
代码随想录算法训练营|字符串内容复习
字符串内容复习
反转字符串
344. 反转字符串 超简单的,一行代码
点击查看代码
class Solution {
public:
void reverseString(vector<char>& s) {
for (int left = 0, right = s.size() - 1; left < right; left++, right--) {
swap(s[left], s[right]);
}
}
};
翻转字符串Ⅱ
541. 反转字符串 II 这次再看这个题,有一点疑惑的地方,就是每次i递增的都是2k的话,正好多出去一位啊,比如“abcdefg”,i指针首先是在a的位置,之后就到了e的位置,这样是没有问题的,和这个图对照一下,每次确实都是加的是2k,索引也是从0开始的。看一下反转之后的结果也是从e开始的,"bacdfeg"没有什么问题。
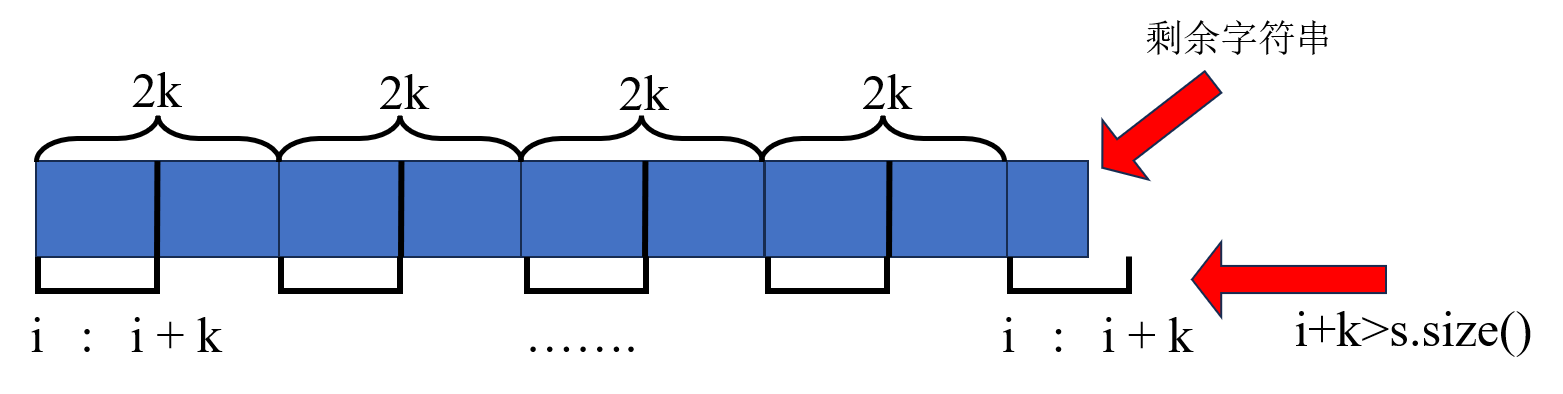
记得reverse()函数是一个左闭右开的区间
点击查看代码
class Solution {
public:
string reverseStr(string s, int k) {
for (int i = 0; i < s.size(); i += 2 * k) {
if (k + i <= s.size()) reverse(s.begin() + i, s.begin() + i + k);
if (k + i > s.size()) reverse(s.begin() + i, s.end());}
return s;
}
};
替换数字
54. 替换数字 这个题不好写的,代码实现有点绕,不写了先。
这个题需要注意的一点的就是,在for循环中,left和right移动之后,left无论是不是指向数字,其下一个数都肯定要--,right也要--
点击查看代码
#include<iostream>
#include<vector>
using namespace std;
int main () {
string s;
cin >> s;
int count = 0;
for (int i = 0; i < s.size(); i++) {
if (s[i] <= '9' && s[i] >= '0') count++;
}
int oldSize = s.size();
s.resize(s.size() + count * 5);
int left = oldSize - 1, right = s.size() - 1;
for (; left >= 0; ) {
if (s[left] <= '9' && s[left] >= '0') {
s[right--] = 'r';
s[right--] = 'e';
s[right--] = 'b';
s[right--] = 'm';
s[right--] = 'u';
s[right--] = 'n';
left--;
} else {
s[right] = s[left];
left--;
right--;
}
}
cout << s;
}
今天54再写一遍回顾一下
~~~
反转字符串中的单词
151. 反转字符串中的单词 现在有点疑惑的地方是在这里,if (slow != 0) s[slow++] = ' ';是在干嘛?s[slow++] = ' '的操作就是精准地控制了每相邻两个单词之间恰好有一个空格来间隔
注意这里还有一个s.resize的操作
脑袋里有好多问号
去空格了以后输出的位数不对,应该是只有11位的。这个去空格好麻烦
这里刚开始一直没有找到错误在哪?重新写了一遍找到了,不是right != ' '而是s[right] != ' '
int left = 0, right = 0;
for (; right < s.size(); right++) {
if (s[right] != ' ') {
if (left != 0) s[left++] = ' ';
while (right < s.size() && right != ' ') {
s[left++] = s[right++];
}
}
}
cout << left << endl;
s.resize(left);
这个题怎么写的这么费劲?
点击查看代码
class Solution {
public:
string reverseWords(string s) {
int left = 0, right = 0;
for (; right < s.size(); right++) {
if (s[right] != ' ') {
if (left != 0) s[left++] = ' ';
while (right < s.size() && s[right] != ' ') {
s[left++] = s[right++];
}
}
}
s.resize(left);
reverse(s.begin(), s.end());
int start = 0;
for (int i = 0; i <= s.size(); i++) {
if (s[i] == ' ' || i == s.size()) {
reverse(s.begin() + start, s.begin() + i);
start = i + 1;
}
}
return s;
}
};
今天再写一遍
下面的是自己写的翻转函数,意思一样
点击查看代码
class Solution {
private:
void rev(string &s, int start, int end) {
int left = start, right = end;
for (; left < right; left++, right--) {
char temp = s[left];
s[left] = s[right];
s[right] = temp;
}
}
public:
string reverseWords(string s) {
int left = 0, right = 0;
for (; right < s.size(); right++) {
if (s[right] != ' ') {
if (left != 0) s[left++] = ' ';
while (s[right] != ' ' && right < s.size()) {
s[left++] = s[right++];
}
}
}
s.resize(left);
// reverse(s.begin(), s.end());
rev(s, 0, s.size() - 1);
cout << s << endl;
int start = 0;
for (int i = 0; i <= s.size(); i++) {
if (s[i] == ' ' || i == s.size()) {
// reverse(s.begin() + start, s.begin() + i);
rev(s, start, i - 1);
start = i + 1;
}
}
return s;
}
};
右旋字符串
右旋转字符串超级简单的
点击查看代码
#include<iostream>
#include<algorithm>
using namespace std;
int main() {
string s;
int k;
cin >> k;
cin >> s;
reverse(s.begin(), s.end());
reverse(s.begin(), s.begin() + k);
reverse(s.begin() + k, s.end());
for (int i = 0; i < s.size(); i++) {
cout << s[i];
}
}
实现 strStr()
核心是四步:
-
初始化
-
前后缀不相等的情况
-
前后缀相等的情况
-
更新next数组
首先是前缀表的作用是什么:用前缀表可以找到当字符不匹配的时候指针应该移动的位置
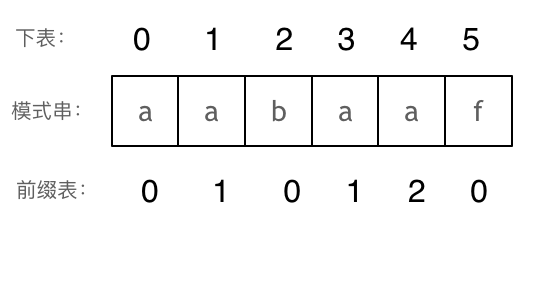
什么是next数组:next数组就可以是前缀表,但是很多实现都是把前缀表统一减一(右移一位,初始位置为-1)之后作为next数组。
如何计算next数组,通过分设一个i指针,指向后缀的末尾,一个j指针,指向前缀的末尾。然后对二者进行比较。
注意在计算next数组的时候,其指针i是从指向1开始的。
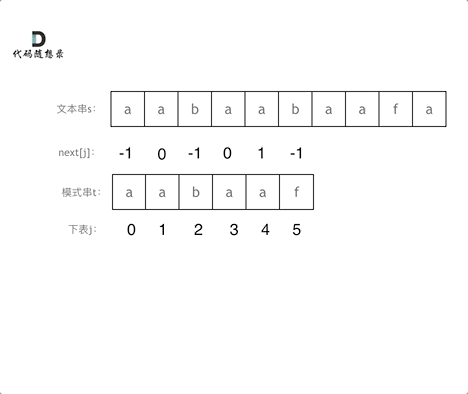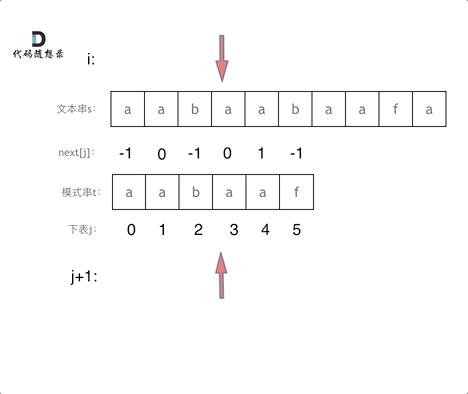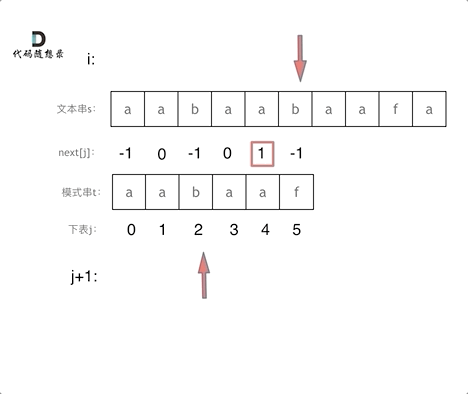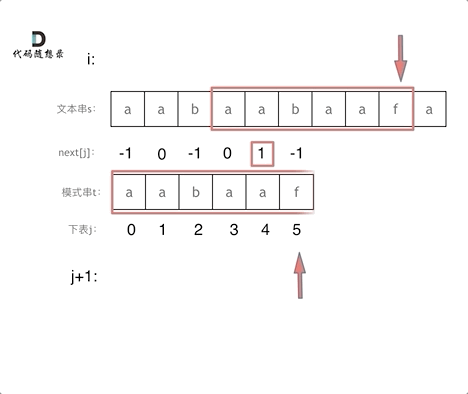
在进行字符串的比较的时候,以下是k哥的示例图
点击查看代码
class Solution {
private:
void getNext(int* next, string& s) {
int j = 0;
next[0] = 0;
for (int i = 1; i < s.size(); i++) {
while (j > 0 && s[j] != s[i]) j = next[j - 1];
if (s[j] == s[i]) j++;
next[i] = j;
}
}
public:
int strStr(string haystack, string needle) {
int j = 0;
vector<int> next(needle.size());
getNext(&next[0], needle);
for (int k = 0; k < next.size(); k++) cout << next[k];
for (int i = 0; i < haystack.size(); i++) {
while (j > 0 && haystack[i] != needle[j]) j = next[j - 1];
if (haystack[i] == needle[j]) j++;
if (j == needle.size()) return i - needle.size() + 1;
}
return -1;
}
};
KMP内容复习
在计算next数组的时候严格按照这四步来就行:
-
初始化
-
前后缀不相等的情况
-
前后缀相等的情况
-
更新next数组
注意在比较的时候,当比较成功的时候,会对j当前的数值加1,然后赋值给i。

而当比较失败的时候,j是在不断回退的,如下图匹配“f”和“a”之后。会将“a”当前的j值0赋给f下面的i
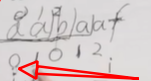
重复的子字符串
这个图有点看不懂了,不知道这里的等式是什么意思。5.30记:今早一看就明白了,挺神奇的,就隔了一天再看就豁然开朗了。在力扣题目中,需要用的结论是【s一定是重复子串组成】推【中间能凑成s子串】,引入这几个例子的目的是从【中间能凑成s子串】推【s一定是重复子串组成】,充要条件这样。所以看第一张图,其中的[4,5,0,1,2,3]其实就是中间的子串s,也就是他和[0,1,2,3,4,5]是一样的,所以才能用等号进行推导。
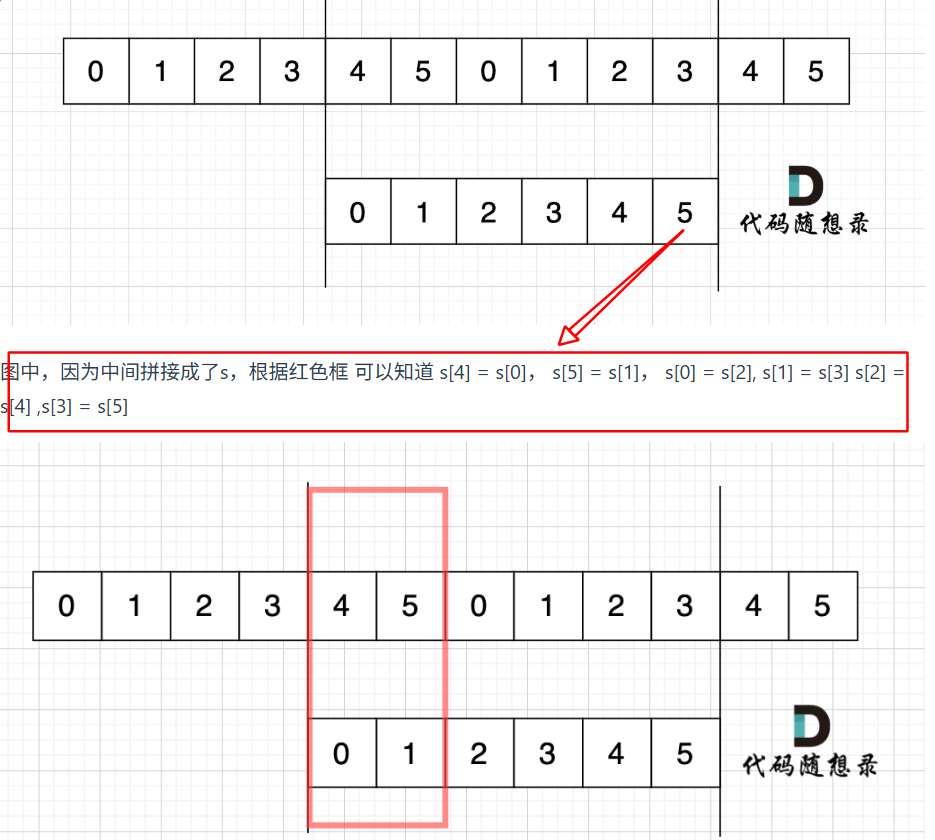
移动匹配
点击查看代码
class Solution {
public:
bool repeatedSubstringPattern(string s) {
string ss;
ss = s + s;
ss.erase(ss.begin());
ss.erase(ss.end() - 1);
if (ss.find(s) != std::string::npos) return true;
return false;
}
};
KMP算法之一
之前没有注意,这个题k哥讲的时候用了一个推导的二级结论。
如果一个字符串是由他的子字符串重复构成的,那么这个字符串减去他的最长相等前缀就是最小的重复字串
这个有点没有看懂,推导太多了,故直接用KMP在ss中进行匹配,然后返回true或者false即可
点击查看代码
class Solution {
private:
void getNext(int* next, string s) {
int j = 0;
next[0] = 0;
for (int i = 1; i < s.size(); i++) {
while (j > 0 && s[i] != s[j]) j = next[j - 1];
if (s[i] == s[j]) {
j++;
next[i] = j;
}
}
}
public:
bool repeatedSubstringPattern(string s) {
string ss;
ss = s + s;
vector<int> next(s.size());
getNext(&next[0], s);
int j = 0;
for (int i = 1; i < ss.size() - 1; i++) {
while (j > 0 && ss[i] != s[j]) j = next[j - 1];
if (ss[i] == s[j]) {
j++;
}
if (j == s.size()) return true;
}
return false;
}
};
KMP算法之二
就是第二重使用KMP的方法就是引用那个结论 “如果这个字符串s是由重复子串组成,那么最长相等前后缀不包含的子串是字符串s的最小重复子串” ,证明就不看了,感觉有点复杂理解不太了。
这里就是直接用到这里的推导,但是需要注意的是因为在next数组计算时我没用统一减一,所以直接next[len - 1]就是最长相等前后缀的长度,不用再单独加1了(单独加1针对的是统一减一的情况)

点击查看代码
class Solution {
private:
void getNext(int* next, string s) {
int j = 0;
next[0] = 0;
for (int i = 1; i < s.size(); i++) {
while (j > 0 && s[i] != s[j]) j = next[j - 1];
if (s[i] == s[j]) {
j++;
}
next[i] = j;
}
}
public:
bool repeatedSubstringPattern(string s) {
int len = s.size();
vector<int> next(s.size());
getNext(&next[0], s);
for (int i = 0; i < s.size(); i++) cout << next[i] << ' ';
if (len % (len - (next[len - 1])) == 0) return true;
return false;
}
};
复盘
翻转字符串里的单词又不会写了,感觉还是理解不太了
151. 反转字符串中的单词
看了一下文档讲解,核心是双指针,其思路和27.移除元素是一样的
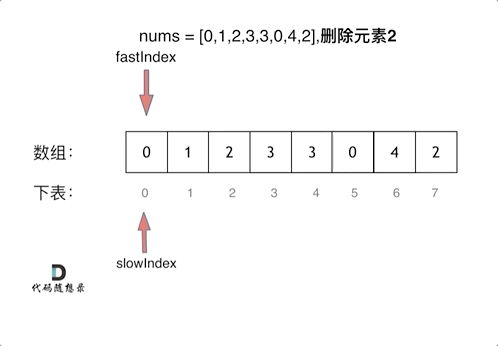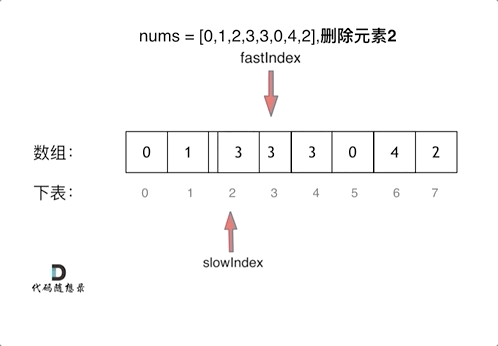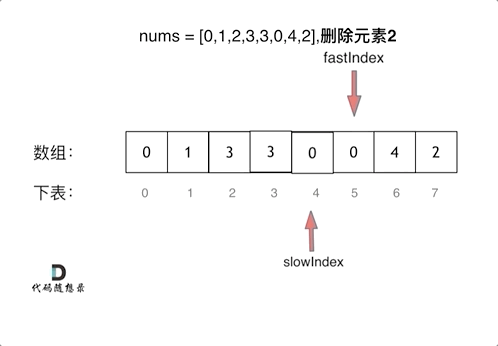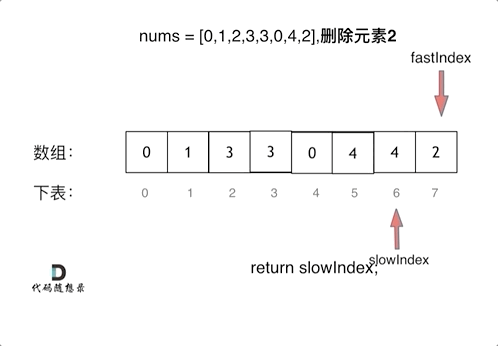
看一下这里的代码,注意:他不是在遇到空格的时候进行处理,是在遇到非空格的时候进行的处理。也就是前提条件是if (s[i] != ' '),这行的作用是来规避掉单词之间重复的空格。下面还有需要注意的两点
-
if (slow != 0) s[slow++] = ' ';,在快指针到达下一个单词的首字母的时候,添加一个空格。 -
while (i < s.size() && s[i] != ' '),从单词的首字母开始,这行的作用是来一次性将一个单词从快指针往后读入到慢指针的
所以,当for循环的s[i]所指不是空的时候,一次性可以将“去重复空格”+“写入单词”两个部分完成
for (int i = 0; i < s.size(); ++i) { //
if (s[i] != ' ') { //遇到非空格就处理,即删除所有空格。
if (slow != 0) s[slow++] = ' '; //手动控制空格,给单词之间添加空格。slow != 0说明不是第一个单词,需要在单词前添加空格。
while (i < s.size() && s[i] != ' ') { //补上该单词,遇到空格说明单词结束。
s[slow++] = s[i++];
}
}
}
点击查看代码
class Solution {
public:
string reverseWords(string s) {
int left = 0, right = 0;
for (; right < s.size(); right++) {
if (s[right] != ' ') {
if (left != 0) s[left++] = ' ';
while (right < s.size() && s[right] != ' ') {
s[left++] = s[right++];
}
}
}
s.resize(left);
int start = 0;
reverse(s.begin(), s.end());
for (int i = 0; i <= s.size(); i++) {
if (s[i] == ' ' || i == s.size()) {
reverse(s.begin() + start, s.begin() + i);
start = i + 1;
}
}
return s;
}
};
151反转字符串
之前写的是处理的中间部分是先加上单词之间的空格,之后再利用双指针进行单词读取。注意这个顺序不能变
如果直接写成这样的提交是不对的
while (s[right] != ' ' && right < s.size()) s[left++] = s[right++];
if (left != 0) s[left++] = ' ';
注意这样的方式在处理完最后第一个字符串的时候,left会++,之后进入下面的if判断之后又会进行一次++操作,所以多加了一次。要想正确的话,就得在下面的resize(left - 1)减少一次++
KMP
注意在这一部分,是对next[i]进行更新,刚才又写错了,对next[j]进行了更新,那样就把之前的next数组修改了,就肯定不对了。
if (s[j] == s[i]) {
j++;
next[i] = j;
}
总结
- 字符串的内容中,反转字符串是很简单的,用swap是很简单的,只需要一行代码就OK,另外还可以用正常的双指针。
- 翻转字符串Ⅱ就是每次i自增2k个单元,然后进行反转即可
- 替换数字这个题需要注意的就是一开始要先进行数字的查找,之后需要修改字符串的长度,一个old,一个new。
- 151反转字符串中的单词,这个真的是写了忘,写了忘。这个题最核心的思路就是和之前27移除元素一致,用的双指针,讲快指针符合条件不为空的char一个个赋给慢指针所在的单元
- 右旋转字符串就很简单了,找区间分别进行翻转即可
- KMP的getNext实现,也用的是双指针,注意写getNext函数时候严格的四步:①初始化next②前后缀不相等③前后缀相等④更新next。
这个KMP的顺序也不能反,如果先处理前后缀相等,再处理前后缀不等的情况。j指针会在处理了上一个相等的前后缀之后,到这里判断前后缀不等,之后j指针就又会跳回原来的位置,但此时i还没有来得及自增。这是出问题的地方。举例用"ababcaabc" - 重复的子字符串有三种方法可以做,第一种是移除匹配,两个字符串相加之后除去首尾,之后直接find。第二种前面的部分不变,在后面的部分使用KMP进行搜索。第三种是用那个推论“如果这个字符串s是由重复子串组成,那么最长相等前后缀不包含的子串是字符串s的最小重复子串”


 浙公网安备 33010602011771号
浙公网安备 33010602011771号