springboot2.X实现双数据源的最简方法(Hikari、Druid两种实现方式)
一、需求解析
这里为项目配置两个数据源,不是为了做读写分离,也不是为了主备切换,单纯是为了支持一个应用同时从2个数据源读写数据。
典型的例子是,一个数据应用,向自己的轻量级数据库(比如mysql)中读写应用相关数据,从数据仓库(比如Hive)拿重量的大宗分析数据。
springboot+mybatis可以非常简单地实现单数据源配置,通过在service层创建Mapper对象拿到数据,且默认就有了Hikari连接池的支持,甚至一个dbutil的类都不需要自己写。
但如果是两个数据源,则需要人工给数据请求“分流”,即不同的Mapper要分配给不同的数据源做数据库连接。
二、工程的实现思路
这里先贴出我的项目工程目录结构,以便讲清思路。
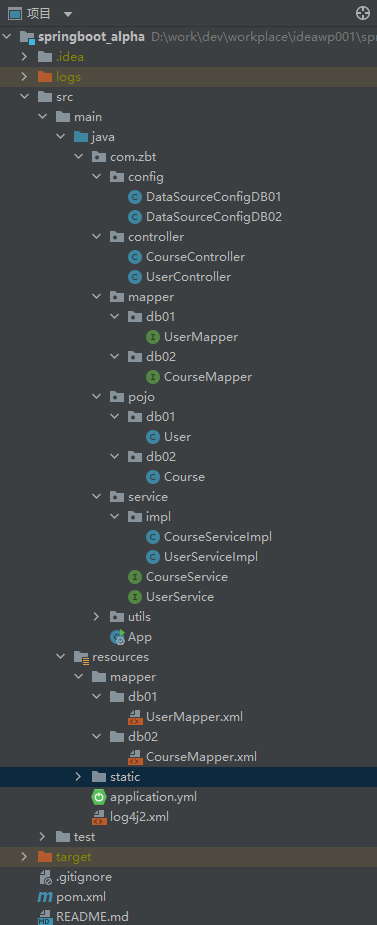
两个数据源分别是db01和db02,这里模拟db01下有数据模型user(用户数据),db02下有数据模型course(课程数据)。
config下创建两个数据源的Config配置类用来分流,这是实现双数据源的关键。
mapper下db01和db02分而治之,也就是数据模型映射到程序中,db01和db02是不掺和的,pojo(dbentity)层同理。
service层和controller合而治之,即在业务调用过程中,可以实现任意一个接口混合调用两个数据源,实现灵活的业务。
而在负责配置数据源入口参数的application.yml中,相比单数据源,需要增加一级db的标签,简单配置如下:
spring:
datasource:
db01:
jdbc-url: jdbc:dm://192.168.124.221:5236
username: panda
password: 12345678
driver-class-name: dm.jdbc.driver.DmDriver
type: com.zaxxer.hikari.HikariDataSource
maximum-pool-size: 50
minimum-idle: 20
connection-timeout: 60000
db02:
jdbc-url: jdbc:mysql://192.168.124.221:3306/panda?useSSl=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: user01
password: 12345678
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.zaxxer.hikari.HikariDataSource
maximum-pool-size: 10
minimum-idle: 3
connection-timeout: 60000
后面讲实现的时候,会对连接池做进一步细化,这里先说思路。相比单数据源,这里添加一个层级,把db01和db02分开,除了有各自的url、username、password、driver以外,数据库连接池类型、参数(如最大池数量)也分开。
这里因为加了db层级,所以spring默认解析的时候,是找不到数据库连接信息的,所以必须增加config类,显性告诉spring如何去找。
三、Hikari实现
1 pom依赖
Hikari是springboot2.X以后的默认数据源连接池,不需要引入任何依赖。
2 Application.yml
分开配置的两个数据源,type分别都指定为com.zaxxer.hikari.HikariDataSource。
spring:
datasource:
db01:
jdbc-url: jdbc:dm://192.168.124.221:5236
username: panda
password: 12345678
driver-class-name: dm.jdbc.driver.DmDriver
type: com.zaxxer.hikari.HikariDataSource
#最大连接数,小于等于0会被重置为默认值10;大于零小于1会被重置为minimum-idle的值
maximum-pool-size: 50
#最小空闲连接,默认值 10,小于0或大于maximum-pool-size,都会重置为maximum-pool-size
minimum-idle: 20
#连接超时时间:毫秒,小于250毫秒,否则被重置为默认值30秒
connection-timeout: 60000
#空闲连接超时时间,默认值600000ms(10分钟),大于等于max-lifetime且max-lifetime>0,会被重置为0;
#不等于0且小于10秒,会被重置为10秒。
#只有空闲连接数大于最大连接数且空闲时间超过该值,才会被释放(自动释放过期链接)
idle-timeout: 600000
#连接最大存活时间.不等于0且小于30秒,会被重置为默认值30分钟.设置应该比mysql设置的超时时间短
max-lifetime: 640000
#连接测试查询
connection-test-query: SELECT 1 from dual
db02:
jdbc-url: jdbc:mysql://192.168.124.221:3306/panda?useSSl=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: user01
password: 12345678
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.zaxxer.hikari.HikariDataSource
maximum-pool-size: 10
minimum-idle: 3
connection-timeout: 60000
idle-timeout: 600000
max-lifetime: 640000
connection-test-query: SELECT 1 from dual
3 Config类
两个数据源,两个Config类,注意给这两个类打上@MapperScan注解,且直接指明映射的mapper目录,对于db01来说,其专用mapper目录中的所有mapper都会走db01数据源,db02同理。
DataSourceConfigDB01.java
package com.zbt.config;
import com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import javax.sql.DataSource;
@Configuration
@MapperScan(basePackages = "com.zbt.mapper.db01", sqlSessionFactoryRef = "db01SqlSessionFactory")
public class DataSourceConfigDB01 {
@Primary
@Bean("db01DataSource")
@ConfigurationProperties(prefix = "spring.datasource.db01")
public DataSource getDB01DataSource(){
//使用默认的Hikari连接池时,用默认的DataSourceBuilder:
return DataSourceBuilder.create().build();
}
@Primary
@Bean("db01SqlSessionFactory")
public SqlSessionFactory db01SqlSessionFactory(@Qualifier("db01DataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/db01/*.xml"));
return bean.getObject();
}
@Primary
@Bean("db01SqlSessionTemplate")
public SqlSessionTemplate db01SqlSessionTemplate(@Qualifier("db01SqlSessionFactory") SqlSessionFactory sqlSessionFactory){
return new SqlSessionTemplate(sqlSessionFactory);
}
}
相比db01的配置类,db02的配置类中,所有方法不打@Primary。按照笔者的分开思路,已经无所谓有没有Primary注解了,所有的数据调用实际都是明确了数据源的。
DataSourceConfigDB02.java
package com.zbt.config;
import com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import javax.sql.DataSource;
@Configuration
@MapperScan(basePackages = "com.zbt.mapper.db02", sqlSessionFactoryRef = "db02SqlSessionFactory")
public class DataSourceConfigDB02 {
@Bean("db02DataSource")
@ConfigurationProperties(prefix = "spring.datasource.db02")
public DataSource getDB02DataSource(){
//使用默认的Hikari连接池时,用默认的DataSourceBuilder:
//return DataSourceBuilder.create().build();
}
@Bean("db02SqlSessionFactory")
public SqlSessionFactory db02SqlSessionFactory(@Qualifier("db02DataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/db02/*.xml"));
return bean.getObject();
}
@Bean("db02SqlSessionTemplate")
public SqlSessionTemplate db02SqlSessionTemplate(@Qualifier("db02SqlSessionFactory") SqlSessionFactory sqlSessionFactory){
return new SqlSessionTemplate(sqlSessionFactory);
}
}
4 Mapper实现的xml
由于在config类中写了MapperScan注解,因此在mapper层,已经无需指定数据源。
UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.zbt.mapper.db01.UserMapper">
<!--查询所有用户-->
<select id="getUserList" resultType="com.zbt.pojo.db01.User">
select id, name, phone1, pwd from panda.t_user;
</select>
<!--删除一个用户,通过id-->
<delete id="deleteUserById" parameterType="int">
delete from panda.t_user
where id = #{id};
</delete>
</mapper>
CourseMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.zbt.mapper.db02.CourseMapper">
<!--查询所有课程-->
<select id="getCourseList" resultType="com.zbt.pojo.db02.Course">
select course_id, course_name, course_teacher, course_begin_date, course_end_date from panda.t_course;
</select>
<!--添加一门课程-->
<insert id="addCourse" parameterType="com.zbt.pojo.db02.Course" useGeneratedKeys="true" keyProperty="course_id">
insert into panda.t_course(course_name, course_teacher, course_begin_date, course_end_date)
values(#{course_name}, #{course_teacher}, #{course_begin_date}, #{course_end_date});
</insert>
</mapper>
5 service和controller
在service层,直接用UserMapper、CourseMapper访问数据即可,和数据源无关。controller同理。
这里只贴出一个service实现的例子。
package com.zbt.service.impl;
import com.zbt.mapper.db01.UserMapper;
import com.zbt.pojo.db01.User;
import com.zbt.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service("UserService")
public class UserServiceImpl implements UserService {
private final UserMapper userMapper;
@Autowired
public UserServiceImpl(UserMapper userMapper) {
this.userMapper = userMapper;
}
@Override
public List<User> getAllUsers() {
return userMapper.getUserList();
}
}
四、Druid实现
这部分将使用更为流行的阿里巴巴开源的Druid数据库连接池组件实现连接池,相比默认的Hikari,性能更好且有非常实用的监控功能。
重点讲解Druid在支持双数据源时,与Hikari的区别。
1 pom依赖
引入druid和druid-spring-boot-starter两个依赖,这里使用的是较新的1.2.18版本。
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.18</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.18</version>
</dependency>
2 application.yml
在配置datasource时,按照以下的嵌套进行配置最为清晰合理。这里注意,一旦使用Druid,jdbc-url必须改为url。
db01和db02两段,还是和配置Hikari思路一样,所有连接池属性,两个数据源各配各的,druid段落配druid自身的内容。
spring:
datasource:
db01:
url:
username:
password:
driver-class-name:
type: com.alibaba.druid.pool.DruidDataSource
......
db02:
url:
username:
password:
driver-class-name:
type: com.alibaba.druid.pool.DruidDataSource
......
druid:
......
这里给出笔者的一个相对比较完整的配置。
stat-view-servlet配置了打开druid专用的servlet界面,并配置了用户名口令和白名单IP。
web-stat-filter配置了druid额外可以监控的web,这个实际不属于数据库连接池范畴了,但druid很贴心地提供了对http/https访问的监控。
还有一个值得注意的是db01和db02段分别配置的filters,config,stat对任何数据源都应该配置,否则监控的统计功能会有问题;但wall功能,即防火墙功能,只有druid支持的数据库才行。笔者的db01是达梦数据库,这个druid不支持,强加上会报错,因此去掉了。笔者db02是mysql,这个druid当然支持,所以可以配上。
spring:
datasource:
db01:
url: jdbc:dm://192.168.124.221:5236
username: panda
password: 12345678
driver-class-name: dm.jdbc.driver.DmDriver
type: com.alibaba.druid.pool.DruidDataSource
initial-size: 5 # 初始化大小
min-idle: 5 # 最小
max-active: 100 # 最大
max-wait: 60000 # 配置获取连接等待超时的时间
validation-query: select 1 from dual
time-between-eviction-runs-millis: 60000 # 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
min-evictable-idle-time-millis: 300000 # 指定一个空闲连接最少空闲多久后可被清除,单位是毫秒
filters: config,stat # 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.slowSqlMillis=200;druid.stat.logSlowSql=true;config.decrypt=false
test-while-idle: true
test-on-borrow: true
test-on-return: false
pool-prepared-statements: true # 是否缓存preparedStatement,也就是PSCache 官方建议MySQL下建议关闭 个人建议如果想用SQL防火墙 建议打开
max-pool-prepared-statement-per-connection-size: 20
db02:
url: jdbc:mysql://192.168.124.221:3306/panda?useSSl=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: user01
password: 12345678
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
initial-size: 5
min-idle: 5
max-active: 100
max-wait: 60000
validation-query: select 1 from dual
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
filters: config,stat,wall
connectionProperties: druid.stat.slowSqlMillis=200;druid.stat.logSlowSql=true;config.decrypt=false
test-while-idle: true
test-on-borrow: true
test-on-return: false
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
druid:
web-stat-filter:
enabled: true
url-pattern: /*
exclusions: /druid/*,*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico
session-stat-enable: true
session-stat-max-count: 10
stat-view-servlet:
enabled: true
url-pattern: /druid/*
reset-enable: true
login-username: admin
login-password: password
allow: 192.168.18.5,192.168.18.9
3 Config类
这里只给出db01的config类,DataSourceConfigDB01.java。db02完全类似。
相比Hikari,这里尤其要注意的是,getDB01DataSource()方法,要使用DruidDataSourceBuilder创建并返回。其他的代码与Hikari实现完全一致。
笔者在第一次调试Druid的时候,就是没注意官方readme中的这个细节,导致无论怎么配,都是Hikari连接池生效。
package com.zbt.config;
import com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import javax.sql.DataSource;
@Configuration
@MapperScan(basePackages = "com.zbt.mapper.db01", sqlSessionFactoryRef = "db01SqlSessionFactory")
public class DataSourceConfigDB01 {
@Primary
@Bean("db01DataSource")
@ConfigurationProperties(prefix = "spring.datasource.db01")
public DataSource getDB01DataSource(){
//使用Druid连接池时,用专门的DataSourceBuilder:
return DruidDataSourceBuilder.create().build();
}
@Primary
@Bean("db01SqlSessionFactory")
public SqlSessionFactory db01SqlSessionFactory(@Qualifier("db01DataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/db01/*.xml"));
return bean.getObject();
}
@Primary
@Bean("db01SqlSessionTemplate")
public SqlSessionTemplate db01SqlSessionTemplate(@Qualifier("db01SqlSessionFactory") SqlSessionFactory sqlSessionFactory){
return new SqlSessionTemplate(sqlSessionFactory);
}
}
4 mapper、service和controller
使用Druid,到了mapper、service、controller这三层,与Hikari实现是一模一样的,这里不再重复。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号