 1 的概率
并且我们我们可以针对类别1 求出 残差y11(x)=0−p1(x)y11(x)=0−p1(x);类别2 求出残差y22(x)=1−p2(x)y22(x)=1−p2(x);类别3 求出残差y33(x)=0−p3(x)y33(x)=0−p3(x).
然后开始第二轮训练 针对第一类 输入为(x,y11(x)y11(x)), 针对第二类输入为(x,y22(x))y22(x)), 针对 第三类输入为 (x,y33(x)y33(x)).继续训练出三颗树。一直迭代M轮。每轮构建 3颗树。
所以当K =3。我们其实应该有三个式子
当训练完毕以后,新来一个样本 x1 ,我们需要预测该样本的类别的时候,便可以有这三个式子产生三个值,f1(x),f2(x),f3(x)f1(x),f2(x),f3(x)。样本属于 某个类别c的概率为
- GBDT 多分类举例说明
上面的理论阐述可能仍旧过于难懂,我们下面将拿Iris 数据集中的六个数据作为例子,来展示gbdt 多分类的过程。
-
图四 Iris 数据集样本编号 花萼长度(cm) 花萼宽度(cm) 花瓣长度(cm) 花瓣宽度 花的种类 1 5.1 3.5 1.4 0.2 山鸢尾 2 4.9 3.0 1.4 0.2 山鸢尾 3 7.0 3.2 4.7 1.4 杂色鸢尾 4 6.4 3.2 4.5 1.5 杂色鸢尾 5 6.3 3.3 6.0 2.5 维吉尼亚鸢尾 6 5.8 2.7 5.1 1.9 维吉尼亚鸢尾
这是一个有6个样本的三分类问题。我们需要根据这个花的花萼长度,花萼宽度,花瓣长度,花瓣宽度来判断这个花属于山鸢尾,杂色鸢尾,还是维吉尼亚鸢尾。具体应用到gbdt多分类算法上面。我们用一个三维向量来标志样本的label。[1,0,0] 表示样本属于山鸢尾,[0,1,0] 表示样本属于杂色鸢尾,[0,0,1] 表示属于维吉尼亚鸢尾。
gbdt 的多分类是针对每个类都独立训练一个 CART Tree。所以这里,我们将针对山鸢尾类别训练一个 CART Tree 1。杂色鸢尾训练一个 CART Tree 2 。维吉尼亚鸢尾训练一个CART Tree 3,这三个树相互独立。
我们以样本 1 为例。针对 CART Tree1 的训练样本是[5.1,3.5,1.4,0.2][5.1,3.5,1.4,0.2],label 是 1,最终输入到模型当中的为[5.1,3.5,1.4,0.2,1][5.1,3.5,1.4,0.2,1]。针对 CART Tree2 的训练样本也是[5.1,3.5,1.4,0.2][5.1,3.5,1.4,0.2],但是label 为 0,最终输入模型的为[5.1,3.5,1.4,0.2,0][5.1,3.5,1.4,0.2,0]. 针对 CART Tree 3的训练样本也是[5.1,3.5,1.4,0.2][5.1,3.5,1.4,0.2],label 也为0,最终输入模型当中的为[5.1,3.5,1.4,0.2,0][5.1,3.5,1.4,0.2,0].
下面我们来看 CART Tree1 是如何生成的,其他树 CART Tree2 , CART Tree 3的生成方式是一样的。CART Tree的生成过程是从这四个特征中找一个特征做为CART Tree1 的节点。比如花萼长度做为节点。6个样本当中花萼长度 大于5.1 cm的就是 A类,小于等于 5.1 cm 的是B类。生成的过程其实非常简单,问题 1.是哪个特征最合适? 2.是这个特征的什么特征值作为切分点? 即使我们已经确定了花萼长度做为节点。花萼长度本身也有很多值。在这里我们的方式是遍历所有的可能性,找到一个最好的特征和它对应的最优特征值可以让当前式子的值最小。
我们以第一个特征的第一个特征值为例。R1 为所有样本中花萼长度小于 5.1 cm 的样本集合,R2 为所有样本当中花萼长度大于等于 5.1cm 的样本集合。所以 R1={2}R1={2},R2={1,3,4,5,6}R2={1,3,4,5,6}.

图 5 节点分裂示意图
y1 为 R1 所有样本的label 的均值 1/1=11/1=1。y2 为 R2 所有样本的label 的均值 (1+0+0+0+0)/5=0.2(1+0+0+0+0)/5=0.2。
下面便开始针对所有的样本计算这个式子的值。样本1 属于 R2 计算的值为(1−0.2)2(1−0.2)2, 样本2 属于R1 计算的值为(1−1)2(1−1)2, 样本 3,4,5,6同理都是 属于 R2的 所以值是(0−0.2)2(0−0.2)2. 把这六个值加起来,便是 山鸢尾类型在特征1 的第一个特征值的损失值。这里算出来(1-0.2)^2+ (1-1)^2 + (0-0.2)^2+(0-0.2)^2+(0-0.2)^2 +(0-0.2)^2= 0.84
接着我们计算第一个特征的第二个特征值,计算方式同上,R1 为所有样本中 花萼长度小于 4.9 cm 的样本集合,R2 为所有样本当中 花萼长度大于等于 4.9 cm 的样本集合.所以 R1={}R1={},R1={1,2,3,4,5,6}R1={1,2,3,4,5,6}. y1 为 R1 所有样本的label 的均值 = 0。y2 为 R2 所有样本的label 的均值 (1+1+0+0+0+0)/6=0.3333(1+1+0+0+0+0)/6=0.3333。

图 6 第一个特征的第二个特侦值的节点分裂情况
我们需要针对所有的样本,样本1 属于 R2, 计算的值为(1−0.333)2(1−0.333)2, 样本2 属于R2 ,计算的值为(1−0.333)2(1−0.333)2, 样本 3,4,5,6同理都是 属于 R2的, 所以值是(0−0.333)2(0−0.333)2. 把这六个值加起来山鸢尾类型在特征1 的第二个特征值的损失值。这里算出来 (1-0.333)^2+ (1-0.333)^2 + (0-0.333)^2+(0-0.333)^2+(0-0.333)^2 +(0-0.333)^2 = 2.244189. 这里的损失值大于 特征一的第一个特征值的损失值,所以我们不取这个特征的特征值。

图 7 所有情况说明
这样我们可以遍历所有特征的所有特征值,找到让这个式子最小的特征以及其对应的特征值,一共有24种情况,4个特征*每个特征有6个特征值。在这里我们算出来让这个式子最小的特征花萼长度,特征值为5.1 cm。这个时候损失函数最小为 0.8。
于是我们的预测函数此时也可以得到:
此处 R1 = {2},R2 = {1,3,4,5,6},y1 = 1,y2 = 0.2。训练完以后的最终式子为
借由这个式子,我们得到对样本属于类别1 的预测值 f1(x)=1+0.2∗5=2f1(x)=1+0.2∗5=2。同理我们可以得到对样本属于类别2,3的预测值f2(x)f2(x),f3(x)f3(x).样本属于类别1的概率 即为
下面我们用代码来实现整个找特征的过程,大家可以自己再对照代码看看。
1 # 定义训练数据 2 train_data = [[5.1,3.5,1.4,0.2],[4.9,3.0,1.4,0.2],[7.0,3.2,4.7,1.4],[6.4,3.2,4.5,1.5],[6.3,3.3,6.0,2.5],[5.8,2.7,5.1,1.9]] 3 4 # 定义label 5 label_data = [[1,0,0],[1,0,0],[0,1,0],[0,1,0],[0,0,1],[0,0,1]] 6 # index 表示的第几类 7 def findBestLossAndSplit(train_data,label_data,index): 8 sample_numbers = len(label_data) 9 feature_numbers = len(train_data[0]) 10 current_label = [] 11 12 # define the minLoss 13 minLoss = 10000000 14 15 # feature represents the dimensions of the feature 16 feature = 0 17 18 # split represents the detail split value 19 split = 0 20 21 # get current label 22 for label_index in range(0,len(label_data)): 23 current_label.append(label_data[label_index][index]) 24 25 # trans all features 26 for feature_index in range(0,feature_numbers): 27 ## current feature value 28 current_value = [] 29 30 for sample_index in range(0,sample_numbers): 31 current_value.append(train_data[sample_index][feature_index]) 32 L = 0 33 ## different split value 34 print current_value 35 for index in range(0,len(current_value)): 36 R1 = [] 37 R2 = [] 38 y1 = 0 39 y2 = 0 40 41 for index_1 in range(0,len(current_value)): 42 if current_value[index_1] < current_value[index]: 43 R1.append(index_1) 44 else: 45 R2.append(index_1) 46 47 ## calculate the samples for first class 48 sum_y = 0 49 for index_R1 in R1: 50 sum_y += current_label[index_R1] 51 if len(R1) != 0: 52 y1 = float(sum_y) / float(len(R1)) 53 else: 54 y1 = 0 55 56 ## calculate the samples for second class 57 sum_y = 0 58 for index_R2 in R2: 59 sum_y += current_label[index_R2] 60 if len(R2) != 0: 61 y2 = float(sum_y) / float(len(R2)) 62 else: 63 y2 = 0 64 65 ## trans all samples to find minium loss and best split 66 for index_2 in range(0,len(current_value)): 67 if index_2 in R1: 68 L += float((current_label[index_2]-y1))*float((current_label[index_2]-y1)) 69 else: 70 L += float((current_label[index_2]-y2))*float((current_label[index_2]-y2)) 71 72 if L < minLoss: 73 feature = feature_index 74 split = current_value[index] 75 minLoss = L 76 print "minLoss" 77 print minLoss 78 print "split" 79 print split 80 print "feature" 81 print feature 82 return minLoss,split,feature 83 84 findBestLossAndSplit(train_data,label_data,0)
- 3 总结
目前,我们总结了 gbdt 的算法的流程,gbdt如何选择特征,如何产生特征的组合,以及gbdt 如何用于分类,这个目前可以认为是gbdt 最经常问到的四个部分。至于剩余的问题,因为篇幅的问题,我们准备再开一个篇幅来进行总结。.
Practical Lessons from Predicting Clicks on Ads at Facebook
ABSTRACT
这篇paper中作者结合GBDT和LR,取得了很好的效果,比单个模型的效果高出3%。随后作者研究了对整体预测系统产生影响的几个因素,发现Feature(能挖掘出用户和广告的历史信息)+Model(GBDT+LR)的贡献程度最大,而其他因素(数据实时性,模型学习速率,数据采样)的影响则较小。
1. INTRODUCTION
介绍了先前的一些相关paper。包括Google,Yahoo,MS的关于CTR Model方面的paper。
而在Facebook,广告系统是由级联型的分类器(a cascade of classifiers)组成,而本篇paper讨论的CTR Model则是这个cascade classifiers的最后一环节。
2. EXPERIMENTAL SETUP
作者介绍了如何构建training data和testing data,以及Evaluation Metrics。包括Normalized Entropy和Calibration。
Normalized Entropy的定义为每次展现时预测得到的log loss的平均值,除以对整个数据集的平均log loss值。之所以需要除以整个数据集的平均log loss值,是因为backgroud CTR越接近于0或1,则越容易预测取得较好的log loss值,而做了normalization后,NE便会对backgroud CTR不敏感了。这个Normalized Entropy值越低,则说明预测的效果越好。下面列出表达式:
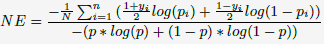
Calibration的定义为预估CTR除以真实CTR,即预测的点击数除以真实观察到的点击数。这个值越接近1,则表明预测效果越好。
3. PREDICTION MODEL STRUCTURE
作者介绍了两种Online Learning的方法。包括Stochastic Gradient Descent(SGD)-based LR:

和Bayesian online learning scheme for probit regression(BOPR):
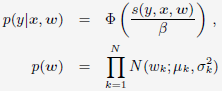
BOPR每轮迭代时的更新公式为:
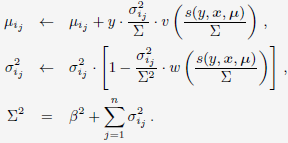
3.1 Decision tree feature transforms
Linear Model的表达能力不够,需要feature transformation。第一种方法是对连续feature进行分段处理(怎样分段,以及分段的分界点是很重要的);第二种方法是进行特征组合,包括对离散feature做笛卡尔积,或者对连续feature使用联合分段(joint binning),比如使用k-d tree。
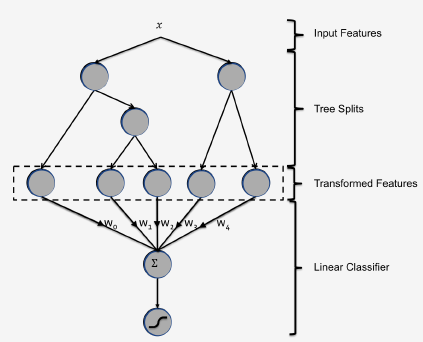
而使用GBDT能作为一种很好的feature transformation的工具,我们可以把GBDT中的每棵树作为一种类别的feature,把一个instance经过GBDT的流程(即从根节点一直往下分叉到一个特定的叶子节点)作为一个instance的特征组合的过程。这里GBDT采用的是Gradient Boosting Machine + L2-TreeBoost算法。这里是本篇paper的重点部分,放一张经典的原图:
3.2 Data freshness
CTR预估系统是在一个动态的环境中,数据的分布随时在变化,所以本文探讨了data freshness对预测效果的影响,表明training data的日期越靠近,效果越好。
3.3 Online linear classifier
探讨了对SGD-based LR中learning rate的选择。最好的选择为:
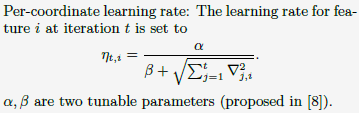
1)global效果差的原因:每个维度上训练样本的不平衡,每个训练样本拥有不同的feature。那些拥有样本数较少的维度的learning rate下降过快,导致无法收敛到最优值。
2)per weight差的原因:虽然对于各个维度有所区分,但是其对于各个维度的learning rate下降速度都太快了,训练过早结束,无法收敛到最优值。
SGD-based LR vs BOPR
1)SGD-based LR对比BOPR的优势:
1-1)模型参数少,内存占用少。SGD-based LR每个维度只有一个weight值,而BOPR每个维度有1个均值 + 1个方差值。
1-2)计算速度快。SGD-LR只需1次内积计算,BOPR需要2次内积计算。
2)BOPR对比SGD-based LR的优势:
2-1)BOPR可以得到完整的预测点击概率分布。
4 ONLINE DATA JOINER
Online Data Joiner主要是用于在线的将label与相应的features进行join。同时作者也介绍了正负样本的选取方式,以及选取负样本时候的waiting time window的选择。
5 CONTAINING MEMORY AND LATENCY
作者探讨了GBDT中tree的个数,各种类型的features(包括contextual features和historical features),对预测效果的影响。结论如下:
1)NE的下降基本来自于前500棵树。
2)最后1000棵树对NE的降低贡献低于0.1%。
3)Submodel 2 过拟合,数据量较少,只有其余2个模型的约四分之一。
4)Importance为feature带来的累积信息增益 / 平方差的减少
5)Top 10 features贡献了将近一半的importance
6)最后的300个features的贡献不足1%
6 COPYING WITH MASSIVE TRANING DATA
作者探讨了如何进行样本采样的过程,包括了均匀采样(Uniform subsampling),和负样本降采样(Negative down sampling),以及对预测效果的影响。
一. GBDT的经典paper:《Greedy Function Approximation:A Gradient Boosting Machine》
Abstract
Function approximation是从function space方面进行numerical optimization,其将stagewise additive expansions和steepest-descent minimization结合起来。而由此而来的Gradient Boosting Decision Tree(GBDT)可以适用于regression和classification,都具有完整的,鲁棒性高,解释性好的优点。
1. Function estimation
在机器学习的任务中,我们一般面对的问题是构造loss function,并求解其最小值。可以写成如下形式:

通常的loss function有:
1. regression:均方误差(y-F)2,绝对误差|y-F|
2. classification:negative binomial log-likelihood log(1+e-2yF)
一般情况下,我们会把F(x)看做是一系列带参数的函数集合 F(x;P),于是进一步将其表示为“additive”的形式:

1.1 Numerical optimizatin
我们可以通过选取一个参数模型F(x;P),来将function optimization问题转化为一个parameter optimization问题:

进一步,我们可以把要优化的参数也表示为“additive”的形式:
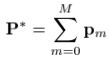
1.2 Steepest-descent
梯度下降是最简单,最常用的numerical optimization method之一。
首先,计算出当前的梯度:

where 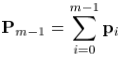
而梯度下降的步长为: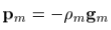
where  ,称为“line search”。
,称为“line search”。
2. Numerical optimization in function space
现在,我们考虑“无参数”模型,转而考虑直接在function space 进行numerical optimization。这时候,我们将在每个数据点x处的函数值F(x)看做是一个“参数”,仍然是来对loss funtion求解最小值。
在function space,为了表示一个函数F(x),理想状况下有无数个点,但在现实中,我们用有限个(N个)离散点来表示它: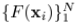 。
。
按照之前的numerical optimization的方式,我们需要求解:
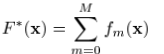
使用steepest-descent,有:

where  ,and
,and 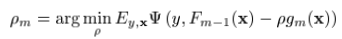
3. Finite data
当我们面对的情况为:用有限的数据集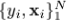 表示x,y的联合分布的时候,上述的方法就有点行不通了。我们可以试试“greedy-stagewise”的方法:
表示x,y的联合分布的时候,上述的方法就有点行不通了。我们可以试试“greedy-stagewise”的方法:
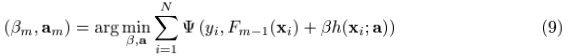
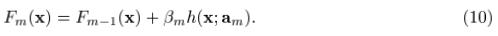
但是对于一般的loss function和base learner来说,(9)式是很难求解的。给定了m次迭代后的当前近似函数Fm-1(x),当步长的direction 是指数函数集合
是指数函数集合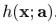 当中的一员时,
当中的一员时,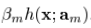 可以看做是在求解最优值上的greedy step,同样,它也可以被看做是相同限制下的steepest-descent step。作为比较,
可以看做是在求解最优值上的greedy step,同样,它也可以被看做是相同限制下的steepest-descent step。作为比较,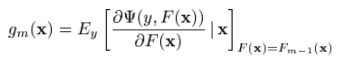 给出了在无限制条件下,在Fm-1(x)处的steepest-descent step direction。一种行之有效的方法就是在求解的时候,把它取为无限制条件下的负梯度方向
给出了在无限制条件下,在Fm-1(x)处的steepest-descent step direction。一种行之有效的方法就是在求解的时候,把它取为无限制条件下的负梯度方向 :
:
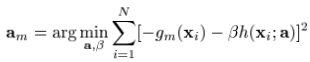
where 
这就把(9)式中较难求解的优化问题转化为了一个基于均方误差的拟合问题。
Gradient Boosting的通用解法如下:

二. 对于GBDT的一些理解
1. Boosting
GBDT的全称是Gradient Boosting Decision Tree,Gradient Boosting和Decision Tree是两个独立的概念。因此我们先说说Boosting。Boosting的概念很好理解,意思是用一些弱分类器的组合来构造一个强分类器。因此,它不是某个具体的算法,它说的是一种理念。和这个理念相对应的是一次性构造一个强分类器。像支持向量机,逻辑回归等都属于后者。通常,我们通过相加来组合分类器,形式如下:
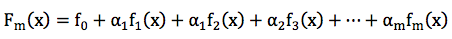
2. Gradient Boosting Modeling(GBM)
给定一个问题,我们如何构造这些弱分类器呢?Gradient Boosting Modeling (GBM) 就是构造 这些弱分类的一种方法。同样,它指的不是某个具体的算法,仍然只是一个理念。在理解 Gradient Boosting Modeling 之前,我们先看看一个典型的优化问题:
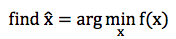
针对这种优化问题,有一个经典的算法叫 Steepest Gradient Descent,也就是最深梯度下降法。 这个算法的过程大致如下:

以上迭代过程可以这么理解:整个寻优的过程就是个小步快跑的过程,每跑一小步,都往函数当前下降最快的那个方向走一点。
这样寻优得到的结果可以表示成加和形式,即:
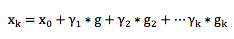
这个形式和以上Fm(x)是不是非常相似? Gradient Boosting 正是由此启发而来。 构造Fm(x)本身也是一个寻优的过程,只不过我们寻找的不是一个最优点,而是一个最优的函数。优化的目标通常都是通过一个损失函数来定义,即:

其中Loss(F(xi), yi)表示损失函数Loss在第i个样本上的损失值,xi和yi分别表示第 i 个样本的特征和目标值。常见的损失函数如平方差函数:
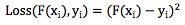
类似最深梯度下降法,我们可以通过梯度下降法来构造弱分类器f1, f2, ... , fm,只不过每次迭代时,令
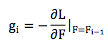
即对损失函数L,以 F 为参考求取梯度。
这里有个小问题,一个函数对函数的求导不好理解,而且通常都无法通过上述公式直接求解 到梯度函数gi。为此,采取一个近似的方法,把函数Fi−1理解成在所有样本上的离散的函数值,即:

不难理解,这是一个 N 维向量,然后计算
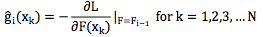
这是一个函数对向量的求导,得到的也是一个梯度向量。注意,这里求导时的变量还是函数F,不是样本xk。
严格来说 ĝi(xk) for k = 1,2, ... , N 只是描述了gi在某些个别点上的值,并不足以表达gi,但我们可以通过函数拟合的方法从ĝi(xk) for k = 1,2, ... , N 构造gi,这样我们就通过近似的方法得到了函数对函数的梯度求导。
因此 GBM 的过程可以总结为如下:

常量函数f0通常取样本目标值的均值,即
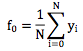
3. Gradient Boosting Decision Tree
以上 Gradient Boosting Modeling 的过程中,还没有说清楚如何通过离散值 ĝi−1(xj) for j = 1,2,3,...N 构造拟合函数gi−1。函数拟合是个比较熟知的概念,有很多现成的方法,不过有一种拟合方法广为应用,那就是决策树 Decision Tree,有关决策树的概念,理解GBDT重点首先是Gradient Boosting,其次才是 Decision Tree。GBDT 是 Gradient Boosting 的一种具体实例,只不过这里的弱分类器是决策树。如果你改用其他弱分类器 XYZ,你也可以称之为 Gradient Boosting XYZ。只不过 Decision Tree 很好用,GBDT 才如此引人注目。
4. 损失函数
谈到 GBDT,常听到一种简单的描述方式:“先构造一个(决策)树,然后不断在已有模型和实际样本输出的残差上再构造一颗树,依次迭代”。其实这个说法不全面,它只是 GBDT 的一种特殊情况,为了看清这个问题,需要对损失函数的选择做一些解释。
从对GBM的描述里可以看到Gradient Boosting过程和具体用什么样的弱分类器是完全独立的,可以任意组合,因此这里不再刻意强调用决策树来构造弱分类器,转而我们来仔细看看弱分类器拟合的目标值,即梯度ĝi−1(xj ),之前我们已经提到过

5. GBDT 和 AdaBoost
Boosting 是一类机器学习算法,在这个家族中还有一种非常著名的算法叫 AdaBoost,是 Adaptive Boosting 的简称,AdaBoost 在人脸检测问题上尤其出名。既然也是 Boosting,可以想象它的构造过程也是通过多个弱分类器来构造一个强分类器。那 AdaBoost 和 GBDT 有什么区别呢?
两者最大的区别在于,AdaBoost 不属于 Gradient Boosting,即它在构造弱分类器时并没有利用到梯度下降法的思想,而是用的Forward Stagewise Additive Modeling (FSAM)。为了理解 FSAM,在回过头来看看之前的优化问题。
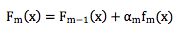
严格来说之前描述的优化问题要求我们同时找出α1, α2, ... , αm和f1, f2, f3 ... , fm,这个问题很 难。为此我们把问题简化为分阶段优化,每个阶段找出一个合适的α 和f 。假设我们已经 得到前 m-1 个弱分类器,即Fm−1(x),下一步在保证Fm−1(x)不变的前提下,寻找合适的 αmfm(x)。按照损失函数的定义,我们可以得到

如果 Loss 是平方差函数,则我们有

这里yi − Fm−1(xi)就是当前模型在数据上的残差,可以看出,求解合适的αmfm(x)就是在这 当前的残差上拟合一个弱分类器,且损失函数还是平方差函数。这和 GBDT 选择平方差损失 函数时构造弱分类器的方法恰好一致。
(1)拟合的是“残差”,对应于GBDT中的梯度方向。
(2)损失函数是平方差函数,对应于GBDT中用Decision Tree来拟合“残差”。
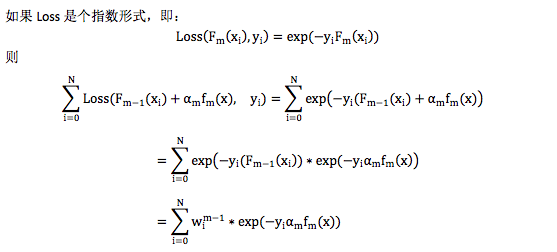
其中 wim−1= exp(−yi(Fm−1(xi))和要求解的αmfm(x)无关,可以当成样本的权重,因此在这种情况下,构造弱分类器就是在对样本设置权重后的数据上拟合,且损失函数还是指数形式。 这个就是 AdaBoost,不过 AdaBoost 最早并不是按这个思路推出来的,相反,是在 AdaBoost 提出 5 年后,人们才开始用 Forward Stagewise Additive Modeling 来解释 AdaBoost 背后的原理。
为什么要把平方差和指数形式 Loss 函数单独拿出来说呢?这是因为对这两个损失函数来说, 按照 Forward Stagewise Additive Modeling 的思路构造弱分类器时比较方便。如果是平方差损 失函数,就在残差上做平方差拟合构造弱分类器; 如果是指数形式的损失函数,就在带权 重的样本上构造弱分类器。但损失函数如果不是这两种,问题就没那么简单,比如绝对差值 函数,虽然构造弱分类器也可以表示成在残差上做绝对差值拟合,但这个子问题本身也不容 易解,因为我们是要构造多个弱分类器的,所以我们当然希望构造弱分类器这个子问题比较 好解。因此 FSAM 思路无法推广到其他一些实用的损失函数上。相比而言,Gradient Boosting Modeling (GBM) 有什么优势呢?GBM 每次迭代时,只需要计算当前的梯度,并在平方差损 失函数的基础上拟合梯度。虽然梯度的计算依赖原始问题的损失函数形式,但这不是问题, 只要损失函数是连续可微的,梯度就可以计算。至于拟合梯度这个子问题,我们总是可以选 择平方差函数作为这个子问题的损失函数,因为这个子问题是一个独立的回归问题。
因此 FSAM 和 GBM 得到的模型虽然从形式上是一样的,都是若干弱模型相加,但是他们求 解弱分类器的思路和方法有很大的差别。只有当选择平方差函数为损失函数时,这两种方法 等同。
6. 为何GBDT受人青睐
以上比较了 GBM 和 FSAM,可以看到 GBM 在损失函数的选择上有更大的灵活性,但这不足以解释GBDT的全部优势。GBDT是拿Decision Tree作为GBM里的弱分类器,GBDT的优势 首先得益于 Decision Tree 本身的一些良好特性,具体可以列举如下:
-
Decision Tree 可以很好的处理 missing feature,这是他的天然特性,因为决策树的每个节点只依赖一个 feature,如果某个 feature 不存在,这颗树依然可以拿来做决策,只是少一些路径。像逻辑回归,SVM 就没这个好处。
-
Decision Tree 可以很好的处理各种类型的 feature,也是天然特性,很好理解,同样逻辑回归和 SVM 没这样的天然特性。
-
对特征空间的 outlier 有鲁棒性,因为每个节点都是 x < 𝑇 的形式,至于大多少,小多少没有区别,outlier 不会有什么大的影响,同样逻辑回归和 SVM 没有这样的天然特性。
-
如果有不相关的 feature,没什么干扰,如果数据中有不相关的 feature,顶多这个 feature 不出现在树的节点里。逻辑回归和 SVM 没有这样的天然特性(但是有相应的补救措施,比如逻辑回归里的 L1 正则化)。
-
数据规模影响不大,因为我们对弱分类器的要求不高,作为弱分类器的决策树的深 度一般设的比较小,即使是大数据量,也可以方便处理。像 SVM 这种数据规模大的时候训练会比较麻烦。
当然 Decision Tree 也不是毫无缺陷,通常在给定的不带噪音的问题上,他能达到的最佳分类效果还是不如 SVM,逻辑回归之类的。但是,我们实际面对的问题中,往往有很大的噪音,使得 Decision Tree 这个弱势就不那么明显了。而且,GBDT 通过不断的叠加组合多个小的 Decision Tree,他在不带噪音的问题上也能达到很好的分类效果。换句话说,通过GBDT训练组合多个小的 Decision Tree 往往要比一次性训练一个很大的 Decision Tree 的效果好很多。因此不能把 GBDT 理解为一颗大的决策树,几颗小树经过叠加后就不再是颗大树了,它比一颗大树更强。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号