变量和对象
1.变量
在程序运行过程中,其值能被改变的量称为变量。在Java中,所有的变量必须声明才能使用,声明方式为:变量类型 变量名;例如:int age,声明了一个int类型的age变量。变量在使用前进行声明是为了告诉编译器这个变量的数据类型,这样编译器才能知道分配多大的内存空间给它,以及它能存放什么样的类型变量。
根据代码能访问该变量的区域将变量分为成员变量和局部变量。成员变量在整个类中都有效,类的成员变量又分为静态变量和实例变量。静态变量是被static修饰的变量,有效范围可以跨类,使用类名.静态变量名访问。局部变量是在方法体中定义的变量,只在当前代码块中有效,即局部变量的生命周期取决于当前方法的调用。结合JVM来看,成员变量存放在运行时数据区的方法区中,局部变量存放在Java虚拟机栈中。
2.对象和变量之间的关系
类是封装对象的属性和行为的载体,而对象的属性以成员变量的形式存在。对象的方法以成员方法的形式存在,在成员方法内定义的变量为局部变量。
3.对象的创建过程
在代码中,new操作符调用构造方法创建对象。那么虚拟机中对象是怎样创建的?
①虚拟机在遇到new指令时,首先检查该指令参数是否能在方法区的常量池中定位到一个符号,并且检查这个符号引用是否已经被类加载,解析和初试化过,若没有,应先进行相应的类加载过程。
- 加载是取得类的二进制流,并且将类信息转换为方法区的运行时数据结构,最后在堆中生成一个java.lang.Class对象,用作访问方法区中该类的信息的入口。
- 解析是将常量池内的符号引用转换为直接引用。
- 初始化阶段执行类中定义的Java代码程序,包括为变量赋值(不是赋默认值)。
②为新生对象分配内存
如何为对象确认内存大小?对象在堆内存中的存储区域包括三部分,对象头,实例数据以及对齐填充。对象头中主要包括两种信息,一种用于存储对象自身的运行时数据,比如哈希码,GC分代年龄,锁状态标志等。另一种存储类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针确定这个对象是哪个类的实例。实例数据是对象真正存储的有效信息,也就是程序代码中定义的各种类型的字段信息。对齐填充不是必须的。由于JVM系统要求对象的起始地址必须是8字节的整数倍,也就是说对象大小是8字节的倍数,由于对象头的大小刚好是8字节倍数,因此有的实例数据部分需要对齐填充来占位。
③将分配到的内存空间初始化为零值(对象头不包括)。
④对对象头进行必要的设置,例如这个对象是哪个类的实例,如何才能找到元数据信息,对象的哈希码,对象的GC分代年龄等信息。
自此,从虚拟机视角来看,一个新的对象就产生了。接下来,虚拟机在new指令之后执行<init>方法,将对象按照代码中的值进行初始化。
4.对象的访问定位
建立对象是为了使用,使用之前必须先要找到该对象,即对对象的访问定位。目前的主流方式有使用句柄和直接指针两种定位方式。
如果使用句柄访问的话,Java堆中会划分出一块内存区域作为句柄池,reference中存的就是对象的句柄地址,句柄地址中存储了到对象实例数据的地址信息以及到对象类型数据的地址信息,分别指向Java堆实例池中的对象实例数据和方法区中的对象类型数据。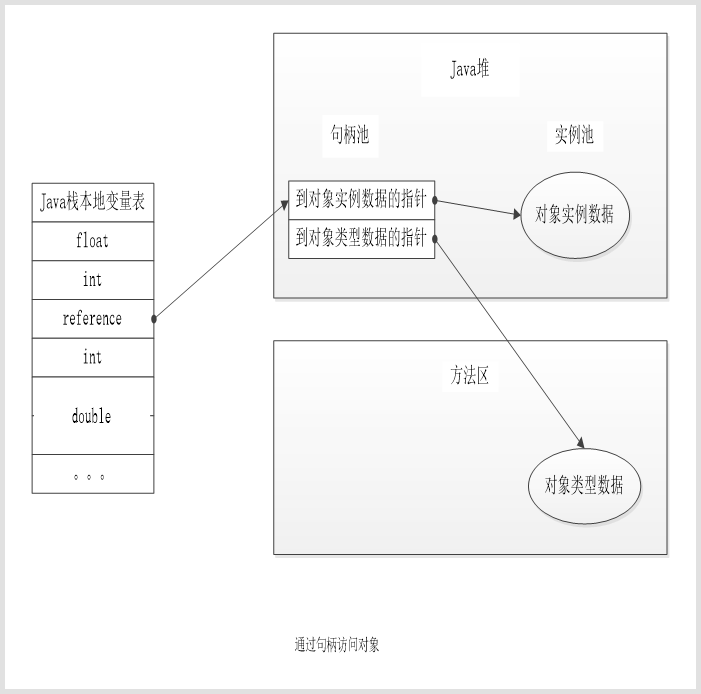
如果使用直接指针的定位方式,那么在Java堆对象的布局中必须考虑如何放置访问类型数据的相关信息,而reference中存储的直接就是对象地址。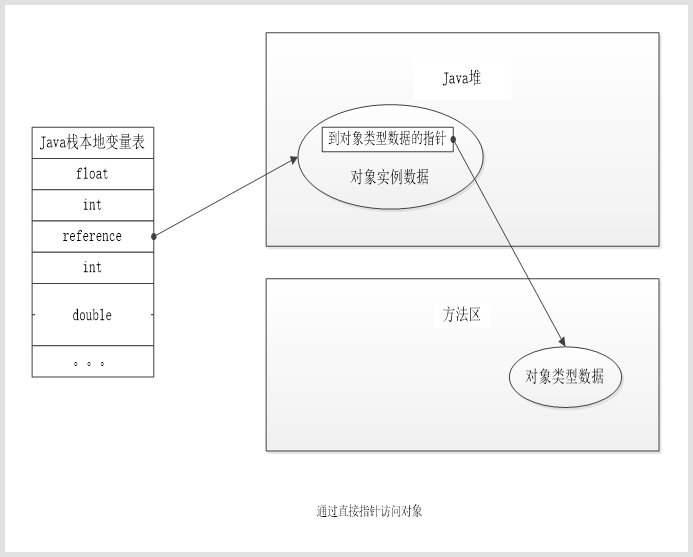
5.new对象放在循环内和循环外
5.1 先来看看对象的创建。如下的示例代码:
public class VariableTest {
int a;
static int b=12;
public VariableTest(){
System.out.println("构造方法执行:");
}
public static void main(String[] args){
//vt-->对象的引用,存储在Java栈的本地变量表中
// new VariableTest()-->对象,存储在堆中,每次new VariableTest() new出来的对象都不一样。
VariableTest vt=new VariableTest();
VariableTest vt1=new VariableTest();
System.out.println(vt); //com.java.Variable.VariableTest@15db9742
System.out.println(new VariableTest()); //@6d06d69c
System.out.println(new VariableTest()); //7852e922
System.out.println(new VariableTest()); //@4e25154f
System.out.println(vt1); //@70dea4e
}
}
在 VariableTest类中创建了构造方法public VariableTest(){},程序中使用new 构造方法就创建了对象。
VariableTest vt=new VariableTest(); vt为对象的引用,也就是对象的访问定位中提到的Java栈本地变量表中存储的reference引用,new VariableTest(); new指针调用构造方法创建一个对象,也就是图中Java堆中的实例数据对象,vt对象引用指向实例数据对象。
接着代码中又new出一个对象,VariableTest vt1=new VariableTest(); 打印出vt和vt1的值是不一样的,也就是说vt和vt1是Java栈本地变量表中存储的两个不同的reference引用,那么vt1 后面的new VariableTest(); 和vt 后面的new VariableTest();是否是同一个对象呢?打印出该对象,发现只要new VariableTest();就会创建一个对象,每次创建的对象都是不同的。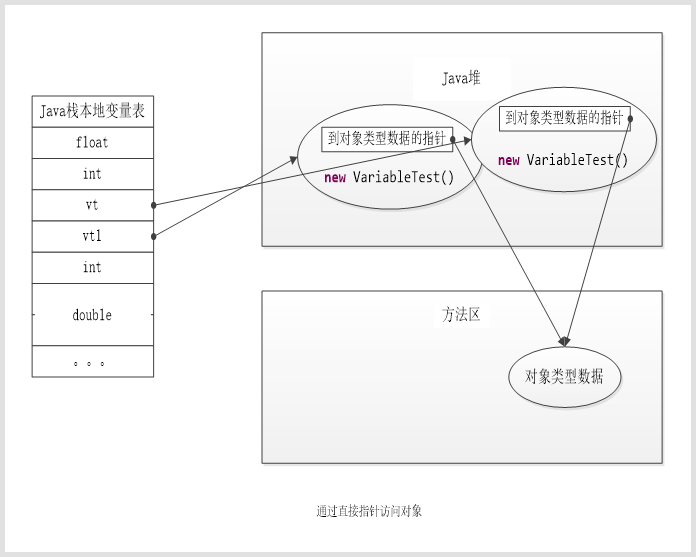
5.2 new对象在循环内和循环外
如下的示例代码:
public static void m1(){
HashMap<Integer,String> hashMap=null;
hashMap=new HashMap<Integer,String>();
for(int j=0;j<b;j++){
hashMap.put(j,"A");
}
for(Map.Entry<Integer,String> entry:hashMap.entrySet()){
System.out.println(entry.getKey()+":"+entry.getValue());
}
}
在VariableTest类中新建了一个成员方法m1(),在方法内创建了一个HashMap<Integer,String>类型的对象hashMap,for循环中存入数据然后遍历,整个过程只new出一个对象,所以for循环每次存数据都是向同一个hashMap中存入数据。遍历结果:
0:A 1:A 2:A 3:A 4:A 5:A 6:A 7:A 8:A 9:A 10:A 11:A
若改为入下的示例代码:
public static void m1(){
HashMap<Integer,String> hashMap=null;
for(int j=0;j<b;j++){
hashMap=new HashMap<Integer,String>();
hashMap.put(j,"A");
}
for(Map.Entry<Integer,String> entry:hashMap.entrySet()){
System.out.println(entry.getKey()+":"+entry.getValue());
}
}
将new HashMap<Integer,String>();放在循环内,之前分析每次new出来的对象都是不同的,所以在for循环的代码块中,一次循环结束,该次循环new出来的对象就已经销毁。也就是提前声明的hashMap引用每次指向的对象都是不同的,一次for循环结束new出来的对象销毁之后hashMap引用指向下一次for循环new出来的 HashMap<Integer,String>()对象。遍历结果:
11:A


 浙公网安备 33010602011771号
浙公网安备 33010602011771号