BUAA-OO Unit1单元总结
BUAA-OO Unit1单元总结
第一次作业
作业简介
输入一定格式的简单多项式,并实现对其导函数的求解。
实现思路
- 首先,第一次作业保证输入都是合法格式,因此直接将空白符号(包括
\t、\s)替换后再进行分析可简化运算。(但同样第一次作业的性能分取决于输出时间,因此直接替换可能一定程度上影响性能分) - 规范格式后,由于第一次作业的表达因子类型较为单一,所以我选择了直接使用正则表达式找出表达式中的各个因子并进行求导运算。具体实现如下:
- 通过正则表达式提出各个项
- 提取出项后提取出各个因子,相同类型的因子求导后直接进行合并(如幂函数的幂指数直接相加,常数因子的系数直接相乘。)
- 最后再次进行合并合并同类项操作:将提取出的项存放在一个ArrayList中,如果遇到系数指数都相同的项,则直接进行合并,反之则直接存入ArrlyList。
度量分析
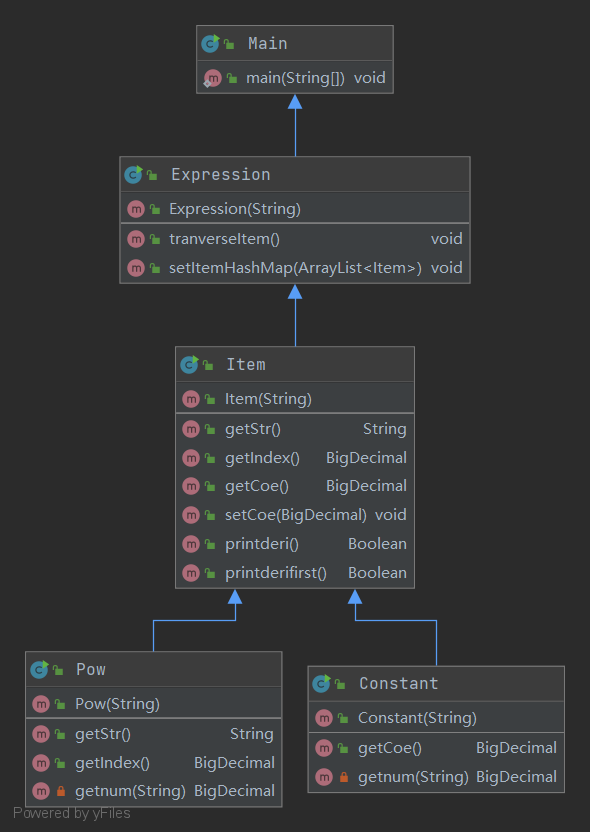
本次作业实现架构如下图所示:
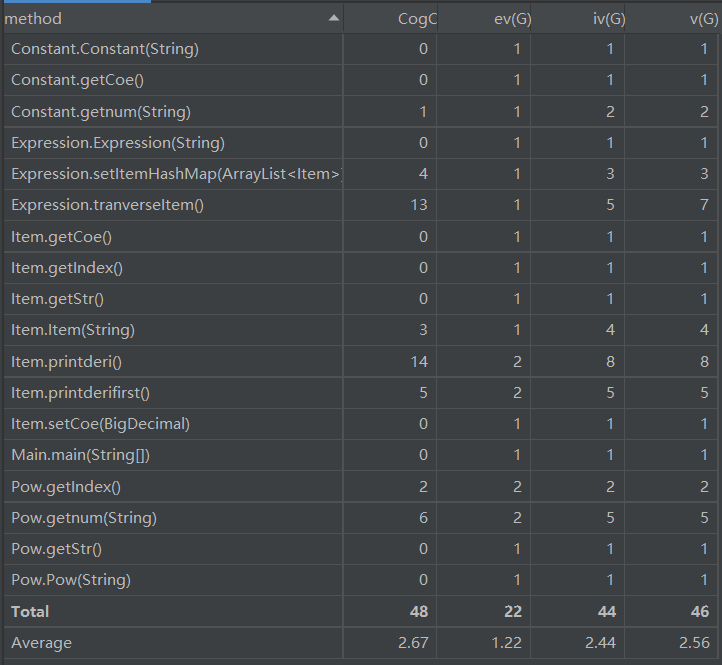
本次作业的代码方法复杂度分析如下:可以看出代码复杂度在正常范围。
优化思路
- 合并同类项
- 第一项是正项时可以少一个符号
x**2替换为x*x
bug分析
由于本次作业较为简单,在强测和互测中没有被hack,同样的我也没有发现别人的bug。。。
第二次作业
作业简介
相较于第一次作业,增加了三角因子(sin(x)、cos(x))以及嵌套(括号中可以有表达式因子)。
实现思路
整体思路:递归下降提取表达式因子并生成表达式树。
整体架构:(其实我感觉写累赘了但是后面真的不想改了)
Parser专门用于分析表达式并提取因子。
Factor类是提取到的各个因子(没啥用,该直接用PolyNode的)。
Polynode类是总类,关系类(Addnode、Mulnode)和因子类(Constant、Pow、Tri)都继承自它。
- 首先因为输入仍然是合法的,所以将表达式字符串传入Parser后开始分析。
- 分析思路如下:
- 构造
getExpression(),getExpression1(),getTerm(),getTerm1(),getFactor方法,利用getNextFactor方法递归下降提取表达式、项、因子。其中xx()和xx1()的区别在于是否是首项。 - 每次提取一个因子,判断出因子的类型后传回上述方法并建立
PolyNode类型的节点,建立节点的同时建立表达式树。
- 构造
- 构建完表达式树后直接开始从根节点开始对表达式树进行求导,边求导边递归得到求导后的表达式。(此处需要重写
derivation和toString方法)
度量分析
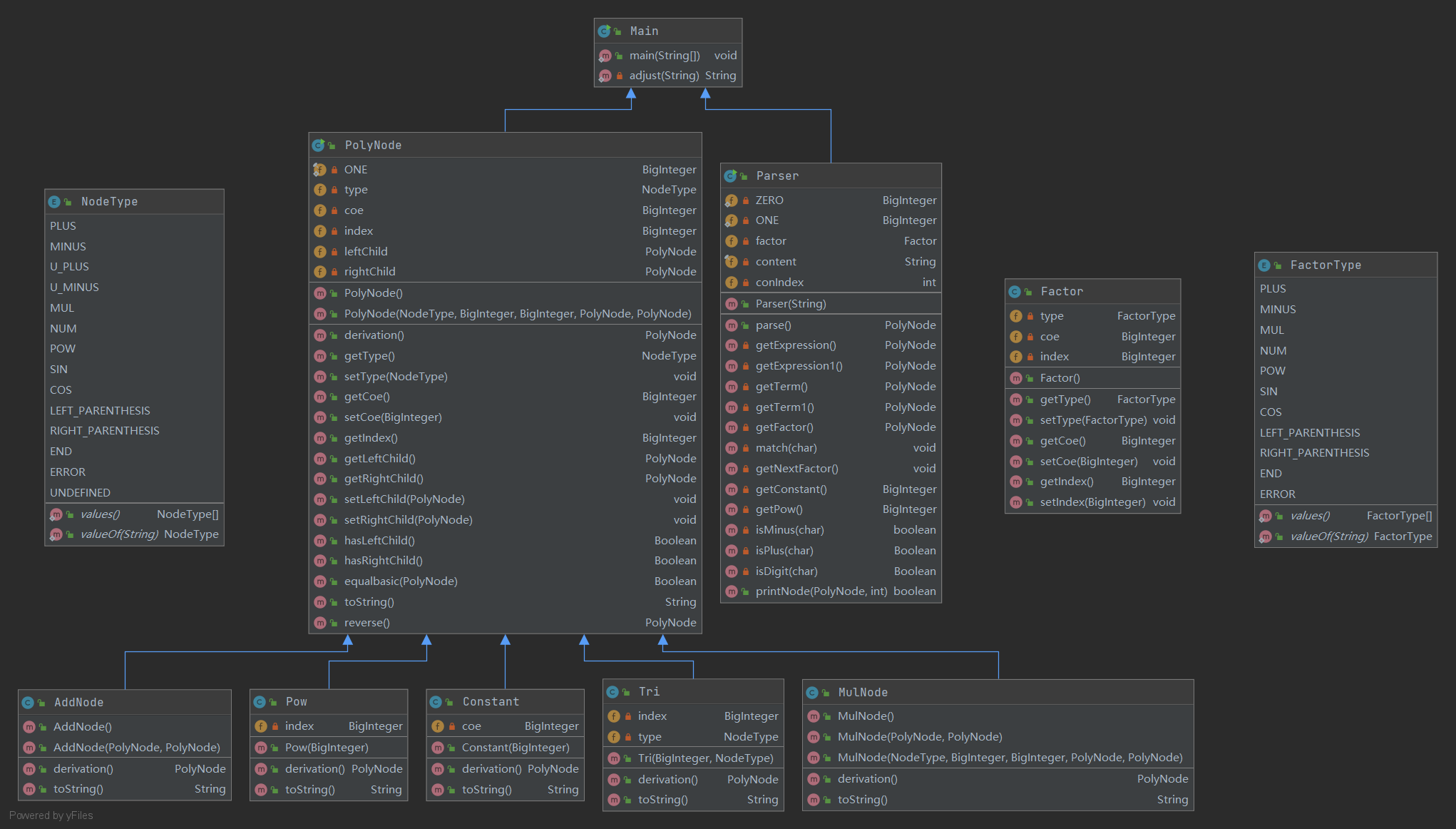
第二次作业UML图如下:Parser是分析器,关系类和因子类都继承自PolyNode,其中NodeType和Factor都是Enum类型,用于判断因子的类型(但写完了我发现为什么不直接用insanceof呢)
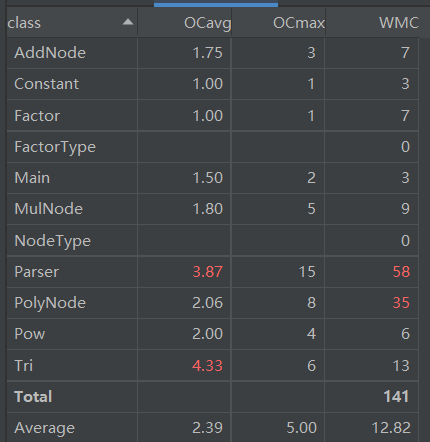
代码方法复杂度如下:可以看出Parser和Tri的复杂度都偏高,其实两者应该都可以简化,但我写完本次作业后时间已经所剩无几。。。
优化思路
- 简单优化(在toString上做文章)
x**0 => 1x**1 => xx**2 => x*xx*0 => 0x+0 => x- etc
- 进阶优化(需要对架构进行优化)
- 将正项放在首位
- 合并同类项
- 三角函数优化,如
sin(x)**2 + cos(x)**2 = 1 - 特殊情况下拆括号(括号内因子较少时)
bug分析
- 在本次作业的强测和互测中我被发现了两个bug
- 一是进行遇到
(A+(B+C))的类型时想要拆括号,但是愚蠢的我拆了外层括号。。。。 - 二是重复递归问题。先放代码(以加法关系
AddNode为例)。
- 一是进行遇到
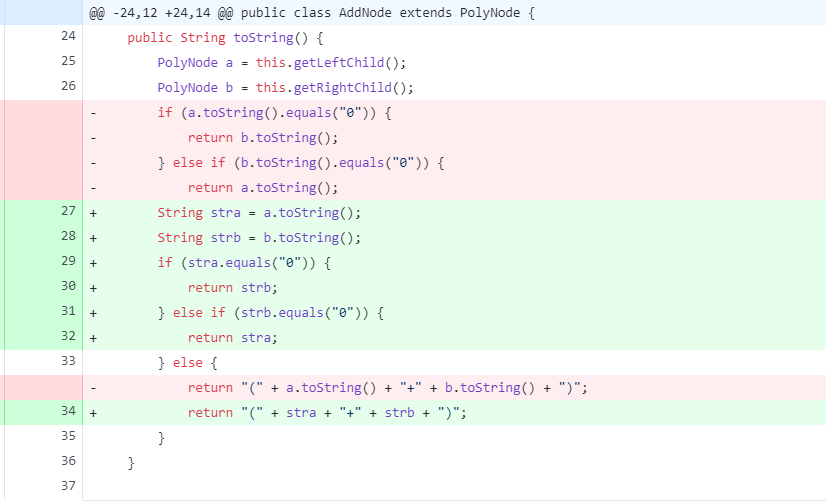
乍一看似乎只是用stra替换了a.toString(),但注意,在递归求导的过程中,a.toString()是再进入到下一个层次再次进行递归,所以可以看出,原代码的时间复杂度是修改后的2-6倍。而因为这段代码是递归调用的,所以这样直接导致了总代码的时间复杂度提高了指数级倍数。这样在跑哪怕是诸如x+x+x+x+x+x+x+x+x+x+x+x+x+x+x的数据也会崩掉。以后遇到类似问题一定要注意。
- 关于其他同学的bug。。。因为自己因为上述的两个bug强测分很低,直接用评测机hack了好多人。。。所以也没有专门总结他人的bug,但感觉大家或多或少都是因为优化错了导致bug,毕竟如果基础求导都错了是过不了中测的。
重构心得
(以下大概是一段非常悲惨的倒苦水的心得体会,各位看官看过笑笑就好www)
相较于去年的第二次作业要求输入格式合法性判断,今年的第二次作业加嵌套是直接是上了一个难度档次。由于第一次使用了正则表达式直接搜索的方法,在看到第二次作业就傻眼了。从周三晚上作业发布到周五,因为各种各样的原因,都没有思考出合适的重构方向。
此时我选择了找dl交流(真的只是交流思路啊(求生欲max))。在dl的一番指点下,我似乎有了醍醐灌顶的感觉,但是对具体的实现仍然很迷惑。于是我又跑去看了去年的学长学姐们写的(第三次作业)的博客,觉得似乎是有学一点递归下降的必要了。星期五琢磨各种博客大概琢磨出了点儿递归下降的味儿,一看时间已经2点就决定第二天再开始写。
然后第二天发现看明白和会写是真的两码事。花了一上午磕磕绊绊写出了整个分析流程,再花了一下午debug到似乎能用的层次。到了晚上,想想离ddl还有24小时吧,算写了一半bug还层出不穷实在很绝望。。。就花了两个小时去绝望。。。绝望完了想总还是得写吧,再厚着脸皮去找dl交流交流卡壳的部分,又哧溜着开始瞎写。。。再次清醒过来一看时间。。。又是凌晨两点了,狠下心设了个6:30的闹钟爬去睡觉。
到了第三天写到8:30决定去教室写,结果打开电脑发现刚刚在寝室一直改不掉的一个bug突然就没了(?),心情稍稍振奋一点继续改呀改写呀写,在ddl前几个小时总算是过了中测。把上面列的简单优化加了后实在不想看下去了就滚回寝室补觉了。
万幸,虽然强测惨烈无比,最后总还是过了中测。
总结一下,面对题目比预期难很多/需要重构的情况,大概有下面这些可以做的:
- (
厚着脸皮)找dl交流,或许能给你提供一个思考的方向 - 学长学姐们的博客
- 足够强大的心态
- 实在做不了就去睡一觉吧,5次不过中测才会挂科嘛。
资料分享
- https://blog.csdn.net/qq_21441793/article/details/79826308 简单讲解了递归下降的原理
- https://blog.csdn.net/lgh1700/article/details/78450116 结合C++源码的递归下降
- https://blog.csdn.net/ZiFung_Yip/article/details/84646991 java表达式树(也包含递归下降的思想)
- https://blog.csdn.net/Prime_min/article/details/104657347 某位学长的一部分思考+源码
第三次作业
作业简介
增加了三角因子的嵌套和表达式输入合法性判断。
实现思路
-
三角因子的嵌套和括号的嵌套区别不大,直接加就好。
-
关于输入合法性判断进行一个总结叭:
我是(
图简单)对空白字符、加减符号、括号都进行了特判。空白字符
因为空白字符只有几种情况不合法(见guidebook),其他都是合法的,因此直接对每个空白字符前后进行判断,如果是不合法的情况,则抛出异常。
String regex1 = "(?<before>[^\\s])(\\s)+(?<after>[^\\s])"; Pattern p = Pattern.compile(regex1); Matcher m = p.matcher(out); while (m.find()) { char a = m.group("before").charAt(0); char b = m.group("after").charAt(0); if (isDigit(a) && isDigit(b)) { throw new WrongFormatException(); } else if ((a == 's' && b == 'i') || (a == 'i' && b == 'n')) { throw new WrongFormatException(); } else if ((a == 'c' && b == 'o') || (a == 'o' && b == 's')) { throw new WrongFormatException(); } else if (isXin(a) && isXin(b)) { throw new WrongFormatException(); } out = out.substring(m.end() - 1); m = p.matcher(out); } out = content; String wrongstr1 = "[+-]\\s*[+-]\\s*[+-]\\s+\\d+"; String wrongstr2 = "\\*\\s*[+-]\\s+\\d+"; String wrongstr3 = "(sin|cos)\\s*\\(\\s*[+-]\\s+[0-9]+\\s*\\)"; String regex2 = "(" + wrongstr1 + ")|(" + wrongstr2 + ")|(" + wrongstr3 + ")"; p = Pattern.compile(regex2); m = p.matcher(out); if (m.find()) { throw new WrongFormatException(); }检查无误后直接替换掉空白字符即可。
加减号
首先三个加减号后只能是数字,再判断两个加减号后的情况。
String regex1 = "(?<before>.)[+-]{3,}(?<after>.)"; Pattern p = Pattern.compile(regex1); Matcher m = p.matcher(content); while (m.find()) { if (!isDigit(m.group("after").charAt(0))) { throw new WrongFormatException(); } } String regex2 = "\\*([+-]){2,}|(sin|cos)\\([+-]{2,}.*\\)"; p = Pattern.compile(regex2); m = p.matcher(content); if (m.find()) { throw new WrongFormatException(); }检查无误后也替换掉符号即可。
剩余的合法性判断
递归下降接着做。按照我的方法还需要判断前后两个因子之间的关系:
public void checkFactorType1() throws WrongFormatException { if (!(this.type.equals(FactorType.PLUS) || (this.type.equals(FactorType.MINUS)) || this.type.equals(FactorType.MUL) || this.type.equals(FactorType.END) || this.type.equals(FactorType.RIGHT_PARENTHESIS))) { throw new WrongFormatException(); } } //1对应因子类型 public void checkFactorType2() throws WrongFormatException { if (this.type.equals(FactorType.MUL)) { throw new WrongFormatException(); } } //2对应关系类型
度量分析
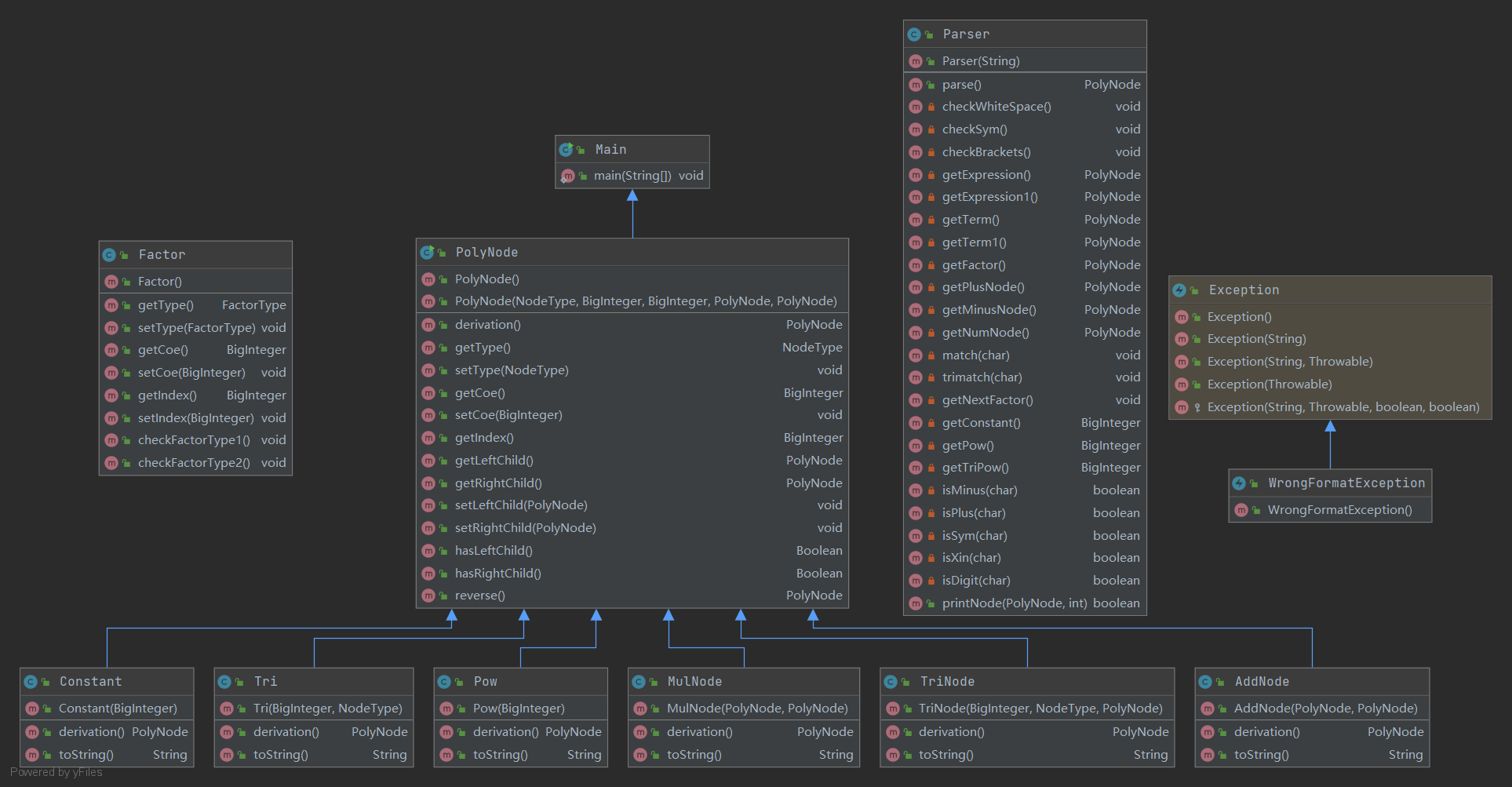
UML图如下:
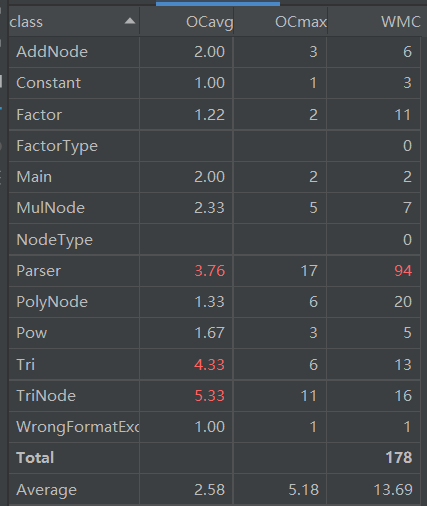
代码复杂度如下:总体似乎还OK。
优化思路
对这次作业PTSD了,没咋优化。
bug分析
佛系到甚至没有仔细研究别人的代码。
自己的bug就是上述格式判断中出现的一点问题。
心得体会
做OO 心态 一定 要好!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号