
论文学习8——Universal Actions for Enhanced Embodied Foundation Models
Abstarct
To solve the heterogeneity in embodied datasets, which due to distinct physical embodiment and control interfaces for different robots. The authors proposed a embodied modeling framework UniAct. The universal actions can be efficiently back to heterogeneous actionable commands by simply adding embodiment-specific details.
Introduction
The versatile embodied foundation models are advantageous in many tasks. However, the embodied action faces the challenges from the substantial heterogeneity of embodied data.
Most of the prior studies cannot treat the the issue of the action heterogeneity. Because the connections between individual action spaces prone to be split.
The universal actions learned in UniAct encode the generic atomic behaviors and decode the universal action to an embodiment-specific one. And the decoding processing just needs to add some embodiment details for each robotic platform.
UniAct employs a shared Vision Language Model(VLM) to construct the universal action space, which encapsulates an atomic behavior versatile enough to be executed by diverse robots. And this setup drives VLM to identify and exploit shared primitive behaviors. After that, the actions can be translated into precise commands for embodiment through decoders. Then, this commands will be augmented with the embodiment-specific features, using observational data.
Related Work
Multimodal Foundation Models
Large Language Models have shown impressive zero-shot and in-context learning capabilities. Building on this, large Vision Language Models(VLMs) are developed by integrating vision and language into a unified tokenized space.
Embodied Foundation Models
The State-of-the-art model also need to get action labels from different robotics platform. But they suffer from serious performance bottlenecks towards building a generalist embodied agent.
The author list some frontier works about embodiment control. The existing works either ignore the heterogeneous properties of different sources, which lead to failing to exploit the underlying shared commonalities across different robots.
Embodied Models with Latent Action Spaces
Their work aims to extract a versatile universal action space, akin to a latent space but encodes common atomic control behaviors and patterns across various robotic platform. However, some works develop embodied models in latent spaces, which means struggling to address action heterogeneity across different embodiment. In contrast, the authors’ actions integrate goal information from the embodiment-agnostic language modality with supervision on the actual action signal.
The UniAct Framework
Universal Action Space
The author model the universal action space as \(u\in R^{N\times D}\) and implement it with a vector quantized codebook, as \(u=(u_1, u_2,u_3,\cdots,u_N)\)
Some studies regard the actions as the dynamic changes observed between two visual states. However, this scheme suffers tow limitations. One is the changes may influenced by the external factors, not from the robots. Another one is the interpretation of two observations cause the difficulty of standardizing.
Universal Action Extraction
The author propose a new method for extracting universal action, pivoting away from solely focusing on explaining observational changes, but more on understanding task progression. Specifically, they fine-tune a VLM model as the universal action extractor. This extractor creates a crucial information bottleneck for cross-domain generalization, as different robots are forced to use the same discrete codebook to capture the generic and shared atomic behaviors across all domains.
The non-differentiable arg max impedes the gradient propagation. So the authors utilize the Gumbel-Softmax technique to facilitate gradient estimation.
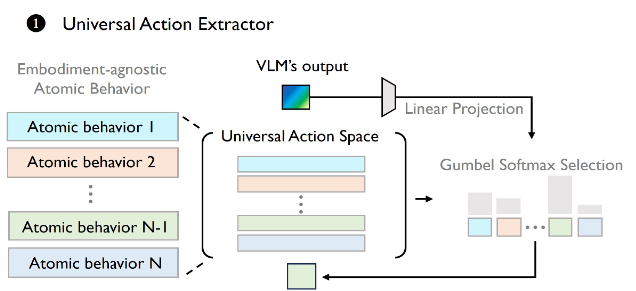
Heterogeneous Decoding
In order to translate the highly abstract behaviors into precise, embodiment-specific control signals, the authors design a series lightweight decoder heads to adapt for each type of embodiment. Through keeping the decoding heads lightweight, the authors ensure that the majority of learning is conducted for the universal action and maximally improving generalization across different embodiments.
Training Procedure
To precisely translate the universal actions into domain-specific control signals, the authors use heterogeneous datasets \(D\) to train the model. In detail, UniAct ingests \(o\) and \(g\) as inputs to predict the universal action \(u^{\*}\) . Besides, the authors optimize the objective(\(L_{loss},o,g\)) to let \(u\) , universal action extractors and heterogeneous heads update in time.
Experiments
Experiments Setup
The author select three SOTA VLA models but they are required complicated preprocessing on the actions
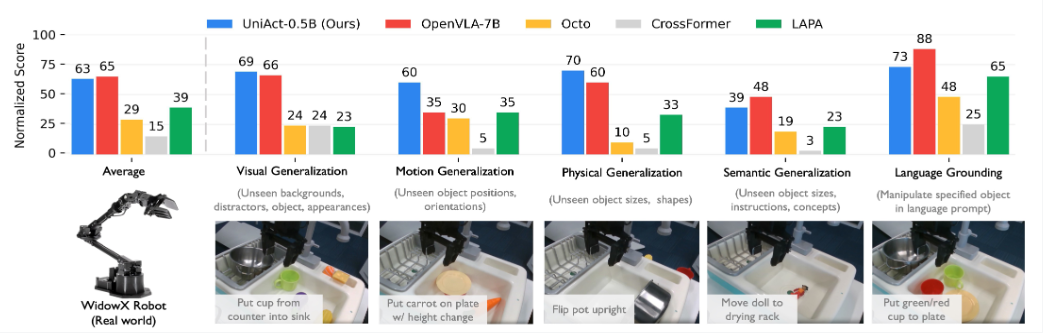
Main Results
The authors use real-world WidowX robot and a simulation Franka robot to verify that UniAct model can translate the universal actions seamlessly back into deployable control signals.
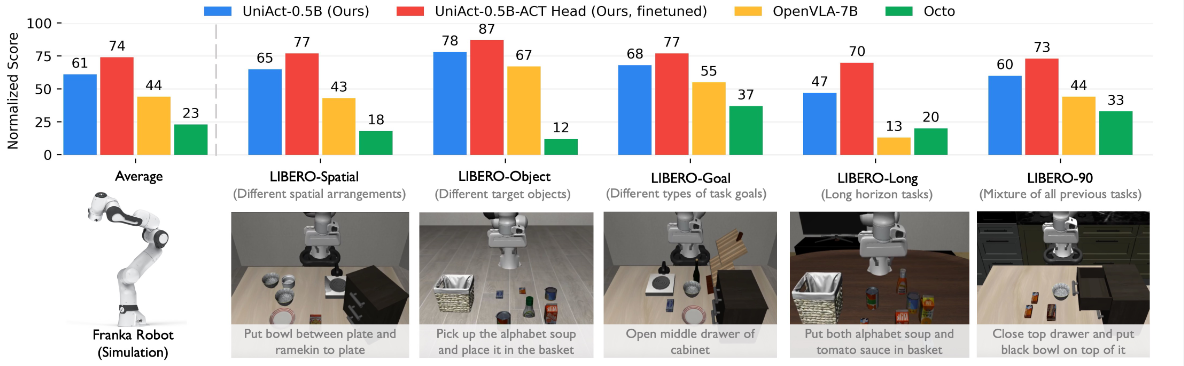
They also utilize the LIBERO Benchmarks for evaluation in 130 tasks. Finally, UniAct significantly enhances task performance on the LIBERO benchmark.
Fast Adaption to New-Embodiment
Uni-Act can rapidly adapt to new embodiments and control interfaces. And the author facilitate fast adaption by freezing the code-book and the universal action extractor.
The Uni-Act with minimal parameter space expansion has high effectiveness and adaptability.
What’s more, the authors compare UniAct-0.5B with ACT decoder after fine-tuning and LLaVa-OV-0.5B. Eventually, the Uni-Act get better performance.
In-depth Analysis of Universal Actions
First, consistent semantical behaviors are encoded as the same universal actions across diverse embodiments. Put it into another words, the specific universal action can be decoded back to consistent behaviors. Second, they use universal action to interact with the robot directly and easily.

They authors summarize the universal action and find the the universal action extractor indeed exploits behaviors more on task progressions over embodiment details.
Conclusion
The authors enable proposed UniAct, which encodes shareable atomic behaviors across diverse embodied action spaces, enabling the 0.5B parameter model to outperform SOTA models. Moreover, the model can also be used as universal action tokenizer to power the construction of future large-scaled embodied foundation models.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号