Java 面试题
Java基础
1. 什么是面向对象?
对比面向过程,是两种不同的处问题的角度,面向过程更注重事情的每一个步骤及顺序,面向对象更注重事情有哪些参与者(对象)、及各自需要做什么,面向过程比较直接高效,而面向对象更易于复用、扩展和维护。
-
封装
封装的意义,在于明确标识出允许外部使用的所有成员函数和数据项
内部细节对外部调用透明,外部调用无需修改或者关心内部实现
javabean的属性私有,提供getset对外访问,因为属性的赋值或者获取逻辑只能由javabean本身决 定。而不能由外部胡乱修改
private String name;
public void setName(String name){
this.name = "tuling_"+name;
}
该name有自己的命名规则,明显不能由外部直接赋值orm框架
操作数据库,我们不需要关心链接是如何建立的、sql是如何执行的,只需要引入mybatis,调方法即可
-
继承
继承基类的方法,并做出自己的改变和/或扩展
子类共性的方法或者属性直接使用父类的,而不需要自己再定义,只需扩展自己个性化的
继承,方法重写,父类引用指向子类对象
父类类型 变量名 = new 子类对象 ;
变量名.方法名();无法调用子类特有的功能
-
多态
基于对象所属类的不同,外部对同一个方法的调用,实际执行的逻辑不同。
2. 对象的四种引用
-
强引用
只要引用存在,垃圾回收器永远不会回收
Object obj = new Object();
User user=new User();可直接通过obj取得对应的对象 如 obj.equels(new Object()); 而这样 obj 对象对后面 new Object 的一个强 引用,只有当 obj 这个引用被释放之后,对象才会被释放掉,这也是我们经常所用到的编码形式。
-
软引用
非必须引用,内存溢出之前进行回收,可以通过以下代码实现
Object obj = new Object();
SoftReference<Object> sf = new SoftReference<Object>(obj);
obj = null;
sf.get();//有时候会返回null这时候sf是对obj的一个软引用,通过sf.get()方法可以取到这个对象,当然,当这个对象被标记为需要回收的对象 时,则返回null; 软引用主要用户实现类似缓存的功能,在内存足够的情况下直接通过软引用取值,无需从繁忙的 真实来源查询数据,提升速度;当内存不足时,自动删除这部分缓存数据,从真正的来源查询这些数据。
-
弱引用
第二次垃圾回收时回收,可以通过如下代码实现
Object obj = new Object();
WeakReference<Object> wf = new WeakReference<Object>(obj);
obj = null;
wf.get();//有时候会返回null
wf.isEnQueued();//返回是否被垃圾回收器标记为即将回收的垃圾弱引用是在第二次垃圾回收时回收,短时间内通过弱引用取对应的数据,可以取到,当执行过第二次垃圾回收时, 将返回null。弱引用主要用于监控对象是否已经被垃圾回收器标记为即将回收的垃圾,可以通过弱引用的 isEnQueued 方法返回对象是否被垃圾回收器标记。
ThreadLocal 中有使用到弱引用,
public class ThreadLocal<T> {
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
//....
}
//.....
} -
虚引用
垃圾回收时回收,无法通过引用取到对象值,可以通过如下代码实现
Object obj = new Object();
PhantomReference<Object> pf = new PhantomReference<Object>(obj);
obj=null;
pf.get();//永远返回null
pf.isEnQueued();//返回是否从内存中已经删除虚引用是每次垃圾回收的时候都会被回收,通过虚引用的get方法永远获取到的数据为null,因此也被成为幽灵引 用。虚引用主要用于检测对象是否已经从内存中删除。
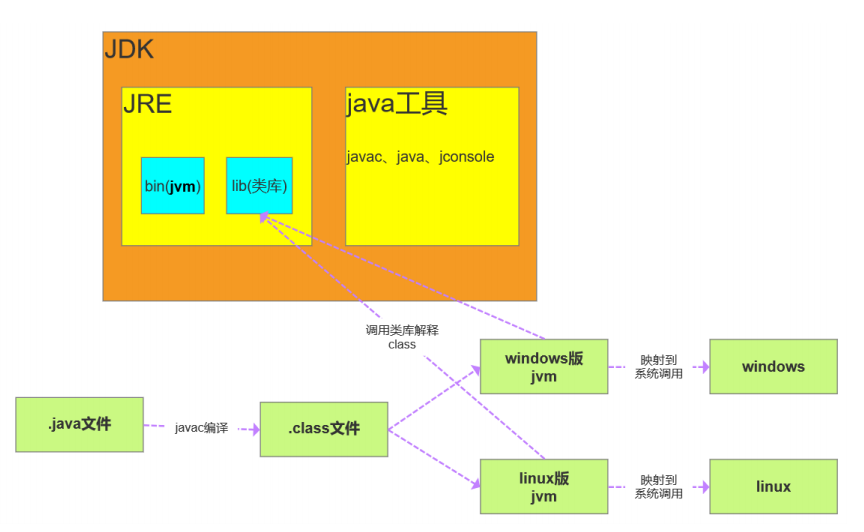
JDK JRE JVM
JDK:Java Develpment Kit java 开发工具
JRE:Java Runtime Environment java运行时环境
JVM:java Virtual Machine java 虚拟机
==和equals比较
==对比的是栈中的值,基本数据类型是变量值,引用类型是堆中内存对象的地址 equals:object中默认也是采用==比较,通常会重写 Object
public boolean equals(Object obj) {
return (this == obj);
}
String
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0 ;
while (n-- != 0 ) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
上述代码可以看出,String类中被复写的equals()方法其实是比较两个字符串的内容。
public class StringDemo {
public static void main(String args[]) {
String str1 = "Hello";
String str2 = new String("Hello");
String str3 = str2; // 引用传递
System.out.println(str1 == str2); // false
System.out.println(str1 == str3); // false
System.out.println(str2 == str3); // true
System.out.println(str1.equals(str2)); // true
System.out.println(str1.equals(str3)); // true
System.out.println(str2.equals(str3)); // true
}
}
hashCode与equals
hashCode介绍:
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是 确定该对象在哈希表中的索引位置。hashCode() 定义在JDK的Object.java中,Java中的任何类都包含有 hashCode() 函数。 散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用 到了散列码!(可以快速找到所需要的对象)
为什么要有hashCode:
以“HashSet如何检查重复”为例子来说明为什么要有hashCode:
对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,看该位置是否有 值,如果没有、HashSet会假设对象没有重复出现。但是如果发现有值,这时会调用equals()方法来 检查两个对象是否真的相同。如果两者相同,HashSet就不会让其加入操作成功。如果不同的话,就会 重新散列到其他位置。这样就大大减少了equals的次数,相应就大大提高了执行速度。
-
如果两个对象相等,则hashcode一定也是相同的
-
两个对象相等,对两个对象分别调用equals方法都返回true
-
两个对象有相同的hashcode值,它们也不一定是相等的
-
因此,equals方法被覆盖过,则hashCode方法也必须被覆盖
-
hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个 对象无论如何都不会相等(即使这两个对象指向相同的数据)
final
最终的
-
修饰类:表示类不可被继承
-
修饰方法:表示方法不可被子类覆盖,但是可以重载
-
修饰变量:表示变量一旦被赋值就不可以更改它的值。
A. 修饰成员变量
-
如果final修饰的是类变量,只能在静态初始化块中指定初始值或者声明该类变量时指定初始值。
-
如果final修饰的是成员变量,可以在非静态初始化块、声明该变量或者构造器中执行初始值。
B. 修饰局部变量
-
系统不会为局部变量进行初始化,局部变量必须由程序员显示初始化。因此使用final修饰局部变量时, 即可以在定义时指定默认值(后面的代码不能对变量再赋值),也可以不指定默认值,而在后面的代码 中对final变量赋初值(仅一次)
public class FinalVar {
final static int a = 0;//在声明的时候就需要赋值 或者静态代码块赋值
/**static{a = 0;}*/
final int b = 0;//在声明的时候就需要赋值 或者代码块中赋值 或者构造器赋值
/*{b = 0;}*/
public static void main(String[] args) {
final int localA; //局部变量只声明没有初始化,不会报错,与final无关。
localA = 0;//在使用之前一定要赋值 //localA = 1; 但是不允许第二次赋值
}
}
-
-
修饰基本类型数据和引用类型数据
-
如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;
-
如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。但是引用的值是可变 的。
public class FinalReferenceTest{
public static void main(){
final int[] iArr={1,2,3,4};
iArr[2]=-3;//合法
iArr=null;//非法,对iArr不能重新赋值
final Person p = new Person(25);
p.setAge(24);//合法
p=null;//非法
}
} -
为什么局部内部类和匿名内部类只能访问局部final变量?
-
编译之后会生成两个class文件,Test.class Test1.class
public class Test {
public static void main(String[] args) {
}
//局部final变量a,b
public void test(final int b) {
//jdk8在这里做了优化, 不用写,语法糖,但实际上也是有的,也不能修改
final int a = 10;
//匿名内部类
new Thread(){
public void run() {
System.out.println(a);
System.out.println(b);
};
}.start();
}
}
class OutClass {
private int age = 12;
public void outPrint(final int x) {
class InClass {
public void InPrint() {
System.out.println(x);
System.out.println(age);
}
}
new InClass().InPrint();
}
}
首先需要知道的一点是: 内部类和外部类是处于同一个级别的,内部类不会因为定义在方法中就会随着 方法的执行完毕就被销毁。
这里就会产生问题:当外部类的方法结束时,局部变量就会被销毁了,但是内部类对象可能还存在(只有 没有人再引用它时,才会死亡)。这里就出现了一个矛盾:内部类对象访问了一个不存在的变量。为了解 决这个问题,就将局部变量复制了一份作为内部类的成员变量,这样当局部变量死亡后,内部类仍可以 访问它,实际访问的是局部变量的"copy"。这样就好像延长了局部变量的生命周期
将局部变量复制为内部类的成员变量时,必须保证这两个变量是一样的,也就是如果我们在内部类中修 改了成员变量,方法中的局部变量也得跟着改变,怎么解决问题呢?
就将局部变量设置为final,对它初始化后,我就不让你再去修改这个变量,就保证了内部类的成员变量 和方法的局部变量的一致性。这实际上也是一种妥协。使得局部变量与内部类内建立的拷贝保持一致。
final finally finalize
-
final可以修饰类、变量、方法,修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表示该变量是一个常量不能被重新赋值。
-
finally一般作用在try-catch代码块中,在处理异常的时候,通常我们将一定要执行的代码放在finally代码块中,表示不管是否出现异常,该代码块都会执行,一般用来存放一些关闭资源的代码。
-
finalize是一个方法,属于Object类的一个方法,而Object类是所有类的父类,该方法一般由垃圾回收器来调用,当我们调用 System.gc() 方法的时候,由垃圾回收器调用finalize(),回收垃圾,一个对象是否可回收的最后判断。
LinkedHashMap 的应用
基于 LinkedHashMap 的访问顺序的特点,可构造一个 LRU(Least Recently Used) 最近最少使用简单缓存。 也有一些开源的缓存产品如 ehcache 的淘汰策略( LRU )就是在 LinkedHashMap 上扩展的。
重载和重写
重载: 发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同,发生在编译时。
重写: 发生在父子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为private则子类就不能重写该方法。
public int add(int a,String b)
public String add(int a,String b)//编译报错
接口和抽象类
-
抽象类可以存在普通成员函数,而接口中只能存在public abstract 方法。
-
抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的。
-
抽象类只能继承一个,接口可以实现多个。
接口的设计目的,是对类的行为进行约束(更准确的说是一种“有”约束,因为接口不能规定类不可以有 什么行为),也就是提供一种机制,可以强制要求不同的类具有相同的行为。它只约束了行为的有无, 但不对如何实现行为进行限制。
而抽象类的设计目的,是代码复用。当不同的类具有某些相同的行为(记为行为集合A),且其中一部分行为的实现方式一致时(A的非真子集,记为B),可以让这些类都派生于一个抽象类。在这个抽象类中实现了B,避免让所有的子类来实现B,这就达到了代码复用的目的。而A减B的部分,留给各个子类自己 实现。正是因为A-B在这里没有实现,所以抽象类不允许实例化出来(否则当调用到A-B时,无法执 行)。
抽象类是对类本质的抽象,表达的是 is a 的关系,比如: BMW is a Car 。抽象类包含并实现子类的通用特性,将子类存在差异化的特性进行抽象,交由子类去实现。
而接口是对行为的抽象,表达的是 like a 的关系。比如: Bird like a Aircraft (像飞行器一样可以 飞),但其本质上 is a Bird 。接口的核心是定义行为,即实现类可以做什么,至于实现类主体是谁、 是如何实现的,接口并不关心。
使用场景:当你关注一个事物的本质的时候,用抽象类;当你关注一个操作的时候,用接口。
抽象类的功能要远超过接口,但是,定义抽象类的代价高。因为高级语言来说(从实际设计上来说也 是)每个类只能继承一个类。在这个类中,你必须继承或编写出其所有子类的所有共性。虽然接口在功 能上会弱化许多,但是它只是针对一个动作的描述。而且你可以在一个类中同时实现多个接口。在设计 阶段会降低难度
List和Set的区别
-
List:有序,按对象进入的顺序保存对象,可重复,允许多个Null元素对象,可以使用Iterator取出 所有元素,在逐一遍历,还可以使用get(int index)获取指定下标的元素
-
Set:无序,不可重复,最多允许有一个Null元素对象,取元素时只能用Iterator接口取得所有元 素,在逐一遍历各个元素
List , Set 都是继承自 Collection 接口 List 特点:元素有放入顺序,元素可重复 , Set 特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉,(元素虽然无放入顺序,但是元素在set中的位 置是有该元素的 HashCode 决定的,其位置其实是固定的,加入Set 的 Object 必须定义 equals ()方法 ,另外list 支持for循环,也就是通过下标来遍历,也可以用迭代器,但是set只能用迭代,因为他无序,无法用下标来取得想 要的值。)
Set和List对比
Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变
String 和 StringBuilder、StringBuffer 的区别
Java 平台提供了两种类型的字符串:String 和StringBuffer/StringBuilder,它们可以储存和操作字符串。其中 String 是只 读字符串,也就意味着 String 引用的字符串内容是不能被改变的。而StringBuffer/StringBuilder 类表示的字符串对象可以直接进行修改。StringBuilder 是 Java 5 中引入的,它和 StringBuffer 的方法完全相同,区 别在于它是在单线程环境下使用的,因为它的所有方面都没有被 synchronized修饰,因此它的效率也比 StringBuffer 要高。
ArrayList和LinkedList区别
-
ArrayList:基于动态数组,连续内存存储,适合下标访问(随机访问),扩容机制:因为数组长度固定,超出长度存数据时需要新建数组,然后将老数组的数据拷贝到新数组,如果不是尾部插入数据还会 涉及到元素的移动(往后复制一份,插入新元素),使用尾插法并指定初始容量可以极大提升性能、甚 至超过linkedList(需要创建大量的node对象)
-
LinkedList:基于链表,可以存储在分散的内存中,适合做数据插入及删除操作,不适合查询:需要逐 一遍历
遍历LinkedList必须使用iterator不能使用for循环,因为每次for循环体内通过get(i)取得某一元素时都需 要对list重新进行遍历,性能消耗极大。 另外不要试图使用indexOf等返回元素索引,并利用其进行遍历,使用indexlOf对list进行了遍历,当结果为空时会遍历整个列表。
ArrayList、Vector、LinkedList 的存储性能和特性
ArrayList 和 Vector 都是使用数组方式存储数据,此数组元素数大于实际 存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入 元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢,Vector中的方法由于添加了 synchronized 修饰,因此 Vector 是线程安全的容器,但 性能上较 ArrayList 差,因此已经是 Java 中的遗留容器。
LinkedList 使用双 向链表实现存储(将内存中零散的内存单元通过附加的引用关联起来,形成一 个可以按序号索引的线性结构,这种链式存储方式与数组的连续存储方式相 比,内存的利用率更高),按序号索引数据需要进行前向或后向遍历,但是插 入数据时只需要记录本项的前后项即可,所以插入速度较快。
Vector 属于遗留 容器(Java 早期的版本中提供的容器,除此之外,Hashtable、Dictionary、BitSet、Stack、Properties 都是遗留容器),已经不推荐使用,但是由于ArrayList 和 LinkedListed 都是非线程安全的,如果遇到多个线程操作同一个容器的场景,则可以通过工具类 Collections 中的 synchronizedList 方法将其 转换成线程安全的容器后再使用(这是对装潢模式的应用,将已有对象传入另 一个类的构造器中创建新的对象来增强实现)。
HashMap,jdk7和jdk8版本的区别
HashMap结构图
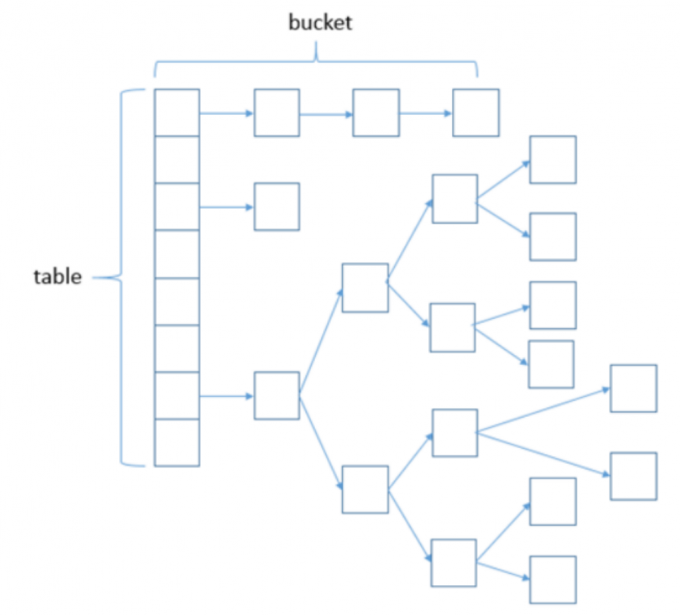
在 JDK1.7 及之前的版本中, HashMap 又叫散列链表:基于一个数组以及多个链表的实现,hash值冲突的时候, 就将对应节点以链表的形式存储。
其下基于 JDK1.7.0_80 与 JDK1.8.0_66 做的分析
JDK1.7中
使用一个 Entry 数组来存储数据,用key的 hashcode 取模来决定key会被放到数组里的位置,如果 hashcode 相 同,或者 hashcode 取模后的结果相同( hash collision ),那么这些 key 会被定位到 Entry 数组的同一个 格子里,这些 key 会形成一个链表。
在 hashcode 特别差的情况下,比方说所有key的 hashcode 都相同,这个链表可能会很长,那么 put/get 操作 都可能需要遍历这个链表,也就是说时间复杂度在最差情况下会退化到 O(n)
JDK1.8中
使用一个 Node 数组来存储数据,但这个 Node 可能是链表结构,也可能是红黑树结构
如果插入的 key 的 hashcode 相同,那么这些key也会被定位到 Node 数组的同一个格子里。
如果同一个格子里的key不超过8个,使用链表结构存储。
如果超过了8个,那么会调用 treeifyBin 函数,将链表转换为红黑树。
那么即使 hashcode 完全相同,由于红黑树的特点,查找某个特定元素,也只需要O(log n)的开销 ,也就是说put/get的操作的时间复杂度最差只有 O(log n) 听起来挺不错,但是真正想要利用 JDK1.8 的好处,有一个限制: key的对象,必须正确的实现了 Compare 接口 如果没有实现 Compare 接口,或者实现得不正确(比方说所有 Compare 方法都返回0) 那 JDK1.8 的 HashMap 其实还是慢于 JDK1.7 的
简单的测试数据如下:
向 HashMap 中 put/get 1w 条 hashcode 相同的对象
JDK1.7: put 0.26s , get 0.55s
JDK1.8 (未实现 Compare 接口): put 0.92s , get 2.1s
但是如果正确的实现了 Compare 接口,那么 JDK1.8 中的 HashMap 的性能有巨大提升,这次 put/get 100W条 hashcode 相同的对象
JDK1.8 (正确实现 Compare 接口,): put/get 大概开销都在320 ms 左右
jdk7
数据结构:ReentrantLock+Segment+HashEntry,一个Segment中包含一个HashEntry数组,每个 HashEntry又是一个链表结构
元素查询:二次hash,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部
锁:Segment分段锁 Segment继承了ReentrantLock,锁定操作的Segment,其他的Segment不受影 响,并发度为segment个数,可以通过构造函数指定,数组扩容不会影响其他的segment
get方法无需加锁,volatile保证
jdk8
数据结构:synchronized+CAS+Node+红黑树,Node的val和next都用volatile修饰,保证可见性
查找,替换,赋值操作都使用CAS
锁:锁链表的head节点,不影响其他元素的读写,锁粒度更细,效率更高,扩容时,阻塞所有的读写 操作、并发扩容
读操作无锁: Node的val和next使用volatile修饰,读写线程对该变量互相可见 数组用volatile修饰,保证扩容时被读线程感知
HashMap和HashTable
区别 :
-
HashMap方法没有synchronized修饰,线程非安全,HashTable线程安全;
-
HashMap允许key和value为null,而HashTable不允许
底层实现:数组+链表实现
jdk8开始链表高度到8、数组长度超过64,链表转变为红黑树,元素以内部类Node节点存在
计算key的hash值,二次hash然后对数组长度取模,对应到数组下标, 如果没有产生hash冲突(下标位置没有元素),则直接创建Node存入数组, 如果产生hash冲突,先进行equal比较,相同则取代该元素,不同,则判断链表高度插入链表,链表高度达到8,并且数组长度到64则转变为红黑树,长度低于6则将红黑树转回链表,key为null,存在下标0的位置
HashSet是如何保证不重复的
向 HashSet 中 add ()元素时,判断元素是否存在的依据,不仅要比较hash值,同时还要结合 equles 方法比较。
HashSet 中的 add ()方法会使用 HashMap 的 add ()方法。以下是 HashSet 部分源码:
private static final Object PRESENT = new Object();
private transient HashMap<E,Object> map;
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
}
HashMap 的 key 是唯一的,由上面的代码可以看出 HashSet 添加进去的值就是作为 HashMap 的key。所以不会 重复( HashMap 比较key是否相等是先比较 hashcode 在比较 equals )。
HashMap是否线程安全
不是线程安全的;
如果有两个线程A和B,都进行插入数据,刚好这两条不同的数据经过哈希计算后得到的哈希码是一样的,且该位 置还没有其他的数据。所以这两个线程都会进入我在上面标记为1的代码中。假设一种情况,线程A通过if判断,该 位置没有哈希冲突,进入了if语句,还没有进行数据插入,这时候 CPU 就把资源让给了线程B,线程A停在了if语句 里面,线程B判断该位置没有哈希冲突(线程A的数据还没插入),也进入了if语句,线程B执行完后,轮到线程A执 行,现在线程A直接在该位置插入而不用再判断。这时候,你会发现线程A把线程B插入的数据给覆盖了。发生了线 程不安全情况。本来在 HashMap 中,发生哈希冲突是可以用链表法或者红黑树来解决的,但是在多线程中,可能 就直接给覆盖了。
上面所说的是一个图来解释可能更加直观。如下面所示,两个线程在同一个位置添加数据,后面添加的数据就覆盖住了前面添加的。
如果上述插入是插入到链表上,如两个线程都在遍历到最后一个节点,都要在最后添加一个数据,那么后面添加数据的线程就会把前面添加的数据给覆盖住。则
在扩容的时候也可能会导致数据不一致,因为扩容是从一个数组拷贝到另外一个数组。
HashMap的扩容过程
当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值(yu)---即当前数组的长度乘以加载因子的值的时候,就要自动扩容啦。
扩容( resize )就是重新计算容量,向 HashMap 对象里不停的添加元素,而 HashMap 对象内部的数组无法装载更 多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然 Java 里的数组是无法自动扩容的,方法 是使用一个新的数组代替已有的容量小的数组。
HashMap hashMap=new HashMap(cap);
-
cap =3, hashMap 的容量为4;
-
cap =4, hashMap 的容量为4;
-
cap=5, 的容量为8;
-
cap =9, hashMap 的容量为16;
-
如果 cap 是2的n次方,则容量为 cap ,否则为大于 cap 的第一个2的n次方的数。
Arrays.sort 和 Collections.sort
Collection和Collections区别
java.util.Collection 是一个集合接口。它提供了对集合对象进行基本操作的通用接口方法。 java.util.Collections 是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、 线程安全等操作。 然后还有混排(Shuffling)、反转(Reverse)、替换所有的元素(fill)、拷贝(copy)、返 回Collections中最小元素(min)、返回Collections中最大元素(max)、返回指定源列表中最后一次出现指定目 标列表的起始位置( lastIndexOfSubList )、返回指定源列表中第一次出现指定目标列表的起始位置 ( IndexOfSubList )、根据指定的距离循环移动指定列表中的元素(Rotate)
事实上Collections.sort方法底层就是调用的array.sort方法,
public static void sort(Object[] a) {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a);
else
ComparableTimSort.sort(a, 0, a.length, null, 0, 0);
}
//void java.util.ComparableTimSort.sort()
static void sort(Object[] a, int lo, int hi, Object[] work, int workBase, int workLen)
{
assert a != null && lo >= 0 && lo <= hi && hi <= a.length;
int nRemaining = hi - lo;
if (nRemaining < 2)
return; // Arrays of size 0 and 1 are always sorted
// If array is small, do a "mini-TimSort" with no merges
if (nRemaining < MIN_MERGE) {
int initRunLen = countRunAndMakeAscending(a, lo, hi);
binarySort(a, lo, hi, lo + initRunLen);
return;
}
}
legacyMergeSort (a):归并排序 ComparableTimSort.sort() : Timsort 排序
Timsort 排序是结合了合并排序(merge sort)和插入排序(insertion sort)而得出的排序算法。
Timsort的核心过程:
TimSort 算法为了减少对升序部分的回溯和对降序部分的性能倒退,将输入按其升序和降序特点进行了分 区。排序的输入的单位不是一个个单独的数字,而是一个个的块-分区。其中每一个分区叫一个run。针对这 些 run 序列,每次拿一个 run 出来按规则进行合并。每次合并会将两个 run合并成一个 run。合并的结果保 存到栈中。合并直到消耗掉所有的 run,这时将栈上剩余的 run合并到只剩一个 run 为止。这时这个仅剩的run 便是排好序的结果。
综上述过程,Timsort算法的过程包括:
-
如何数组长度小于某个值,直接用二分插入排序算法。
-
找到各个run,并入栈。
-
按规则合并run。
Cloneable接口实现原理
Cloneable接口是Java开发中常用的一个接口, 它的作用是使一个类的实例能够将自身拷贝到另一个新的实例中, 注意,这里所说的“拷贝”拷的是对象实例,而不是类的定义,进一步说,拷贝的是一个类的实例中各字段的值。
在开发过程中,拷贝实例是常见的一种操作,如果一个类中的字段较多,而我们又采用在客户端中逐字段复制的方 法进行拷贝操作的话,将不可避免的造成客户端代码繁杂冗长,而且也无法对类中的私有成员进行复制,而如果让需要 具备拷贝功能的类实现Cloneable接口,并重写clone()方法,就可以通过调用clone()方法的方式简洁地实现实例 拷贝功
深拷贝(深复制)和浅拷贝(浅复制)是两个比较通用的概念,尤其在C++语言中,若不弄懂,则会在delete的时候出问 题,但是我们在这幸好用的是Java。虽然Java自动管理对象的回收,但对于深拷贝(深复制)和浅拷贝(浅复制),我们 还是要给予足够的重视,因为有时这两个概念往往会给我们带来不小的困惑。
浅拷贝是指拷贝对象时仅仅拷贝对象本身(包括对象中的基本变量),而不拷贝对象包含的引用指向的对象。深拷 贝不仅拷贝对象本身,而且拷贝对象包含的引用指向的所有对象。举例来说更加清楚:对象 A1 中包含对 B1 的引 用, B1 中包含对 C1 的引用。浅拷贝 A1 得到 A2 , A2 中依然包含对 B1 的引用, B1 中依然包含对 C1 的引 用。深拷贝则是对浅拷贝的递归,深拷贝 A1 得到 A2 , A2 中包含对 B2 ( B1 的 copy )的引用, B2 中包含 对 C2 ( C1 的 copy )的引用。
若不对clone()方法进行改写,则调用此方法得到的对象即为浅拷贝 。
异常分类以及处理机制
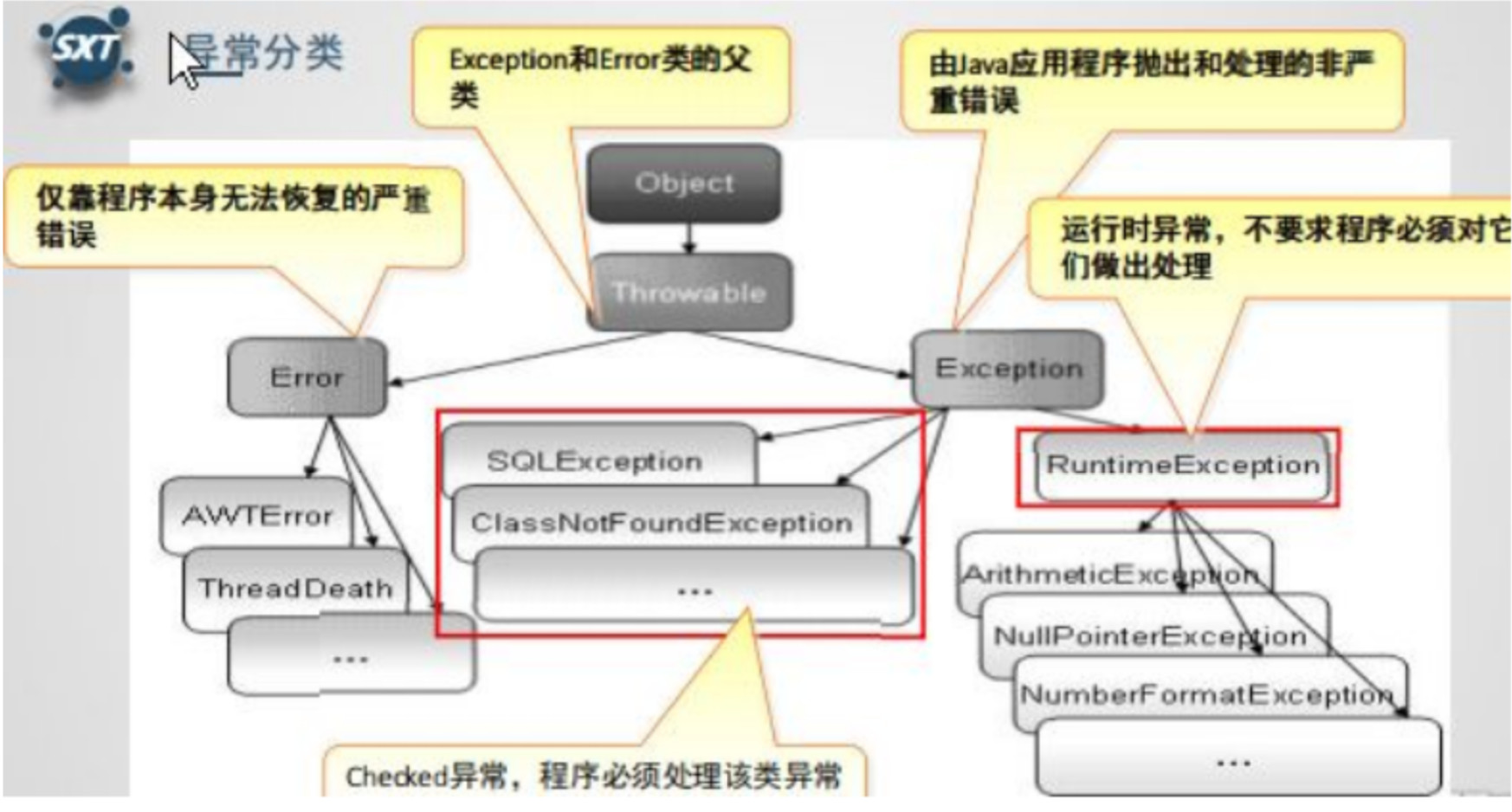
Java标准库内建了一些通用的异常,这些类以Throwable为顶层父类。Throwable又派生出Error类和Exception类。
错误:Error类以及他的子类的实例,代表了JVM本身的错误。错误不能被程序员通过代码处理,Error很少出现。因此,程序员应该关注Exception为父类的分支下的各种异常类。
异常:Exception以及他的子类,代表程序运行时发送的各种不期望发生的事件。可以被Java异常处理机制使用, 是异常处理的核心。
总体上我们根据 Javac 对异常的处理要求,将异常类分为二类。
非检查异常( unckecked exception )
Error 和 RuntimeException 以及他们的子类。 javac 在编译时, 不会提示和发现这样的异常,不要求在程序处理这些异常。所以如果愿意,我们可以编写代码处理(使用 try… catch…finally )这样的异常,也可以不处理。对于这些异常,我们应该修正代码,而不是去通过异常处理器处 理 。这样的异常发生的原因多半是代码写的有问题。如除0错误 ArithmeticException ,错误的强制类型转换错 误 ClassCastException ,数组索引越界 ArrayIndexOutOfBoundsException ,使用了空对象 NullPointerException 等等。
检查异常( checked exception )
除了 Error 和 RuntimeException 的其它异常。 javac 强制要求程序员 为这样的异常做预备处理工作(使用 try…catch…finally 或者 throws )。在方法中要么用 try-catch 语句捕 获它并处理,要么用throws子句声明抛出它,否则编译不会通过。这样的异常一般是由程序的运行环境导致的。因 为程序可能被运行在各种未知的环境下,而程序员无法干预用户如何使用他编写的程序,于是程序员就应该为这样 的异常时刻准备着。如 SQLException , IOException , ClassNotFoundException 等。
需要明确的是:检查和非检查是对于 javac 来说的,这样就很好理解和区分了。
数组在内存中的分配
对于 Java 数组的初始化,有以下两种方式,这也是面试中经常考到的经典题目。
静态初始化:初始化时由程序员显式指定每个数组元素的初始值,由系统决定数组长度,如:
//只是指定初始值,并没有指定数组的长度,但是系统为自动决定该数组的长度为4
String[] computers = {"Dell", "Lenovo", "Apple", "Acer"}; //1
//只是指定初始值,并没有指定数组的长度,但是系统为自动决定该数组的长度为3
String[] names = new String[]{"多啦A梦", "大雄", "静香"}; //2
动态初始化:初始化时由程序员显示的指定数组的长度,由系统为数据每个元素分配初始值,如:
//只是指定了数组的长度,并没有显示的为数组指定初始值,但是系统会默认给数组数组元素分配初始值为null
String[] cars = new String[4]; //3
因为 Java 数组变量是引用类型的变量,所以上述几行初始化语句执行后,三个数组在内存中的分配情况如下图所 示:
由上图可知,静态初始化方式,程序员虽然没有指定数组长度,但是系统已经自动帮我们给分配了,而动态初始化 方式,程序员虽然没有显示的指定初始化值,但是因为 Java 数组是引用类型的变量,所以系统也为每个元素分配 了初始化值 null ,当然不同类型的初始化值也是不一样的,假设是基本类型int类型,那么为系统分配的初始化值 也是对应的默认值0。
Java反射机制
Java 反射机制是在运行状态中,对于任意一个类,都能够获得这个类的所有属性和方法,对于任意一个对象都能够 调用它的任意一个属性和方法。这种在运行时动态的获取信息以及动态调用对象的方法的功能称为 Java 的反射机 制。
Class 类与 java.lang.reflect 类库一起对反射的概念进行了支持,该类库包含了 Field,Method,Constructor 类 (每 个类都实现了 Member 接口)。这些类型的对象时由 JVM 在运行时创建的,用以表示未知类里对应的成员。
这样你就可以使用 Constructor 创建新的对象,用 get() 和 set() 方法读取和修改与 Field 对象关联的字段,用 invoke() 方法调用与 Method 对象关联的方法。另外,还可以调用 getFields() getMethods() 和 getConstructors() 等很便利的方法,以返回表示字段,方法,以及构造器的对象的数组。这样匿名对象的信息 就能在运行时被完全确定下来,而在编译时不需要知道任何事情。
import java.lang.reflect.Constructor;
public class ReflectTest {
public static void main(String[] args) throws Exception {
Class clazz = null;
clazz = Class.forName("com.jas.reflect.Fruit");
Constructor<Fruit> constructor1 = clazz.getConstructor();
Constructor<Fruit> constructor2 = clazz.getConstructor(String.class);
Fruit fruit1 = constructor1.newInstance();
Fruit fruit2 = constructor2.newInstance("Apple");
}
}
class Fruit{
public Fruit(){
System.out.println("无参构造器 Run...........");
}
public Fruit(String type){
System.out.println("有参构造器 Run..........." + type);
}
}
运行结果: 无参构造器 Run........... 有参构造器 Run...........Apple
Java获取反射的三种方法
-
通过new对象实现反射机制。
-
通过路径实现反射机制。
-
通过类名实现反射机制。
public class Student {
private int id;
String name;
protected boolean sex;
public float score;
}
public class Get {
//获取反射机制三种方式
public static void main(String[] args) throws ClassNotFoundException {
//方式一(通过建立对象)
Student stu = new Student();
Class classobj1 = stu.getClass();
System.out.println(classobj1.getName());
//方式二(所在通过路径-相对路径)
Class classobj2 = Class.forName("fanshe.Student");
System.out.println(classobj2.getName());
//方式三(通过类名) Class classobj3 = Student.class;
System.out.println(classobj3.getName());
}
}
字节码定义以及采用的好处
java中的编译器和解释器
Java中引入了虚拟机的概念,即在机器和编译程序之间加入了一层抽象的虚拟的机器。这台虚拟的机器 在任何平台上都提供给编译程序一个的共同的接口。
编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后由解释器来将虚拟机代码转换为特定系统的机器码执行。在Java中,这种供虚拟机理解的代码叫做 字节码(即扩展名为 .class的文件),它不面向任何特定的处理器,只面向虚拟机。
每一种平台的解释器是不同的,但是实现的虚拟机是相同的。Java源程序经过编译器编译后变成字节码,字节码由虚拟机解释执行,虚拟机将每一条要执行的字节码送给解释器,解释器将其翻译成特定机器上的机器码,然后在特定的机器上运行。这也就是解释了Java的编译与解释并存的特点。
Java源代码---->编译器---->jvm可执行的Java字节码(即虚拟指令)---->jvm---->jvm中解释器----->机器可执行的二进制机器码---->程序运行。
采用字节码的好处
Java语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解 释型语言可移植的特点。所以Java程序运行时比较高效,而且,由于字节码并不专对一种特定的机器, 因此,Java程序无须重新编译便可在多种不同的计算机上运行。
二叉树/B树/B+树/红黑树
红黑树 R-B Tree :自平衡二叉树
在每个节点增加了一个存储位记录节点 的颜色,可以是 RED,也可以是 BLACK,
通过任意一条从根到叶子简单路径上颜色的约束,红黑树保证最长路径不超过最短路径的两倍,加以平衡。
在二叉查找树基础上,添加以下性质:
节点是红色或黑色
根节点是黑色
每个为空的叶子节点是黑色的
每个红色节点的两个子节点都是黑色
从任一节点到其每个叶子节点的所有路径都包含相同数目的黑色节点
时间复杂度为O(logn)

B-tree (B树):多路搜索树
文件系统和数据库的索引都是存在硬盘上的,并且如果数据量大的话,不一定能一次性加载到内存中。
如果在内存中,红黑树比B树效率更高,但是涉及到磁盘操作,B树就更优了。
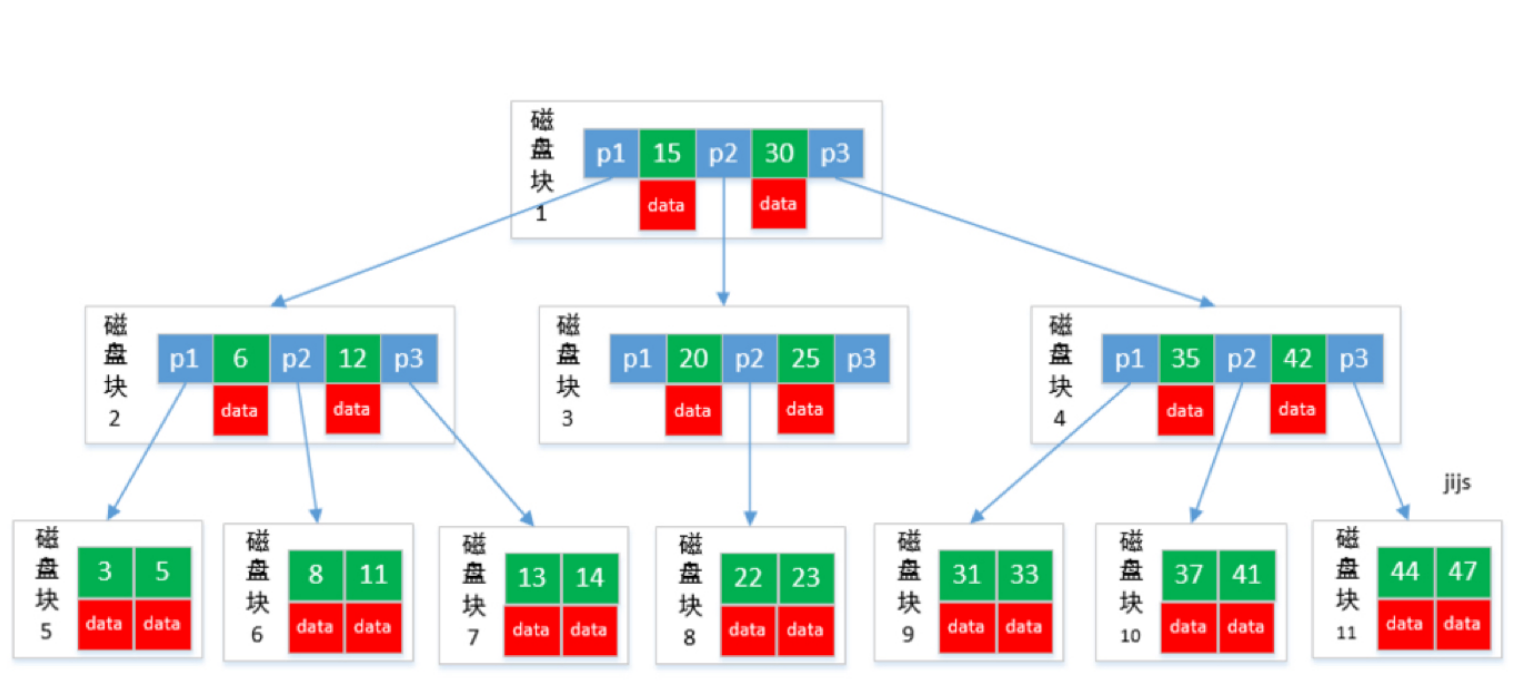
B-tree 利⽤了磁盘块的特性进⾏构建的树。每个磁盘块⼀个节点,每个节点包含了很多关键字。把树的节点关键字增多后树的层级⽐原来的⼆叉树少了,减少数据查找的次数和复杂度。
B-tree巧妙利⽤了磁盘预读原理,将⼀个节点的⼤⼩设为等于⼀个⻚(每⻚为4K),这样每个节点只需要⼀次I/O就可以完全载 ⼊。
B-tree 的数据可以存在任何节点中。
B+tree
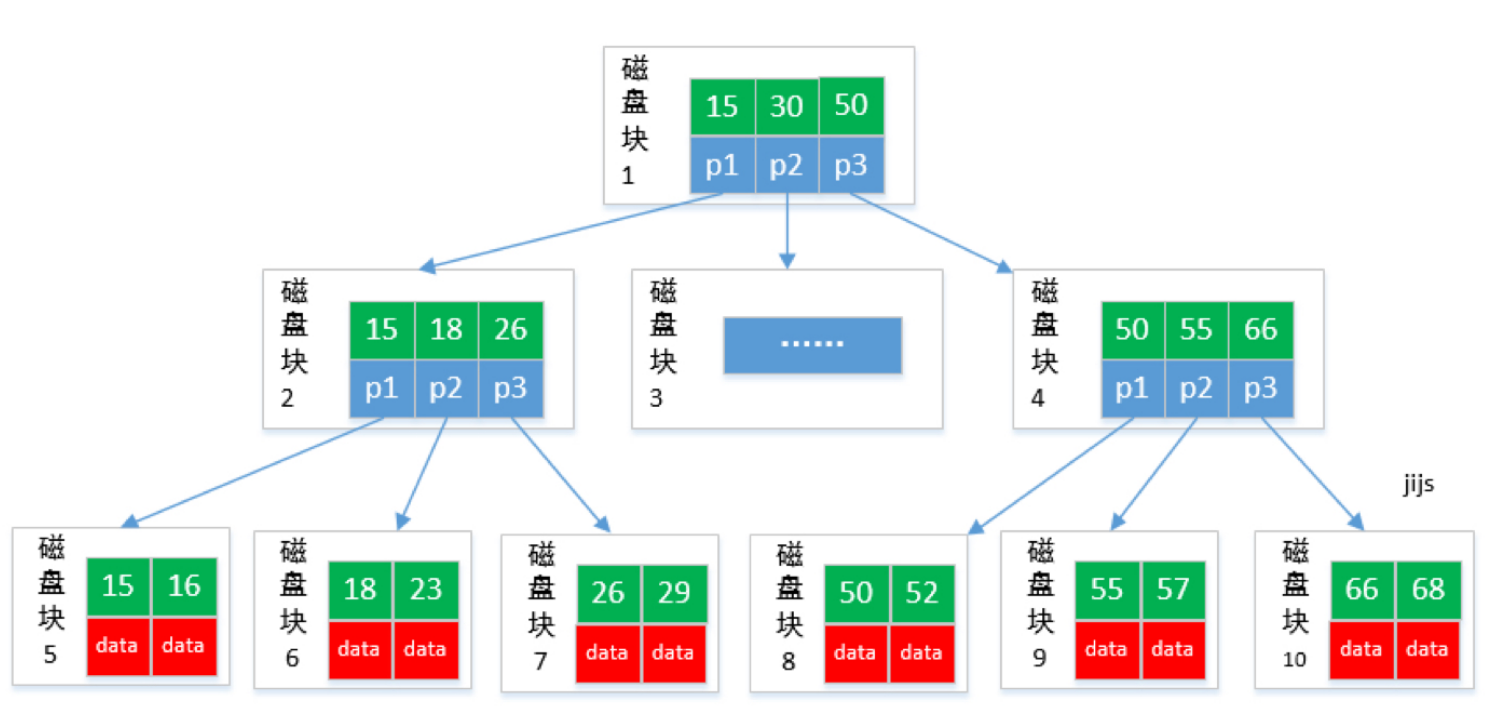

B+tree 是 B-tree 的变种,B+tree 数据只存储在叶⼦节点中。这样在B树的基础上每个节点存储的关键字数更多,树的层级更少 所以查询数据更快,所有指关键字指针都存在叶⼦节点,所以每次查找的次数都相同所以查询速度更稳定;
详见:https://www.cnblogs.com/rainwang/p/12243954.html(漫画形式)
https://blog.csdn.net/qq_34694342/article/details/84255739
https://www.sohu.com/a/154640931_478315(漫画形式)
日志级别知道有哪些吗?
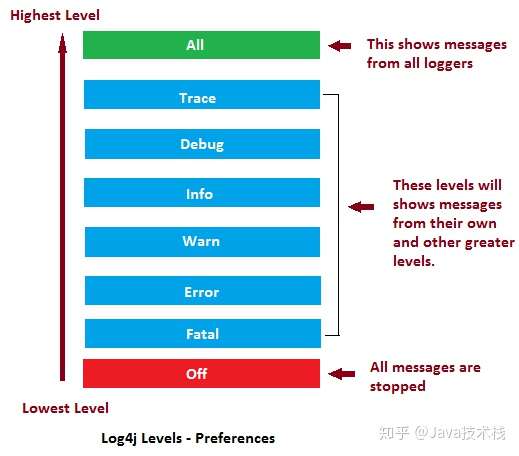
日志级别 | 描述 ---|---
OFF | 关闭:最高级别,不打印日志。
FATAL | 致命:指明非常严重的可能会导致应用终止执行错误事件。
ERROR | 错误:指明错误事件,但应用可能还能继续运行。
WARN | 警告:指明可能潜在的危险状况。
INFO | 信息:指明描述信息,从粗粒度上描述了应用运行过程。
DEBUG | 调试:指明细致的事件信息,对调试应用最有用。
TRACE | 跟踪:指明程序运行轨迹,比DEBUG级别的粒度更细。
ALL | 所有:所有日志级别,包括定制级别
ALL < TRACE < DEBUG < INFO < WARN < ERROR < FATAL < OFF
JVM相关
JVM内存模型

方法区:
-
有时候也成为永久代,在该区内很少发生垃圾回收,但是并不代表不发生 GC,在这里进行的 GC 主要是对方法区里的常量池和对类型的卸载。
-
方法区主要用来存储已被虚拟机加载的类的信息、常量、静态变量和即时编译器编译后的代码等数据。
-
该区域是被线程共享的。
-
方法区里有一个运行时常量池,用于存放静态编译产生的字面量和符号引用。该常量池具有动态性,也就是说常量并不一定是编译时确定,运行时生成的常量也会存在这个常量池中。
虚拟机栈:
-
虚拟机栈也就是我们平常所称的栈内存,它为 java 方法服务,每个方法在执行的时候都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接和方法出口等信息。
-
虚拟机栈是线程私有的,它的生命周期与线程相同。
-
局部变量表里存储的是基本数据类型、returnAddress 类型(指向一条字节码指令的地址)和对象引用,这个对象引用有可能是指向对象起始地址的一个指针,也有可能是代表 对象的句柄或者与对象相关联的位置。局部变量所需的内存空间在编译期间确定。
局部变量表,定义为一个数组:https://www.cnblogs.com/wangflower/p/12501804.html
-
操作数栈的作用主要用来存储运算结果以及运算的操作数,它不同于局部变量表通过索引来访问,而是压栈和出栈的方式。
-
每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了 支持方法调用过程中的动态连接.动态链接就是将常量池中的符号引用在运行期转化为直接引用。
本地方法栈:
本地方法栈和虚拟机栈类似,只不过本地方法栈为 Native 方法服务。
堆:
java 堆是所有线程所共享的一块内存,在虚拟机启动时创建,几乎所有的对象实例都在这里创建,因此该区域经常发生垃圾回收操作。
程序计数器:
内存空间小,字节码解释器工作时通过改变这个计数值可以选取下一条需要执行的字节码 指令,分支、循环、跳转、异常处理和线程恢复等功能都需要依赖这个计数器完成。该内 存区域是唯一一个 java 虚拟机规范没有规定任何 OOM 情况的区域。
Minor GC 和Major GC、Full GC
由于对象进行了分代处理,因此垃圾回收区域、时间也不一样。GC有两种类型:Scavenge GC和Full GC。对于一个拥有终结方法的对象,在垃圾收集器释放对象前必须执行终结方法。但是当垃圾收集器第二次收集这个对象时便不会再次调用终结方法。
Minor Gc
一般情况下,当新对象生成,并且在Eden申请空间失败时,就会触发Minor GC,对Eden区域进行GC,清除非存活对象,并且把尚且存活的对象移动到Survivor区,然后整理Survivor的两个区。这种方式的GC是对新生代的Eden区进行,不会影响到老年代。因为大部分对象都是从Eden区开始的,同时Eden区不会分配的很大,所以Eden区的GC会频繁进行。
Full Gc/Major GC
发生在老年代,一般情况下,触发老年代 GC的时候不会触发 Minor GC,但是通过配置,可以在 Full GC 之前进行一次 Minor GC 这样可以加快老年代的回收速度。
对整个堆进行整理,包括Young、Tenured和Perm。Full GC因为需要对整个对进行回收,所以比Minor GC要慢,因此应该尽可能减少Full GC的次数。在对JVM调优的过程中,很大一部分工作就是对于FullGC的调节。有如下原因可能导致Full GC:
-
老年代(Tenured)被写满
-
持久代(Perm)被写满
-
System.gc()被显示调用
堆里面的分区:Eden,survival (from+ to),老年代
答:堆里面分为新生代和老生代(java8 取消了永久代,采用了 Metaspace),新生代包含 Eden+Survivor 区,survivor 区里面分为 from 和 to 区,内存回收时,如果用的是复制算法,从 from 复制到 to,当经过一次或者多次 GC 之后,存活下来的对象会被移动到老年区,当 JVM 内存不够用的时候,会触发 Full GC,清理 JVM 老年区当新生区满了之后会触发 YGC,先把存活的对象放到其中一个 Survice区,然后进行垃圾清理。因为如果仅仅清理需要删除的对象,这样会导致内存碎片,因此一般会把 Eden 进行完全的清理,然后整理内存。那么下次 GC 的时候,就会使用下一个 Survive,这样循环使用。如果有特别大的对象,新生代放不下,就会使用老年代的担保,直接放到老年代里面。因为 JVM 认为,一般大对象的存活时间一般比较久远。
1.Eden区
Eden区位于Java堆的年轻代,是新对象分配内存的地方,由于堆是所有线程共享的,因此在堆上分配内存需要加锁。而Sun JDK为提升效率,会为每个新建的线程在Eden上分配一块独立的空间由该线程独享,这块空间称为TLAB(Thread Local Allocation Buffer)。在TLAB上分配内存不需要加锁,因此JVM在给线程中的对象分配内存时会尽量在TLAB上分配。如果对象过大或TLAB用完,则仍然在堆上进行分配。如果Eden区内存也用完了,则会进行一次Minor GC(young GC)。
2.Survival from to
Survival区与Eden区相同都在Java堆的年轻代。Survival区有两块,一块称为from区,另一块为to区,这两个区是相对的,在发生一次Minor GC后,from区就会和to区互换。在发生Minor GC时,Eden区和Survivalfrom区会把一些仍然存活的对象复制进Survival to区,并清除内存。Survival to区会把一些存活得足够旧的对象移老年代。
3.老年代
老年代里存放的都是存活时间较久的,大小较大的对象,因此年老代使用标记整理算法。当年老代容量满的时候,会触发一次Major GC(full GC),回收年老代和年轻代中不再被使用的对象资源。
简述 java 垃圾回收机制?
答:在 java 中,程序员是不需要显示的去释放一个对象的内存的,而是由虚拟机自行执行。在 JVM 中,有一个垃圾回收线程,它是低优先级的,在正常情况下是不会执行的,只有在虚 拟机空闲或者当前堆内存不足时,才会触发执行,扫面那些没有被任何引用的对象,并将 它们添加到要回收的集合中,进行回收。
GC如何判断对象可以被回收
-
引用计数法:每个对象有一个引用计数属性,新增一个引用时计数加1,引用释放时计数减1,计数为0时可以回收,引用计数法,可能会出现A 引用了 B,B 又引用了 A,这时候就算他们都不再使用了,但因为相互引用计数器=1 永远无法被回收。
-
可达性分析法:从 GC Roots 开始向下搜索,搜索所走过的路径称为引用链。当一个对象到 GC Roots 没有任何引用链相连时,则证明此对象是不可用的,那么虚拟机就判断是可回收对象。
GC Roots的对象有:
-
虚拟机栈(栈帧中的本地变量表)中引用的对象
-
方法区中类静态属性引用的对象
-
方法区中常量引用的对象
-
本地方法栈中JNI(即一般说的Native方法)引用的对象
可达性算法中的不可达对象并不是立即死亡的,对象拥有一次自我拯救的机会。对象被系统宣告死亡至 少要经历两次标记过程:第一次是经过可达性分析发现没有与GC Roots相连接的引用链,第二次是在由 虚拟机自动建立的Finalizer队列中判断是否需要执行finalize()方法。当对象变成(GC Roots)不可达时,GC会判断该对象是否覆盖了finalize方法,若未覆盖,则直接将其回 收。否则,若对象未执行过finalize方法,将其放入F-Queue队列,由一低优先级线程执行该队列中对象 的finalize方法。执行finalize方法完毕后,GC会再次判断该对象是否可达,若不可达,则进行回收,否 则,对象“复活”。每个对象只能触发一次finalize()方法。由于finalize()方法运行代价高昂,不确定性大,无法保证各个对象的调用顺序,不推荐大家使用,建议 遗忘它。
-
SafePoint 是什么?
答:比如 GC 的时候必须要等到 Java 线程都进入到 safepoint 的时候 VMThread 才能开始 执行 GC。
-
循环的末尾(防止大循环的时候一直不进入 safepoint,而其他线程在等待它进入safepoint)。
-
方法返回前。
-
调用方法的call之后4。
-
抛出异常的位置。
详见:https://blog.csdn.net/szw906689771/article/details/113941741
GC的三种收集方法
-
标记清除算法
分为标记和清除两个阶段,首先标记所有需要回收的对象,在标记完成后统一回收所有被标记的对象。它主要有两个问题:一个是效率问题,标记清除的效率较低;第二个是碎片问题,清除后会产生大量不连续的内存碎片。
-
复制算法—回收新生代,回收比例较大
原理就是把内存划分为大小相等的两块,每次只使用其中的一块。当这一块上的内存用完了,就把还存活的对象(可达性分析)复制到另一块上,然后把已使用过的内存空间一次性清理掉,这样每次都不用考虑内存碎片的情况,并且实现的更加简单。如果存活的比例很低,那么复制的操作就很小,效率会比较高。只是如果一次只使用其中一半,那么代价太大了。
现在主要都是用于新生代的回收,98%的新生代对象都是很快就不用的,所以只需要把内存分为一块较大的Eden空间和两块Survivor空间,每次只使用Eden和一块Survivor空间,当回收时把两个区域存活的对象复制到那一块剩余的Survivor上。一般比例为8:1,这样浪费的空间只有10%。如果Survivor内存不够,就是用老年代的内存进行担保。
-
标记整理算法—回收老年代,回收比例较小
对于老年代,存活的比例一般会比较高,如果使用复制算法那么复制操作的效率就会比较低。根据老年代的特点,提出了标记整理算法,先标记需要回收的对象;第二部不是进行回收,而是将存活对象都移动向一端,然后直接清除掉边界外的内存。
-
分代收集算法—常见虚拟机的方式
分代收集算法就是综合2、3,对于堆中的不同区域使用不同的收集算法。
GC 收集器
-
Serial收集器
Serial收集器是最基本的收集器,这是一个单线程收集器,它“单线程”的意义不仅仅是说明它只用一个线程去完成垃圾收集工作,更重要的是在它进行垃圾收集工作时,必须暂停其他工作线程,直到它收集完成。Sun将这件事称之为”Stop the world“。
没有一个收集器能完全不停顿,只是停顿的时间长短。
虽然Serial收集器的缺点很明显,但是它仍然是JVM在Client模式下的默认新生代收集器。它有着优于其他收集器的地方:简单而高效(与其他收集器的单线程比较),Serial收集器由于没有线程交互的开销,专心只做垃圾收集自然也获得最高的效率。在用户桌面场景下,分配给JVM的内存不会太多,停顿时间完全可以在几十到一百多毫秒之间,只要收集不频繁,这是完全可以接受的。
-
ParNew收集器
ParNew是Serial的多线程版本,在回收算法、对象分配原则上都是一致的。ParNew收集器是许多运行在Server模式下的默认新生代垃圾收集器,其主要在于除了Serial收集器,目前只有ParNew收集器能够与CMS收集器配合工作。
-
Parallel Scavenge收集器
Parallel Scavenge收集器是一个新生代垃圾收集器,其使用的算法是复制算法,也是并行的多线程收集器。
Parallel Scavenge 收集器更关注可控制的吞吐量,吞吐量等于运行用户代码的时间/(运行用户代码的时间+垃圾收集时间)。直观上,只要最大的垃圾收集停顿时间越小,吞吐量是越高的,但是GC停顿时间的缩短是以牺牲吞吐量和新生代空间作为代价的。比如原来10秒收集一次,每次停顿100毫秒,现在变成5秒收集一次,每次停顿70毫秒。停顿时间下降的同时,吞吐量也下降了。
停顿时间越短就越适合需要与用户交互的程序;而高吞吐量则可以最高效的利用CPU的时间,尽快的完成计算任务,主要适用于后台运算。
-
Serial Old收集器
Serial Old收集器是Serial收集器的老年代版本,也是一个单线程收集器,采用“标记-整理算法”进行回收。其运行过程与Serial收集器一样。
-
Parallel Old收集器
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和标记-整理算法进行垃圾回收。其通常与Parallel Scavenge收集器配合使用,“吞吐量优先”收集器是这个组合的特点,在注重吞吐量和CPU资源敏感的场合,都可以使用这个组合。
-
CMS 收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短停顿时间为目标的收集器,CMS收集器采用标记--清除算法,运行在老年代。主要包含以下几个步骤:
初始标记
并发标记
重新标记
并发清除
其中初始标记和重新标记仍然需要“Stop the world”。初始标记仅仅标记GC Root能直接关联的对象,并发标记就是进行GC Root Tracing过程,而重新标记则是为了修正并发标记期间,因用户程序继续运行而导致标记变动的那部分对象的标记记录。
由于整个过程中最耗时的并发标记和并发清除,收集线程和用户线程一起工作,所以总体上来说,CMS收集器回收过程是与用户线程并发执行的。虽然CMS优点是并发收集、低停顿,很大程度上已经是一个不错的垃圾收集器,但是还是有三个显著的缺点:
CMS收集器对CPU资源很敏感。在并发阶段,虽然它不会导致用户线程停顿,但是会因为占用一部分线程(CPU资源)而导致应用程序变慢。
CMS收集器不能处理浮动垃圾。所谓的“浮动垃圾”,就是在并发标记阶段,由于用户程序在运行,那么自然就会有新的垃圾产生,这部分垃圾被标记过后,CMS无法在当次集中处理它们,只好在下一次GC的时候处理,这部分未处理的垃圾就称为“浮动垃圾”。也是由于在垃圾收集阶段程序还需要运行,即还需要预留足够的内存空间供用户使用,因此CMS收集器不能像其他收集器那样等到老年代几乎填满才进行收集,需要预留一部分空间提供并发收集时程序运作使用。要是CMS预留的内存空间不能满足程序的要求,这是JVM就会启动预备方案:临时启动Serial Old收集器来收集老年代,这样停顿的时间就会很长。
由于CMS使用标记--清除算法,所以在收集之后会产生大量内存碎片。当内存碎片过多时,将会给分配大对象带来困难,这是就会进行Full GC。
-
G1收集器
G1收集器与CMS相比有很大的改进:
G1收集器采用标记--整理算法实现。
可以非常精确地控制停顿。
G1收集器可以实现在基本不牺牲吞吐量的情况下完成低停顿的内存回收,这是由于它极力的避免全区域的回收,G1收集器将Java堆(包括新生代和老年代)划分为多个区域(Region),并在后台维护一个优先列表,每次根据允许的时间,优先回收垃圾最多的区域 。
JVM类加载过程
加载、验证、准备、解析、初始化。
虚拟机把描述类的数据从 Class 文件加载到内存,并对数据进行校验,解析和初始化,最 终形成可以被虚拟机直接使用的 java 类型。
1.加载
加载时jvm做了这三件事:
1)通过一个类的全限定名来获取该类的二进制字节流
2)将这个字节流的静态存储结构转化为方法区运行时数据结构
3)在内存堆中生成一个代表该类的java.lang.Class对象,作为该类数据的访问入口
2.验证
验证、准备、解析这三步可以看做是一个连接的过程,将类的字节码连接到JVM的运行状态之中
验证是为了确保Class文件的字节流中包含的信息符合当前虚拟机的要求,不会威胁到jvm的安全
验证主要包括以下几个方面的验证:
1)文件格式的验证,验证字节流是否符合Class文件的规范,是否能被当前版本的虚拟机处理
2)元数据验证,对字节码描述的信息进行语义分析,确保符合java语言规范
3)字节码验证 通过数据流和控制流分析,确定语义是合法的,符合逻辑的
4)符号引用验证 这个校验在解析阶段发生
3.准备
为类的静态变量分配内存,初始化为系统的初始值。对于final static修饰的变量,
直接赋值为用户的定义值。如下面的例子:这里在准备阶段过后的初始值为0,而不是7
public static int a=7
4.解析
解析是将常量池内的符号引用转为直接引用(如物理内存地址指针)
5.初始化
到了初始化阶段,jvm才真正开始执行类中定义的java代码
1)初始化阶段是执行类构造器<clinit>()方法的过程。类构造器<clinit>()方法是由编译器自动收集。
类中的所有类变量的赋值动作和静态语句块(static块)中的语句合并产生的。
2)当初始化一个类的时候,如果发现其父类还没有进行过初始化、则需要先触发其父类的初始化。
3)虚拟机会保证一个类的<clinit>()方法在多线程环境中被正确加锁和同步。
描述一下 JVM 加载 class 文件的原理机制?
JVM 中类的装载是由类加载器(ClassLoader)和它的子类来实现的,Java中的类加载器是一个重要的 Java 运行时系统组件,它负责在运行时查找和装入类文件中的类。
由于 Java 的跨平台性,经过编译的 Java 源程序并不是一个可执行程序,而是 一个或多个类文件。当 Java 程序需要使用某个类时,JVM 会确保这个类已经被 加载、连接(验证、准备和解析)和初始化。类的加载是指把类的.class 文件 中的数据读入到内存中,通常是创建一个字节数组读入.class 文件,然后产生 与所加载类对应的 Class 对象。加载完成后,Class 对象还不完整,所以此时 的类还不可用。当类被加载后就进入连接阶段,这一阶段包括验证、准备(为静态变量分配内存并设置默认的初始值)和解析(将符号引用替换为直接引 用)三个步骤。最后 JVM 对类进行初始化,包括:1)如果类存在直接的父类并 且这个类还没有被初始化,那么就先初始化父类;2)如果类中存在初始化语 句,就依次执行这些初始化语句。
类的加载是由类加载器完成的,类加载器包括:根加载器(BootStrap)、扩展 加载器(Extension)、系统加载器(System)和用户自定义类加载器 (java.lang.ClassLoader 的子类)。从 Java 2(JDK 1.2)开始,类加载过程 采取了父亲委托机制(PDM)。PDM 更好的保证了 Java 平台的安全性,在该机 制中,JVM 自带的 Bootstrap 是根加载器,其他的加载器都有且仅有一个父类 加载器。类的加载首先请求父类加载器加载,父类加载器无能为力时才由其子 类加载器自行加载。JVM 不会向 Java 程序提供对 Bootstrap 的引用。
类加载器
实现通过类的权限定名获取该类的二进制字节流的代码块叫做类加载器。主要有一下四种类加载器:
-
启动类加载器(Bootstrap ClassLoader)
用来加载 java 核心类库,无法被 java 程序直接 引用。
默认负责加载%JAVA_HOME%lib下的jar包和 class文件。
-
扩展类加载器(extensions class loader)
它的父加载器是 Bootstrap,负责加载%JAVA_HOME%/lib/ext文件夹下的jar包和 class类。
它用来加载 Java 的扩展库。Java 虚拟机的 实现会提供一个扩展库目录。该类加载器在此目录里面查找并加载 Java 类。
-
系统类加载器(system class loader)
它根据 Java 应用的类路径(CLASSPATH) 来加载 Java 类。一般来说,Java 应用的类都是由它来完成加载的。可以通过ClassLoader.getSystemClassLoader()来获取它。
它的父加载器是Extension,又叫应用类加载器。
-
用户自定义类加载器
通过继承 java.lang.ClassLoader 类的方式实现。
类加载器双亲委派模型机制
当一个类收到了类加载请求时,不会自己先去加载这个类,而是将其委派给父类,由父类去加载,如果此时父类不能加载,反馈给子类,由子类去完成类的加载。
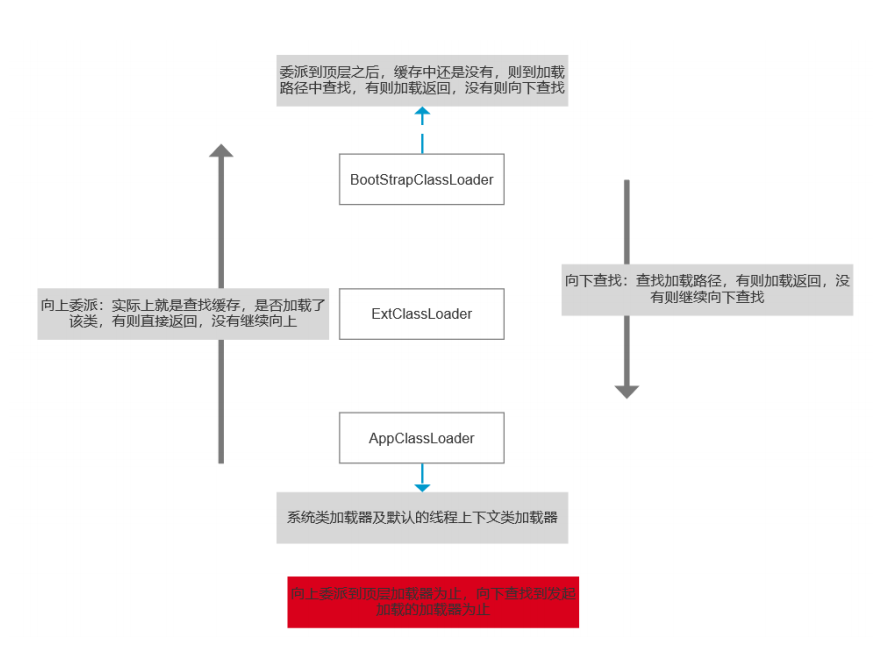
双亲委派模型的好处
-
主要是为了安全性,避免用户自己编写的类动态替换 Java的一些核心类,比如 String。
-
同时也避免了类的重复加载,因为 JVM中区分不同类,不仅仅是根据类名,相同的 class文件被不 同的 ClassLoader加载就是不同的两个类
简述对象创建方法
答:对象的创建方法主要是:new的过程
-
进行类加载检查。当遇到一个new指令,首先检查能否在方法区的常量池中能否定位到这个类的符号引用,并且检查类有没有进行加载、解析和初始化;
-
分配空间。有两种常见的分配方式,一是指针碰撞,二是空闲列表,分别针对连续分配内存和不连续的,有空隙的,取决于虚拟机是否会压缩整理。内存分配的大小是在类加载完成之后就已经确定的,但是分配的时候修改指针的指向位置应该是线程安全的(栈上的Reference),第一种方式就保证原子性;第二种是给每个线程分配自己的一小块内存,成为本地线程分配缓冲(TLAB),每个线程在自己的TLAB是哪个分配。
-
初始化。将分配的内存初始化为0值。
-
基本设置。进行基本的设置,确定这个对象是哪个类的实例,对象的HASH码,对象的年龄等等。
对象的内存布局
对象在内存中的存储的布局可以分为3块区域:
-
对象头(Header):对象头包含两个部分的信息,第一部分是对象自身的运行时数据,如哈希码、GC分代年龄、持有的锁等等;第二部分是类型指针,指向它的类元数据的指针,通过这个虚拟机来确定这个对象是哪个类的实例。
-
实例数据(Instance Data):对象真正存储的数据,就是程序代码中定义的字段内容。
-
对齐填充(Padding):用于使对象的开头必须是8字节的整数倍,无特殊意义。
对象的访问定位
对于这句代码:
Object objectRef = new Object();
Object objectRef 这部分将会反映到Java栈的本地变量中,作为一个reference类型数据出现。而“new Object()”这部分将会反映到Java堆中,形成一块存储Object类型所有实例数据值的结构化内存,根据具体类型以及虚拟机实现的对象内存布局的不同,这块内存的长度是不固定。另外,在java堆中还必须包括能查找到此对象类型数据(如对象类型、父类、实现的接口、方法等)的地址信息,这些数据类型存储在方法区中。
有两种基本的定位方式:
-
句柄访问(间接):在Java堆中划分一块内存作为句柄池(即一个句柄列表),reference中存储的就是对象在句柄池中的地址,得到了句柄池的地址就可以知道对象的实例数据和类型数据的位置。
-
直接指针访问(直接):reference中存储的直接就是对象的实例数据的地址,而实例数据中自己有一个指针存储对象类型数据的地址(方法区中),不需要reference来存储。
Mysql
事务
基本特性
事务基本特性ACID分别是:
原子性:指的是一个事务中的操作要么全部成功,要么全部失败。
一致性:指的是数据库总是从一个一致性的状态转换到另外一个一致性的状态。比如A转账给B100块钱, 假设A只有90块,支付之前我们数据库里的数据都是符合约束的,但是如果事务执行成功了,我们的数据库 数据就破坏约束了,因此事务不能成功,这里我们说事务提供了一致性的保证
隔离性:指的是一个事务的修改在最终提交前,对其他事务是不可见的。
持久性:指的是一旦事务提交,所做的修改就会永久保存到数据库中。
ACID靠什么保证的?
A原子性由undo log日志保证,它记录了需要回滚的日志信息,事务回滚时撤销已经执行成功的sql
C一致性由其他三大特性保证、程序代码要保证业务上的一致性
I隔离性由MVCC来保证
D持久性由内存+redo log来保证,mysql修改数据同时在内存和redo log记录这次操作,宕机的时候可 以从redo log恢复
InnoDB redo log 写盘,InnoDB 事务进入 prepare 状态。 如果前面 prepare 成功,binlog 写盘,再继续将事务日志持久化到 binlog,如果持久化成功,那么 InnoDB 事务则进入 commit 状态(在 redo log 里面写一个 commit 记录)
redolog的刷盘会在系统空闲时进行
MySQL 中 InnoDB 支持的四种事务隔离级别名称,以及逐级之间的区别
-
Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。读取未提交的数据,也称之为脏读。
脏读(Drity Read)
某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因, 前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
-
Read Committed(读取提交内容)
这是大部分数据库的隔离级别,比如Oracle,它满足了隔离的简单定义,一个事务只能看见已经提交事务所做的改变。解决了脏读问题。这种隔离级别也支持所谓的不可重复读,因为同一个事务的其他实例在该实例处理期间可能会有新的commit,所以同一select可能返回不同结果。
不可重复读(Non-repeatable read)
在一个事务的两次查询之中数据不一致,这可能是两次查询过程中 间插入了一个事务更新的原有的数据。
-
Repeatable Read(可重复读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。解决了脏读和不可重复度问题。不过理论上,这会导致另一个棘手的问题Phantom Read幻读。
幻读Phantom Read
幻读是指当用户读取某一范围的数据行时,另一个事务又在该范围内插入新行,用户再读取该范围的数据行时,会发现新的“幻影”行。
在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数 据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据 是它先前所没有的。
怎么解决幻读呢?
InnoDB存储引擎通过多版本并发控制MVCC,再加上间隙锁解决了幻读问题。
-
Serializable(可窜行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能互相冲突,从而解决幻读问题。它是在每个读的数据行上加上共享锁。在这级别,可能会导致大量的超时现象和锁竞争。一般不会使用。
MVCC
多版本并发控制:读取数据时通过一种类似快照的方式将数据保存下来,这样读锁就和写锁不冲突了, 不同的事务session会看到自己特定版本的数据,版本链
MVCC只在 READ COMMITTED 和 REPEATABLE READ 两个隔离级别下工作。其他两个隔离级别够和 MVCC不兼容, 因为 READ UNCOMMITTED 总是读取最新的数据行, 而不是符合当前事务版本的数据 行。而 SERIALIZABLE 则会对所有读取的行都加锁。
聚簇索引记录中有两个必要的隐藏列:
trx_id:用来存储每次对某条聚簇索引记录进行修改的时候的事务id。
roll_pointer:每次对哪条聚簇索引记录有修改的时候,都会把老版本写入undo日志中。这个
roll_pointer就是存了一个指针,它指向这条聚簇索引记录的上一个版本的位置,通过它来获得上一个 版本的记录信息。(注意插入操作的undo日志没有这个属性,因为它没有老版本)
已提交读和可重复读的区别就在于它们生成ReadView的策略不同。
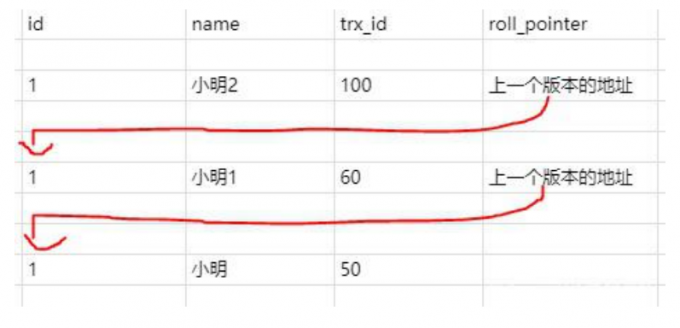
开始事务时创建readview,readView维护当前活动的事务id,即未提交的事务id,排序生成一个数组 访问数据,获取数据中的事务id(获取的是事务id最大的记录),对比readview:
如果在readview的左边(比readview都小),可以访问(在左边意味着该事务已经提交)
如果在readview的右边(比readview都大)或者就在readview中,不可以访问,获取roll_pointer,取 上一版本重新对比(在右边意味着,该事务在readview生成之后出现,在readview中意味着该事务还 未提交)
已提交读隔离级别下的事务在每次查询的开始都会生成一个独立的ReadView,而可重复读隔离级别则在 第一次读的时候生成一个ReadView,之后的读都复用之前的ReadView。
这就是Mysql的MVCC,通过版本链,实现多版本,可并发读-写,写-读。通过ReadView生成策略的不同 实现不同的隔离级别。
分表后非sharding_key的查询怎么处理,分表后的排序?
-
可以做一个mapping表,比如这时候商家要查询订单列表怎么办呢?不带user_id查询的话你总不 能扫全表吧?所以我们可以做一个映射关系表,保存商家和用户的关系,查询的时候先通过商家查 询到用户列表,再通过user_id去查询。
-
宽表,对数据实时性要求不是很高的场景,比如查询订单列表,可以把订单表同步到离线(实时) 数仓,再基于数仓去做成一张宽表,再基于其他如es提供查询服务。
-
数据量不是很大的话,比如后台的一些查询之类的,也可以通过多线程扫表,然后再聚合结果的方 式来做。或者异步的形式也是可以的。
union
排序字段是唯一索引:
-
首先第一页的查询:将各表的结果集进行合并,然后再次排序
-
第二页及以后的查询,需要传入上一页排序字段的最后一个值,及排序方式。
-
根据排序方式,及这个值进行查询。如排序字段date,上一页最后值为3,排序方式降序。查询的 时候sql为select ... from table where date < 3 order by date desc limit 0,10。这样再将几个表的 结果合并排序即可。
Mysql锁
当数据库有并发事务的时候,可能会产生数据的不一致,这时候需要一些机制来保证访问的次序,锁机制就是这样的一个机制。
-
MyISAM 支持表锁
-
InnoDB 支持表锁和行锁,默认为行锁。
-
表级锁:开销小,加锁快,不会出现死锁。锁定粒度大,发生锁冲突的概率最高,并发量 最低。
-
行级锁:开销大,加锁慢,会出现死锁。锁力度小,发生锁冲突的概率小,并发度最高。
锁的类型有哪些
基于锁的属性分类:共享锁、排他锁。
基于锁的粒度分类:行级锁(INNODB)、表级锁(INNODB、MYISAM)、页级锁(BDB引擎 )、记录锁、间 隙锁、临键锁。
基于锁的状态分类:意向共享锁、意向排它锁。
-
共享锁(Share Lock)
共享锁又称读锁,简称S锁;当一个事务为数据加上读锁之后,其他事务只能对该数据加读锁,而不能对 数据加写锁,直到所有的读锁释放之后其他事务才能对其进行加持写锁。共享锁的特性主要是为了支持 并发的读取数据,读取数据的时候不支持修改,避免出现重复读的问题。
-
排他锁(eXclusive Lock)
排他锁又称写锁,简称X锁;当一个事务为数据加上写锁时,其他请求将不能再为数据加任何锁,直到该 锁释放之后,其他事务才能对数据进行加锁。排他锁的目的是在数据修改时候,不允许其他人同时修 改,也不允许其他人读取。避免了出现脏数据和脏读的问题。
-
表锁
表锁是指上锁的时候锁住的是整个表,当下一个事务访问该表的时候,必须等前一个事务释放了锁才能 进行对表进行访问; 特点: 粒度大,加锁简单,容易冲突;
-
行锁
行锁是指上锁的时候锁住的是表的某一行或多行记录,其他事务访问同一张表时,只有被锁住的记录不 能访问,其他的记录可正常访问; 特点:粒度小,加锁比表锁麻烦,不容易冲突,相比表锁支持的并发要高;
-
记录锁(Record Lock)
记录锁也属于行锁中的一种,只不过记录锁的范围只是表中的某一条记录,记录锁是说事务在加锁后锁 住的只是表的某一条记录。 精准条件命中,并且命中的条件字段是唯一索引 加了记录锁之后数据可以避免数据在查询的时候被修改的重复读问题,也避免了在修改的事务未提交前 被其他事务读取的脏读问题。
-
页锁
页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突 少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。 特点:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
-
间隙锁(Gap Lock)
属于行锁中的一种,间隙锁是在事务加锁后其锁住的是表记录的某一个区间,当表的相邻ID之间出现空 隙则会形成一个区间,遵循左开右闭原则。 范围查询并且查询未命中记录,查询条件必须命中索引、间隙锁只会出现在REPEATABLE_READ(重复 读)的事务级别中。 触发条件:防止幻读问题,事务并发的时候,如果没有间隙锁,就会发生如下图的问题,在同一个事务 里,A事务的两次查询出的结果会不一样。 比如表里面的数据ID 为 1,4,5,7,10 ,那么会形成以下几个间隙区间,-n-1区间,1-4区间,7-10 区间,10-n区间 (-n代表负无穷大,n代表正无穷大)
-
临建锁(Next-Key Lock)
也属于行锁的一种,并且它是INNODB的行锁默认算法,总结来说它就是记录锁和间隙锁的组合,临键锁 会把查询出来的记录锁住,同时也会把该范围查询内的所有间隙空间也会锁住,再之它会把相邻的下一 个区间也会锁住 触发条件:范围查询并命中,查询命中了索引。 结合记录锁和间隙锁的特性,临键锁避免了在范围查询时出现脏读、重复读、幻读问题。加了临键锁之 后,在范围区间内数据不允许被修改和插 入。
如果当事务A加锁成功之后就设置一个状态告诉后面的人,已经有人对表里的行加了一个排他锁 了,你们不能对整个表加共享锁或排它锁了,那么后面需要对整个表加锁的人只需要获取这个状态 就知道自己是不是可以对表加锁,避免了对整个索引树的每个节点扫描是否加锁,而这个状态就是 意向锁。
-
意向共享锁
当一个事务试图对整个表进行加共享锁之前,首先需要获得这个表的意向共享锁。
-
意向排他锁
当一个事务试图对整个表进行加排它锁之前,首先需要获得这个表的意向排它锁。
InnoDB存储引擎的锁的算法
-
Record lock:单个行记录上的锁
-
Gap lock:间隙锁,锁定一个范围,不包括记录本身
-
Next-key lock:record+gap 锁定一个范围,包含记录本身
相关知识点:
-
innodb对于行的查询使用next-key lock
-
Next-locking keying为了解决Phantom Problem幻读问题
-
当查询的索引含有唯一属性时,将next-key lock降级为record key
-
Gap锁设计的目的是为了阻止多个事务将记录插入到同一范围内,而这会导致幻读问题的产生
-
有两种方式显式关闭gap锁:(除了外键约束和唯一性检查外,其余情况仅使用record lock) A. 将事务隔离级别设置为RC B. 将参数innodb_locks_unsafe_for_binlog设置为1
时间复杂度大小比较
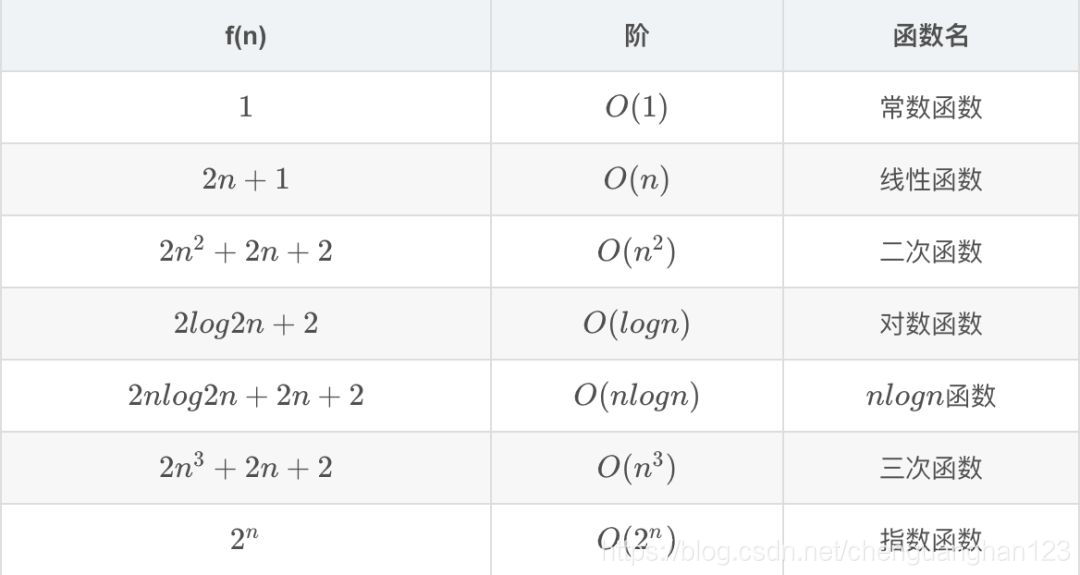
在上图中,我们可以看到当 n 很小时,函数之间不易区分,很难说谁处于主导地位,但是当 n 增大时,我们就能看到很明显的区别,谁是老大一目了然:
O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n)
出处:https://blog.csdn.net/chenguanghan123/article/details/83478259

如果ax=N(a>0,且a≠1),那么数x叫做以a为底N的对数,记作x=logaN,读作以a为底N的对数,其中a叫做对数的底数,N叫做真数。
出处:https://blog.csdn.net/ted_cs/article/details/82881831
索引
索引用来快速地寻找那些具有特定值的记录。如果没有索引,一般来说执行查询时遍历整张表。
原理
就是把无序的数据变成有序的查询
-
把创建了索引的列的内容进行排序
-
对排序结果生成倒排表
-
在倒排表内容上拼上数据地址链
-
在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
-
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则在表中搜索所有的行相比,索引有助于更快地获取信息
-
通俗的讲,索引就是数据的目录,就像看书一样,假如我想看第三章第四节的内容,如果有目录,我直接翻目录,找到第三章第四节的页码即可。如果没有目录,我就需要将从书的开头开始,一页一页翻,直到翻到第三章第四节的内容。
索引设计的原则?
查询更快、占用空间更小
-
适合索引的列是出现在where子句中的列,或者连接子句中指定的列
-
基数较小的表,索引效果较差,没有必要在此列建立索引
-
使用短索引,如果对长字符串列进行索引,应该指定一个前缀长度,这样能够节省大量索引空间, 如果搜索词超过索引前缀长度,则使用索引排除不匹配的行,然后检查其余行是否可能匹配。
-
不要过度索引。索引需要额外的磁盘空间,并降低写操作的性能。在修改表内容的时候,索引会进 行更新甚至重构,索引列越多,这个时间就会越长。所以只保持需要的索引有利于查询即可。
-
定义有外键的数据列一定要建立索引。
-
更新频繁字段不适合创建索引
-
若是不能有效区分数据的列不适合做索引列(如性别,男女未知,最多也就三种,区分度实在太低)
-
尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修 改原来的索引即可。
-
对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
-
对于定义为text、image和bit的数据类型的列不要建立索引。
MySQL索引的分类
我们根据对以列属性生成的索引大致分为两类:
-
单列索引:以该表的单个列,生成的索引树,就称为该表的单列索引。
-
组合索引:以该表的多个列组合,一起生成的索引树,就称为该表的组合索引。
单列索引又有具体细的划分:
-
主键索引:以该表主键生成的索引树。
-
唯一索引:以该表唯一列生成的索引树。
-
普通索引:以该表的普通列(非主键,非唯一列)生成的索引树。
-
全文索引:让搜索关键词更高效的一种索引。
详见:https://www.cnblogs.com/beyond-succeed/p/12573839.html
mysql聚簇和非聚簇索引的区别
都是B+树的数据结构
-
聚簇索引:将数据存储与索引放到了一块、并且是按照一定的顺序组织的,找到索引也就找到了数 据,数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是 相邻地存放在磁盘上的
-
非聚簇索引:叶子节点不存储数据、存储的是数据行地址,也就是说根据索引查找到数据行的位置 再取磁盘查找数据,这个就有点类似一本树的目录,比如我们要找第三章第一节,那我们先在这个 目录里面找,找到对应的页码后再去对应的页码看文章。
优势:
1、查询通过聚簇索引可以直接获取数据,相比非聚簇索引需要第二次查询(非覆盖索引的情况下)效率 要高 2、聚簇索引对于范围查询的效率很高,因为其数据是按照大小排列的
3、聚簇索引适合用在排序的场合,非聚簇索引不适合
劣势:
1、维护索引很昂贵,特别是插入新行或者主键被更新导至要分页(page split)的时候。建议在大量插 入新行后,选在负载较低的时间段,通过OPTIMIZE TABLE优化表,因为必须被移动的行数据可能造成 碎片。使用独享表空间可以弱化碎片
2、表因为使用UUId(随机ID)作为主键,使数据存储稀疏,这就会出现聚簇索引有可能有比全表扫面 更慢,所以建议使用int的auto_increment作为主键
3、如果主键比较大的话,那辅助索引将会变的更大,因为辅助索引的叶子存储的是主键值;过长的主键 值,会导致非叶子节点占用占用更多的物理空间
InnoDB中一定有主键,主键一定是聚簇索引,不手动设置、则会使用unique索引,没有unique索引, 则会使用数据库内部的一个行的隐藏id来当作主键索引。在聚簇索引之上创建的索引称之为辅助索引, 辅助索引访问数据总是需要二次查找,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引, 辅助索引叶子节点存储的不再是行的物理位置,而是主键值
MyISM使用的是非聚簇索引,没有聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构 完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助 键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据 来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
如果涉及到大数据量的排序、全表扫描、count之类的操作的话,还是MyISAM占优势些,因为索引所 占空间小,这些操作是需要在内存中完成的。
mysql索引的数据结构,各自优劣
索引的数据结构和具体存储引擎的实现有关,在MySQL中使用较多的索引有Hash索引,B+树索引等, InnoDB存储引擎的默认索引实现为:B+树索引。对于哈希索引来说,底层的数据结构就是哈希表,因 此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议 选择BTree索引。
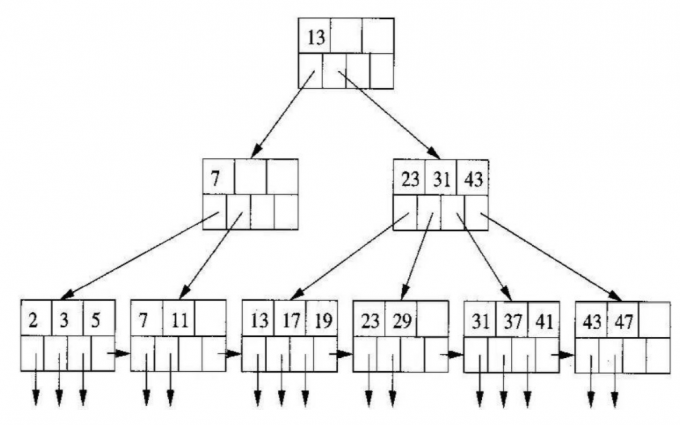
B+树
B+树是一个平衡的多叉树,从根节点到每个叶子节点的高度差值不超过1,而且同层级的节点间有指针 相互链接。在B+树上的常规检索,从根节点到叶子节点的搜索效率基本相当,不会出现大幅波动,而且 基于索引的顺序扫描时,也可以利用双向指针快速左右移动,效率非常高。因此,B+树索引被广泛应用 于数据库、文件系统等场景。
哈希索引
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到 叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快
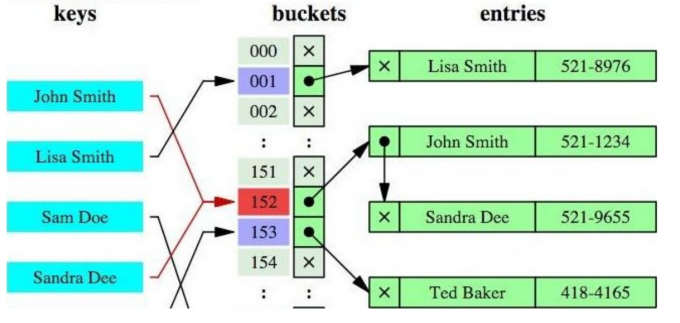
如果是等值查询,那么哈希索引明显有绝对优势,因为只需要经过一次算法即可找到相应的键值;前提 是键值都是唯一的。如果键值不是唯一的,就需要先找到该键所在位置,然后再根据链表往后扫描,直 到找到相应的数据;
如果是范围查询检索,这时候哈希索引就毫无用武之地了,因为原先是有序的键值,经过哈希算法后, 有可能变成不连续的了,就没办法再利用索引完成范围查询检索;
哈希索引也没办法利用索引完成排序,以及like ‘xxx%’ 这样的部分模糊查询(这种部分模糊查询,其实 本质上也是范围查询);
哈希索引也不支持多列联合索引的最左匹配规则;
B+树索引的关键字检索效率比较平均,不像B树那样波动幅度大,在有大量重复键值情况下,哈希索引 的效率也是极低的,因为存在哈希碰撞问题。
Hash索引和B+树索引
答:首先要知道Hash索引和B+树索引的底层实现原理:
-
hash索引底层就是hash表,进行查找时,调用一次hash函数就可以获取到相应的键值,之后进行回表查询获得实际数据。
-
B+树底层实现是多路平衡查找树,对于每一次的查询都是从根节点出发,查找到叶子节点方可以获得所查键值,然后根据查询判断是否需要回表查询数据。
那么可以看出他们有以下的不同:
-
hash索引进行等值查询更快(一般情况下),但是却无法进行范围查询。因为在hash索引中经过hash函数建立索引之后,索引的顺序与原顺序无法保持一致,不能支持范围查询。而B+树的的所有节点皆遵循(左节点小于父节点,右节点大于父节点,多叉树也类似),天然支持范围。
-
hash索引不支持使用索引进行排序,原理同上。
-
hash索引不支持模糊查询以及多列索引的最左前缀匹配.原理也是因为hash函数的不可预测,AAAA和AAAAB的索引没有相关性。
-
hash索引任何时候都避免不了回表查询数据,而B+树在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询。
-
hash索引虽然在等值查询上较快,但是不稳定,性能不可预测。当某个键值存在大量重复的时候,发生hash碰撞,此时效率可能极差。而B+树的查询效率比较稳定,对于所有的查询都是从根节点到叶子节点,且树的高度较低。
因此,在大多数情况下,直接选择B+树索引可以获得稳定且较好的查询速度。而不需要使用hash索引。
上面提到了B+树在满足聚簇索引和覆盖索引的时候不需要回表查询数据,什么是聚簇索引?
答:在B+树的索引中,叶子节点可能存储了当前的key值,也可能存储了当前的key值以及整行的数据,这就是聚簇索引和非聚簇索引.。在InnoDB中,只有主键索引是聚簇索引,如果没有主键,则挑选一个唯一键建立聚簇索引,如果没有唯一键,则隐式的生成一个键来建立聚簇索引。
当查询使用聚簇索引时,在对应的叶子节点,可以获取到整行数据,因此不用再次进行回表查询。
非聚簇索引一定会回表查询吗?
答:不一定。这涉及到查询语句所要求的字段是否全部命中了索引,如果全部命中了索引,那么就不必再进行回表查询。
举个简单的例子,假设我们在员工表的年龄上建立了索引,那么当进行select age from employee where age < 20的查询时,在索引的叶子节点上,已经包含了age信息,不会再次进行回表查询。
Mysql支持事务吗
在缺省模式下,MYSQL 是 autocommit 模式的,所有的数据库更新操作都会即时提交,所 以在缺省情况下,mysql 是不支持事务的。
但是如果你的 MYSQL 表类型是使用 InnoDB Tables 或 BDB tables 的话,你的 MYSQL 就可以 使用事务处理,使用 SET AUTOCOMMIT=0 就可以使 MYSQL 允许在非 autocommit 模式,在非autocommit 模式下,你必须使用 COMMIT 来提交你的更改,或者用 ROLLBACK 来回滚你的 更改。
示例如下:
START TRANSACTION;
SELECT @A:=SUM(salary) FROM table1 WHERE type=1;
UPDATE table2 SET summmary=@A WHERE type=1;
COMMIT;
Mysql查询是否区分大小写
不区分。
SELECT VERSION(),
CURRENT_DATE;
SeLect version(),
current_date;
seleCt vErSiOn(),
current_DATE;
这几个例子都是一样的,Mysql 不区分大小写。
列设置为 AUTO INCREMENT 时,如果在表中达到最大值,会发生什么情况?
答:它会停止递增,任何进一步的插入都将产生错误,因为密钥已被使用。
一张表,里面有 ID 自增主键,当 insert 了 17 条记录之后,删除了第 15,16,17 条记录, 再把 Mysql 重启,再 insert 一条记录,这条记录的 ID 是 18 还是 15 ?
-
如果表的类型是 MyISAM,那么是 18。因为 MyISAM 表会把自增主键的最大 ID 记录到数据文件里,重启 MySQL 自增主键的最大ID 也不会丢失。
-
如果表的类型是 InnoDB,那么是 15。InnoDB 表只是把自增主键的最大 ID 记录到内存中,所以重启数据库或者是对表进行OPTIMIZE 操作,都会导致最大 ID 丢失。
数据库三范式
-
第一范式(1NF)
确保每列保持原子性
字段具有原子性,不可再分。(所有关系型数据库系 统都满足第一范式数据库表中的字段都是单一属性的,不可再分)
-
第二范式(2NF)
确保表中的每列都和主键相关
是在第一范式(1NF)的基础上建立起来的,即满足 第二范式(2NF)必须先满足第一范式(1NF)。要求数据库表中的每个实例或行必须可以被唯一地区分。通常需要为表加上一个列,以存储 各个实例的惟一标识。这个惟一属性列被称为主关键字或主键。
-
满足第三范式(3NF)
确保每列都和主键列直接相关,而不是间接相关
必须先满足第二范式(2NF)。简而言之,第三 范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关 键字信息。
所以第三范式具有如下特征:
-
每一列只有一个值
-
每一行都能区分。
-
每一个表都不包含其他表已经包含的非主关键字信息。
-
详见:https://www.cnblogs.com/linjiqin/archive/2012/04/01/2428695.html
mysql 的复制原理以及流程
答:Mysql 内建的复制功能是构建大型,高性能应用程序的基础。将 Mysql 的数据分布到多个系统上去,这种分布的机制,是通过将 Mysql 的某一台主机的数据复制到其它主机(slaves)上,并重新执行一遍来实现的。复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器。主服务器将更新写入二进制日志文件,并维护文件的一个索引以跟踪日志循环。这些日志可以记录发送到从服务器的更新。当一个从服务器连接主服务器时,它通知主服务器在日志中读取的最后一次成功更新的位置。从服务器接收从那时起发生的任何更新,然后封锁并等待主服务器通知新的更新。
过程如下 :
-
主服务器 把更新记录到二进制日志文件中。
-
从服务器把主服务器的二进制日志拷贝到自己的中继日志(replay log)中。
-
从服务器重做中继日志中的时间, 把更新应用到自己的数据库上。
详见:https://www.cnblogs.com/huixuexidezhu/p/7059202.html
mysql主从同步原理
mysql主从同步的过程:
Mysql的主从复制中主要有三个线程: master(binlog dump thread)、slave(I/O thread 、SQL thread) ,Master一条线程和Slave中的两条线程。
-
主节点 binlog,主从复制的基础是主库记录数据库的所有变更记录到 binlog。binlog 是数据库服 务器启动的那一刻起,保存所有修改数据库结构或内容的一个文件。
-
主节点 log dump 线程,当 binlog 有变动时,log dump 线程读取其内容并发送给从节点。
-
从节点 I/O线程接收 binlog 内容,并将其写入到 relay log 文件中。
-
从节点的SQL 线程读取 relay log 文件内容对数据更新进行重放,最终保证主从数据库的一致性。
注:主从节点使用 binglog 文件 + position 偏移量来定位主从同步的位置,从节点会保存其已接收到的 偏移量,如果从节点发生宕机重启,则会自动从 position 的位置发起同步。
由于mysql默认的复制方式是异步的,主库把日志发送给从库后不关心从库是否已经处理,这样会产生 一个问题就是假设主库挂了,从库处理失败了,这时候从库升为主库后,日志就丢失了。由此产生两个 概念。
全同步复制
主库写入binlog后强制同步日志到从库,所有的从库都执行完成后才返回给客户端,但是很显然这个方 式的话性能会受到严重影响。
半同步复制
和全同步不同的是,半同步复制的逻辑是这样,从库写入日志成功后返回ACK确认给主库,主库收到至 少一个从库的确认就认为写操作完成。
mysql 中 myISAM与 innodb
-
事务支持
MyISAM:强调的是性能,每次查询具有原子性,其执行数度比 InnoDB 类型更快,但是不提供事务支持。
InnoDB:提供事务支持事务,外部键等高级数据库功能。具有事务(commit)、回滚 (rollback)和崩溃修复能力(crash recovery capabilities)的事务安全 (transaction-safe (ACID compliant))型表。
-
InnoDB 支持行级锁,而 MyISAM 支持表级锁.
用户在操作 myisam 表时,select,update,delete,insert 语句都会给表自动加锁,如果加锁以后的表满足 insert 并发的情况下,可以在表的尾部插入新的数据。
-
InnoDB 支持 MVCC, 而 MyISAM 不支持。
-
InnoDB支持外键,而MyISAM不支持。
-
表主键
MyISAM:允许没有任何索引和主键的表存在,索引都是保存行的地址。
InnoDB:如果没有设定主键或者非空唯一索引,就会自动生成一个6字节的主键(用户不可见),数据是主索引的一部分,附加索引保存的是主索引的值。
-
InnoDB不支持全文索引,而MyISAM支持。
-
可移植性、备份及恢复
MyISAM:数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作。
InnoDB:免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十 G 的时候就相对痛苦了。
-
存储结构
MyISAM:每个 MyISAM 在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。.frm文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex)。
InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB 表的大小只受限于操作系统文件的大小,一般为 2GB。
MyISAM
不⽀持事务,回滚将造成不完全回滚,不具有原⼦性
不⽀持外键
⽀持全⽂搜索
保存表的具体⾏数,不带where时,直接返回保存的⾏数
DELETE 表时,先drop表,然后重建表
MyISAM 表被存放在三个⽂件 。frm ⽂件存放表格定义。 数据⽂件是MYD (MYData) 。 索引⽂件是MYI (MYIndex)引伸
跨平台很难直接拷⻉
AUTO_INCREMENT类型字段可以和其他字段⼀起建⽴联合索引
表格可以被压缩
InnoDB
⽀持事务处理
⽀持外键
⽀持⾏锁
不⽀持FULLTEXT类型的索引(在Mysql5.6已引⼊)
不保存表的具体⾏数,扫描表来计算有多少⾏
对于AUTO_INCREMENT类型的字段,必须包含只有该字段的索引
DELETE 表时,是⼀⾏⼀⾏的删除
InnoDB 把数据和索引存放在表空间⾥⾯
跨平台可直接拷⻉使⽤
表格很难被压缩
选择
因为MyISAM相对简单所以在效率上要优于InnoDB.如果系统读多,写少。对原⼦性要求低。那么MyISAM最好的选择。 且MyISAM恢复速度快。可直接⽤备份覆盖恢复。如果系统读少,写多的时候,尤其是并发写⼊⾼的时候。InnoDB就是⾸选了。 两种类型都有⾃⼰优缺点,选择那个完全要看⾃⼰的实际类弄。
[SELECT *] 和[SELECT 全部字段]
-
前者要解析数据字典,后者不需要
-
结果输出顺序,前者与建表列顺序相同,后者按指定字段顺序
-
表字段改名,前者不需要修改,后者需要改
-
后者可以建立索引进行优化,前者无法优化
-
后者的可读性比前者要高
简述 Mybatis 的插件运行原理,以及如何编写一个插件
-
Mybatis 仅可以编写针对 ParameterHandler、ResultSetHandler、StatementHandler、 Executor 这 4 种接口的插件,Mybatis 通过动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这 4 种接口对象的方法时,就会进入拦截方法,具体就是 InvocationHandler 的 invoke()方法,当然,只会拦截那些你指定需要拦截的方法。
-
实现 Mybatis 的 Interceptor 接口并复写 intercept()方法,然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可,记住,别忘了在配置文件中配置你编写的插件。
#{}和${}
-
#{}是预编译处理,${}是字符串替换。
-
Mybatis 在处理#{}时,会将 sql 中的#{}替换为?号,调用 PreparedStatement 的 set 方法 来赋值。
-
Mybatis 在处理${}时,就是把${}成变量的值。
-
使用#{}可以有效的防止 SQL 注入,提高系统安全性。
MySQL的binlog有有几种录入格式?分别有什么区别?
答:有三种格式,statement,row和mixed。
-
statement模式下,记录单元为语句。即每一个sql造成的影响会记录,由于sql的执行是有上下文的,因此在保存的时候需要保存相关的信息,同时还有一些使用了函数之类的语句无法被记录复制。
-
row级别下,记录单元为每一行的改动,基本是可以全部记下来但是由于很多操作,会导致大量行的改动(比如alter table),因此这种模式的文件保存的信息太多,日志量太大。
-
mixed,一种折中的方案,普通操作使用statement记录,当无法使用statement的时候使用row。
此外,新版的MySQL中对row级别也做了一些优化,当表结构发生变化的时候,会记录语句而不是逐行记录。
SQL调化
在业务系统中,除了使用主键进行的查询,其他的都会在测试库上测试其耗时,慢查询的统计主要由运维在做,会定期将业务中的慢查询反馈给我们。慢查询的优化首先要搞明白慢的原因是什么?是查询条件没有命中索引?是load了不需要的数据列?还是数据量太大?
所以优化也是针对这三个方向来的,
-
首先分析语句,看看是否load了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载 了许多结果中并不需要的列,对语句进行分析以及重写。
-
分析语句的执行计划,然后获得其使用索引的情况,之后修改语句或者修改索引,使得语句可以尽 可能的命中索引。
-
如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者 纵向的分表。
具体细节
1、查看sql是否涉及多表的联表或者子查询,如果有,看是否能进行业务拆分,相关字段冗余或者合并成临时表(业务和算法的优化)。
2、涉及链表的查询,是否能进行分表查询,单表查询之后的结果进行字段整合。
3、如果以上两种都不能操作,非要链表查询,那么考虑对相对应的查询条件做索引。加快查询速度。
4、针对数量大的表进行历史表分离(如交易流水表)。
5、数据库主从分离,读写分离,降低读写针对同一表同时的压力,至于主从同步,mysql有自带的binlog实现主从同步。
6、explain分析sql语句,查看执行计划,分析索引是否用上,分析扫描行数等等。
7、查看mysql执行日志,看看是否有其他方面的问题。
explain:https://www.cnblogs.com/tufujie/p/9413852.html
a. explain select语句; b. 当只要⼀条数据时使⽤limit 1; c. 为搜索字段建索引; d. 避免select *; e. 字段尽量使⽤not null; f. 垂直分割; g. 拆分⼤的delete和insert语句:delete和insert会锁表; h. 分表分库分区。
-
选择最合适的字段属性:类型、⻓度、是否允许NULL等;尽量把字段设为not null,⼀⾯查询时对⽐是否为null;
-
要尽量避免全表扫描,⾸先应考虑在 where 及 order by 涉及的列上建⽴索引。
-
应尽量避免在 where ⼦句中对字段进⾏ null 值判断、使⽤!= 或 <> 操作符,否则将导致引擎放弃使⽤索引⽽进⾏全表扫描
-
应尽量避免在 where ⼦句中使⽤ or 来连接条件,如果⼀个字段有索引,⼀个字段没有索引,将导致引擎放弃使⽤索引⽽进⾏全 表扫描
-
in 和 not in 也要慎⽤,否则会导致全表扫描
-
模糊查询也将导致全表扫描,若要提⾼效率,可以考虑字段建⽴前置索引或⽤全⽂检索;
-
如果在 where ⼦句中使⽤参数,也会导致全表扫描。因为SQL只有在运⾏时才会解析局部变量,但优化程序不能将访问计划的选择 推迟到运⾏时;它必须在编译时进⾏选择。然 ⽽,如果在编译时建⽴访问计划,变量的值还是未知的,因⽽⽆法作为索引选择的输⼊项。
-
应尽量避免在where⼦句中对字段进⾏函数操作,这将导致引擎放弃使⽤索引⽽进⾏全表扫描。
-
不要在 where ⼦句中的“=”左边进⾏函数、算术运算或其他表达式运算,否则系统将可能⽆法正确使⽤索引。
-
在使⽤索引字段作为条件时,如果该索引是复合索引,那么必须使⽤到该索引中的第⼀个字段作为条件时才能保证系统使⽤该索 引,否则该索引将不会被使⽤,并且应尽可能的让字段顺序与索引顺序相⼀致。
-
不要写⼀些没有意义的查询,如需要⽣成⼀个空表结构:
-
Update 语句,如果只更改1、2个字段,不要Update全部字段,否则频繁调⽤会引起明显的性能消耗,同时带来⼤量⽇志。
-
对于多张⼤数据量(这⾥⼏百条就算⼤了)的表JOIN,要先分⻚再JOIN,否则逻辑读会很⾼,性能很差。
-
select count(*) from table;这样不带任何条件的count会引起全表扫描,并且没有任何业务意义,是⼀定要杜绝的。
-
索引并不是越多越好,索引固然可以提⾼相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况⽽定。⼀个表的索引数最好不要超过6个,若太多则应考虑⼀些不常使 ⽤到的列上建的索引是否有 必要。
-
应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,⼀旦该列值改 变将导致整个表记录的顺序的调整,会耗费相当⼤的资源。若应⽤系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
-
尽量使⽤数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为 引擎在处理查询和连 接时会逐个⽐较字符串中每⼀个字符,⽽对于数字型⽽⾔只需要⽐较⼀次就够了。
-
尽可能的使⽤ varchar/nvarchar 代替 char/nchar ,因为⾸先变⻓字段存储空间⼩,可以节省存储空间,其次对于查询来 说,在⼀个相对较⼩的字段内搜索效率显然要⾼些。
-
任何地⽅都不要使⽤ select * from t ,⽤具体的字段列表代替“*”,不要返回⽤不到的任何字段。
-
尽量使⽤表变量来代替临时表。如果表变量包含⼤量数据,请注意索引⾮常有限(只有主键索引)。
-
避免频繁创建和删除临时表,以减少系统表资源的消耗。临时表并不是不可使⽤,适当地使⽤它们可以使某些例程更有效,例如, 当需要重复引⽤⼤型表或常⽤表中的某个数据集时。但是,对于⼀次性事件, 最好使⽤导出表。
-
在新建临时表时,如果⼀次性插⼊数据量很⼤,那么可以使⽤ select into 代替 create table,避免造成⼤量 log ,以提 ⾼速度;如果数据量不⼤,为了缓和系统表的资源,应先create table,然后insert。
-
如果使⽤到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可 以避免系统表的较⻓时间锁定。
-
尽量避免使⽤游标,因为游标的效率较差,如果游标操作的数据超过1万⾏,那么就应该考虑改写。
-
使⽤基于游标的⽅法或临时表⽅法之前,应先寻找基于集的解决⽅案来解决问题,基于集的⽅法通常更有效。
-
与临时表⼀样,游标并不是不可使⽤。对⼩型数据集使⽤ FAST_FORWARD 游标通常要优于其他逐⾏处理⽅法,尤其是在必须引⽤ ⼏个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要⽐使⽤游标执⾏的速度快。如果开发时 间允许,基于游标的⽅法和基于集的⽅法 都可以尝试⼀下,看哪⼀种⽅法的效果更好。
-
在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。⽆需在执⾏存储过程和触 发器的每个语句后向客户端发送 DONE_IN_PROC 消息。
-
尽量避免⼤事务操作,提⾼系统并发能⼒。
-
尽量避免向客户端返回⼤数据量,若数据量过⼤,应该考虑相应需求是否合理。
innodb如何实现mysql的事务
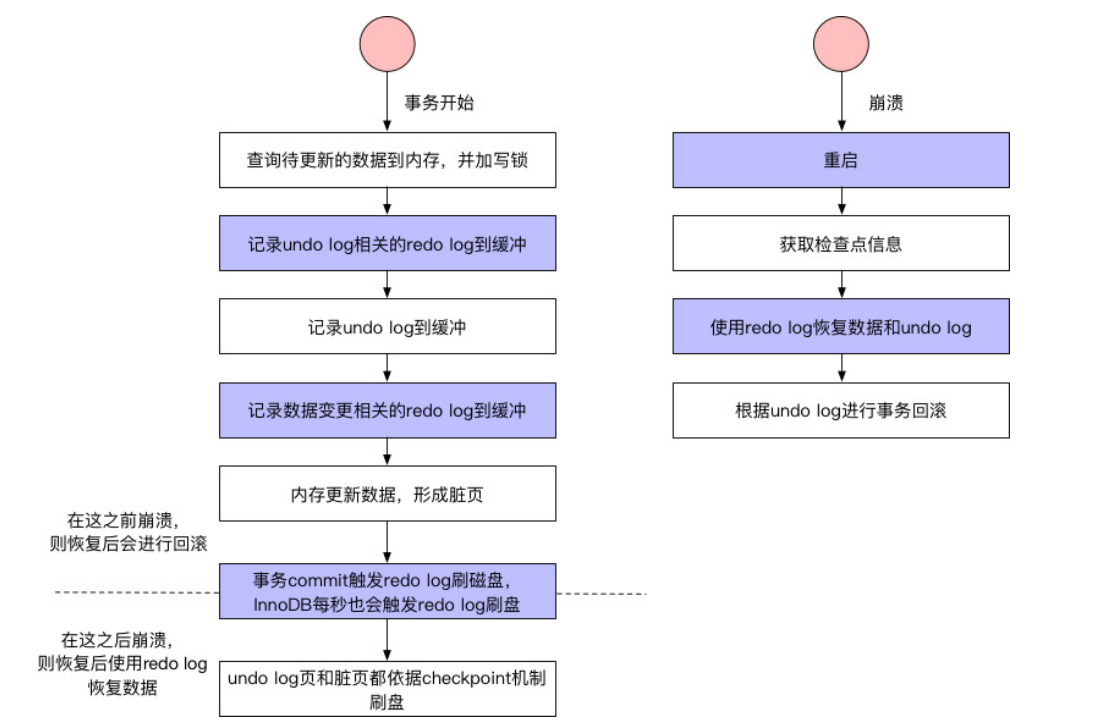
事务进⾏过程中,每次sql语句执⾏,都会记录undo log和redo log,然后更新数据形成脏⻚,然后redo log按照时间或 者空间等条件进⾏落盘,undo log和脏⻚按照checkpoint进⾏落盘,落盘后相应的redo log就可以删除了。此时,事务还未 COMMIT,如果发⽣崩溃,则⾸先检查checkpoint记录,使⽤相应的redo log进⾏数据和undo log的恢复,然后查看undo log的 状态发现事务尚未提交,然后就使⽤undo log进⾏事务回滚。事务执⾏COMMIT操作时,会将本事务相关的所有redo log都进⾏ 落盘,只有所有redo log落盘成功,才算COMMIT成功。然后内存中的数据脏⻚继续按照checkpoint进⾏落盘。如果此时发⽣了 崩溃,则只使⽤redo log恢复数据。
Java并发
线程和进程
线程是进程的子集,一个进程可以有很多线程。每个进程都有自己的内存空间,可执行代码和唯一进程标识符(PID)。
每条线程并行执行不同的任务。不同的进程使用不同的内存空间(线程自己的堆栈),而所有的线程共享一片相同的内存空间(进程主内存)。别把它和栈内存搞混,每个线程都拥有单独的栈内存用来存储本地数据。
实现多线程的方式有哪些?
-
继承Thread类:Java单继承,不推荐;
-
实现Runnable接口:Thread类也是继承Runnable接口,推荐;
-
实现Callable接口:实现Callable接口,配合FutureTask使用,有返回值;
-
使用线程池:复用,节约资源;
-
更多方式可以参考我的文章
并发的三大特性
-
原子性
原子性是指在一个操作中cpu不可以在中途暂停然后再调度,即不被中断操作,要不全部执行完成,要 不都不执行。就好比转账,从账户A向账户B转1000元,那么必然包括2个操作:从账户A减去1000元, 往账户B加上1000元。2个操作必须全部完成。
private long count = 0;
public void calc() {
count++;
}1:将 count 从主存读到工作内存中的副本中
2:+1的运算
3:将结果写入工作内存
4:将工作内存的值刷回主存(什么时候刷入由操作系统决定,不确定的)
那程序中原子性指的是最小的操作单元,比如自增操作,它本身其实并不是原子性操作,分了3步的, 包括读取变量的原始值、进行加1操作、写入工作内存。所以在多线程中,有可能一个线程还没自增 完,可能才执行到第二部,另一个线程就已经读取了值,导致结果错误。那如果我们能保证自增操作是 一个原子性的操作,那么就能保证其他线程读取到的一定是自增后的数据。
关键字:synchronized
-
可见性
当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。 若两个线程在不同的cpu,那么线程1改变了i的值还没刷新到主存,线程2又使用了i,那么这个i值肯定 还是之前的,线程1对变量的修改线程没看到这就是可见性问题。
//线程1
boolean stop = false;
while(!stop){
doSomething();
}
//线程2
stop = true;如果线程2改变了stop的值,线程1一定会停止吗?不一定。当线程2更改了stop变量的值之后,但是还 没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因 此还会一直循环下去。
关键字:volatile、synchronized、final
-
有序性
虚拟机在进行代码编译时,对于那些改变顺序之后不会对最终结果造成影响的代码,虚拟机不一定会按 照我们写的代码的顺序来执行,有可能将他们重排序。实际上,对于有些代码进行重排序之后,虽然对 变量的值没有造成影响,但有可能会出现线程安全问题。
int a = 0;
bool flag = false;
public void write() {
a = 2; //1
flag = true; //2
}
public void multiply() {
if (flag) { //3
int ret = a * a;//4
}
}write方法里的1和2做了重排序,线程1先对flag赋值为true,随后执行到线程2,ret直接计算出结果, 再到线程1,这时候a才赋值为2,很明显迟了一步
关键字:volatile、synchronized
volatile本身就包含了禁止指令重排序的语义,而synchronized关键字是由“一个变量在同一时刻只允许 一条线程对其进行lock操作”这条规则明确的。
synchronized关键字同时满足以上三种特性,但是volatile关键字不满足原子性。
在某些情况下,volatile的同步机制的性能确实要优于锁(使用synchronized关键字或 java.util.concurrent包里面的锁),因为volatile的总开销要比锁低。
我们判断使用volatile还是加锁的唯一依据就是volatile的语义能否满足使用的场景(原子性)
用Runnable还是Thread?
这个问题是上题的后续,大家都知道我们可以通过继承Thread类或者调用Runnable接口来实现线程,问题是,那个方法更好呢?什么情况下使用它?这个问题很容易回答,如果你知道Java不支持类的多重继承,但允许你调用多个接口。所以如果你要继承其他类,当然是调用Runnable接口好了。
-
Runnable和Thread两者最大的区别是Thread是类而Runnable是接口,至于用类还是用接口,取决于继承上的实际需要。Java类是单继承的,实现多个接口可以实现类似多继承的操作。
-
其次, Runnable就相当于一个作业,而Thread才是真正的处理线程,我们需要的只是定义这个作业,然后将作业交给线程去处理,这样就达到了松耦合,也符合面向对象里面组合的使用,另外也节省了函数开销,继承Thread的同时,不仅拥有了作业的方法run(),还继承了其他所有的方法。
-
当需要创建大量线程的时候,有以下不足:①线程生命周期的开销非常高;②资源消耗;③稳定性。
-
如果二者都可以选择不用,那就不用。因为Java这门语言发展到今天,在语言层面提供的多线程机制已经比较丰富且高级,完全不用在线程层面操作。直接使用Thread和Runnable这样的“裸线程”元素比较容易出错,还需要额外关注线程数等问题。建议:简单的多线程程序,使用Executor。复杂的多线程程序,使用一个Actor库,首推Akka。
-
如果一定要在Runnable和Thread中选择一个使用,选择Runnable。
Thread和Runnable的实质是继承关系,没有可比性。无论使用Runnable还是Thread,都会new Thread,然后执行run方法。用法上,如果有复杂的线程操作需求,那就选择继承Thread,如果只是简 单的执行一个任务,那就实现runnable。
//会卖出多一倍的票public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
new MyThread().start();
new MyThread().start();
}
static class MyThread extends Thread{
private int ticket = 5;
public void run(){
while(true){
System.out.println("Thread ticket = " + ticket--);
if(ticket < 0){
break;
}
}
}
}
}
//正常卖出public
class Test2 {
public static void main(String[] args) {
// TODO Auto-generated method stub
MyThread2 mt=new MyThread2();
new Thread(mt).start();
new Thread(mt).start();
}
static class MyThread2 implements Runnable{
private int ticket = 5;
public void run(){
while(true){
System.out.println("Runnable ticket = " + ticket--);
if(ticket < 0){
break;
}
}
}
}
}
原因是:MyThread创建了两个实例,自然会卖出两倍,属于用法错误
Thread 类中的start() 和 run()
这个问题经常被问到,但还是能从此区分出面试者对Java线程模型的理解程度。start()方法被用来启动新创建的线程,而且start()内部调用了run()方法,JDK 1.8源码中start方法的注释这样写到:Causes this thread to begin execution; the Java Virtual Machine calls the run method of this thread.这和直接调用run()方法的效果不一样。当你调用run()方法的时候,只会是在原来的线程中调用,没有新的线程启动,start()方法才会启动新线程,JDK 1.8源码中注释这样写:The result is that two threads are running concurrently: the current thread (which returns from the call to the start method) and the other thread (which executes its run method).。
new 一个 Thread,线程进入了新建状态;调用 start() 方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。而直接执行 run() 方法,会把 run 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
总结:调用 start 方法方可启动线程并使线程进入就绪状态,而 run 方法只是 thread 的一个普通方法调用,还是在主线程里执行。
sleep() 和 wait()
-
两者最主要的区别在于:sleep 方法没有释放锁,而 wait 方法释放了锁 。
-
两者都可以暂停线程的执行。
-
Wait 通常被用于线程间交互/通信,sleep 通常被用于暂停执行。
-
wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify() 或者 notifyAll() 方法。sleep() 方法执行完成后,线程会自动苏醒。
源码如下:
public class Thread implements Runnable {
public static native void sleep(long millis) throws InterruptedException;
public static void sleep(long millis, int nanos) throws InterruptedException {
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
}
if (nanos >= 500000 || (nanos != 0 && millis == 0)) {
millis++;
}
sleep(millis);
}
//...
}
public class Object {
public final native void wait(long timeout) throws InterruptedException;
public final void wait(long timeout, int nanos) throws InterruptedException {
if (timeout < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
}
if (nanos > 0) {
timeout++;
}
wait(timeout);
}
//...
}
1、 sleep 来自 Thread 类,和 wait 来自 Object 类。
2、最主要是sleep方法没有释放锁,而wait方法释放了 锁,使得其他线程可以使用同步控制块或者方法。 3、wait,notify和 notifyAll 只能在同步控制方法或者同步控制块里面使用,而 sleep 可以在任何地方使用(使 用范围)
4、 sleep 必须捕获异常,而 wait , notify 和 notifyAll 不需要捕获异常
-
sleep 方法属于 Thread 类中方法,表示让一个线程进入睡眠状态,等待一定的时间之后,自动醒来进入到可 运行状态,不会马上进入运行状态,因为线程调度机制恢复线程的运行也需要时间,一个线程对象调用了 sleep方法之后,并不会释放他所持有的所有对象锁,所以也就不会影响其他进程对象的运行。但在 sleep 的过程中过 程中有可能被其他对象调用它的 interrupt() ,产生 InterruptedException 异常,如果你的程序不捕获这个异 常,线程就会异常终止,进入 TERMINATED 状态,如果你的程序捕获了这个异常,那么程序就会继续执行catch语 句块(可能还有 finally 语句块)以及以后的代码。
注意 sleep() 方法是一个静态方法,也就是说他只对当前对象有效,通过 t.sleep() 让t对象进入 sleep ,这样 的做法是错误的,它只会是使当前线程被 sleep 而不是 t 线程。
-
wait 属于 Object 的成员方法,一旦一个对象调用了wait方法,必须要采用 notify() 和 notifyAll() 方法 唤醒该进程;如果线程拥有某个或某些对象的同步锁,那么在调用了 wait() 后,这个线程就会释放它持有的所有 同步资源,而不限于这个被调用了 wait() 方法的对象。wait() 方法也同样会在 wait 的过程中有可能被其他对 象调用 interrupt() 方法而产生 。
-
锁池
所有需要竞争同步锁的线程都会放在锁池当中,比如当前对象的锁已经被其中一个线程得到,则其他线 程需要在这个锁池进行等待,当前面的线程释放同步锁后锁池中的线程去竞争同步锁,当某个线程得到 后会进入就绪队列进行等待cpu资源分配。
-
等待池
当我们调用wait()方法后,线程会放到等待池当中,等待池的线程是不会去竞争同步锁。只有调用了 notify()或notifyAll()后等待池的线程才会开始去竞争锁,notify()是随机从等待池选出一个线程放 到锁池,而notifyAll()是将等待池的所有线程放到锁池当中
-
sleep 是 Thread 类的静态本地方法,wait 则是 Object 类的本地方法。
-
sleep方法不会释放lock,但是wait会释放,而且会加入到等待队列中。
sleep就是把cpu的执行资格和执行权释放出去,不再运行此线程,当定时时间结束再取回cpu资源,参与cpu 的调度,获取到cpu资源后就可以继续运行了。而如果sleep时该线程有锁,那么sleep不会释放这个锁,而 是把锁带着进入了冻结状态,也就是说其他需要这个锁的线程根本不可能获取到这个锁。也就是说无法执行程 序。如果在睡眠期间其他线程调用了这个线程的interrupt方法,那么这个线程也会抛出 interruptexception异常返回,这点和wait是一样的。
-
sleep方法不依赖于同步器synchronized,但是wait需要依赖synchronized关键字
-
sleep不需要被唤醒(休眠之后推出阻塞),但是wait需要(不指定时间需要被别人中断)。
-
sleep 一般用于当前线程休眠,或者轮循暂停操作,wait 则多用于多线程之间的通信。
-
sleep 会让出 CPU 执行时间且强制上下文切换,而 wait 则不一定,wait 后可能还是有机会重新竞 争到锁继续执行的。
-
yield()执行后线程直接进入就绪状态,马上释放了cpu的执行权,但是依然保留了cpu的执行资格, 所以有可能cpu下次进行线程调度还会让这个线程获取到执行权继续执行
-
join()执行后线程进入阻塞状态,例如在线程B中调用线程A的join(),那线程B会进入到阻塞队 列,直到线程A结束或中断线程
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("22222222");
}
});
t1.start();
t1.join(); // 这行代码必须要等t1全部执行完毕,才会执行
System.out.println("1111");
}
222222221111
-
并发、并行、串行的区别
-
串行:在时间上不可能发生重叠,前一个任务没搞定,下一个任务就只能等着
-
并发: 同一时间段,多个任务都在执行 (单位时间内不一定同时执行)。
-
并行: 单位时间内,多个任务同时执行。
说说线程的生命周期和状态?
-
线程通常有五种状态,创建,就绪,运行、阻塞和死亡状态。
-
新建状态(New):新创建了一个线程对象。
-
就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start方法。该状态的线程位于 可运行线程池中,变得可运行,等待获取CPU的使用权。
-
运行状态(Running):就绪状态的线程获取了CPU,执行程序代码。
-
阻塞状态(Blocked):阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进 入就绪状态,才有机会转到运行状态。
-
死亡状态(Dead):线程执行完了或者因异常退出了run方法,该线程结束生命周期。
-
-
阻塞的情况又分为三种:
-
等待阻塞:运行的线程执行wait方法,该线程会释放占用的所有资源,JVM会把该线程放入“等待 池”中。进入这个状态后,是不能自动唤醒的,必须依靠其他线程调用notify或notifyAll方法才能被唤 醒,wait是object类的方法
-
同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放 入“锁池”中。
-
其他阻塞:运行的线程执行sleep或join方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状 态。当sleep状态超时、join等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。 sleep是Thread类的方法
-
Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种不同状态的其中一个状态(图源《Java 并发编程艺术》4.1.4 节)。
线程在生命周期中并不是固定处于某一个状态而是随着代码的执行在不同状态之间切换。Java 线程状态变迁如下图所示(图源《Java 并发编程艺术》4.1.4 节):
由上图可以看出:线程创建之后它将处于 NEW(新建) 状态,调用 start() 方法后开始运行,线程这时候处于 READY(可运行) 状态。可运行状态的线程获得了 CPU 时间片(timeslice)后就处于 RUNNING(运行) 状态。
操作系统隐藏 Java 虚拟机(JVM)中的 RUNNABLE 和 RUNNING 状态,它只能看到 RUNNABLE 状态(图源:HowToDoInJava:Java Thread Life Cycle and Thread States),所以 Java 系统一般将这两个状态统称为 RUNNABLE(运行中) 状态 。
当线程执行 wait()方法之后,线程进入 WAITING(等待)状态。进入等待状态的线程需要依靠其他线程的通知才能够返回到运行状态,而 TIME_WAITING(超时等待) 状态相当于在等待状态的基础上增加了超时限制,比如通过 sleep(long millis)方法或 wait(long millis)方法可以将 Java 线程置于 TIMED WAITING 状态。当超时时间到达后 Java 线程将会返回到 RUNNABLE 状态。当线程调用同步方法时,在没有获取到锁的情况下,线程将会进入到 BLOCKED(阻塞) 状态。线程在执行 Runnable 的run()方法之后将会进入到 TERMINATED(终止) 状态。
什么是线程死锁?
多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
如下图所示,线程 A 持有资源 2,线程 B 持有资源 1,他们同时都想申请对方的资源,所以这两个线程就会互相等待而进入死锁状态。
下面通过一个例子来说明线程死锁,代码模拟了上图的死锁的情况 (代码来源于《并发编程之美》):
public class DeadLockDemo {
private static Object resource1 = new Object();//资源 1
private static Object resource2 = new Object();//资源 2
public static void main(String[] args) {
new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
}
}
}, "线程 1").start();
new Thread(() -> {
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource1");
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
}
}
}, "线程 2").start();
}
}
输出:
Thread[线程 1,5,main]get resource1
Thread[线程 2,5,main]get resource2
Thread[线程 1,5,main]waiting get resource2
Thread[线程 2,5,main]waiting get resource1
线程 A 通过 synchronized (resource1) 获得 resource1 的监视器锁,然后通过 Thread.sleep(1000);让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。上面的例子符合产生死锁的四个必要条件。
学过操作系统的朋友都知道产生死锁必须具备以下四个条件:
-
互斥条件:该资源任意一个时刻只由一个线程占用。
-
请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
-
不剥夺条件:线程已获得的资源在末使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
-
循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
如何避免线程死锁?
我们只要破坏产生死锁的四个条件中的其中一个就可以了。
-
破坏互斥条件:这个条件我们没有办法破坏,因为我们用锁本来就是想让他们互斥的(临界资源需要互斥访问)。
-
破坏请求与保持条件:一次性申请所有的资源。
-
破坏不剥夺条件:占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
-
破坏循环等待条件:靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
我们对线程 2 的代码修改成下面这样就不会产生死锁了。
new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
}
}
}, "线程 2").start();
输出:
Thread[线程 1,5,main]get resource1Thread[线程 1,5,main]waiting get resource2Thread[线程 1,5,main]get resource2Thread[线程 2,5,main]get resource1Thread[线程 2,5,main]waiting get resource2Thread[线程 2,5,main]get resource2Process finished with exit code 0
我们分析一下上面的代码为什么避免了死锁的发生?
线程 1 首先获得到 resource1 的监视器锁,这时候线程 2 就获取不到了。然后线程 1 再去获取 resource2 的监视器锁,可以获取到。然后线程 1 释放了对 resource1、resource2 的监视器锁的占用,线程 2 获取到就可以执行了。这样就破坏了破坏循环等待条件,因此避免了死锁。
什么是死锁,活锁?
-
死锁:多个线程都无法获得资源继续执行。可以通过避免一个线程获取多个锁;一个锁占用一个资源;使用定时锁;数据库加解锁在一个连接中。
-
死锁的必要条件:环路等待,不可剥夺,请求保持,互斥条件
-
活锁:线程之间相互谦让资源,都无法获取所有资源继续执行。
Java中CyclicBarrier 和 CountDownLatch有什么不同?
CyclicBarrier 和 CountDownLatch 都可以用来让一组线程等待其它线程。与 CyclicBarrier 不同的是,CountdownLatch 不能重新使用。
-
CountDownLatch是一种灵活的闭锁实现,可以使一个或者多个线程等待一组事件发生。闭锁状态包括一个计数器,改计数器初始化为一个正数,表示需要等待的事件数量。countDown方法递减计数器,表示有一个事件发生了,而await方法等待计数器到达0,表示所有需要等待的事情都已经发生。如果计数器的值非零,那么await就会一直阻塞知道计数器的值为0,或者等待的线程中断,或者等待超时。
-
CyclicBarrier适用于这样的情况:你希望创建一组任务,他们并行地执行工作,然后在进行下一个步骤之前等待,直至所有任务都完成。它使得所有的并行任务都将在栅栏出列队,因此可以一致的向前移动。这非常像CountDownLatch,只是CountDownLatch是只触发一次的事件,而CyclicBarrier可以多次重用。
Java中的同步集合与并发集合有什么区别?
-
同步集合与并发集合都为多线程和并发提供了合适的线程安全的集合,不过并发集合的可扩展性更高。在Java1.5之前程序员们只有同步集合来用且在多线程并发的时候会导致争用,阻碍了系统的扩展性。Java5介绍了并发集合像ConcurrentHashMap,不仅提供线程安全还用锁分离和内部分区等现代技术提高了可扩展性。
-
同步容器是线程安全的。同步容器将所有对容器状态的访问都串行化,以实现他们的线程安全性。这种方法的代价是严重降低并发性,当多个线程竞争容器的锁时,吞吐量将严重降低。并发容器是针对多个线程并发访问设计的,改进了同步容器的性能。通过并发容器来代替同步容器,可以极大地提高伸缩性并降低风险。
你如何在Java中获取线程堆栈?
对于不同的操作系统,有多种方法来获得Java进程的线程堆栈。当你获取线程堆栈时,JVM会把所有线程的状态存到日志文件或者输出到控制台。在Windows你可以使用Ctrl + Break组合键来获取线程堆栈,Linux下用kill -3命令。你也可以用jstack这个工具来获取,它对线程id进行操作,你可以用jps这个工具找到id。
ava中ConcurrentHashMap的并发度是什么?
-
ConcurrentHashMap把实际map划分成若干部分来实现它的可扩展性和线程安全。这种划分是使用并发度获得的,它是ConcurrentHashMap类构造函数的一个可选参数,默认值为16,这样在多线程情况下就能避免争用。
-
并发度可以理解为程序运行时能够同时更新ConccurentHashMap且不产生锁竞争的最大线程数,实际上就是ConcurrentHashMap中的分段锁个数,即Segment[]的数组长度。ConcurrentHashMap默认的并发度为16,但用户也可以在构造函数中设置并发度。当用户设置并发度时,ConcurrentHashMap会使用大于等于该值的最小2幂指数作为实际并发度(假如用户设置并发度为17,实际并发度则为32)。运行时通过将key的高n位(n = 32 – segmentShift)和并发度减1(segmentMask)做位与运算定位到所在的Segment。segmentShift与segmentMask都是在构造过程中根据concurrency level被相应的计算出来。
-
如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个Segment内的访问会扩散到不同的Segment中,CPU cache命中率会下降,从而引起程序性能下降。
Java中的同步集合与并发集合有什么区别?
-
同步集合与并发集合都为多线程和并发提供了合适的线程安全的集合,不过并发集合的可扩展性更高。在Java1.5之前程序员们只有同步集合来用且在多线程并发的时候会导致争用,阻碍了系统的扩展性。Java5介绍了并发集合像ConcurrentHashMap,不仅提供线程安全还用锁分离和内部分区等现代技术提高了可扩展性。
-
同步容器是线程安全的。同步容器将所有对容器状态的访问都串行化,以实现他们的线程安全性。这种方法的代价是严重降低并发性,当多个线程竞争容器的锁时,吞吐量将严重降低。并发容器是针对多个线程并发访问设计的,改进了同步容器的性能。通过并发容器来代替同步容器,可以极大地提高伸缩性并降低风险。
对守护线程的理解
守护线程:为所有非守护线程提供服务的线程;任何一个守护线程都是整个JVM中所有非守护线程的保 姆;
守护线程类似于整个进程的一个默默无闻的小喽喽;它的生死无关重要,它却依赖整个进程而运行;哪 天其他线程结束了,没有要执行的了,程序就结束了,理都没理守护线程,就把它中断了;
注意: 由于守护线程的终止是自身无法控制的,因此千万不要把IO、File等重要操作逻辑分配给它;因 为它不靠谱;
守护线程的作用是什么?
-
举例, GC垃圾回收线程:就是一个经典的守护线程,当我们的程序中不再有任何运行的Thread,程序就 不会再产生垃圾,垃圾回收器也就无事可做,所以当垃圾回收线程是JVM上仅剩的线程时,垃圾回收线 程会自动离开。它始终在低级别的状态中运行,用于实时监控和管理系统中的可回收资源。
应用场景:
-
来为其它线程提供服务支持的情况;
-
或者在任何情况下,程序结束时,这个线 程必须正常且立刻关闭,就可以作为守护线程来使用;反之,如果一个正在执行某个操作的线程必须要 正确地关闭掉否则就会出现不好的后果的话,那么这个线程就不能是守护线程,而是用户线程。通常都 是些关键的事务,比方说,数据库录入或者更新,这些操作都是不能中断的。
thread.setDaemon(true)必须在thread.start()之前设置,否则会跑出一个 IllegalThreadStateException异常。你不能把正在运行的常规线程设置为守护线程。
在Daemon线程中产生的新线程也是Daemon的。 守护线程不能用于去访问固有资源,比如读写操作或者计算逻辑。因为它会在任何时候甚至在一个操作 的中间发生中断。
Java自带的多线程框架,比如ExecutorService,会将守护线程转换为用户线程,所以如果要使用后台线 程就不能用Java的线程池。
Thread类中的yield方法有什么作用?
-
Yield方法可以暂停当前正在执行的线程对象,让其它有相同优先级的线程执行。它是一个静态方法而且只保证当前线程放弃CPU占用而不能保证使其它线程一定能占用CPU,执行yield()的线程有可能在进入到暂停状态后马上又被执行。
-
线程让步:如果知道已经完成了在run()方法的循环的一次迭代过程中所需的工作,就可以给线程调度机制一个暗示:你的工作已经做得差不多了,可以让别的线程使用CPU了。这个暗示将通过调用yield()方法来做出(不过这只是一个暗示,没有任何机制保证它将会被采纳)。当调用yield()时,也是在建议具有相同优先级的其他线程可以运行。
-
yield()的作用是让步。它能让当前线程由“运行状态”进入到“就绪状态”,从而让其它具有相同优先级的等待线程获取执行权;但是,并不能保证在当前线程调用yield()之后,其它具有相同优先级的线程就一定能获得执行权;也有可能是当前线程又进入到“运行状态”继续运行!
对线程安全的理解
不是线程安全、应该是内存安全,堆是共享内存,可以被所有线程访问
-
当多个线程访问一个对象时,如果不用进行额外的同步控制或其他的协调操作,调用这个对象的行为都可以获 得正确的结果,我们就说这个对象是线程安全的
堆
-
是进程和线程共有的空间,分全局堆和局部堆。全局堆就是所有没有分配的空间,局部堆就是用户分 配的空间。堆在操作系统对进程初始化的时候分配,运行过程中也可以向系统要额外的堆,但是用完了 要还给操作系统,要不然就是内存泄漏。
-
在Java中,堆是Java虚拟机所管理的内存中最大的一块,是所有线程共享的一块内存区域,在虚 拟机启动时创建。堆所存在的内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及 数组都在这里分配内存。
栈
-
是每个线程独有的,保存其运行状态和局部自动变量的。栈在线程开始的时候初始化,每个线程的栈 互相独立,因此,栈是线程安全的。操作系统在切换线程的时候会自动切换栈。栈空间不需要在高级语 言里面显式的分配和释放。
目前主流操作系统都是多任务的,即多个进程同时运行。为了保证安全,每个进程只能访问分配给自己 的内存空间,而不能访问别的进程的,这是由操作系统保障的。
在每个进程的内存空间中都会有一块特殊的公共区域,通常称为堆(内存)。进程内的所有线程都可以 访问到该区域,这就是造成问题的潜在原因。
什么是ThreadLocal变量?
ThreadLocal是Java里一种特殊的变量。每个线程都有一个ThreadLocal就是每个线程都拥有了自己独立的一个变量,竞争条件被彻底消除了。它是为创建代价高昂的对象获取线程安全的好方法,比如你可以用ThreadLocal让SimpleDateFormat变成线程安全的,因为那个类创建代价高昂且每次调用都需要创建不同的实例所以不值得在局部范围使用它,如果为每个线程提供一个自己独有的变量拷贝,将大大提高效率。首先,通过复用减少了代价高昂的对象的创建个数。其次,你在没有使用高代价的同步或者不变性的情况下获得了线程安全。线程局部变量的另一个不错的例子是ThreadLocalRandom类,它在多线程环境中减少了创建代价高昂的Random对象的个数。
ThreadLocal是一种线程封闭技术。ThreadLocal提供了get和set等访问接口或方法,这些方法为每个使用该变量的线程都存有一份独立的副本,因此get总是返回由当前执行线程在调用set时设置的最新值。
ThreadLocal原理和使用场景
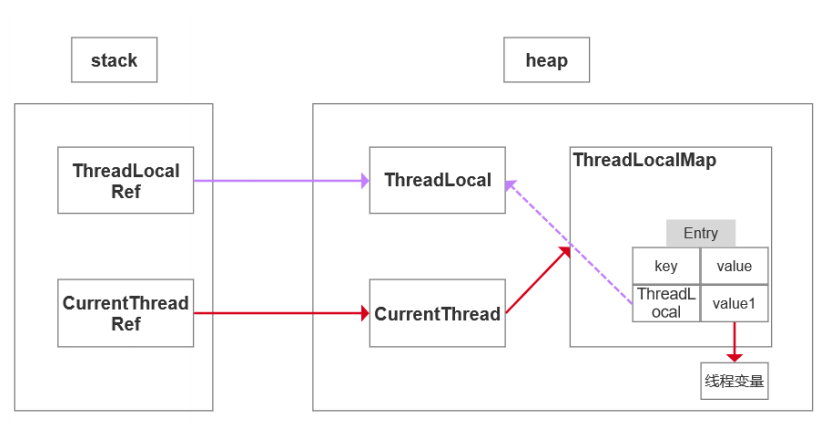
每一个 Thread 对象均含有一个 ThreadLocalMap 类型的成员变量 threadLocals ,它存储本线程中所 有ThreadLocal对象及其对应的值
ThreadLocalMap 由一个个 Entry 对象构成
Entry 继承自 WeakReference> ,一个 Entry 由 ThreadLocal 对象和 Object 构 成。由此可见, Entry 的key是ThreadLocal对象,并且是一个弱引用。当没指向key的强引用后,该 key就会被垃圾收集器回收
当执行set方法时,ThreadLocal首先会获取当前线程对象,然后获取当前线程的ThreadLocalMap对 象。再以当前ThreadLocal对象为key,将值存储进ThreadLocalMap对象中。
get方法执行过程类似。ThreadLocal首先会获取当前线程对象,然后获取当前线程的ThreadLocalMap 对象。再以当前ThreadLocal对象为key,获取对应的value。
由于每一条线程均含有各自私有的ThreadLocalMap容器,这些容器相互独立互不影响,因此不会存在 线程安全性问题,从而也无需使用同步机制来保证多条线程访问容器的互斥性。
使用场景
-
在进行对象跨层传递的时候,使用ThreadLocal可以避免多次传递,打破层次间的约束。
-
线程间数据隔离
-
进行事务操作,用于存储线程事务信息
-
数据库连接,Session会话管理。
-
Spring框架在事务开始时会给当前线程绑定一个Jdbc Connection,在整个事务过程都是使用该线程绑定的 connection来执行数据库操作,实现了事务的隔离性。Spring框架里面就是用的ThreadLocal来实现这种 隔离
-
Java内存模型是什么?
Java内存模型规定和指引Java程序在不同的内存架构、CPU和操作系统间有确定性地行为。它在多线程的情况下尤其重要。Java内存模型对一个线程所做的变动能被其它线程可见提供了保证,它们之间是先行发生关系。这个关系定义了一些规则让程序员在并发编程时思路更清晰。比如,先行发生关系确保了:
-
线程内的代码能够按先后顺序执行,这被称为程序次序规则。
-
对于同一个锁,一个解锁操作一定要发生在时间上后发生的另一个锁定操作之前,也叫做管程锁定规则。
-
前一个对volatile的写操作在后一个volatile的读操作之前,也叫volatile变量规则。
-
一个线程内的任何操作必需在这个线程的start()调用之后,也叫作线程启动规则。
-
一个线程的所有操作都会在线程终止之前,线程终止规则。
-
一个对象的终结操作必需在这个对象构造完成之后,也叫对象终结规则。
-
可传递性
我强烈建议大家阅读《Java并发编程实践》第十六章来加深对Java内存模型的理解。
Java中的volatile 变量是什么?
volatile是一个特殊的修饰符,只有成员变量才能使用它。在Java并发程序缺少同步类的情况下,多线程对成员变量的操作对其它线程是透明的。volatile变量可以保证下一个读取操作会在前一个写操作之后发生,就是上一题的volatile变量规则。
Java语言提供了一种稍弱的同步机制,即volatile变量,用来确保将变量的更新操作通知到其他线程。当把变量声明为volatile类型后,编译器和运行时都会注意到这个变量是共享的,因此不会将变量上的操作和其他内存操作一起重排序。volatile变量不会被缓存在寄存器或者对其他处理器不可见的地方,因此在读取volatile类型的时候总会返回最新写入的值。
在访问volatile变量时不会执行加锁操作,因此也不会使执行线程阻塞,因此volatile变量是一种比synchronized关键字更轻量级的同步机制。
加锁机制既可以确保可见性又可以确保原子性,而volatile变量只能确保可见性。
-
保证被volatile修饰的共享变量对所有线程总是可见的,也就是当一个线程修改了一个被volatile修 饰共享变量的值,新值总是可以被其他线程立即得知。
//线程1
boolean stop = false;
while(!stop){
doSomething();
}
//线程2
stop = true;如果线程2改变了stop的值,线程1一定会停止吗?不一定。当线程2更改了stop变量的值之后,但 是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的 更改,因此还会一直循环下去。
-
禁止指令重排序优化。
int a = 0;
bool flag = false;
public void write() {
a = 2;
//1
flag = true;
//2
}
public void multiply() {
if (flag) { //3
int ret = a * a;//4
}
}
write方法里的1和2做了重排序,线程1先对flag赋值为true,随后执行到线程2,ret直接计算出结果, 再到线程1,这时候a才赋值为2,很明显迟了一步。
但是用volatile修饰之后就变得不一样了
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存 行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主 存读取。
inc++; 其实是两个步骤,先加加,然后再赋值。不是原子性操作,所以volatile不能保证线程安全
volatile 变量和 atomic 变量有什么不同?
这是个有趣的问题。首先,volatile 变量和 atomic 变量看起来很像,但功能却不一样。Volatile变量可以确保先行关系,即写操作会发生在后续的读操作之前, 但它并不能保证原子性。例如用volatile修饰count变量那么 count++ 操作就不是原子性的。而AtomicInteger类提供的atomic方法可以让这种操作具有原子性如getAndIncrement()方法会原子性的进行增量操作把当前值加一,其它数据类型和引用变量也可以进行相似操作。
Java中Runnable和Callable有什么不同?
-
Runnable和Callable都代表那些要在不同的线程中执行的任务。Runnable从JDK1.0开始就有了,Callable是在JDK1.5增加的。它们的主要区别是Callable的 call() 方法可以返回值和抛出异常,而Runnable的run()方法没有这些功能。Callable可以返回装载有计算结果的Future对象。
-
Runnable是执行工作的独立任务,但是它不返回任何值。如果希望任务在完成的时候能够返回一个值,那么可以实现Callable接口而不是Runnable接口。在Java SE5中引入的Callable是一种具有类型参数的泛型,它的类型参数表示的是从方法call()(而不是run())中返回的值,并且必须使用ExecutorService.submit()方法调用它。submit()方法会产生Future对象,它用Callable返回结果的特定类型进行了参数化。
哪些操作释放锁,哪些不释放锁?
-
sleep(): 释放资源,不释放锁,进入阻塞状态,唤醒随机线程,Thread类方法。
-
wait(): 释放资源,释放锁,Object类方法。
-
yield(): 不释放锁,进入可执行状态,选择优先级高的线程执行,Thread类方法。
-
如果线程产生的异常没有被捕获,会释放锁。
如何正确的终止线程?
-
使用共享变量,要用volatile关键字,保证可见性,能够及时终止。
-
使用interrupt()和isInterrupted()配合使用。
interrupt(), interrupted(), isInterrupted()的区别?
-
interrupt():设置中断标志;
-
interrupted():响应中断标志并复位中断标志;
-
isInterrupted():响应中断标志;
synchronized的锁对象是哪些?
-
普通方法是当前实例对象;
-
同步方法快是括号中配置内容,可以是类Class对象,可以是实例对象;
-
静态方法是当前类Class对象。
-
只要不是同一个锁,就可以并行执行,同一个锁,只能串行执行。
-
更多参考我的文章
volatile和synchronized的区别是什么?
-
volatile只能使用在变量上;而synchronized可以在类,变量,方法和代码块上。
-
volatile至保证可见性;synchronized保证原子性与可见性。
-
volatile禁用指令重排序;synchronized不会。
-
volatile不会造成阻塞;synchronized会。
什么是缓存一致性协议?
因为CPU是运算很快,而主存的读写很忙,所以在程序运行中,会复制一份数据到高速缓存,处理完成在将结果保存主存.
这样存在一些问题,在多核CPU中多个线程,多个线程拷贝多份的高速缓存数据,最后在计算完成,刷到主存的数据就会出现覆盖
所以就出现了缓存一致性协议。最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
Synchronized关键字、Lock,并解释它们之间的区别?
Synchronized 与Lock都是可重入锁,同一个线程再次进入同步代码的时候.可以使用自己已经获取到的锁
Synchronized是悲观锁机制,独占锁。而Locks.ReentrantLock是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。ReentrantLock适用场景
某个线程在等待一个锁的控制权的这段时间需要中断
需要分开处理一些wait-notify,ReentrantLock里面的Condition应用,能够控制notify哪个线程,锁可以绑定多个条件。
具有公平锁功能,每个到来的线程都将排队等候。
Volatile如何保证内存可见性?
-
当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存。
-
当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
Java中什么是竞态条件?
竞态条件会导致程序在并发情况下出现一些bugs。多线程对一些资源的竞争的时候就会产生竞态条件,如果首先要执行的程序竞争失败排到后面执行了,那么整个程序就会出现一些不确定的bugs。这种bugs很难发现而且会重复出现,因为线程间的随机竞争。
为什么wait, notify 和 notifyAll这些方法不在thread类里面?
明显的原因是JAVA提供的锁是对象级的而不是线程级的,每个对象都有锁,通过线程获得。如果线程需要等待某些锁那么调用对象中的wait()方法就有意义了。如果wait()方法定义在Thread类中,线程正在等待的是哪个锁就不明显了。简单的说,由于wait,notify和notifyAll都是锁级别的操作,所以把他们定义在Object类中因为锁属于对象。
32、Java中synchronized 和 ReentrantLock 有什么不同?
相似点:
这两种同步方式有很多相似之处,它们都是加锁方式同步,而且都是阻塞式的同步,也就是说当如果一个线程获得了对象锁,进入了同步块,其他访问该同步块的线程都必须阻塞在同步块外面等待,而进行线程阻塞和唤醒的代价是比较高的.
区别:
这两种方式最大区别就是对于Synchronized来说,它是java语言的关键字,是原生语法层面的互斥,需要jvm实现。而ReentrantLock它是JDK 1.5之后提供的API层面的互斥锁,需要lock()和unlock()方法配合try/finally语句块来完成。
Synchronized进过编译,会在同步块的前后分别形成monitorenter和monitorexit这个两个字节码指令。在执行monitorenter指令时,首先要尝试获取对象锁。如果这个对象没被锁定,或者当前线程已经拥有了那个对象锁,把锁的计算器加1,相应的,在执行monitorexit指令时会将锁计算器就减1,当计算器为0时,锁就被释放了。如果获取对象锁失败,那当前线程就要阻塞,直到对象锁被另一个线程释放为止。
由于ReentrantLock是java.util.concurrent包下提供的一套互斥锁,相比Synchronized,ReentrantLock类提供了一些高级功能,主要有以下3项:
-
等待可中断,持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待,这相当于Synchronized来说可以避免出现死锁的情况。
-
公平锁,多个线程等待同一个锁时,必须按照申请锁的时间顺序获得锁,Synchronized锁非公平锁,ReentrantLock默认的构造函数是创建的非公平锁,可以通过参数true设为公平锁,但公平锁表现的性能不是很好。
-
锁绑定多个条件,一个ReentrantLock对象可以同时绑定对个对象。
33、Synchronized 用过吗,其原理是什么?
这是一道 Java 面试中几乎百分百会问到的问题,因为只要是程序员就一定会通过或者接触过Synchronized。
答:Synchronized 是由 JVM 实现的一种实现互斥同步的一种方式,如果 你查看被 Synchronized 修饰过的程序块编译后的字节码,会发现, 被 Synchronized 修饰过的程序块,在编译前后被编译器生成了monitorenter 和 monitorexit 两 个 字 节 码 指 令 。
这两个指令是什么意思呢?
在虚拟机执行到 monitorenter 指令时,首先要尝试获取对象的锁: 如果这个对象没有锁定,或者当前线程已经拥有了这个对象的锁,把锁 的计数器 +1;当执行 monitorexit 指令时将锁计数器 -1;当计数器 为 0 时,锁就被释放了。如果获取对象失败了,那当前线程就要阻塞等待,直到对象锁被另外一 个线程释放为止。
Java 中 Synchronize 通过在对象头设置标记,达到了获取锁和释放 锁的目的。
34、上面提到获取对象的锁,这个“锁”到底是什么?如何确定对象的锁?
答:“锁”的本质其实是 monitorenter 和 monitorexit 字节码指令的一 个 Reference 类型的参数,即要锁定和解锁的对象。我们知道,使用Synchronized 可以修饰不同的对象,因此,对应的对象锁可以这么确 定:
\1. 如果 Synchronized 明确指定了锁对象,比如 Synchronized(变量 名)、Synchronized(this) 等,说明加解锁对象为该对象。
\2. 如果没有明确指定:
-
若 Synchronized 修饰的方法为非静态方法,表示此方法对应的对象为 锁对象;
-
若 Synchronized 修饰的方法为静态方法,则表示此方法对应的类对象 为锁对象。
注意,当一个对象被锁住时,对象里面所有用 Synchronized 修饰的 方法都将产生堵塞,而对象里非 Synchronized 修饰的方法可正常被 调用,不受锁影响。
35、什么是可重入性,为什么说 Synchronized 是可重入锁?
先来看一下维基百科关于可重入锁的定义:
若一个程序或子程序可以“在任意时刻被中断然后操作系统调度执行另外一段代码,这段代码又调用了该子程序不会出错”,则称其为可重入(reentrant或re-entrant)的。即当该子程序正在运行时,执行线程可以再次进入并执行它,仍然获得符合设计时预期的结果。与多线程并发执行的线程安全不同,可重入强调对单个线程执行时重新进入同一个子程序仍然是安全的。
通俗来说:当线程请求一个由其它线程持有的对象锁时,该线程会阻塞,而当线程请求由自己持有的对象锁时,如果该锁是重入锁,请求就会成功,否则阻塞。
要证明synchronized是不是可重入锁,我们先来看一段代码:
package com.mzc.common.concurrent.synchronize;
/**
* <p class="detail">
* 功能: 证明synchronized为什么是可重入锁
* </p>
*
* @author Moore
* @ClassName Super class.
* @Version V1.0.
* @date 2020.02.07 15:34:12
*/
public class SuperClass {
public synchronized void doSomething(){
System.out.println("father is doing something,the thread name is:"+Thread.currentThread().getName());
}
}
package com.mzc.common.concurrent.synchronize;
/**
* <p class="detail">
* 功能: 证明synchronized为什么是可重入锁
* </p>
*
* @author Moore
* @ClassName Sub class.
* @Version V1.0.
* @date 2020.02.07 15:34:41
*/
public class SubClass extends SuperClass {
public synchronized void doSomething() {
System.out.println("child is doing doSomething,the thread name is:" + Thread.currentThread().getName());
// 调用自己类中其他的synchronized方法
doAnotherThing();
}
private synchronized void doAnotherThing() {
// 调用父类的synchronized方法
super.doSomething();
System.out.println("child is doing anotherThing,the thread name is:" + Thread.currentThread().getName());
}
public static void main(String[] args) {
SubClass child = new SubClass();
child.doSomething();
}
}
通过运行main方法,先一下结果:
child is doing doSomething,the thread name is:main
father is doing something,the thread name is:main
child is doing anotherThing,the thread name is:main
因为这些方法输出了相同的线程名称,表明即使递归使用synchronized也没有发生死锁,证明其是可重入的。
还看不懂?那我就再解释下!
这里的对象锁只有一个,就是 child 对象的锁,当执行 child.doSomething 时,该线程获得 child 对象的锁,在 doSomething 方法内执行 doAnotherThing 时再次请求child对象的锁,因为synchronized 是重入锁,所以可以得到该锁,继续在 doAnotherThing 里执行父类的 doSomething 方法时第三次请求 child 对象的锁,同样可得到。如果不是重入锁的话,那这后面这两次请求锁将会被一直阻塞,从而导致死锁。
所以在 java 内部,同一线程在调用自己类中其他 synchronized 方法/块或调用父类的 synchronized 方法/块都不会阻碍该线程的执行。就是说同一线程对同一个对象锁是可重入的,而且同一个线程可以获取同一把锁多次,也就是可以多次重入。因为java线程是基于“每线程(per-thread)”,而不是基于“每调用(per-invocation)”的(java中线程获得对象锁的操作是以线程为粒度的,per-invocation 互斥体获得对象锁的操作是以每调用作为粒度的)。
重入锁实现可重入性原理或机制是:每一个锁关联一个线程持有者和计数器,当计数器为 0 时表示该锁没有被任何线程持有,那么任何线程都可能获得该锁而调用相应的方法;当某一线程请求成功后,JVM会记下锁的持有线程,并且将计数器置为 1;此时其它线程请求该锁,则必须等待;而该持有锁的线程如果再次请求这个锁,就可以再次拿到这个锁,同时计数器会递增;当线程退出同步代码块时,计数器会递减,如果计数器为 0,则释放该锁。
36、JVM 对 Java 的原生锁做了哪些优化?
在 Java 6 之前,Monitor 的实现完全依赖底层操作系统的互斥锁来 实现,也就是我们刚才在问题二中所阐述的获取/释放锁的逻辑。
由于 Java 层面的线程与操作系统的原生线程有映射关系,如果要将一 个线程进行阻塞或唤起都需要操作系统的协助,这就需要从用户态切换 到内核态来执行,这种切换代价十分昂贵,很耗处理器时间,现代 JDK中做了大量的优化。一种优化是使用自旋锁,即在把线程进行阻塞操作之前先让线程自旋等待一段时间,可能在等待期间其他线程已经解锁,这时就无需再让线程 执行阻塞操作,避免了用户态到内核态的切换。
现代 JDK 中还提供了三种不同的 Monitor 实现,也就是三种不同的锁:
-
偏向锁(Biased Locking)
-
轻量级锁
-
重量级锁
这三种锁使得 JDK 得以优化 Synchronized 的运行,当 JVM 检测 到不同的竞争状况时,会自动切换到适合的锁实现,这就是锁的升级、 降级。
-
当没有竞争出现时,默认会使用偏向锁。
JVM 会利用 CAS 操作,在对象头上的 Mark Word 部分设置线程ID,以表示这个对象偏向于当前线程,所以并不涉及真正的互斥锁,因 为在很多应用场景中,大部分对象生命周期中最多会被一个线程锁定, 使用偏斜锁可以降低无竞争开销。
-
如果有另一线程试图锁定某个被偏斜过的对象,JVM 就撤销偏斜锁, 切换到轻量级锁实现。
-
轻量级锁依赖 CAS 操作 Mark Word 来试图获取锁,如果重试成功, 就使用普通的轻量级锁;否则,进一步升级为重量级锁。
37、为什么说 Synchronized 是非公平锁?
答:非公平主要表现在获取锁的行为上,并非是按照申请锁的时间前后给等 待线程分配锁的,每当锁被释放后,任何一个线程都有机会竞争到锁, 这样做的目的是为了提高执行性能,缺点是可能会产生线程饥饿现象。
38、为什么说 Synchronized 是一个悲观锁?乐观锁的实现原理 又是什么?什么是 CAS,它有什么特性?
答:Synchronized 显然是一个悲观锁,因为它的并发策略是悲观的:不管是否会产生竞争,任何的数据操作都必须要加锁、用户态核心态转 换、维护锁计数器和检查是否有被阻塞的线程需要被唤醒等操作。
随着硬件指令集的发展,我们可以使用基于冲突检测的乐观并发策略。先进行操作,如果没有其他线程征用数据,那操作就成功了; 如果共享数据有征用,产生了冲突,那就再进行其他的补偿措施。这种 乐观的并发策略的许多实现不需要线程挂起,所以被称为非阻塞同步。
乐观锁的核心算法是 CAS(Compareand Swap,比较并交换),它涉 及到三个操作数:内存值、预期值、新值。当且仅当预期值和内存值相 等时才将内存值修改为新值。这样处理的逻辑是,首先检查某块内存的值是否跟之前我读取时的一 样,如不一样则表示期间此内存值已经被别的线程更改过,舍弃本次操 作,否则说明期间没有其他线程对此内存值操作,可以把新值设置给此 块内存。
CAS 具有原子性,它的原子性由CPU 硬件指令实现保证,即使用JNI 调用 Native 方法调用由 C++ 编写的硬件级别指令,JDK 中提 供了 Unsafe 类执行这些操作。
39、乐观锁一定就是好的吗?
答:乐观锁避免了悲观锁独占对象的现象,同时也提高了并发性能,但它也 有缺点:
-
乐观锁只能保证一个共享变量的原子操作。如果多一个或几个变量,乐 观锁将变得力不从心,但互斥锁能轻易解决,不管对象数量多少及对象 颗粒度大小。
-
长时间自旋可能导致开销大。假如 CAS 长时间不成功而一直自旋,会 给 CPU 带来很大的开销。
-
ABA 问题。CAS 的核心思想是通过比对内存值与预期值是否一样而判 断内存值是否被改过,但这个判断逻辑不严谨,假如内存值原来是 A, 后来被一条线程改为 B,最后又被改成了 A,则 CAS 认为此内存值并 没有发生改变,但实际上是有被其他线程改过的,这种情况对依赖过程 值的情景的运算结果影响很大。解决的思路是引入版本号,每次变量更新都把版本号加一。
40、谈一谈AQS框架。
AQS(AbstractQueuedSynchronizer 类)是一个用来构建锁和同步器 的框架,各种Lock 包中的锁(常用的有 ReentrantLock、 ReadWriteLock) , 以 及 其 他 如 Semaphore、 CountDownLatch, 甚 至是早期的 FutureTask 等,都是基于 AQS 来构建。
-
AQS 在内部定义了一个 volatile int state 变量,表示同步状态:当线 程调用 lock 方法时 ,如果 state=0,说明没有任何线程占有共享资源 的锁,可以获得锁并将 state=1;如果 state=1,则说明有线程目前正在 使用共享变量,其他线程必须加入同步队列进行等待。
-
AQS 通过 Node 内部类构成的一个双向链表结构的同步队列,来完成线 程获取锁的排队工作,当有线程获取锁失败后,就被添加到队列末尾。
Node 类是对要访问同步代码的线程的封装,包含了线程本身及其状态叫waitStatus(有五种不同 取值,分别表示是否被阻塞,是否等待唤醒, 是否已经被取消等),每个 Node 结点关联其 prev 结点和 next 结 点,方便线程释放锁后快速唤醒下一个在等待的线程,是一个 FIFO 的过 程。
Node 类有两个常量,SHARED 和 EXCLUSIVE,分别代表共享模式和独 占模式。所谓共享模式是一个锁允许多条线程同时操作(信号量Semaphore 就是基于 AQS 的共享模式实现的),独占模式是同一个时 间段只能有一个线程对共享资源进行操作,多余的请求线程需要排队等待 ( 如 ReentranLock) 。
-
AQS 通过内部类 ConditionObject 构建等待队列(可有多个),当Condition 调用 wait() 方法后,线程将会加入等待队列中,而当Condition 调用 signal() 方法后,线程将从等待队列转移动同步队列中进行锁竞争。
-
AQS 和 Condition 各自维护了不同的队列,在使用 Lock 和Condition 的时候,其实就是两个队列的互相移动。
41、ReentrantLock 是如何实现可重入性的?
答:ReentrantLock 内部自定义了同步器 Sync(Sync 既实现了 AQS, 又实现了 AOS,而 AOS 提供了一种互斥锁持有的方式),其实就是 加锁的时候通过 CAS 算法,将线程对象放到一个双向链表中,每次获 取锁的时候,看下当前维护的那个线程 ID 和当前请求的线程 ID 是否 一样,一样就可重入了。
42、Java中Semaphore是什么?
Java中的Semaphore是一种新的同步类,它是一个计数信号。从概念上讲,从概念上讲,信号量维护了一个许可集合。如有必要,在许可可用前会阻塞每一个 acquire(),然后再获取该许可。每个 release()添加一个许可,从而可能释放一个正在阻塞的获取者。但是,不使用实际的许可对象,Semaphore只对可用许可的号码进行计数,并采取相应的行动。信号量常常用于多线程的代码中,比如数据库连接池。
package com.mzc.common.concurrent;
import java.util.concurrent.Semaphore;
/**
* <p class="detail">
* 功能: Semaphore Test
* </p>
*
* @author Moore
* @ClassName Test semaphore.
* @Version V1.0.
* @date 2020.02.07 20:11:00
*/
public class TestSemaphore {
static class Worker extends Thread{
private int num;
private Semaphore semaphore;
public Worker(int num,Semaphore semaphore){
this.num = num;
this.semaphore = semaphore;
}
@Override
public void run() {
try {
// 抢许可
semaphore.acquire();
Thread.sleep(2000);
// 释放许可
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
// 机器数目,即5个许可
Semaphore semaphore = new Semaphore(5);
// 8个线程去抢许可
for (int i = 0; i < 8; i++){
new Worker(i,semaphore).start();
}
}
}
43、Java 中的线程池是如何实现的?
-
在 Java 中,所谓的线程池中的“线程”,其实是被抽象为了一个静态 内部类 Worker,它基于 AQS 实现,存放在线程池的HashSet<Worker> workers 成员变量中;
-
而需要执行的任务则存放在成员变量 workQueue(BlockingQueue<Runnable> workQueue)中。这样,整个线程池实现的基本思想就是:从 workQueue 中不断取出 需要执行的任务,放在 Workers 中进行处理。
44、线程池中的线程是怎么创建的?是一开始就随着线程池的启动创建好的吗?
答:显然不是的。线程池默认初始化后不启动 Worker,等待有请求时才启动。每当我们调用 execute() 方法添加一个任务时,线程池会做如下判 断:
-
如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
-
如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列;
-
如果这时候队列满了,而且正在运行的线程数量小于maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
-
如果队列满了,而且正在运行的线程数量大于或等于maximumPoolSize,那么线程池会抛出异常RejectExecutionException。
当一个线程完成任务时,它会从队列中取下一个任务来执行。当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断。
如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
45、什么是竞争条件?**如何发现和解决竞争?**
两个线程同步操作同一个对象,使这个对象的最终状态不明——叫做竞争条件。竞争条件可以在任何应该由程序员保证原子操作的,而又忘记使用synchronized的地方。
唯一的解决方案就是加锁。
Java有两种锁可供选择:
-
对象或者类(class)的锁。每一个对象或者类都有一个锁。使用synchronized关键字获取。 synchronized加到static方法上面就使用类锁,加到普通方法上面就用对象锁。除此之外synchronized还可以用于锁定关键区域块(Critical Section)。 synchronized之后要制定一个对象(锁的携带者),并把关键区域用大括号包裹起来。synchronized(this){// critical code}。
-
显示构建的锁(java.util.concurrent.locks.Lock),调用lock的lock方法锁定关键代码。
46、很多人都说要慎用 ThreadLocal,谈谈你的理解,使用ThreadLocal 需要注意些什么?
答:使 用 ThreadLocal 要 注 意 remove!
ThreadLocal 的实现是基于一个所谓的 ThreadLocalMap,在ThreadLocalMap 中,它的 key 是一个弱引用。通常弱引用都会和引用队列配合清理机制使用,但是 ThreadLocal 是 个例外,它并没有这么做。这意味着,废弃项目的回收依赖于显式地触发,否则就要等待线程结 束,进而回收相应 ThreadLocalMap!这就是很多 OOM 的来源,所 以通常都会建议,应用一定要自己负责 remove,并且不要和线程池配 合,因为 worker 线程往往是不会退出的。
参考资料:https://www.cnblogs.com/jxldjsn/p/10872154.html
参考资料:https://www.cnblogs.com/sgh1023/p/10297322.html
参考资料:https://blog.csdn.net/u011780616/article/details/95339236
Spring
spring是什么?
轻量级的开源的J2EE框架。它是一个容器框架,用来装javabean(java对象),中间层框架(万能胶) 可以起一个连接作用,比如说把Struts和hibernate粘合在一起运用,可以让我们的企业开发更快、更简 洁
Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架 --从大小与开销两方面而言Spring都是轻量级的。 --通过控制反转(IoC)的技术达到松耦合的目的 --提供了面向切面编程的丰富支持,允许通过分离应用的业务逻辑与系统级服务进行内聚性的 开发 --包含并管理应用对象(Bean)的配置和生命周期,这个意义上是一个容器。 --将简单的组件配置、组合成为复杂的应用,这个意义上是一个框架。
IOC
-
IOC就是控制反转,是指创建对象的控制权的转移,以前创建对象的主动权和时机是由自己把控的,而现在这种权力转移到Spring容器中,并由容器根据配置文件去创建实例和管理各个实例之间的依赖关系,对象与对象之间松散耦合,也利于功能的复用。DI依赖注入,和控制反转是同一个概念的不同角度的描述,即 应用程序在运行时依赖IoC容器来动态注入对象需要的外部资源。
-
最直观的表达就是,IOC让对象的创建不用去new了,可以由spring自动生产,使用java的反射机制,根据配置文件在运行时动态的去创建对象以及管理对象,并调用对象的方法的。
-
Spring的IOC有三种注入方式 :构造器注入、setter方法注入、根据注解注入。
IoC让相互协作的组件保持松散的耦合,而AOP编程允许你把遍布于应用各层的功能分离出来形成可重用的功能组件。
Spring IOC源码的阅读可以查看:https://javadoop.com/post/spring-ioc
容器概念、控制反转、依赖注入
ioc容器:实际上就是个map(key,value),里面存的是各种对象(在xml里配置的bean节点、 @repository、@service、@controller、@component),在项目启动的时候会读取配置文件里面的 bean节点,根据全限定类名使用反射创建对象放到map里、扫描到打上上述注解的类还是通过反射创 建对象放到map里。
这个时候map里就有各种对象了,接下来我们在代码里需要用到里面的对象时,再通过DI注入 (autowired、resource等注解,xml里bean节点内的ref属性,项目启动的时候会读取xml节点ref属性 根据id注入,也会扫描这些注解,根据类型或id注入;id就是对象名)。
控制反转:
没有引入IOC容器之前,对象A依赖于对象B,那么对象A在初始化或者运行到某一点的时候,自己必须 主动去创建对象B或者使用已经创建的对象B。无论是创建还是使用对象B,控制权都在自己手上。
引入IOC容器之后,对象A与对象B之间失去了直接联系,当对象A运行到需要对象B的时候,IOC容器会 主动创建一个对象B注入到对象A需要的地方。
通过前后的对比,不难看出来:对象A获得依赖对象B的过程,由主动行为变为了被动行为,控制权颠倒 过来了,这就是“控制反转”这个名称的由来。
全部对象的控制权全部上缴给“第三方”IOC容器,所以,IOC容器成了整个系统的关键核心,它起到了一 种类似“粘合剂”的作用,把系统中的所有对象粘合在一起发挥作用,如果没有这个“粘合剂”,对象与对 象之间会彼此失去联系,这就是有人把IOC容器比喻成“粘合剂”的由来。
依赖注入:
“获得依赖对象的过程被反转了”。控制被反转之后,获得依赖对象的过程由自身管理变为了由IOC容器 主动注入。依赖注入是实现IOC的方法,就是由IOC容器在运行期间,动态地将某种依赖关系注入到对 象之中。
如何实现一个IOC容器
-
配置文件配置包扫描路径
-
递归包扫描获取.class文件
-
反射、确定需要交给IOC管理的类
-
对需要注入的类进行依赖注入
-
配置文件中指定需要扫描的包路径
-
定义一些注解,分别表示访问控制层、业务服务层、数据持久层、依赖注入注解、获取配置文件注 解
-
从配置文件中获取需要扫描的包路径,获取到当前路径下的文件信息及文件夹信息,我们将当前路 径下所有以.class结尾的文件添加到一个Set集合中进行存储
-
遍历这个set集合,获取在类上有指定注解的类,并将其交给IOC容器,定义一个安全的Map用来 存储这些对象
-
遍历这个IOC容器,获取到每一个类的实例,判断里面是有有依赖其他的类的实例,然后进行递归 注入
-
AOP的理解
系统是由许多不同的组件所组成的,每一个组件各负责一块特定功能。除了实现自身核心功能之外,这 些组件还经常承担着额外的职责。例如日志、事务管理和安全这样的核心服务经常融入到自身具有核心 业务逻辑的组件中去。这些系统服务经常被称为横切关注点,因为它们会跨越系统的多个组件。
当我们需要为分散的对象引入公共行为的时候,OOP则显得无能为力。也就是说,OOP允许你定义从 上到下的关系,但并不适合定义从左到右的关系。例如日志功能。
日志代码往往水平地散布在所有对象层次中,而与它所散布到的对象的核心功能毫无关系。
在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。
AOP:将程序中的交叉业务逻辑(比如安全,日志,事务等),封装成一个切面,然后注入到目标对象 (具体业务逻辑)中去。AOP可以对某个对象或某些对象的功能进行增强,比如对象中的方法进行增 强,可以在执行某个方法之前额外的做一些事情,在某个方法执行之后额外的做一些事情
OOP面向对象,允许开发者定义纵向的关系,但并适用于定义横向的关系,导致了大量代码的重复,而不利于各个模块的重用。
AOP,一般称为面向切面,作为面向对象的一种补充,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面”(Aspect),减少系统中的重复代码,降低了模块间的耦合度,同时提高了系统的可维护性。可用于权限认证、日志、事务处理。
AOP实现的关键在于 代理模式,AOP代理主要分为静态代理和动态代理。静态代理的代表为AspectJ;动态代理则以Spring AOP为代表。
(1)AspectJ是静态代理的增强,所谓静态代理,就是AOP框架会在编译阶段生成AOP代理类,因此也称为编译时增强,他会在编译阶段将AspectJ(切面)织入到Java字节码中,运行的时候就是增强之后的AOP对象。
(2)Spring AOP使用的动态代理,所谓的动态代理就是说AOP框架不会去修改字节码,而是每次运行时在内存中临时为方法生成一个AOP对象,这个AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法。
Spring AOP中的动态代理主要有两种方式,JDK动态代理和CGLIB动态代理:
①JDK动态代理只提供接口的代理,不支持类的代理。核心InvocationHandler接口和Proxy类,InvocationHandler 通过invoke()方法反射来调用目标类中的代码,动态地将横切逻辑和业务编织在一起;接着,Proxy利用 InvocationHandler动态创建一个符合某一接口的的实例, 生成目标类的代理对象。
②如果代理类没有实现 InvocationHandler 接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成指定类的一个子类对象,并覆盖其中特定方法并添加增强代码,从而实现AOP。CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
(3)静态代理与动态代理区别在于生成AOP代理对象的时机不同,相对来说AspectJ的静态代理方式具有更好的性能,但是AspectJ需要特定的编译器进行处理,而Spring AOP则无需特定的编译器处理。
InvocationHandler 的 invoke(Object proxy,Method method,Object[] args):proxy是最终生成的代理实例; method 是被代理目标实例的某个具体方法; args 是被代理目标实例某个方法的具体入参, 在方法反射调用时使用。
Spring AOP和AspectJ AOP有什么区别?
-
Spring AOP是属于运行时增强,而AspectJ是编译时增强。Spring AOP基于代理(Proxying),而AspectJ基于字节码操作(Bytecode Manipulation)。
-
Spring AOP已经集成了AspectJ,AspectJ应该算得上是Java生态系统中最完整的AOP框架了。AspectJ相比于Spring AOP功能更加强大,但是Spring AOP相对来说更简单。
-
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择AspectJ,它比SpringAOP快很多。
Spring中的bean的作用域有哪些?
-
singleton:唯一bean实例,Spring中的bean默认都是单例的。
-
prototype:每次请求都会创建一个新的bean实例。
-
request:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效。
-
session:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP session内有效。
-
application:bean被定义为在ServletContext的生命周期中复用一个单例对象。
-
websocket:bean被定义为在websocket的生命周期中复用一个单例对象。
-
global-session:全局session作用域,仅仅在基于Portlet的Web应用中才有意义,Spring5中已经没有了。Portlet是能够生成语义代码(例如HTML)片段的小型Java Web插件。它们基于Portlet容器,可以像Servlet一样处理HTTP请求。但是与Servlet不同,每个Portlet都有不同的会话。
@Component和@Bean的区别是什么
-
作用对象不同。@Component注解作用于类,而@Bean注解作用于方法。
-
@Component注解通常是通过类路径扫描来自动侦测以及自动装配到Spring容器中(我们可以使用@ComponentScan注解定义要扫描的路径)。@Bean注解通常是在标有该注解的方法中定义产生这个bean,告诉Spring这是某个类的实例,当我需要用它的时候还给我。
-
@Bean注解比@Component注解的自定义性更强,而且很多地方只能通过@Bean注解来注册bean。比如当引用第三方库的类需要装配到Spring容器的时候,就只能通过@Bean注解来实现。
@Bean注解的使用示例:
@Configuration
public class MzcConfig {
@Bean
public UserService userService() {
return new UserServiceImpl();
}
}
上面的代码相当于下面的XML配置:
<beans>
<bean id="userService" class="com.mazhichu.service.UserServiceImpl"/>
</beans>
Spring事务
Spring事务的实现方式和原理以及隔离级别?
在使用Spring框架时,可以有两种使用事务的方式,一种是编程式的,一种是申明式的, @Transactional注解就是申明式的。
首先,事务这个概念是数据库层面的,Spring只是基于数据库中的事务进行了扩展,以及提供了一些能 让程序员更加方便操作事务的方式。
比如我们可以通过在某个方法上增加@Transactional注解,就可以开启事务,这个方法中所有的sql都 会在一个事务中执行,统一成功或失败。
在一个方法上加了@Transactional注解后,Spring会基于这个类生成一个代理对象,会将这个代理对象 作为bean,当在使用这个代理对象的方法时,如果这个方法上存在@Transactional注解,那么代理逻 辑会先把事务的自动提交设置为false,然后再去执行原本的业务逻辑方法,如果执行业务逻辑方法没有 出现异常,那么代理逻辑中就会将事务进行提交,如果执行业务逻辑方法出现了异常,那么则会将事务 进行回滚。
当然,针对哪些异常回滚事务是可以配置的,可以利用@Transactional注解中的rollbackFor属性进行 配置,默认情况下会对RuntimeException和Error进行回滚。
spring事务隔离级别就是数据库的隔离级别:外加一个默认级别
-
read uncommitted(未提交读)
-
read committed(提交读、不可重复读)
-
repeatable read(可重复读)
-
serializable(可串行化)
数据库的配置隔离级别是Read Commited,而Spring配置的隔离级别是Repeatable Read,请问这时隔离 级别是以哪一个为准?
以Spring配置的为准,如果spring设置的隔离级别数据库不支持,效果取决于数据库
spring事务传播机制
多个事务方法相互调用时,事务如何在这些方法间传播
方法A是一个事务的方法,方法A执行过程中调用了方法B,那么方法B有无事务以及方法B对事务的要求不同都 会对方法A的事务具体执行造成影响,同时方法A的事务对方法B的事务执行也有影响,这种影响具体是什么就 由两个方法所定义的事务传播类型所决定。
REQUIRED(Spring默认的事务传播类型):如果当前没有事务,则自己新建一个事务,如果当前存在事 务,则加入这个事务
-
SUPPORTS:当前存在事务,则加入当前事务,如果当前没有事务,就以非事务方法执行
-
MANDATORY:当前存在事务,则加入当前事务,如果当前事务不存在,则抛出异常。
-
REQUIRES_NEW:创建一个新事务,如果存在当前事务,则挂起该事务。
-
NOT_SUPPORTED:以非事务方式执行,如果当前存在事务,则挂起当前事务
-
NEVER:不使用事务,如果当前事务存在,则抛出异常
-
NESTED:如果当前事务存在,则在嵌套事务中执行,否则
-
REQUIRED的操作一样(开启一个事务)
-
和REQUIRES_NEW的区别 REQUIRES_NEW是新建一个事务并且新开启的这个事务与原有事务无关,而NESTED则是当前存在事务时(我 们把当前事务称之为父事务)会开启一个嵌套事务(称之为一个子事务)。 在NESTED情况下父事务回滚时, 子事务也会回滚,而在REQUIRES_NEW情况下,原有事务回滚,不会影响新开启的事务。
-
和REQUIRED的区别 REQUIRED情况下,调用方存在事务时,则被调用方和调用方使用同一事务,那么被调用方出现异常时,由于 共用一个事务,所以无论调用方是否catch其异常,事务都会回滚 而在NESTED情况下,被调用方发生异常 时,调用方可以catch其异常,这样只有子事务回滚,父事务不受影响
-
spring事务什么时候会失效?
spring事务的原理是AOP,进行了切面增强,那么失效的根本原因是这个AOP不起作用了!常见情况有 如下几种
-
发生自调用,类里面使用this调用本类的方法(this通常省略),此时这个this对象不是代理类,而 是UserService对象本身!
解决方法很简单,让那个this变成UserService的代理类即可!
-
方法不是public的
@Transactional 只能用于 public 的方法上,否则事务不会失效,如果要用在非 public 方法上,可 以开启 AspectJ 代理模式。
-
数据库不支持事务
-
没有被spring管理
-
异常被吃掉,事务不会回滚(或者抛出的异常没有被定义,默认为RuntimeException)
Spring事务管理方式有几种?
-
编程式事务:在代码中硬编码(不推荐使用)。
-
声明式事务:在配置文件中配置(推荐使用),分为基于XML的声明式事务和基于注解的声明式事务。
Spring事务中的隔离级别有哪几种
在TransactionDefinition接口中定义了五个表示隔离级别的常量:
-
ISOLATION_DEFAULT:使用后端数据库默认的隔离级别,Mysql默认采用的REPEATABLE_READ隔离级别;Oracle默认采用的READ_COMMITTED隔离级别。
-
ISOLATION_READ_UNCOMMITTED:最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-
ISOLATION_READ_COMMITTED:允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
-
ISOLATION_REPEATABLE_READ:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
-
ISOLATION_SERIALIZABLE:最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
Spring事务中有哪几种事务传播行为?
在TransactionDefinition接口中定义了八个表示事务传播行为的常量。
1、支持当前事务的情况:
-
PROPAGATION_REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
-
PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
-
PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)。
2、不支持当前事务的情况:
-
PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
-
PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
-
PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
3、其他情况:
-
PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于PROPAGATION_REQUIRED。
Spring设计模式
下面简单举7个常用的设计模式:
-
工厂设计模式:Spring使用工厂模式通过BeanFactory和ApplicationContext创建bean对象。
-
代理设计模式:Spring AOP功能的实现。
-
单例设计模式:Spring中的bean默认都是单例的。
-
模板方法模式:Spring中的jdbcTemplate、hibernateTemplate等以Template结尾的对数据库操作的类,它们就使用到了模板模式。
-
包装器设计模式:我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
-
观察者模式:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。spring中Observer模式常用的地方是listener的实现。如ApplicationListener。
-
适配器模式:Spring AOP的增强或通知(Advice)使用到了适配器模式、Spring MVC中也是用到了适配器模式适配Controller。
简单工厂:由一个工厂类根据传入的参数,动态决定应该创建哪一个产品类。
Spring中的BeanFactory就是简单工厂模式的体现,根据传入一个唯一的标识来获得Bean对象,但是否是 在传入参数后创建还是传入参数前创建这个要根据具体情况来定。
单例模式:保证一个类仅有一个实例,并提供一个访问它的全局访问点
spring对单例的实现: spring中的单例模式完成了后半句话,即提供了全局的访问点BeanFactory。但没 有从构造器级别去控制单例,这是因为spring管理的是任意的java对象。
适配器模式:
Spring定义了一个适配接口,使得每一种Controller有一种对应的适配器实现类,让适配器代替 controller执行相应的方法。这样在扩展Controller时,只需要增加一个适配器类就完成了SpringMVC 的扩展了。
装饰器模式:动态地给一个对象添加一些额外的职责。就增加功能来说,Decorator模式相比生成子类 更为灵活。
Spring中用到的包装器模式在类名上有两种表现:一种是类名中含有Wrapper,另一种是类名中含有 Decorator。
动态代理:
切面在应用运行的时刻被织入。一般情况下,在织入切面时,AOP容器会为目标对象创建动态的创建一个代理 对象。SpringAOP就是以这种方式织入切面的。 织入:把切面应用到目标对象并创建新的代理对象的过程。
观察者模式:
spring的事件驱动模型使用的是 观察者模式 ,Spring中Observer模式常用的地方是listener的实现。
策略模式:
Spring框架的资源访问Resource接口。该接口提供了更强的资源访问能力,Spring 框架本身大量使用了 Resource 接口来访问底层资源。
模板方法:父类定义了骨架(调用哪些方法及顺序),某些特定方法由子类实现。
最大的好处:代码复用,减少重复代码。除了子类要实现的特定方法,其他方法及方法调用顺序都在父 类中预先写好了。
refresh方法
Spring中的单例bean的线程安全问题了解吗?
大部分时候我们并没有在系统中使用多线程,所以很少有人会关注这个问题。单例bean存在线程问题,主要是因为当多个线程操作同一个对象的时候,对这个对象的非静态成员变量的写操作会存在线程安全问题。
有两种常见的解决方案:
1.在bean对象中尽量避免定义可变的成员变量(不太现实)。
2.在类中定义一个ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal中(推荐的一种方式)。
Spring框架中的单例Bean是线程安全的么?
Spring中的Bean默认是单例模式的,框架并没有对bean进行多线程的封装处理。
如果Bean是有状态的 那就需要开发人员自己来进行线程安全的保证,最简单的办法就是改变bean的作 用域 把 "singleton"改为’‘protopyte’ 这样每次请求Bean就相当于是 new Bean() 这样就可以保证线程的 安全了。
-
有状态就是有数据存储功能
-
无状态就是不会保存数据 controller、service和dao层本身并不是线程安全的,只是如果只 是调用里面的方法,而且多线程调用一个实例的方法,会在内存中复制变量,这是自己的线程的工 作内存,是安全的。
Dao会操作数据库Connection,Connection是带有状态的,比如说数据库事务,Spring的事务管理器 使用Threadlocal为不同线程维护了一套独立的connection副本,保证线程之间不会互相影响(Spring 是如何保证事务获取同一个Connection的)
不要在bean中声明任何有状态的实例变量或类变量,如果必须如此,那么就使用ThreadLocal把变量变 为线程私有的,如果bean的实例变量或类变量需要在多个线程之间共享,那么就只能使用 synchronized、lock、CAS等这些实现线程同步的方法了
Spring如何处理线程并发问题?
在一般情况下,只有无状态的Bean才可以在多线程环境下共享,在Spring中,绝大部分Bean都可以声明为singleton作用域,因为Spring对一些Bean中非线程安全状态采用ThreadLocal进行处理,解决线程安全问题。
ThreadLocal和线程同步机制都是为了解决多线程中相同变量的访问冲突问题。同步机制采用了“时间换空间”的方式,仅提供一份变量,不同的线程在访问前需要获取锁,没获得锁的线程则需要排队。而ThreadLocal采用了“空间换时间”的方式。
ThreadLocal会为每一个线程提供一个独立的变量副本,从而隔离了多个线程对数据的访问冲突。因为每一个线程都拥有自己的变量副本,从而也就没有必要对该变量进行同步了。ThreadLocal提供了线程安全的共享对象,在编写多线程代码时,可以把不安全的变量封装进ThreadLocal。
说一说Spring中的bean生命周期?
1、解析类得到BeanDefinition
2、如果有多个构造方法,则要推断构造方法
3、确定好构造方法后,进行实例化得到一个对象
4、对对象中的加了@Autowired注解的属性进行属性填充
5、回调Aware方法,比如BeanNameAware,BeanFactoryAware
6、调用BeanPostProcessor的初始化前的方法
7、调用初始化方法
8、调用BeanPostProcessor的初始化后的方法,在这里会进行AOP
9、如果当前创建的bean是单例的则会把bean放入单例池
10、使用bean
11、Spring容器关闭时调用DisposableBean中destory()方法
1.Bean容器找到配置文件中Spring Bean的定义。
2.Bean容器利用Java Reflection API创建一个Bean的实例。
3.如果涉及到一些属性值,利用set()方法设置一些属性值。
4.如果Bean实现了BeanNameAware接口,调用setBeanName()方法,传入Bean的名字。
5.如果Bean实现了BeanClassLoaderAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。
6.如果Bean实现了BeanFactoryAware接口,调用setBeanClassFacotory()方法,传入ClassLoader对象的实例。
7.与上面的类似,如果实现了其他*Aware接口,就调用相应的方法。
8.如果有和加载这个Bean的Spring容器相关的BeanPostProcessor对象,执行postProcessBeforeInitialization()方法。
9.如果Bean实现了InitializingBean接口,执行afeterPropertiesSet()方法。
10.如果Bean在配置文件中的定义包含init-method属性,执行指定的方法。
11.如果有和加载这个Bean的Spring容器相关的BeanPostProcess对象,执行postProcessAfterInitialization()方法。
12.当要销毁Bean的时候,如果Bean实现了DisposableBean接口,执行destroy()方法。
13.当要销毁Bean的时候,如果Bean在配置文件中的定义包含destroy-method属性,执行指定的方法。
https://www.jianshu.com/p/1dec08d290c1
Spring MVC的主要组件?
Handler:也就是处理器。它直接应对着MVC中的C也就是Controller层,它的具体表现形式有很多,可 以是类,也可以是方法。在Controller层中@RequestMapping标注的所有方法都可以看成是一个 Handler,只要可以实际处理请求就可以是Handler
-
HandlerMapping
initHandlerMappings(context),处理器映射器,根据用户请求的资源uri来查找Handler的。在 SpringMVC中会有很多请求,每个请求都需要一个Handler处理,具体接收到一个请求之后使用哪个 Handler进行,这就是HandlerMapping需要做的事。
-
HandlerAdapter
initHandlerAdapters(context),适配器。因为SpringMVC中的Handler可以是任意的形式,只要能处 理请求就ok,但是Servlet需要的处理方法的结构却是固定的,都是以request和response为参数的方 法。如何让固定的Servlet处理方法调用灵活的Handler来进行处理呢?这就是HandlerAdapter要做的 事情。
Handler是用来干活的工具;HandlerMapping用于根据需要干的活找到相应的工具;HandlerAdapter 是使用工具干活的人。
-
HandlerExceptionResolver
initHandlerExceptionResolvers(context), 其它组件都是用来干活的。在干活的过程中难免会出现问 题,出问题后怎么办呢?这就需要有一个专门的角色对异常情况进行处理,在SpringMVC中就是 HandlerExceptionResolver。具体来说,此组件的作用是根据异常设置ModelAndView,之后再交给 render方法进行渲染。
-
ViewResolver
initViewResolvers(context),ViewResolver用来将String类型的视图名和Locale解析为View类型的视 图。View是用来渲染页面的,也就是将程序返回的参数填入模板里,生成html(也可能是其它类型) 文件。这里就有两个关键问题:使用哪个模板?用什么技术(规则)填入参数?这其实是ViewResolver 主要要做的工作,ViewResolver需要找到渲染所用的模板和所用的技术(也就是视图的类型)进行渲 染,具体的渲染过程则交由不同的视图自己完成。
-
RequestToViewNameTranslator
initRequestToViewNameTranslator(context),ViewResolver是根据ViewName查找View,但有的 Handler处理完后并没有设置View也没有设置ViewName,这时就需要从request获取ViewName了, 如何从request中获取ViewName就是RequestToViewNameTranslator要做的事情了。
RequestToViewNameTranslator在Spring MVC容器里只可以配置一个,所以所有request到 ViewName的转换规则都要在一个Translator里面全部实现。
-
LocaleResolver
initLocaleResolver(context), 解析视图需要两个参数:一是视图名,另一个是Locale。视图名是处理 器返回的,Locale是从哪里来的?这就是LocaleResolver要做的事情。LocaleResolver用于从request 解析出Locale,Locale就是zh-cn之类,表示一个区域,有了这个就可以对不同区域的用户显示不同的 结果。SpringMVC主要有两个地方用到了Locale:一是ViewResolver视图解析的时候;二是用到国际化 资源或者主题的时候。
-
ThemeResolver
initThemeResolver(context),用于解析主题。SpringMVC中一个主题对应一个properties文件,里面 存放着跟当前主题相关的所有资源、如图片、css样式等。SpringMVC的主题也支持国际化,同一个主 题不同区域也可以显示不同的风格。SpringMVC中跟主题相关的类有 ThemeResolver、ThemeSource 和Theme。主题是通过一系列资源来具体体现的,要得到一个主题的资源,首先要得到资源的名称,这 是ThemeResolver的工作。然后通过主题名称找到对应的主题(可以理解为一个配置)文件,这是 ThemeSource的工作。最后从主题中获取资源就可以了。
-
MultipartResolver
initMultipartResolver(context),用于处理上传请求。处理方法是将普通的request包装成 MultipartHttpServletRequest,后者可以直接调用getFile方法获取File,如果上传多个文件,还可以调 用getFileMap得到FileName->File结构的Map。此组件中一共有三个方法,作用分别是判断是不是上传 请求,将request包装成MultipartHttpServletRequest、处理完后清理上传过程中产生的临时资源。
-
FlashMapManager
initFlashMapManager(context),用来管理FlashMap的,FlashMap主要用在redirect中传递参数。
说一下Spring MVC的工作原理?
-
用户发送请求至前端控制器 DispatcherServlet。
-
DispatcherServlet 收到请求调用 HandlerMapping 处理器映射器。
-
处理器映射器找到具体的处理器(可以根据 xml 配置、注解进行查找),生成处理器及处理器拦截器 (如果有则生成)一并返回给 DispatcherServlet。
-
DispatcherServlet 调用 HandlerAdapter 处理器适配器。
-
HandlerAdapter 经过适配调用具体的处理器(Controller,也叫后端控制器)
-
Controller 执行完成返回 ModelAndView。
-
HandlerAdapter 将 controller 执行结果 ModelAndView 返回给 DispatcherServlet。
-
DispatcherServlet 将 ModelAndView 传给 ViewReslover 视图解析器。
-
ViewReslover 解析后返回具体 View。
-
DispatcherServlet 根据 View 进行渲染视图(即将模型数据填充至视图中)。
-
DispatcherServlet 响应用户。
流程说明:
1.客户端(浏览器)发送请求,直接请求到DispatcherServlet。
2.DispatcherServlet根据请求信息调用HandlerMapping,解析请求对应的Handler。
3.解析到对应的Handler(也就是我们平常说的Controller控制器)。
4.HandlerAdapter会根据Handler来调用真正的处理器来处理请求和执行相对应的业务逻辑。
5.处理器处理完业务后,会返回一个ModelAndView对象,Model是返回的数据对象,View是逻辑上的View。
6.ViewResolver会根据逻辑View去查找实际的View。
7.DispatcherServlet把返回的Model传给View(视图渲染)。
8.把View返回给请求者(浏览器)。
ApplicationContext与BeanFactory的区别
BeanFactory和ApplicationContext是Spring的两大核心接口,都可以当做Spring的容器。其中ApplicationContext是BeanFactory的子接口。
| BeanFactory | ApplicationContext |
|---|---|
| 使用懒加载 | 使用延迟加载 |
| 使用语法显式提供资源对象 | 自己创建和管理资源对象 |
| 不支持国际化 | 支持国际化 |
| 不支持基于依赖的注解 | 支持基于依赖的注解 |
BeanFactory
-
BeanFactory是Spring里面最底层的接口,包含了各种Bean的定义,读取bean配置文档,管理bean的加载、实例化,控制bean的生命周期,维护bean之间的依赖关系。
-
BeanFactory 可以理解为含有 bean 集合的工厂类。BeanFactory 包含了种 bean 的定义, 以便在接收到客户端请求时将对应的 bean 实例化。
-
BeanFactory 还能在实例化对象时生成协作类之间的关系。此举将 bean 自身与 bean 客 户端的配置中解放出来。BeanFactory 还包含了 bean 生命周期的控制,调用客户端的初始化方法(initialization methods)和销毁方法(destruction methods)。
ApplicationContext
-
从表面上看,application context 如同 bean factory 一样具有 bean 定义、bean 关联关系的设置,根据请求分发 bean 的功能。ApplicationContext接口作为BeanFactory的派生,除了提供BeanFactory所具有的功能外,还提供了更完整的框架功能:
①继承MessageSource,因此支持国际化。
②统一的资源文件访问方式。
③提供在监听器中注册bean的事件。
④同时加载多个配置文件。
⑤载入多个(有继承关系)上下文 ,使得每一个上下文都专注于一个特定的层次,比如应用的web层。
区别:
-
BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用 getBean()),才对该Bean进行加载实例化。这样,我们就不能发现一些存在的Spring的配置问 题。如果Bean的某一个属性没有注入,BeanFacotry加载后,直至第一次使用调用getBean方法 才会抛出异常。
-
ApplicationContext,它是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误,这样有利于检查所依赖属性是否注入。 ApplicationContext启动后预载入所有的单实例Bean,通过预载入单实例bean ,确保当你需要的时候,你就不用等待,因为它们已经创建好了。
-
相对于基本的BeanFactory,ApplicationContext 唯一的不足是占用内存空间。当应用程序配置 Bean较多时,程序启动较慢。
-
BeanFactory通常以编程的方式被创建,ApplicationContext还能以声明的方式创建,如使用 ContextLoader。
-
BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的使用,但两者之间的区别是:BeanFactory需要手动注册,而ApplicationContext则是自动注册。
什么是bean装配?
装配,或bean 装配是指在Spring 容器中把bean组装到一起,前提是容器需要知道bean的依赖关系,如何通过依赖注入来把它们装配到一起。
什么是bean的自动装配?
Spring 容器能够自动装配相互合作的bean,这意味着容器不需要<constructor-arg>和<property>配置,能通过Bean工厂自动处理bean之间的协作。
Spring中自动装配的方式有哪些?
开启自动装配,只需要在xml配置文件中定义“autowire”属性。
<bean id="cutomer" class="com.xxx.xxx.Customer" autowire="" />
autowire属性有五种装配的方式:
-
no – 缺省情况下,自动配置是通过“ref”属性手动设定 。
手动装配:以value或ref的方式明确指定属性值都是手动装配。 需要通过‘ref’属性来连接bean。
-
byName-根据bean的属性名称进行自动装配。
Cutomer的属性名称是person,Spring会将bean id为person的bean通过setter方法进行自动装配。
<bean id="cutomer" class="com.xxx.xxx.Cutomer" autowire="byName"/><bean id="person" class="com.xxx.xxx.Person"/> -
byType-根据bean的类型进行自动装配。
Cutomer的属性person的类型为Person,Spirng会将Person类型通过setter方法进行自动装配。
<bean id="cutomer" class="com.xxx.xxx.Cutomer" autowire="byType"/><bean id="person" class="com.xxx.xxx.Person"/> -
constructor-类似byType,不过是应用于构造器的参数。如果一个bean与构造器参数的类型形同,则进行自动装配,否则导致异常。
Cutomer构造函数的参数person的类型为Person,Spirng会将Person类型通过构造方法进行自动装配。<bean id="cutomer" class="com.xxx.xxx.Cutomer" autowire="construtor"/><bean id="person" class="com.xxx.xxx.Person"/>
-
autodetect-如果有默认的构造器,则通过constructor方式进行自动装配,否则使用byType方式进行自动装配。
@Autowired自动装配bean,可以在字段、setter方法、构造函数上使用。
Spring自动装配有哪些局限性 ?
自动装配的局限性是:
-
重写: 你仍需用 <constructor-arg>和 <property> 配置来定义依赖,意味着总要重写自动装配。
-
基本数据类型:你不能自动装配简单的属性,如基本数据类型,String字符串,和类。
-
模糊特性:自动装配不如显式装配精确,如果有可能,建议使用显式装配。
如何在 spring 中启动注解装配?
默认情况下,Spring 容器中未打开注解装配。因此,要使用基于注解装配,我们必须通过配置 <context:annotation-config /> 元素在 Spring 配置文件中启用它。
请谈一下@Autowired 和@Resource区别是什么?
1、共同点
两者都可以写在字段和setter方法上。两者如果都写在字段上,那么就不需要再写setter方法。
2、不同点
-
@Autowired为Spring提供的注解,需要导入包org.springframework.beans.factory.annotation.Autowired;只按照byType注入。
@Autowired注解是按照类型(byType)装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它的required属性为false。如果我们想使用按照名称(byName)来装配,可以结合@Qualifier注解一起使用。
-
@Resource默认按照ByName自动注入,由J2EE提供,需要导入包javax.annotation.Resource。@Resource有两个重要的属性:name和type,而Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。所以,如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。如果既不制定name也不制定type属性,这时将通过反射机制使用byName自动注入策略。
Spring 中的事件
Spring的ApplicationContext提供了支持事务和代码中添加监听器的功能。
可以创建一个bean其实现ApplicationListener接口(类型是ApplicationEvent),当一个ApplicationEvent 被发布后,bean就自动被通知,并且在方法onApplicationEvent(…)方法中处理该事件。
public class AllApplicationEventListener implements ApplicationListener < ApplicationEvent > {
@Override
public void onApplicationEvent(ApplicationEvent applicationEvent) {
//process event
}
}
在Spring中有5种标准的事件:
-
上下文更新事件(ContextRefreshedEvent):该事件会在ApplicationContext被初始化或者更新时发布,也可以在调用ConfigurableApplicationContext接口中的refresh()方法时被触发。
-
上下文开始事件(ContextStartedEvent): 当容器调用ConfigurableApplicationContext的Start()方法开始/重新开始容器时被触发。
-
上下文停止事件(ContextStoppedEvent): 当容器调用ConfigurableApplicationContext的Stop()方法停止容器时触发该事件。
-
上下文关闭事件(ContextClosedEvent): 当ApplicationContext被关闭时触发该事件。容器被关闭时,其管理的所有单例Bean都被销毁。
-
请求处理事件(RequestHandledEvent): 在Web应用中,当一个http请求(request)结束触发该事件。
//spring也让用户可以自定义事件类型,继承ApplicationEvent。
public class CustomApplicationEvent extends ApplicationEvent {
public CustomApplicationEvent ( Object source, final String msg ) {
super(source);
System.out.println("Created a Custom event");
}
}
//为了监听这个事件,还需要创建一个监听器:
public class CustomEventListener
implements ApplicationListener < CustomApplicationEvent >{
@Override
public void onApplicationEvent(CustomApplicationEvent applicationEvent) {
//handle event
}
}
//之后通过applicationContext接口的publishEvent()方法来发布自定义事件。
CustomApplicationEvent customEvent =
new CustomApplicationEvent(applicationContext, "Test message"); applicationContext.publishEvent(customEvent);
参考资料:https://www.cnblogs.com/yanggb/p/11004887.html
Mybatis
mybatis的优缺点
优点
基于 SQL 语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任何影响,SQL 写在 XML 里,解除 sql 与程序代码的耦合,便于统一管理;提供 XML 标签, 支持编写动态 SQL 语句, 并 可重用。
与 JDBC 相比,减少了 50%以上的代码量,消除了 JDBC 大量冗余的代码,不需要手动开关连接;
很好的与各种数据库兼容( 因为 MyBatis 使用 JDBC 来连接数据库,所以只要JDBC 支持的数据库 MyBatis 都支持)。
能够与 Spring 很好的集成;
提供映射标签, 支持对象与数据库的 ORM 字段关系映射; 提供对象关系映射标签, 支持对象关 系组件维护。
缺点
SQL 语句的编写工作量较大, 尤其当字段多、关联表多时, 对开发人员编写SQL 语句的功底有一 定要求
SQL 语句依赖于数据库, 导致数据库移植性差, 不能随意更换数据库。
MyBatis 与Hibernate 有哪些不同?
SQL 和 ORM 的争论,永远都不会终止
开发速度的对比:
Hibernate的真正掌握要比Mybatis难些。Mybatis框架相对简单很容易上手,但也相对简陋些。 比起两者的开发速度,不仅仅要考虑到两者的特性及性能,更要根据项目需求去考虑究竟哪一个更适合 项目开发,比如:一个项目中用到的复杂查询基本没有,就是简单的增删改查,这样选择hibernate效 率就很快了,因为基本的sql语句已经被封装好了,根本不需要你去写sql语句,这就节省了大量的时 间,但是对于一个大型项目,复杂语句较多,这样再去选择hibernate就不是一个太好的选择,选择 mybatis就会加快许多,而且语句的管理也比较方便。
开发工作量的对比:
Hibernate和MyBatis都有相应的代码生成工具。可以生成简单基本的DAO层方法。针对高级查询, Mybatis需要手动编写SQL语句,以及ResultMap。而Hibernate有良好的映射机制,开发者无需关心 SQL的生成与结果映射,可以更专注于业务流程
sql优化方面:
Hibernate的查询会将表中的所有字段查询出来,这一点会有性能消耗。Hibernate也可以自己写SQL来 指定需要查询的字段,但这样就破坏了Hibernate开发的简洁性。而Mybatis的SQL是手动编写的,所以 可以按需求指定查询的字段。 Hibernate HQL语句的调优需要将SQL打印出来,而Hibernate的SQL被很多人嫌弃因为太丑了。 MyBatis的SQL是自己手动写的所以调整方便。但Hibernate具有自己的日志统计。Mybatis本身不带日 志统计,使用Log4j进行日志记录。
对象管理的对比:
Hibernate 是完整的对象/关系映射解决方案,它提供了对象状态管理(state management)的功能, 使开发者不再需要理会底层数据库系统的细节。也就是说,相对于常见的 JDBC/SQL 持久层方案中需要 管理 SQL 语句,Hibernate采用了更自然的面向对象的视角来持久化 Java 应用中的数据。 换句话说,使用 Hibernate 的开发者应该总是关注对象的状态(state),不必考虑 SQL 语句的执行。 这部分细节已经由 Hibernate 掌管妥当,只有开发者在进行系统性能调优的时候才需要进行了解。而 MyBatis在这一块没有文档说明,用户需要对对象自己进行详细的管理。
缓存机制对比:
相同点:都可以实现自己的缓存或使用其他第三方缓存方案,创建适配器来完全覆盖缓存行为。
不同点:Hibernate的二级缓存配置在SessionFactory生成的配置文件中进行详细配置,然后再在具体 的表-对象映射中配置是哪种缓存。
MyBatis的二级缓存配置都是在每个具体的表-对象映射中进行详细配置,这样针对不同的表可以自定义 不同的缓存机制。并且Mybatis可以在命名空间中共享相同的缓存配置和实例,通过Cache-ref来实现。
两者比较:因为Hibernate对查询对象有着良好的管理机制,用户无需关心SQL。所以在使用二级缓存 时如果出现脏数据,系统会报出错误并提示。
而MyBatis在这一方面,使用二级缓存时需要特别小心。如果不能完全确定数据更新操作的波及范围, 避免Cache的盲目使用。否则,脏数据的出现会给系统的正常运行带来很大的隐患。
Hibernate功能强大,数据库无关性好,O/R映射能力强,如果你对Hibernate相当精通,而且对 Hibernate进行了适当的封装,那么你的项目整个持久层代码会相当简单,需要写的代码很少,开发速 度很快,非常爽。
Hibernate的缺点就是学习门槛不低,要精通门槛更高,而且怎么设计O/R映射,在性能和对象模型之 间如何权衡取得平衡,以及怎样用好Hibernate方面需要你的经验和能力都很强才行。
iBATIS入门简单,即学即用,提供了数据库查询的自动对象绑定功能,而且延续了很好的SQL使用经 验,对于没有那么高的对象模型要求的项目来说,相当完美。
iBATIS的缺点就是框架还是比较简陋,功能尚有缺失,虽然简化了数据绑定代码,但是整个底层数据库 查询实际还是要自己写的,工作量也比较大,而且不太容易适应快速数据库修改。
#{}和${}的区别是什么?
#{}是预编译处理、是占位符, ${}是字符串替换、是拼接符。
Mybatis 在处理#{}时,会将 sql 中的#{}替换为?号,调用 PreparedStatement 来赋值;
Mybatis 在处理${}时, 就是把${}替换成变量的值,调用 Statement 来赋值;
#{} 的变量替换是在DBMS 中、变量替换后,#{} 对应的变量自动加上单引号
${} 的变量替换是在 DBMS 外、变量替换后,${} 对应的变量不会加上单引号
使用#{}可以有效的防止 SQL 注入, 提高系统安全性。
简述 Mybatis 的插件运行原理,如何编写一个插件。
答: Mybatis 只支持针对 ParameterHandler、ResultSetHandler、StatementHandler、Executor 这 4 种接口的插件, Mybatis 使用 JDK 的动态代理, 为需要拦截的接口生成代理对象以实现接口方法拦 截功能, 每当执行这 4 种接口对象的方法时,就会进入拦截方法,具体就是 InvocationHandler 的 invoke() 方法, 拦截那些你指定需要拦截的方法。
编写插件: 实现 Mybatis 的 Interceptor 接口并复写 intercept()方法, 然后在给插件编写注解, 指定 要拦截哪一个接口的哪些方法即可, 在配置文件中配置编写的插件。
@Intercepts({@Signature(type = StatementHandler.class, method = "query", args ={Statement.class, ResultHandler.class}),@Signature(type = StatementHandler.class, method = "update", args ={Statement.class}),@Signature(type = StatementHandler.class, method = "batch", args = {Statement.class })})@Componentinvocation.proceed()执行具体的业务逻辑
Redis
Redis,全称:Remote Dictionary Server,是一个基于内存的高性能key-value数据库,是应用服务提高效率和性能必不可少的一部分,因为当前大部分的应用都离不开Redis。
1、什么是 Redis?简述它的优缺点?
Redis 的全称是:Remote Dictionary.Server,本质上是一个 Key-Value 类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据 flush 到硬盘 上进行保存。
因为是纯内存操作,Redis 的性能非常出色,每秒可以处理超过 10 万次读写操作,是已知性能最快的Key-Value DB。
Redis 的出色之处不仅仅是性能,Redis 最大的魅力是支持保存多种数据结构,此外单个 value 的最大限制是 1GB,不像 memcached 只能保存 1MB 的数据,因此 Redis 可以用来实现很多有用的功能。比方说用他的 List 来做 FIFO 双向链表,实现一个轻量级的高性能消息队列服务,用他的 Set 可以做高 性能的 tag 系统等等。
另外 Redis 也可以对存入的 Key-Value 设置 expire 时间,因此也可以被当作一 个功能加强版的memcached 来用。
Redis 的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能 读写,因此 Redis 适合的场景主要局限在较小数据量的高性能操作和运算上。
2、使用redis有哪些好处?
-
速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)。
-
支持丰富数据类型,支持string,list,set,sorted set,hash
-
支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行。
-
丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除。
3、Redis支持哪几种数据类型?
答:Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
还有一些数据结构如HyperLogLog、Geo、Pub/Sub等,我们也最好知道,另外像Redis Module,像BloomFilter,RedisSearch,Redis-ML等,能有个印象,哪怕知其然不知其所以然也比听都没听过好点。
4、Redis有哪几种淘汰策略?
Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
-
no-eviction:当内存不足以容纳新写入数据时,新写入操作会报错。
-
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。
-
allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
-
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
-
volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
-
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
注意这里的6种机制,volatile和allkeys规定了是对已设置过期时间的数据集淘汰数据还是从全部数据集淘汰数据,后面的lru、ttl以及random是三种不同的淘汰策略,再加上一种no-enviction永不回收的策略。
使用策略规则:
-
如果数据呈现幂律分布,也就是一部分数据访问频率高,一部分数据访问频率低,则使用allkeys-lru
-
如果数据呈现平等分布,也就是所有的数据访问频率都相同,则使用allkeys-random
5、为什么 Redis 需要把所有数据放到内存中?
答:Redis 为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。所以 redis 具有快速和数据持久化的特征,如果不将数据放在内存中,磁盘 I/O 速度会严重影响 redis 的 性能。
在内存越来越便宜的今天,redis 将会越来越受欢迎, 如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值。
6、Redis 有哪些适合的场景?
(1)会话缓存(Session Cache)
最常用的一种使用 Redis 的情景是会话缓存(sessioncache),用 Redis 缓存会话比其他存储(如Memcached)的优势在于:Redis 提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的 购物车信息全部丢失,大部分人都会不高兴的,现在,他们还会这样吗? 幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用 Redis 来缓存会话的文档。甚至广为 人知的商业平台 Magento 也提供 Redis 的插件。 (2)全页缓存(FPC)
除基本的会话 token 之外,Redis 还提供很简便的 FPC 平台。回到一致性问题,即使重启了 Redis 实 例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似 PHP 本地FPC。
再次以 Magento 为例,Magento 提供一个插件来使用 Redis 作为全页缓存后端。此外,对 WordPress 的用户来说,Pantheon 有一个非常好的插件 wp-redis,这个插件能帮助你以最快 速度加载你曾浏览过的页面。 (3)队列
Reids 在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得 Redis 能作为一个很好的消息队列平台来使用。Redis 作为队列使用的操作,就类似于本地程序语言(如 Python)对 list 的 push/pop操作。
如果你快速的在 Google 中搜索“Redis queues”,你马上就能找到大量的开源项目,这些项目的目的 就是利用 Redis 创建非常好的后端工具,以满足各种队列需求。例如,Celery 有一个后台就是使用Redis 作为 broker,你可以从这里去查看。 (4)排行榜/计数器
Redis 在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(SortedSet)也使 得我们在执行这些操作的时候变的非常简单,Redis 只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的 10 个用户–我们称之为“user_scores”,我们只需要像 下面一样执行即可: 当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执 行:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games 就是一个很好的例子,用 Ruby 实现的,它的排行榜就是使用 Redis 来存储数据的,你可 以在这里看到。 (5)发布/订阅
最后(但肯定不是最不重要的)是 Redis 的发布/订阅功能。发布/订阅的使用场景确实非常多。我已看见 人们在社交网络连接中使用,还可作为基于发布/订阅的脚本触发器,甚至用 Redis 的发布/订阅功能来建 立聊天系统!
7、说说 Redis 哈希槽的概念?
Redis 集群没有使用一致性 hash,而是引入了哈希槽的概念,Redis 集群有 16384 个哈希槽,每个 key 通 过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
8、Redis 集群的主从复制模型是怎样的?
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有 N-1 个复制品。
9、Redis 集群会有写操作丢失吗?为什么?
Redis 并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作。
10、Redis 集群之间是如何复制的?
答:异步复制
11、Redis 中的管道有什么用?
一次请求/响应服务器能实现处理新的请求即使旧的请求还未被响应,这样就可以将多个命令发送到服务 器,而不用等待回复,最后在一个步骤中读取该答复。这就是管道(pipelining),是一种几十年来广泛使用的技术。例如许多 POP3 协议已经实现支持这个功 能,大大加快了从服务器下载新邮件的过程。
12、怎么理解 Redis 事务?
-
事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行,事务在执行的过程中,不会 被其他客户端发送来的命令请求所打断。
-
事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
13、Redis 事务相关的命令有哪几个?
MULTI、EXEC、DISCARD、WATCH
14、Redis key 的过期时间和永久有效分别怎么设置?
EXPIRE 和 PERSIST 命令
15、Redis 如何做内存优化?
尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该 尽可能的将你的数据模型抽象到一个散列表里面。
比如你的 web 系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的 key,而是 应该把这个用户的所有信息存储到一张散列表里面。
16、Redis 回收进程如何工作的?
一个客户端运行了新的命令,添加了新的数据。Redi 检查内存使用情况,如果大于 maxmemory 的限制, 则根据设定好的策略进行回收。一个新的命令被执行,等等。所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。如果一个命令的结果导致大量内存被使用(例如很大的集合的交集保存到一个新的键),不用多久内存限 制就会被这个内存使用量超越。
17、Redis集群最大节点个数是多少?
答:16384个。
18、Redis集群如何选择数据库?
答:Redis集群目前无法做数据库选择,默认在0数据库。
19、都有哪些办法可以降低Redis的内存使用情况呢?
答:如果你使用的是32位的Redis实例,可以好好利用Hash,list,sorted set,set等集合类型数据,因为通常情况下很多小的Key-Value可以用更紧凑的方式存放到一起。
20、Redis的内存用完了会发生什么?
答:如果达到设置的上限,Redis的写命令会返回错误信息(但是读命令还可以正常返回。)或者你可以将Redis当缓存来使用配置淘汰机制,当Redis达到内存上限时会冲刷掉旧的内容。
21、一个Redis实例最多能存放多少的keys?List、Set、Sorted Set他们最多能存放多少元素?
答:理论上Redis可以处理多达232的keys,并且在实际中进行了测试,每个实例至少存放了2亿5千万的keys。我们正在测试一些较大的值。任何list、set、和sorted set都可以放232个元素。换句话说,Redis的存储极限是系统中的可用内存值。
22、假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如果将它们全部找出来?
答:使用keys指令可以扫出指定模式的key列表。
23、如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
答:redis的单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
24、如果有大量的key需要设置同一时间过期,一般需要注意什么?
答:如果大量的key过期时间设置的过于集中,到过期的那个时间点,redis可能会出现短暂的卡顿现象。一般需要在时间上加一个随机值,使得过期时间分散一些。
25、Redis 集群方案应该怎么做?都有哪些方案?
-
codis:目前用的最多的集群方案,基本和 twemproxy 一致的效果,但它支持在节点数量改变情况下,旧节点数据可恢复到新 hash 节点。
-
redis cluster3.0 自带的集群,特点在于他的分布式算法不是一致性 hash,而是 hash 槽的概念,以及自身支持节点设置从节点。具体看官方文档介绍。
-
在业务代码层实现,起几个毫无关联的 redis 实例,在代码层,对 key 进行 hash 计算,然后去对应的redis 实例操作数据。这种方式对 hash 层代码要求比较高,考虑部分包括,节点失效后的替代算法方案,数据震荡后的自动脚本恢复,实例的监控,等等。
26、使用过 Redis 分布式锁么,它是怎么实现的?
答:先拿 setnx 来争抢锁,抢到之后,再用 expire 给锁加一个过期时间防止锁忘记了释放。
27、如果在 setnx 之后执行 expire 之前进程意外 crash 或者要重启维护了,那会怎么样?
答:set 指令有非常复杂的参数,这个应该是可以同时把 setnx 和 expire 合成一条指令来用的!
28、使用过 Redis 做异步队列么,你是怎么用的?有什么缺点?
一般使用 list 结构作为队列,rpush 生产消息,lpop 消费消息。当 lpop 没有消息的时候,要适当 sleep 一会再重试。
缺点:在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如 rabbitmq 等。
能不能生产一次消费多次呢?
使用 pub/sub 主题订阅者模式,可以实现 1:N 的消息队列。
29、缓存穿透、缓存击穿、缓存雪崩解决方案?
缓存穿透:指查询一个一定不存在的数据,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到 DB 去查询,可能导致 DB 挂掉。
解决方案:
1.查询返回的数据为空,仍把这个空结果进行缓存,但过期时间会比较短;
2.布 隆过滤器:将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据 会被这个 bitmap 拦截掉,从而避免了对 DB 的查询。
缓存击穿:对于设置了过期时间的 key,缓存在某个时间点过期的时候,恰好这时间点对 这个 Key 有大量的并发请求过来,这些请求发现缓存过期一般都会从后端 DB 加载数据并 回设到缓存,这个时候大并发的请求可能会瞬间把 DB 压垮。
解决方案:
1.使用互斥锁:当缓存失效时,不立即去load db,先使用如Redis的setnx去设 置一个互斥锁,当操作成功返回时再进行load db的操作并回设缓存,否则重试get缓存的 方法。
2.永远不过期:物理不过期,但逻辑过期(后台异步线程去刷新)。
缓存雪崩:设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部 转发到 DB,DB 瞬时压力过重雪崩。与缓存击穿的区别:雪崩是很多 key,击穿是某一个key 缓存。
解决方案:
将缓存失效时间分散开,比如可以在原有的失效时间基础上增加一个随机值, 比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效 的事件。
30、为什么redis单线程还是那么快?
答:redis利用队列技术将并发访问变为串行访问,消除了传统数据库串行控制的开销。
31、使用 redis 如何设计分布式锁?说一下实现思路?使用 zk 可以吗?如何实现?这两种有什 么区别?
redis:
-
线程 A setnx(上锁的对象,超时时的时间戳 t1),如果返回 true,获得锁。
-
线程 B 用 get 获取 t1,与当前时间戳比较,判断是是否超时,没超时 false,若超时执行第 3 步。
-
计算新的超时时间 t2,使用 getset 命令返回 t3(该值可能其他线程已经修改过),如果t1==t3,获得锁,如果 t1!=t3 说明锁被其他线程获取了。4.获取锁后,处理完业务逻辑,再去判断锁是否超时,如果没超时删除锁,如果已超时, 不用处理(防止删除其他线程的锁)。
zk:
-
客户端对某个方法加锁时,在 zk 上的与该方法对应的指定节点的目录下,生成一个唯一 的瞬时有序节点 node1。
-
客户端获取该路径下所有已经创建的子节点,如果发现自己创建的 node1 的序号是最小 的,就认为这个客户端获得了锁。
-
如果发现 node1 不是最小的,则监听比自己创建节点序号小的最大的节点,进入等待。
-
获取锁后,处理完逻辑,删除自己创建的 node1 即可。
区别:zk 性能差一些,开销大,实现简单。
32、知道 redis 的持久化吗?底层如何实现的?有什么优点缺点?
-
RDB(Redis DataBase:在不同的时间点将 redis 的数据生成的快照同步到磁盘等介质上):内存 到硬盘的快照,定期更新。缺点:耗时,耗性能(fork+io 操作),易丢失数据。 AOF(Append Only File:将redis所执行过的所有指令都记录下来,在下次redis重启时,只 需要执行指令就可以了):写日志。缺点:体积大,恢复速度慢。
-
bgsave 做镜像全量持久化,aof 做增量持久化。因为 bgsave 会消耗比较长的时间,不够实 时,在停机的时候会导致大量的数据丢失,需要 aof 来配合,在 redis 实例重启时,优先使 用 aof 来恢复内存的状态,如果没有 aof 日志,就会使用 rdb 文件来恢复。Redis 会定期做aof 重写,压缩 aof 文件日志大小。Redis4.0 之后有了混合持久化的功能,将 bgsave 的全量 和 aof 的增量做了融合处理,这样既保证了恢复的效率又兼顾了数据的安全性。bgsave 的 原理,fork 和 cow, fork 是指 redis 通过创建子进程来进行 bgsave 操作,cow 指的是 copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据 会逐渐和子进程分离开来。
33、redis 过期策略都有哪些?LRU 算法知道吗?写一下 java 代码实现?
过期策略:
-
定时过期(一 key 一定时器)。
-
惰性过期:只有使用 key 时才判断 key 是否已过期,过期则清除。
-
定期过期:前两者折中。
LRU:
new LinkedHashMap<K, V>(capacity, DEFAULT_LOAD_FACTORY, true); //第三个参数置为 true,代表 linkedlist 按访问顺序排序,可作为 LRU 缓存;设为 false 代表 按插入顺序排序,可作为 FIFO 缓存
LRU 算法实现:
1.通过双向链表来实现,新数据插入到链表头部;
2.每当缓存命中(即缓存 数据被访问),则将数据移到链表头部;
3.当链表满的时候,将链表尾部的数据丢弃。
LinkedHashMap:HashMap 和双向链表合二为一即是 LinkedHashMap。HashMap 是无序 的,LinkedHashMap 通过维护一个额外的双向链表保证了迭代顺序。该迭代顺序可以是插 入顺序(默认),也可以是访问顺序。
34、缓存与数据库不一致怎么办?
答:假设采用的主存分离,读写分离的数据库,
如果一个线程 A 先删除缓存数据,然后将数据写入到主库当中,这个时候,主库和从库同 步没有完成,线程 B 从缓存当中读取数据失败,从从库当中读取到旧数据,然后更新至缓 存,这个时候,缓存当中的就是旧的数据。
发生上述不一致的原因在于,主从库数据不一致问题,加入了缓存之后,主从不一致的时间被拉长了。
处理思路:在从库有数据更新之后,将缓存当中的数据也同时进行更新,即当从库发生了
数据更新之后,向缓存发出删除,淘汰这段时间写入的旧数据。
35、主从数据库不一致如何解决?
场景描述,对于主从库,读写分离,如果主从库更新同步有时差,就会导致主从库数据的不一致,解决方法:
-
忽略这个数据不一致,在数据一致性要求不高的业务下,未必需要时时一致性。
-
强制读主库,使用一个高可用的主库,数据库读写都在主库,添加一个缓存,提升数据读取的性能。
-
选择性读主库,添加一个缓存,用来记录必须读主库的数据,将哪个库,哪个表,哪个 主键,作为缓存的 key,设置缓存失效的时间为主从库同步的时间,如果缓存当中有这个数 据,直接读取主库,如果缓存当中没有这个主键,就到对应的从库中读取。
36、Redis 常见的性能问题和解决方案
-
master 最好不要做持久化工作,如 RDB 内存快照和 AOF 日志文件。
-
如果数据比较重要,某个 slave 开启 AOF 备份,策略设置成每秒同步一次。
-
为了主从复制的速度和连接的稳定性,master 和 Slave 最好在一个局域网内。
-
尽量避免在压力大得主库上增加从库5、主从复制不要采用网状结构,尽量是线性结构,Master<--Slave1<----Slave2 ....
37、为什么要做Redis分区?
答:分区可以让Redis管理更大的内存,Redis将可以使用所有机器的内存。如果没有分区,你最多只能使用一台机器的内存。分区使Redis的计算能力通过简单地增加计算机得到成倍提升,Redis的网络带宽也会随着计算机和网卡的增加而成倍增长。
38、你知道有哪些Redis分区实现方案?
答:客户端分区就是在客户端就已经决定数据会被存储到哪个redis节点或者从哪个redis节点读取。大多数客户端已经实现了客户端分区。
-
代理分区意味着客户端将请求发送给代理,然后代理决定去哪个节点写数据或者读数据。代理根据分区规则决定请求哪些Redis实例,然后根据Redis的响应结果返回给客户端。redis和memcached的一种代理实现就是Twemproxy
-
查询路由(Query routing) 的意思是客户端随机地请求任意一个redis实例,然后由Redis将请求转发给正确的Redis节点。Redis Cluster实现了一种混合形式的查询路由,但并不是直接将请求从一个redis节点转发到另一个redis节点,而是在客户端的帮助下直接redirected到正确的redis节点。
39、Redis分区有什么缺点?
涉及多个key的操作通常不会被支持。例如你不能对两个集合求交集,因为他们可能被存储到不同的Redis实例(实际上这种情况也有办法,但是不能直接使用交集指令)。
同时操作多个key,则不能使用Redis事务。
分区使用的粒度是key,不能使用一个非常长的排序key存储一个数据集(The partitioning granularity is the key, so it is not possible to shard a dataset with a single huge key like a very big sorted set)。
当使用分区的时候,数据处理会非常复杂,例如为了备份你必须从不同的Redis实例和主机同时收集RDB / AOF文件。
分区时动态扩容或缩容可能非常复杂。Redis集群在运行时增加或者删除Redis节点,能做到最大程度对用户透明地数据再平衡,但其他一些客户端分区或者代理分区方法则不支持这种特性。然而,有一种预分片的技术也可以较好的解决这个问题。
40、Redis持久化数据和缓存怎么做扩容?
答:如果Redis被当做缓存使用,使用一致性哈希实现动态扩容缩容。
如果Redis被当做一个持久化存储使用,必须使用固定的keys-to-nodes映射关系,节点的数量一旦确定不能变化。否则的话(即Redis节点需要动态变化的情况),必须使用可以在运行时进行数据再平衡的一套系统,而当前只有Redis集群可以做到这样。
41、redis的并发竞争问题如何解决?
答:Redis为单进程单线程模式,采用队列模式将并发访问变为串行访问。Redis本身没有锁的概念,Redis对于多个客户端连接并不存在竞争,但是在Jedis客户端对Redis进行并发访问时会发生连接超时、数据转换错误、阻塞、客户端关闭连接等问题,这些问题均是由于客户端连接混乱造成。
对此有2种解决方法:
1.客户端角度,为保证每个客户端间正常有序与Redis进行通信,对连接进行池化,同时对客户端读写Redis操作采用内部锁synchronized。
2.服务器角度,利用setnx实现锁。
注:对于第一种,需要应用程序自己处理资源的同步,可以使用的方法比较通俗,可以使用synchronized也可以使用lock;第二种需要用到Redis的setnx命令,但是需要注意一些问题。
42、简述redis的哨兵模式
答:哨兵是对redis进行实时的监控,主要有两个功能。
-
监测主数据库和从数据库是否正常运行。
-
当主数据库出现故障的时候,可以自动将一个从数据库转换为主数据库,实现自动切换。
43、redis的哨兵的监控机制是怎样的?
答:哨兵监控也是有集群的,会有多个哨兵进行监控,当判断发生故障的哨兵达到一定数量的时候才进行修复。一个健壮的部署至少需要三个哨兵实例。
1.每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令
2.如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel 标记为主观下线。
3.如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
4.当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线
5.在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令
6.当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次
7.若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会被移除。若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。
SpringBoot
https://www.cnblogs.com/javastack/p/9790700.html
Spring Boot、Spring MVC 和 Spring 有什么区别
spring是一个IOC容器,用来管理Bean,使用依赖注入实现控制反转,可以很方便的整合各种框架,提 供AOP机制弥补OOP的代码重复问题、更方便将不同类不同方法中的共同处理抽取成切面、自动注入给 方法执行,比如日志、异常等
springmvc是spring对web框架的一个解决方案,提供了一个总的前端控制器Servlet,用来接收请求, 然后定义了一套路由策略(url到handle的映射)及适配执行handle,将handle结果使用视图解析技术 生成视图展现给前端
springboot是spring提供的一个快速开发工具包,让程序员能更方便、更快速的开发spring+springmvc 应用,简化了配置(约定了默认配置),整合了一系列的解决方案(starter机制)、redis、 mongodb、es,可以开箱即用
springboot启动过程
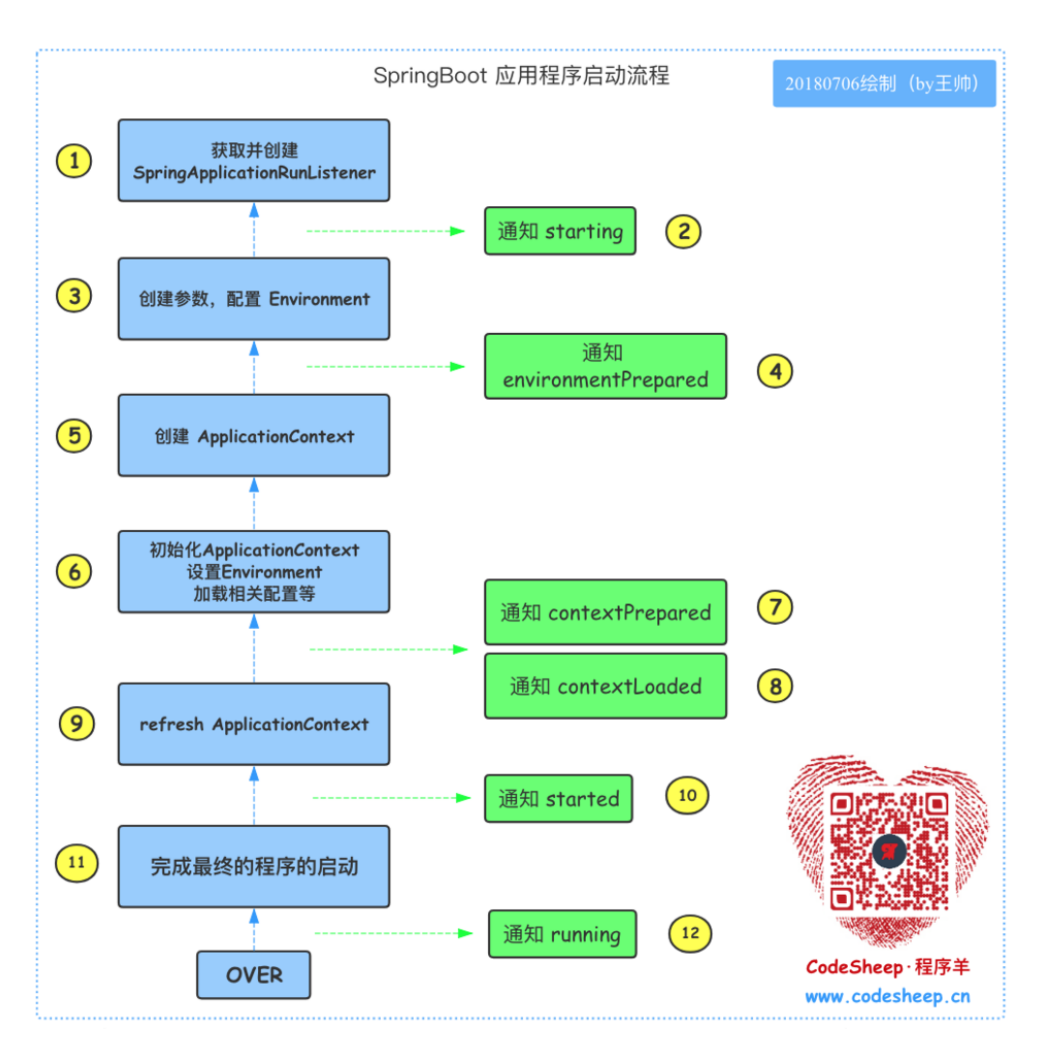
-
通过 SpringFactoriesLoader加载 META-INF/spring.factories⽂件,获取并创建 SpringApplicationRunListener对象
-
然后由 SpringApplicationRunListener来发出 starting 消息
-
创建参数,并配置当前 SpringBoot 应⽤将要使⽤的 Environment
-
完成之后,依然由 SpringApplicationRunListener来发出 environmentPrepared 消息
-
创建 ApplicationContext
-
初始化 ApplicationContext,并设置 Environment,加载相关配置等
-
由 SpringApplicationRunListener来发出 contextPrepared消息,告知SpringBoot 应⽤使⽤的 ApplicationContext已准备OK
-
将各种 beans 装载⼊ ApplicationContext,继续由 SpringApplicationRunListener来发出 contextLoaded 消息,告知 SpringBoot 应⽤使⽤的 ApplicationContext已装填OK
-
refresh ApplicationContext,完成IoC容器可⽤的最后⼀步
-
由 SpringApplicationRunListener来发出 started 消息
-
完成最终的程序的启动
-
由 SpringApplicationRunListener来发出 running 消息,告知程序已运⾏起来了
说说常⽤的springboot注解,及其实现?
-
@Bean:注册Bean
-
默认使⽤⽅法名作为id,可以在后⾯定义id如@Bean("xx");
-
默认为单例。
-
可以指定init⽅法和destroy⽅法:
-
对象创建和赋值完成,调⽤初始化⽅法;
-
单实例bean在容器销毁的时候执⾏destroy⽅法;
-
多实例bean,容器关闭是不会调⽤destroy⽅法。
-
-
-
@Scope:Bean作⽤域
-
默认为singleton;
-
类型:
-
singleton单实例(默认值):ioc容器启动时会调⽤⽅法创建对象放到ioc容器中,以后每次获取就是直接从容器中拿 实例;
-
prototype多实例:ioc容器启动不会创建对象,每次获取时才会调⽤⽅法创建实例;
-
request同⼀次请求创建⼀个实例;
-
session同⼀个session创建⼀个实例。
-
-
-
@Value:给变量赋值
-
代码:
import org.springframework.beans.factory.annotation.Value;
public class Person extends BaseEntity{
@Value("xuan")
private String name;
@Value("27")
private int age;
@Value("#{20-7}")
private int count;
@Value("${person.nickName}")
private String nickName;
} -
⽅式:
-
基本数字
-
可以写SpEL(Spring EL表达式):#{}
-
可以写${},取出配置⽂件中的值(在运⾏环境变量⾥⾯的值)
-
-
-
@Autowired:⾃动装配
-
默认优先按照类型去容器中找对应的组件:BookService bookService = applicationContext.getBean(BookService.class);
-
默认⼀定要找到,如果没有找到则报错。可以使⽤@Autowired(required = false)标记bean为⾮必须的。
-
如果找到多个相同类型的组件,再根据属性名称去容器中查找。
-
@Qualifier("bookDao2")明确的指定要装配的bean。
-
@Primary:让spring默认装配⾸选的bean,也可以使⽤@Qualifier()指定要装配的bean。
-
-
@Profile:环境标识
-
Spring为我们提供的可以根据当前环境,动态的激活和切换⼀系列组件的功能;
-
@Profile指定组件在哪个环境才能被注册到容器中,默认为"default"@Profile("default")。
-
激活⽅式:
-
运⾏时添加虚拟机参数:-Dspring.profiles.active=test
-
代码⽅式:
-
-
说说⼏个常⽤的注解?
-
@RestController :@ResponseBody和@Controller的合集。
-
@EnableAutoConfiguration :尝试根据你添加的jar依赖⾃动配置你的Spring应⽤。
-
@ComponentScan:表示将该类⾃动发现(扫描)并注册为Bean,可以⾃动收集所有的Spring组件,包@Configuration类。
-
@ImportResource :⽤来加载xml配置⽂件。
-
@Configuration :相当于传统的xml配置⽂件,如果有些第三⽅库需要⽤到xml⽂件,建议仍然通过@Configuration类作为项⽬的配置主类——可以使⽤@ImportResource注解加载xml配置⽂件。
-
@SpringBootApplication:相当于@EnableAutoConfiguration、@ComponentScan和@Configuration的合集。
Spring Boot 自动配置原理?
@Import + @Configuration + Spring spi
自动配置类由各个starter提供,使用@Configuration + @Bean定义配置类,放到METAINF/spring.factories下
使用Spring spi扫描META-INF/spring.factories下的配置类
使用@Import导入自动配置类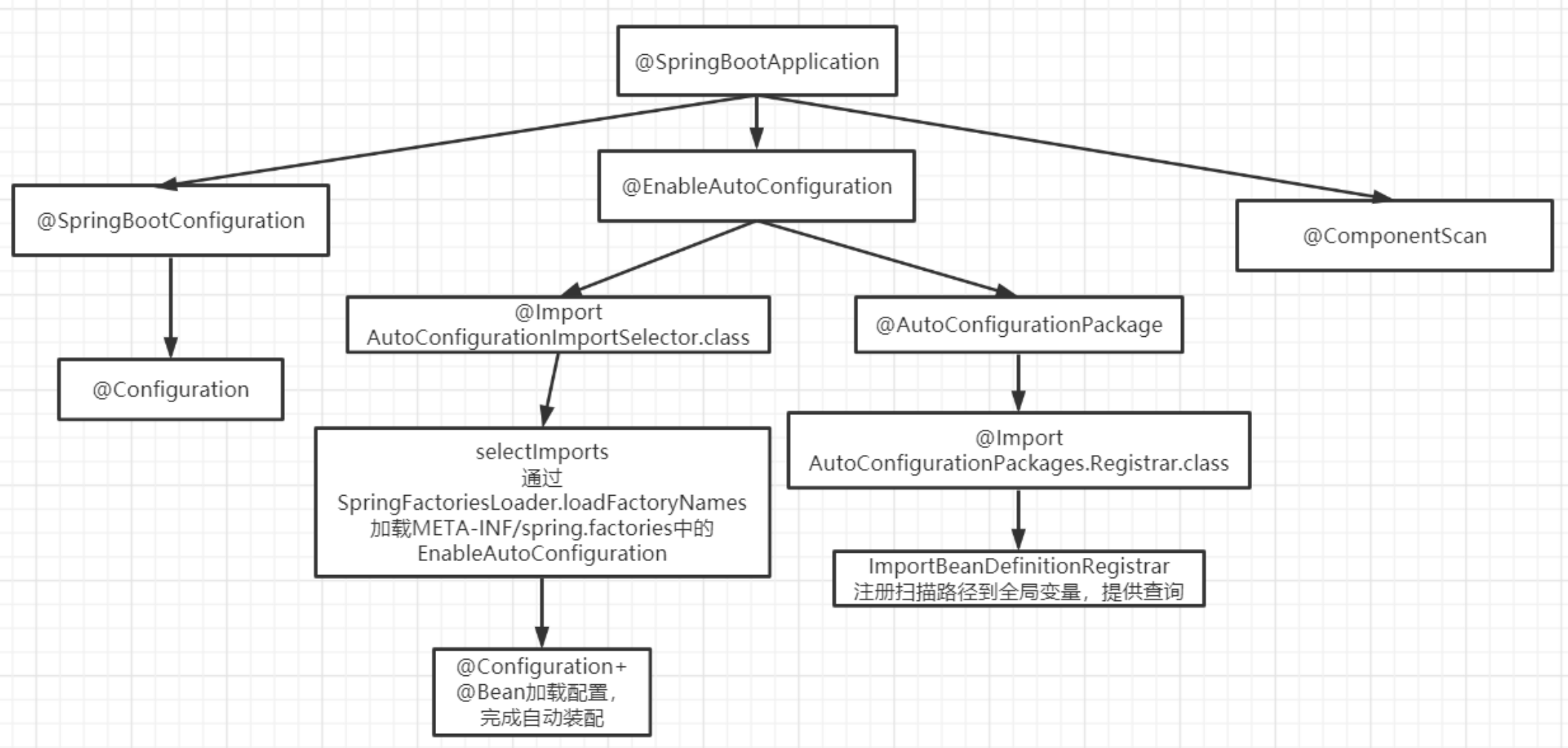
如何理解 Spring Boot 中的 Starter
使用spring + springmvc使用,如果需要引入mybatis等框架,需要到xml中定义mybatis需要的bean
starter就是定义一个starter的jar包,写一个@Configuration配置类、将这些bean定义在里面,然后在 starter包的META-INF/spring.factories中写入该配置类,springboot会按照约定来加载该配置类
开发人员只需要将相应的starter包依赖进应用,进行相应的属性配置(使用默认配置时,不需要配 置),就可以直接进行代码开发,使用对应的功能了,比如mybatis-spring-boot--starter,springboot-starter-redis
什么是嵌入式服务器?为什么要使用嵌入式服务器?
节省了下载安装tomcat,应用也不需要再打war包,然后放到webapp目录下再运行
只需要一个安装了 Java 的虚拟机,就可以直接在上面部署应用程序了
springboot已经内置了tomcat.jar,运行main方法时会去启动tomcat,并利用tomcat的spi机制加载 springmvc
springboot 目录
spring-boot-parent 父项目 spring-boot-starter 开始 spring-boot-starter-actuator 监控日志 spring-boot-starter-amqp RabbitMQ(Erlang) 增强消息访问协议 spring-boot-starter-aop 面向切面编程 spring-boot-starter-data-elasticsearch es/solr 全文及检索 spring-boot-starter-data-jpa jara持久化API spring-boot-starter-data-mongobd nosql数据库(kv) spring-boot-starter-data-redis nsql分布式内存数据库 spring-boot-starter-data-solr solr全文检索 spring-boot-starter-freemarker 页面摸板 spring-boot-starter-jdbc spring-boot-starter-json spring-boot-starter-logging logback spring-boot-starter-parent 程序都要使用父项目 spring-boot-starter-quartz 定时器 spring-boot-starters spring-boot-starter-security 安全框架,类似shiro spring-boot-starter-test 测试 spring-boot-starter-thymeleaf 类似freemarker spring-boot-starter-tomcat
mybatis (pojo+映射文件xml(sql)+映射接口) 配置:包扫描注解,个性配置application.yml(数据源)——树型层次结构
约定大于配置,约定:resources 目录下放banner.txt 替换掉默认logo
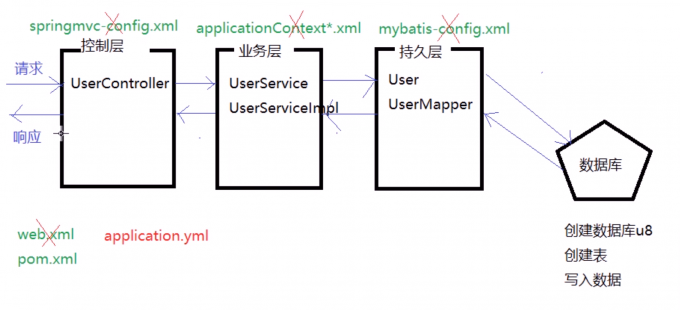
面试答术
开发工具越来越多,开发结构内容越来越多,开发效率变低,业界提倡敏捷开发。SpringBoot可以实现敏捷开发,让编码人员专注于业务。以前maven的缺点:jar管理不统一,jar版本升级冲突。三大框架整合之后,配置文件太多,配置项太多记不住,配置项xml文件没有语法检查,增加了bug几率。还有启动方式过于繁琐,而spring boot通过注解+约定大于配置,大量节约开发代码量。通过spring boot自己出品的父工程 spring-boot-starter-parent,统一管理公用大多的jar的版本。基于parent和starter-web整合SSM框架,通过注解和约定从而不用配置三大框架的配置文件,另外的个性化配置通过datasource和application.yml实现,无需配置tomcat,连插件也不需要,只需要写一个启动类,通过main执行。增加两行代码,一行SpringApplication.run(),一个注解搞定。
定义
基于maven实现spring boot敏捷开发(eclipse支持不够好,spring eclipse sts/idea
创建Springboot的项目,继承spring boot出品的父项目,依赖starter-web jar.基于SSM三大框架
@RestController,都是spring一家子,spring开发时“完全”兼容springmvc注解,@RequestMapping,@GetMapping,@PostMapping.使用新的main启动方式。
我们项目中全面使用微服务框架,基于spring boot来构建,使用SpringCloud微服务框架来开发我们业务。Eureka完成注册中心,Ribbon完成前端负载均衡,Fegin封装REST方式支持,Hystrix完成断路器,Zuul完成API网关,Sidercar完成异构开发语音调用,NodeJS.SpringCloudConfig配置中心+GIT版本控制。
新的部署运行方式:
旧的分时:外置tomcat,打包war,放入tomcat制定目录,启动tomcat
新的方式:打包jar,内置tomcat(embed简版)。命令:Java -jar hello.jar
SpringCloud
说说springcloud的⼯作原理
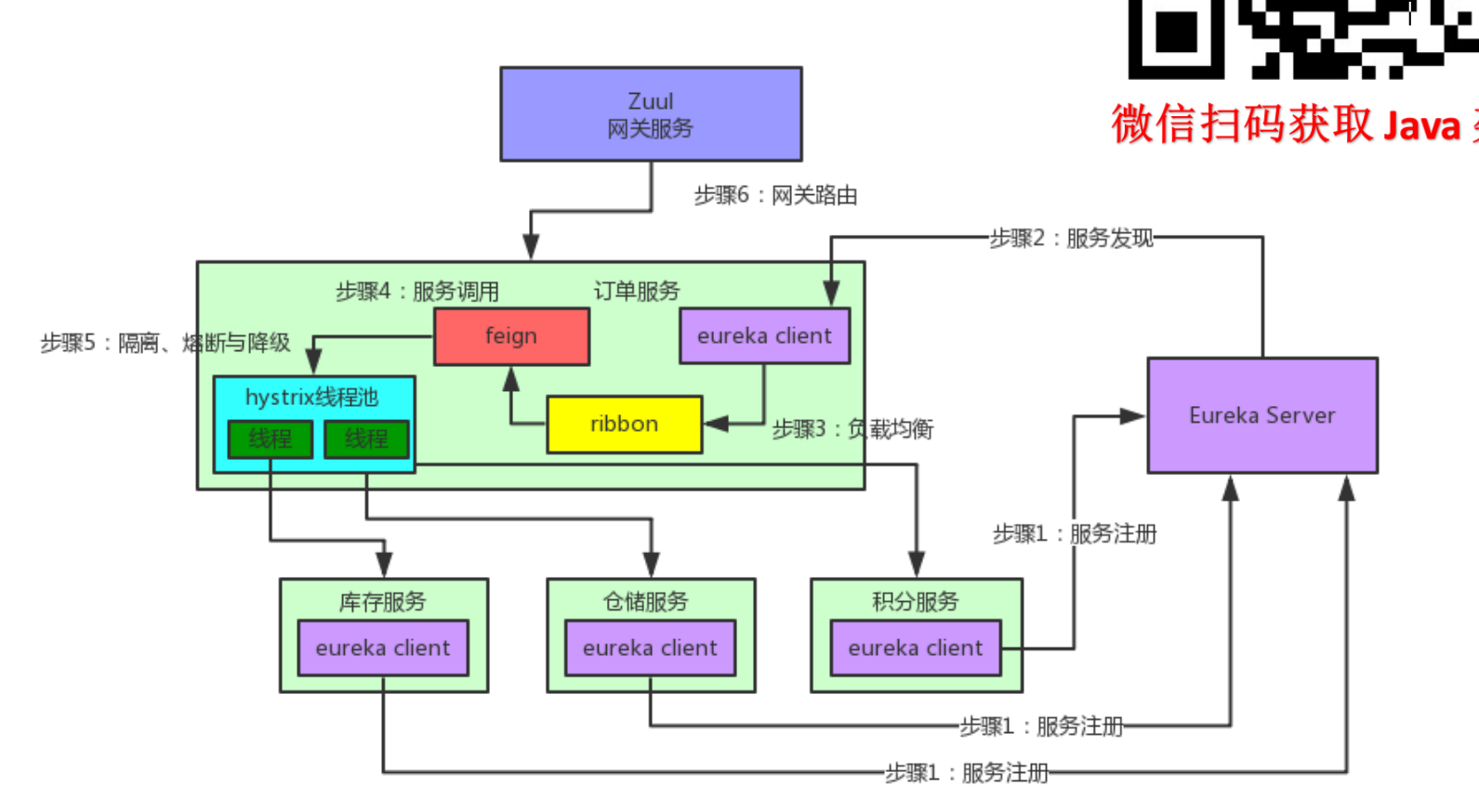 springcloud由以下⼏个核⼼组件构成: Eureka:各个服务启动时,Eureka Client都会将服务注册到Eureka Server,并且Eureka Client还可以反过来从Eureka Server拉取注册表,从⽽知道其他服务在哪⾥ Ribbon:服务间发起请求的时候,基于Ribbon做负载均衡,从⼀个服务的多台机器中选择⼀台 Feign:基于Feign的动态代理机制,根据注解和选择的机器,拼接请求URL地址,发起请求 Hystrix:发起请求是通过Hystrix的线程池来⾛的,不同的服务⾛不同的线程池,实现了不同服务调⽤的隔离,避免了服务雪崩的问题 Zuul:如果前端、移动端要调⽤后端系统,统⼀从Zuul⽹关进⼊,由Zuul⽹关转发请求给对应的服务
springcloud由以下⼏个核⼼组件构成: Eureka:各个服务启动时,Eureka Client都会将服务注册到Eureka Server,并且Eureka Client还可以反过来从Eureka Server拉取注册表,从⽽知道其他服务在哪⾥ Ribbon:服务间发起请求的时候,基于Ribbon做负载均衡,从⼀个服务的多台机器中选择⼀台 Feign:基于Feign的动态代理机制,根据注解和选择的机器,拼接请求URL地址,发起请求 Hystrix:发起请求是通过Hystrix的线程池来⾛的,不同的服务⾛不同的线程池,实现了不同服务调⽤的隔离,避免了服务雪崩的问题 Zuul:如果前端、移动端要调⽤后端系统,统⼀从Zuul⽹关进⼊,由Zuul⽹关转发请求给对应的服务
⽤什么组件发请求
在Spring Cloud中使⽤Feign, 我们可以做到使⽤HTTP请求远程服务时能与调⽤本地⽅法⼀样的编码体验,开发者完全感知不到 这是远程⽅法,更感知不到这是个HTTP请求。
注册中⼼⼼跳是⼏秒
1、Eureka的客户端默认每隔30s会向eureka服务端更新实例,注册中⼼也会定时进⾏检查,发现某个实例默认90s内没有再收到⼼跳,会注销此实例,这些时间间隔是可配置的。 2、不过注册中⼼还有⼀个保护模式(服务端在短时间内丢失过多客户端的时候,就会进⼊保护模式),在这个保护模式下,他会认为是⽹络问题,不会注销任何过期的实例。
消费者是如何发现服务提供者的
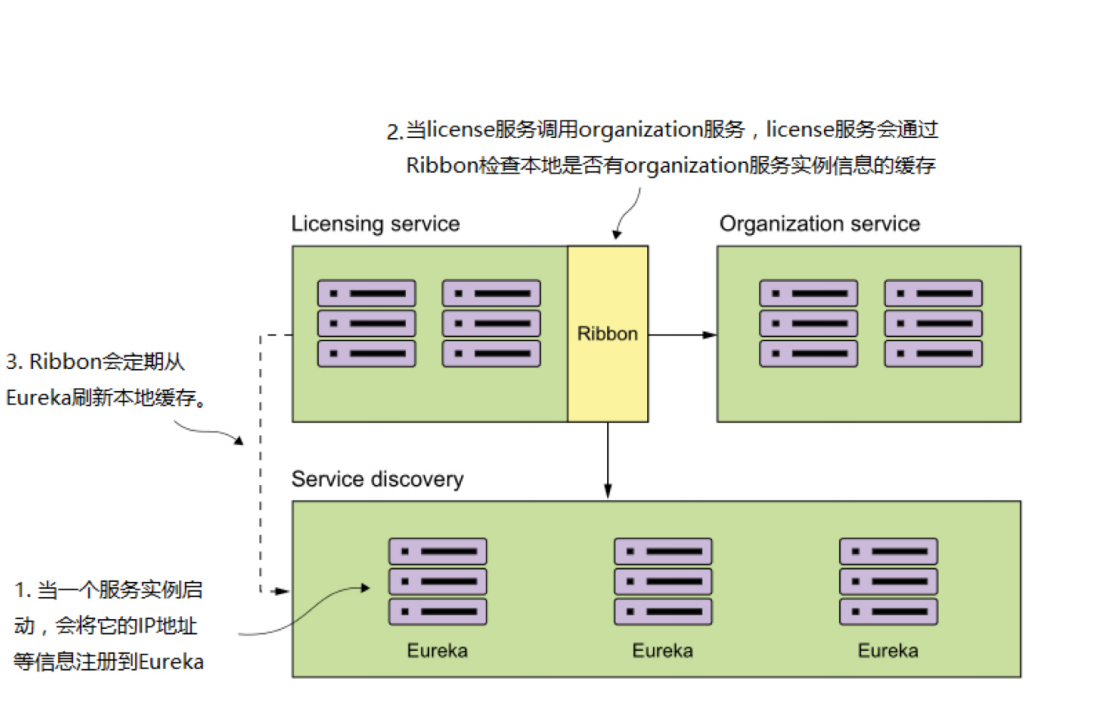 a. 当⼀个服务实例启动,会将它的ip地址等信息注册到eureka; b. 当a服务调⽤b服务,a服务会通过Ribbon检查本地是否有b服务实例信息的缓存; c. Ribbon会定期从eureka刷新本地缓存。
a. 当⼀个服务实例启动,会将它的ip地址等信息注册到eureka; b. 当a服务调⽤b服务,a服务会通过Ribbon检查本地是否有b服务实例信息的缓存; c. Ribbon会定期从eureka刷新本地缓存。
-
多个消费者调⽤同⼀接⼝,eruka默认的分配⽅式是什么 a. RoundRobinRule:轮询策略,Ribbon以轮询的⽅式选择服务器,这个是默认值。所以示例中所启动的两个服务会被循环访问; b. RandomRule:随机选择,也就是说Ribbon会随机从服务器列表中选择⼀个进⾏访问; c. BestAvailableRule:最⼤可⽤策略,即先过滤出故障服务器后,选择⼀个当前并发请求数最⼩的; d. WeightedResponseTimeRule:带有加权的轮询策略,对各个服务器响应时间进⾏加权处理,然后在采⽤轮询的⽅式来获取相 应的服务器; e. AvailabilityFilteringRule:可⽤过滤策略,先过滤出故障的或并发请求⼤于阈值⼀部分服务实例,然后再以线性轮询的⽅式从 过滤后的实例清单中选出⼀个; f. ZoneAvoidanceRule:区域感知策略,先使⽤主过滤条件(区域负载器,选择最优区域)对所有实例过滤并返回过滤后的实例 清单,依次使⽤次过滤条件列表中的过滤条件对主过滤条件的结果进⾏过滤,判断最⼩过滤数(默认1)和最⼩过滤百分⽐(默 认0),最后对满⾜条件的服务器则使⽤RoundRobinRule(轮询⽅式)选择⼀个服务器实例。
springcloud学习笔记
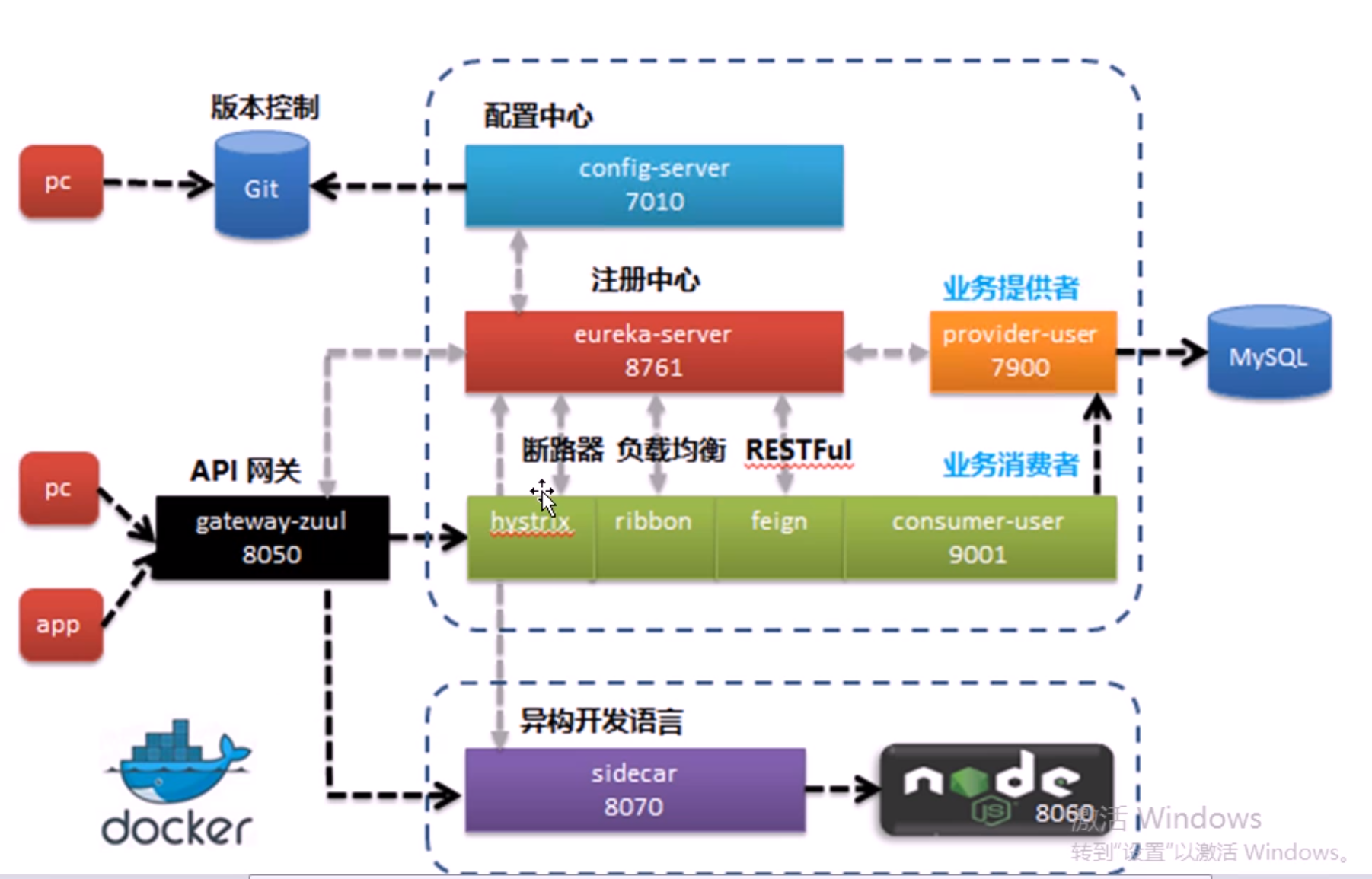
单体项目:各个业务模块 垂直拆分+水平拆分:各个系统 微服务:业务垂直拆分粒度更细
Dubbo 基于RPC的微服务框架
SOA 面向架构编程
N面向
a.面向过程 POP
b.面向对象 OOP
c.面向切面 AOP
d.面向服务/架构 SOA
ESB 企业级服务总线(热插拔)太重(所有项目) 延伸,提供服务,微服务Dubbo,Dubbo——SOA 最佳实践(阿里出品) Ddubbo 两件最重要的事情:1.服务动态发现 Zookeeper(热插拔) 2.RPC hession序列化,反序列化
Spring和Dubbo比较
Dubbo:阿里 3.0 支持stream。基于RPC,hession序列化算法,压缩,二进制,长连接 (直播)。 将来我只是spring cloud一个子集,只专注于RPC解决方案,追求性能。
SpringCloud:基于REST+json,heepclient
两者比较:
性能:subbo远远超过springcloud
异构开发语言支持:springcloud使用json
Eureka 注册中心
import org.springframework.beans.factory.annotation.Value;
public class Person extends BaseEntity{
@Value("xuan")
private String name;
@Value("27")
private int age;
@Value("#{20-7}")
private int count;
@Value("${person.nickName}")
private String nickName;
}
注册中心Eureka设计更加合适!异构开发语音直接支持 阿里,为什么注册中心不适用ZooKeeper。
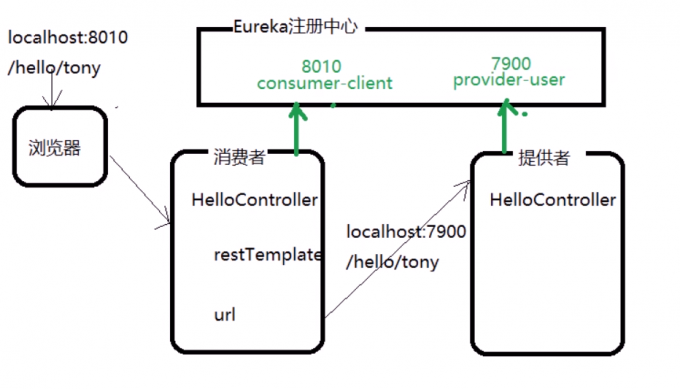
怎么体现使用Eureka动态列表?
再增加一个服务provider-user2,一样业务
过程中也体现负载均衡
故障自动恢复
CAP 定理
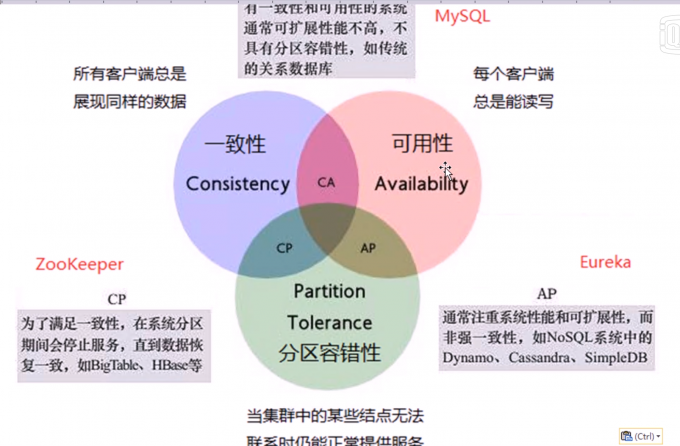
分布式系统设计定理,P分区容错性必须实现,实现方式AP侧重可用性,CP侧重一致性 C 一致性:MySQL Oracle SQL server DRMS 数据要有唯一出处。外键。
A 可用性:哪怕消息已经旧的。使用消息不太变化的。
P 分区容错性。
针对注册中心特点,注册信息不会频繁发生变化,Eureka设计目标AP,zookeeper设计目标CP,这时针对注册中心,eureka更合适。
-
Zookeeper 支持集群,主从结构(leader,follows)zk 节点如果有半数节点宕机,此时zk集群不让用。zk如果在选举过程中,也不能使用。
-
Eureka 也支持集群,点对点,每两个点互为主从。哪怕剩下最后一个节点,仍然能继续访问。最后这个节点宕机,照样用。Server 和 Client,Client 本低有缓存!Eureka宁可错误,也要试试。
Ribbon 前端负载均衡器
Nginx 反向代理,Ribbon可以在访问消费者本地增加缓存,客户端发起请求前它的路见已经决定。 Nginx没有故障处理,也就是说,它代理某个服务宕机,或者无法访问。它不能告诉程序。程序调用才出错,等一会(超时时间),抛出异常。Ribbon依赖Eureka动态列表。Eureka客户端有向服务端定时发心跳,如果客户端阈值(几次机会)之后,宣布服务死亡,Eureka会把其服务从列表中移除。Eureka客户端它的心跳处理时,顺便判断列表有无更新。如果判断有更新,从新获取一个新的数据。
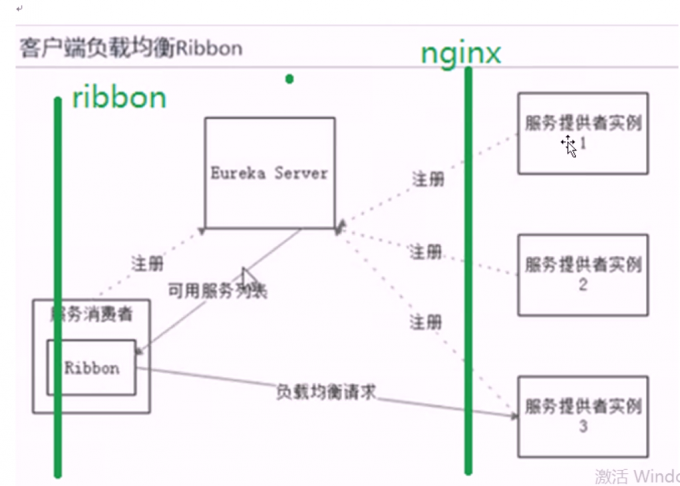
Nginx
why
使用C语音,5w/s
Apache 2k/s,F5硬件20w;9w/s
底层原理,5种!默认轮询 权重 ip_hash url_hash fair 第三方支持
挖陷阱
Feign 声明式接口
如果使用RestTemplate学习成本比较高。
RestTemplate spring出品的模板对象封装底层的API,更好的调用 feign比它结构更好。
Dubbo对外暴露接口
好处:以接口形式体现,接口和业务挂钩,业务程序员必须增加做。做接口同时对业务更加了解。屏蔽复杂API学习成本,解决API太繁琐,而且版本升级API不同。
Feign is a declarative web service client. 声明式It makes writing web service clients easier. 写webservice程序非常容易To use Feign create an interface and annotate it. 接口+注解It has pluggable annotation support including Feign annotations and JAX-RS annotations 可插拔的支持包括feign的注解和jrs的注解Feign also supports pluggable encoders and decoders.解决Get请求中文乱码Spring Cloud adds support for Spring MVC annotations and 支持mvc注解。for using the same HttpMassageConverters used by default in Spring Web.Spring Cloud integrates Ribbon and Eureka to provide a load balanced http client when using Feign.
WebService
SOA时用的,ESB时后端,WebService是一个前端结构
用ApacheCXF实现 ApacheCXF底层用的xml,封装HTTP,形成新的协议SAOP简单对象访问协议
WebService支持异构开发语言。.net<>java 转换效率极其低。
txt > xml 结构化 > json [{x,y},{}]
现在都用:httpClient+json(REST)
J2EE jws规范 jrs规范
Feign底层会给我们写的接口来创建实例 
使用jdk动态代理 $ProxyN (cglib动态代理(CFLIB))
Hystrix 断路器(熔断器)
//启动Hytrix
@SpringBootApplication
@EnableFeignClients
@EnableCircuitBreaker
//标识启动Hytrix
public class HytrixRunApp{
public static void main(String[] args){ SpringApplication.run(HytrixRunApp.class,args);
}
}
雪崩
超时机制,30s,30m. 缺点:超时时间可能设置太长了,手工解决。
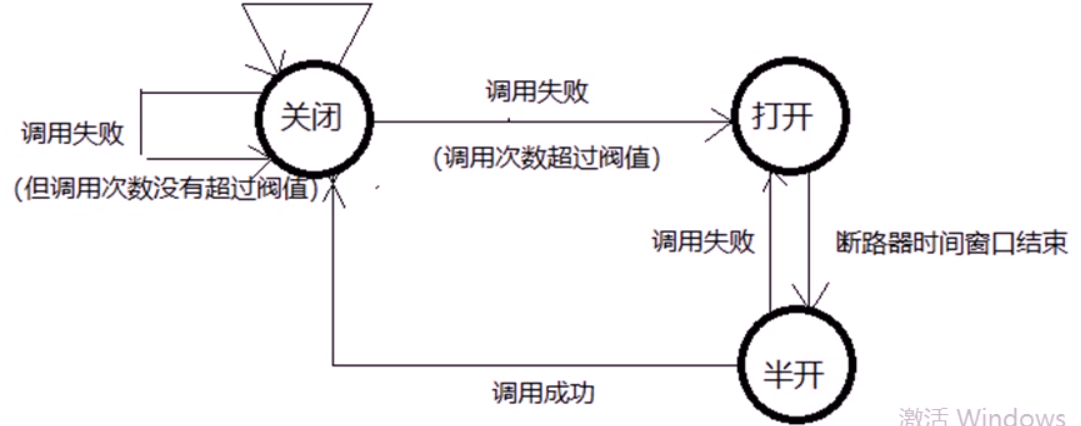
断路器有三种状态:
关闭:当访问没有问题时,断路器处于关闭未使用
打开:当访问开始出现异常,错误次数增多,达到阀值时就会打开断路器,这样服 务直接访问断路器,断路器会再尝试访问,如果失败直接返回.
半开:那服务一直走断路器,系统就没法用了,万一被调用的服务以及稳定了呢. 断路器的优势就来了,过一定时间窗口后(若干秒)它就会自动分流一部分服务再 去尝试访问之前失败的服务.如果继续失败,那就不再转发,如果一个成功立即关 闭断路器。
Netflux出品Hytrix,API繁琐,javanica把hystrix又封装了一层,但是调用更加简洁。
spring-boot-starter-actuator 一旦我们需要监控系统的信息,需要系统提供给我们丰富日志信息,方便监控必须开启这个依赖

hystrix面试答术
For example, for an application that depends on 30 services where each service has 99.99% here is what you can expect:
99.9930 = 99.7% uptime 0.3% of 1 billion requests = 3,000,000 failures 2+ hours downtime/month even if all dependencies have excellent uptime.
随着服务请求次数和服务数量的增加,错误次数也增强加。传统方法只能抛出异常,提示用户不可用。断路器可以快速响应用户,第一种就快速失败。第二种返回预先定义的值。
创建一个springboot应用程序,手写pom.xml增加依赖starter-hystrix,hystrix基于ribbon和feign来开发
在原来ribbon和feign项目基础上,修改它的启动类,增加@EnableCircuitBreaker注解即可
在controller中增加一个注解,@HystrixCommand,有一个参数fallbackMethod失败返回回调的一个方法名。在这个controller下再声明一个回调方法,这个参数和参数类型、返回值、返回值类型必须和配置的这个方法一致。
用户直接请求Hystrix消费者就可以
Hystrix提供3种状态,当访问异常时,尝试多次(阈值),如果还无法访问成功,断路器由“关闭”状态切换“打开”状态。业务如果继续有人访问,如果失败,继续处于“半开”状态,一旦有访问成功,状态立即切换到“关闭”。
Zuul API Gateway 网关 (怪兽)
//启动zuul
@SpringBootApplication
@EnableZuulproxy
@EnableEurekaClient //zuul服务要注册到Eureka上
public class ZuulAppRun{
public static void main(String[] args){ SpringApplication.run(ZuulAppRun.class,args);
}
}
server: port: 8050spring: application: name: zuuleureka: client: serviceUrl: defaultZone: hhtp://user:password123@localhost:8761/eurekalogging: level: root: INFOzuul: routes: user-app: path: /user/** serviceId: provider-user sidecar-app: path: /car/** serviceId: sidecar
Gateway 网关开发方式
1.nginx+lua(linux shell 脚本) 5w/s 2.springcloud gateway 3.springcloud zuul2.0 100w/s
客户端与微服务直接通信的问题。
1 .客 户 端 需 求 和 每 个 微 服 务 暴 露 的 细 粒 度A P I不 匹 配 。 在 这 个 例 子 中 , 客 户 端 需 要 发 送 7 个 独 立 请 求 。 在 更 复 杂 的 应 用 程 序 中 , 可 能 要 发 送 更 多 的 请 求 ; 按 照 Amazon的说法,他们在显示他们的产品页面时就调用了数百个服务。然而,客户 端通过LAN发送许多请求,这在公网上可能会很低效,在移动网络上就根本不可 行。这种方法还使得客户端代码非常复杂。 2 .客 户 端 直 接 调 用 微 服 务 的 另 一 个 问 题 是 , 部 分 服 务 使 用 的 协 议 对w e b并 不 友 好 。 一 个 服 务 可 能 使 用 T h r i f t 二 进 制 R P C , 而 另 一 个 服 务 可 能 使 用 A M Q P 消 息 传 递 协议。不管哪种协议对于浏览器或防火墙都不够友好,最好是内部使用。在防火墙 之外,应用程序应该使用诸如HfTP和WebSocket之类的协议。 3 .另一个缺点是,它会使得微服务难以重构。随着时间推移,我们可能想要更改系统 拆分服务的方式。例如,我们可能合并两个服务,或者将一个服务拆分成两个或更 多服务。然而,如果客户端与微服务直接通信,那么执行这类重构就非常困难了
静态资源怎么处理?
静态资源:js、css、imag、html
tomcat
nginx
browser
zuul
browser>zuul>nginx>tomcat
底层原理:拦截器、过滤器
application.yml
zuul:routes: 路由 app-a: 随便写,唯一代表 path: /user/** 映射了一个路径/userhello/tony **当前层下所有子路径 serviceld: provide-user 提供者application.name
方便过滤,/admin,不同的前缀就可以支持不同的权限过滤,前缀就相当于一个分类
zuul面试答术
SpringCloud是几月RESTFul+json形式,访问链接没有安全性。引入API网关,对于访问者进行授权验证。把非法用户禁止访问,提升整个系统安全。
微服务架构,把服务拆分成很多细小的服务,带来一个问题。之前在一个方法内部完成,变成多个微服务远程调用,发起端就需要发起多个微服务请求,每个微服务都有创建和销毁,这样编码繁琐,也占用更多资源。API网关就可以合成一次调用,内部发起多次请求,将结果拼成一个结果。
屏蔽很多开发结构RPC,JSON,异构。
拦截器、缓存、授权等等
直接软件公司做微服务来卖!可以监控调用次数和时长。(天齐预报)
Sidecar 异构开发语言
//启动Hytrix
@SpringBootApplication
@EnableSidecar
@EnableCircuitBreaker
//标识启动Hytrix
public class SidecarRunApp{
public static void main(String[] args){
SpringApplication.run(SidecarRunApp.class,args);
}
}
server: port: 8070spring: application: name: sidecareureka: client: serviceUrl: defaultZone: hhtp://user:password123@localhost:8761/eurekasidecar: port: 8060 health-url: http://localhost:8086/health.json
异构开发语言,多种语言互相访问。
传统怎么处理异构开发语言支持
二进制,截串 TCP 2jkj34890(通讯协议) 电信
txt,edi报文(国际物流)kv
xml 标签,灵活,dom4j。sax。WebService ApacheCXF。废弃性能太低。xml传输标签太多,影响传输性能。xml纯文本,安全性差。它事先要自动生成java类。符合标准:基于HTTP 协议SOAP简单对象访问协议。封装多层后转化多次时间都浪费了。
json,京陶httpclient+json,json内容没有xml那么多标签,节约大量空间,传输效率高,但比txt有结构,直接获取其中一个值,方便转化成object。
转化工具类:jackson、fastjson阿里
SpringCloud出品Sidecar。它把我们的程序封装了一下。对外暴露RESTFul+json返回
NodeJS
JS天生缺点:同源策略,js跨域。解决跨域问题:jsonp。 同源策略,使js称为脚本语言。弱语言。不允许访问本地资源(磁盘、内存、CPU) NodeJS,它完成一个web服务器(后端),可以存储本地资源。本地隔离。这样JS也可以做整个其他语言所能做的事情。
NodeJS基于chrome v8,号称目前为止解析js最快引擎。成为一个类似tomcat。
前端工程师什么都能做了?
互联网架构(外延,nginx C语言,rabbitmq erlang高并发语言,docker go 语言)
大数据(Hadoop生态链java、Spark生态链scala 编译完就是Java语句,下一代java)
java1.8引入lamda表达式(函数式编程)面向对象+面向函数 lamda出自scala
sidecar面试答术
实际系统中由于历史原因,.net,php;开发团队技术原因。
springcloud选型RESTFul+json,因为完全支持异构。
sidecar把异构开发语言,对外暴露url地址,做了映射。结合Zull映射。
启动NodeJS,安装完成 node node-service.js直接执行,启动web服务。Sidecar把nodejs映射来封装
sidecar: port: 8060 端口 health-url: http://localhost:8086/health.json 访问健康地址,必须,提供给平台感知服务死活。如果暂停这个服务。Status:DOWNZuul配置中映射:
zuul: routes: user-app: path: /user/** serviceId: provider-user sidecar-app: 随便写,不要有重复 path: /car/** 访问多加一级路径,区分不同微服务入口 serviceId: sidecar 映射,到eureka注册apoplication.name
配置中心:SpringCloud-config
静态内容,配置项变化,只能重启服务
动态刷新,手动变化,刷新一个连接,必须post请求(httpclient)
STS eclipse , spring出品,对spring项目支持更好,配置文件的提升丰富,创建springboot应用程序。
Browser CDN nginx tomcat
application.properties
server.port=7010spring.application.name=config-server# 配置.git仓库地址spring . cloud . config . server . git . uri=https://github . com/nutony/myspringcloud1806# 配置.仓库的分支spring . cloud . config.label=master# 访问git仓库的用户名spring , cloud . config . server ・ git . username=nutony# 访问git仓库的用户密码如果Git仓库为公开仓库,可以不填写用户名和密码,如果是私有仓库需要填写spring , cloud ・ config.server.git.password=Tonyl23-eureka . client . service-url. defaultZone=http://user:passwordl23@locahost:8761/eureka
@Value("${key}")注解
直接读取属性配置文件的内容。 这个注解是在启动时,spring扫描注解,然后获取属性值的,然后set进去。静态处理。
application.yml在启动之后处理的,读的太晚了。提前读取这个数据,SpringBoot还要其他配置文件:Bootsrap.yml/bootstrap.properties
spring boot加载配置文件顺序:先加载bootstrap.properties,(@Value)然后再加载application.properties。
ConfigServer
动态的配置项:数据库+Redis Redis LRU 算法,最近最久未使用就驱逐 单独给它一个redis节点(集群)
传统方案
写死属性配置文件 jdbc.properties
数据库+redis
配置中心:完全支持分布式,依赖git来完成数据存储 和项目结合
搭建Config-Server
创建SpringBoot项目
增加依赖config-server
配置关联git,
搭建客户端,最终是消费者Config-client
客户端启动时,扫描@Value,去hashmap中找对应key,找不到报错。
动态刷新配置(手工刷新一个连接地址)
http://localhost:7020/refresh访问config-server端,必须以post请求提交,部署在内网,部署到一个需要登陆系统上,对shiro安全校验
在Conreoller上增加一个注解@RefreshScope,pom.xml增加一个依赖starter-actuator监控需要jar依赖
@Value处理在然后再加载application.yml文件处理之前处理。必须换一个配置文件bootstrap。properties。bootstrap启动时间是在application之前。
配置中心,ZooKeeper zk存储数据,数据量非常小,数据字典,树形结构
开发步骤
服务提供者
服务消费者
MyBatisPlus

项目框架:springboot+SSM+MP
通用Mapper MybatisPlus
继承SysMapper,扩展批量删除 继承BaseMapper
在pojo上JPA注解,不写SQL。 自定义注解@TableName
支持分页PageHelper,Mybatis拦截器 在加载时处理
不很好支持查询条件、排序、分组 EntityWrapper包装
QBC(Query By Criteria) 出处 hibernate QBC , 鸡肋,号称面向对象方式
动态生成SQL SELECT id,NAME,birthday,address FROM user” 分析: 1)关键字:SELECT FROM (selectUst) 〃 2)字段:poi。属性,“
表:@Table(〃tb_user")JPA”
项目框架:springmvc+spring+mybatis+myabtisPlus
pojo+mp注解
UserMapper接口,继承BaseMapper
UserServer、UserServicelmpl
UserController
相关依赖 + 代码
<!-- 热部署支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
<!-- eureka服务提供方 -->
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka-server</artifactId>
</dependency>
</dependencies>
<!-- Hystrix,Feign是基于Hystrix的 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
</dependency>
<!-- Eureka依赖,连接注册中心的都需要有这个依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
</dependency>
<!-- Zuul依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zuul</artifactId>
</dependency>
<!-- Feign依赖,声明式开发 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-feign</artifactId>
</dependency>
<!-- sidecar -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-netflix-sidecar</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-web</artifactId>
</dependency>
<dependencyManagement>
<dependencies>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-depengencies</artifactId>
<version>Dalston.SR1</version>
<type>pom</type>
<scope>import</scope>
</dependencies>
</dependencyManagement>
//@PathVariable用法
@RequestMapping("/get/{id}")
public User get(@PathVariable Interger id){}
//注意:如果对象接收RESTFul参数时,不用@PathVariable
@RequestMapping("/insert/{name}/{birthday}/{address}")
public String insert(User user){}
-
提供者 provider-user
@SpringBootApplication
@EnableEurekaClient //eureka客户端
public class ProviderRunApp {
public static void main(String[] args) {
SpringApplication.run(ProviderRunApp.class, args);
}
}
@RestController
public class HelloController {
@GetMapping("/hello/{name}")
public String hello(@PathVariable String name) {
return "1:"+name;
}
}
-
消费者 consumer-client
@SpringBootApplication
@EnableEurekaClient //eureka客户端
public class ConsumerRunApp{
@Bean //初始化模板对象
@LoadBalanced //Ribbon负载均衡 RestTemplate是spring出品的模板对象封装底层的API,更好的调用 feign比它结构更好。
public RestTemplate restTemplate(){
return new RestTemplate();
}
public static void main(String[] args){
SpringApplication.run(ConsumerRunApp.class,args);
}
}
@RestController //控制类
public class HelloController{
@Autowired
private RestTemplate restTemplate;
@GetMapping("/hello/{name}")
@ResponseBody
public String hello(@PathVariable String name){
String url = "http://localhost:7900/hello"; //直接访问
//使用Eureka动态列表,通过Application.name找到真正提供地址
url="http://provider-user:7900//hello/"+name;
return this.restTemplate.getForObject(url,String.class);
}
}
>>>>>>>>>>>>>>>>>>>>>>>> RestTemplate改用feign后
@RestController //控制类
public class HelloController{
@Autowired
private EurekaServiceFeign feign;
@GetMapping("/hello/{name}")
@ResponseBody
public String hello(@PathVariable String name){
return feign.hello(name); //调用服务提供者
}
} -
消费者 consumr-feign
//引入Feign,以接口对外暴露,从而封装底层操作
//这个接口相当于把原来的服务提供者项目当成一个Service类
@FeignClient(value=”provider-user“) //跟提供者关联
public interface EurekaServiceFeign{
//feign中没有原生的@GetMapping/@PostMapping/@PutMapping,要指定需要用method进行
@RequestMapping(value="/hello/{name}",method=RequestMethod.GET)
public String hello(@PathVariable("name") String name);
}
//启动Feign
@SpringCloudApplication //启动Feign时必须使用Cloud
@EnableFeignClients //标识Feign程序
public class FeignRunApp{
public static void main(String[] args){
SpringApplication.run(FeignRunApp.class,args);
}
} -
消费者 consumr-hytrix
@RestController //控制类
public class HelloController{
@Autowired
private EurekaServiceFeign feign;
@GetMapping("/hello/{name}")
@HytrixCommand(fallbackMethod="fallbackHello")
public String hello(@PathVariable String name){
return feign.hello(name); //调用服务提供者
}
//失败时,断路器自动回调这个方法
//方法名字和fallbackMethod名称一致,参数和返回值一致。
public String fallbackHello(String name){
//设置一个失败时的默认值
return “失败”;
}
}
-
yaml文件格式
#普通数据的配置
name: zhangsan
#对象的配置
person:
name: zhangsan
age: 18
addr: beijing
#行内对象配置
animal: {name: duck, age: 1, color: white}
#配置数组、集合(普通字符串)
city:
-beijing
-tianjin
-chongqing
-shanghai
color: [blue,white,yellow,red]
#配置数组、集合(对象数据)
student:
- name: tom
age: 12
addr: beijing
- name: lucy
age: 23
addr: tianjin
teachers: [{name: tom,age: 12,addr: beijing},{name: lucy,age: 23,addr: tianjin}]
#map 配置
map:
key1: value1
key2: value2
————————————————
版权声明:本文为CSDN博主「Jing-Kathy」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/luckystar_99/article/details/103596277
Zookeeper
Zookeeper是一个开发和维护实现高度可靠的分布式协调的开源服务器,既然是分布式协调,那最大的特点就是高度可靠,也因此受各大公司分布式应用的青睐,因为学习掌握zookeeper知识也是非常重要的,今天为大家带来Zookeeper的高频面试题,希望至少能让乡亲们有些概念上的理解,也算一点帮助。
1、ZooKeeper 是什么?
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现, 它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易 用的接口和性能高效、功能稳定的系统提供给用户。客户端的读请求可以被集群中的任意一台机器处理,如果Sidecar 异构开发语言读请求在节点上注册了监听器,这个监听器也是由所 连接的 zookeeper 机器来处理。对于写请求,这些请求会同时发给其他 zookeeper 机器并且达成一致后,请 求才会返回成功。因此,随着 zookeeper 的集群机器增多,读请求的吞吐会提高但是写请求的吞吐会下降。有序性是 zookeeper 中非常重要的一个特性,所有的更新都是全局有序的,每个更新都有一个唯一的时间戳, 这个时间戳称为 zxid(Zookeeper Transaction Id)。而读请求只会相对于更新有序,也就是读请求的返回 结果中会带有这个 zookeeper 最新的 zxid。
2、ZooKeeper 提供了什么?
-
文件系统
-
通知机制
3、Zookeeper 文件系统
Zookeeper 提供一个多层级的节点命名空间(节点称为 znode)。与文件系统不同的是,这些节点都可以设置 关联的数据,而文件系统中只有文件节点可以存放数据而目录节点不行。Zookeeper 为了保证高吞吐和低延 迟,在内存中维护了这个树状的目录结构,这种特性使得 Zookeeper 不能用于存放大量的数据,每个节点的存 放数据上限为 1M。
4、四种类型的数据节点 Znode
-
PERSISTENT-持久节点 除非手动删除,否则节点一直存在于Zookeeper上
-
EPHEMERAL-临时节点 临时节点的生命周期与客户端会话绑定,一旦客户端会话失效(客户端与zookeeper连接断开不一定会话失效),那么这个客户端创建的所有临时节点都会被移除。
-
PERSISTENT_SEQUENTIAL-持久顺序节点 基本特性同持久节点,只是增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
-
EPHEMERAL_SEQUENTIAL-临时顺序节点 基本特性同临时节点,增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
5、Zookeeper Watcher 机制 -- 数据变更通知
Zookeeper允许客户端向服务端的某个Znode注册一个Watcher监听,当服务端的一些指定事件触发了这个Watcher,服务端会向指定客户端发送一个事件通知来实现分布式的通知功能,然后客户端根据Watcher通知状态和事件类型做出业务上的改变。
工作机制:
-
客户端注册watcher
-
服务端处理watcher
-
客户端回调watcher
Watcher特性总结:
-
一次性 无论是服务端还是客户端,一旦一个Watcher被触发,Zookeeper都会将其从相应的存储中移除。这样的设计有效的减轻了服务端的压力,不然对于更新非常频繁的节点,服务端会不断的向客户端发送事件通知,无论对于网络还是服务端的压力都非常大。
-
客户端串行执行 客户端Watcher回调的过程是一个串行同步的过程。
-
轻量
-
-
Watcher通知非常简单,只会告诉客户端发生了事件,而不会说明事件的具体内容。
-
客户端向服务端注册Watcher的时候,并不会把客户端真实的Watcher对象实体传递到服务端,仅仅是在客户端请求中使用boolean类型属性进行了标记。
-
-
watcher event异步发送watcher的通知事件从server发送到client是异步的,这就存在一个问题,不同的客户端和服务器之间通过socket进行通信,由于网络延迟或其他因素导致客户端在不通的时刻监听到事件,由于Zookeeper本身提供了ordering guarantee,即客户端监听事件后,才会感知它所监视znode发生了变化。所以我们使用Zookeeper不能期望能够监控到节点每次的变化。Zookeeper只能保证最终的一致性,而无法保证强一致性。
-
注册watcher getData、exists、getChildren
-
触发watcher create、delete、setData
-
当一个客户端连接到一个新的服务器上时,watch将会被以任意会话事件触发。当与一个服务器失去连接的时候,是无法接收到watch的。而当client重新连接时,如果需要的话,所有先前注册过的watch,都会被重新注册。通常这是完全透明的。只有在一个特殊情况下,watch可能会丢失:对于一个未创建的znode的exist watch,如果在客户端断开连接期间被创建了,并且随后在客户端连接上之前又删除了,这种情况下,这个watch事件可能会被丢失。
6、客户端注册Watcher实现
-
调用getData()/getChildren()/exist()三个API,传入Watcher对象
-
标记请求request,封装Watcher到WatchRegistration
-
封装成Packet对象,发服务端发送request
-
收到服务端响应后,将Watcher注册到ZKWatcherManager中进行管理
-
请求返回,完成注册。
7、服务端处理Watcher实现
-
服务端接收Watcher并存储 接收到客户端请求,处理请求判断是否需要注册Watcher,需要的话将数据节点的节点路径和ServerCnxn(ServerCnxn代表一个客户端和服务端的连接,实现了Watcher的process接口,此时可以看成一个Watcher对象)存储在WatcherManager的WatchTable和watch2Paths中去。
-
Watcher触发 以服务端接收到 setData() 事务请求触发NodeDataChanged事件为例:
-
-
封装WatchedEvent 将通知状态(SyncConnected)、事件类型(NodeDataChanged)以及节点路径封装成一个WatchedEvent对象
-
查询Watcher 从WatchTable中根据节点路径查找Watcher
-
没找到;说明没有客户端在该数据节点上注册过Watcher
-
找到;提取并从WatchTable和Watch2Paths中删除对应Watcher(从这里可以看出Watcher在服务端是一次性的,触发一次就失效了)
-
-
调用process方法来触发Watcher 这里process主要就是通过ServerCnxn对应的TCP连接发送Watcher事件通知。
8、客户端回调Watcher
客户端SendThread线程接收事件通知,交由EventThread线程回调Watcher。客户端的Watcher机制同样是一次性的,一旦被触发后,该Watcher就失效了。
9、服务器角色
Leader
-
事务请求的唯一调度和处理者,保证集群事务处理的顺序性
-
集群内部各服务的调度者
Follower
-
处理客户端的非事务请求,转发事务请求给Leader服务器
-
参与事务请求Proposal的投票
-
参与Leader选举投票
Observer
3.3.0版本以后引入的一个服务器角色,在不影响集群事务处理能力的基础上提升集群的非事务处理能力
-
处理客户端的非事务请求,转发事务请求给Leader服务器
-
不参与任何形式的投票
10、Zookeeper 通知机制
client 端会对某个 znode 建立一个 watcher 事件,当该 znode 发生变化时,这些 client 会收到 zk 的通知, 然后 client 可以根据 znode 变化来做出业务上的改变等。
11、Zookeeper 做了什么?
1、命名服务
2、配置管理
3、集群管理
4、分布式锁
5、队列管理
12、主从集群和主备集群的区别?
-
主从集群:一主多从,主从各司其职,主节点负责资源分配和任务调度,从节点负责具体的执行;
-
主备集群:一主一备,主要是为了解决单点故障问题,便于备份恢复
13、zookeeper为什么能保证全局数据一致性?
(1)首先,zookeeper集群每个节点都可以接收到客户端请求;
(2)其次,客户端请求分为两种请求,一种请求是事务性请求,另一种是非事务性请求,下边就这两种请求展开论述:
1)事务性请求:当事务性请求是从节点接收到的,就会将请求转发给主节点,然后让主节点按照时间顺序来指定各个节点完 成请求;当事务性请求是主节点接收到的,主节点将会直接自己按照客户端请求顺序来处理请求;
2)非事务性请求:任何节点收到了都可以自行处理;
14、Zookeeper有哪几种节点类型
-
持久:创建之后一直存在,除非有删除操作,创建节点的客户端会话失效也不影响此节点。
-
持久顺序:跟持久一样,就是父节点在创建下一级子节点的时候,记录每个子节点创建的先后顺序,会给每个子节点名加上一个数字后缀。
-
临时:创建客户端会话失效(注意是会话失效,不是连接断了),节点也就没了。不能建子节点。
-
临时顺序:不用解释了吧。
15、Zookeeper 分布式锁(文件系统、通知机制)
有了 zookeeper 的一致性文件系统,锁的问题变得容易。锁服务可以分为两类:
-
保持独占
-
控制时序
对于第一类,我们将 zookeeper 上的一个 znode 看作是一把锁,通过 createznode 的方式来实现。所有客户 端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除掉自己创建的distribute_lock 节点就释放出锁。
对于第二类, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选master 一样,编号最小的获得锁,用完删除,依次方便。
16、一个客户端修改了某个节点的数据,其他客户端能够马上获取到这个最新数据吗?
ZooKeeper 不能确保任何客户端能够获取(即 Read Request)到一样的数据,除非客户端自己要求,方法是客户端在获取数据之前调用 sync。通常情况下(这里所说的通常情况满足:1. 对获取的数据是否是最新版本不敏感,2. 一个客户端修改了数据,其它客户端是否需要立即能够获取最新数据),可以不关心这点。在其它情况下,最清晰的场景是这样:ZK 客户端 A 对 /my_test 的内容从 v1->v2, 但是 ZK 客户端 B 对 /my_test 的内容获取,依然得到的是 v1. 请注意,这个是实际存在的现象,当然延时很短。解决的方法是客户端 B 先调用 sync(), 再调用 getData()。
17、Zookeeper 数据复制
Zookeeper 作为一个集群提供一致的数据服务,自然,它要在所有机器间做数据复制。数据复制的好处:
-
容错:一个节点出错,不致于让整个系统停止工作,别的节点可以接管它的工作。
-
提高系统的扩展能力:把负载分布到多个节点上,或者增加节点来提高系统的负载能力。
-
提高性能:让客户端本地访问就近的节点,提高用户访问速度。
从客户端读写访问的透明度来看,数据复制集群系统分下面两种:
-
写主(WriteMaster) :对数据的修改提交给指定的节点。读无此限制,可以读取任何一个节点。这种情况下 客户端需要对读与写进行区别,俗称读写分离。
-
写任意(Write Any):对数据的修改可提交给任意的节点,跟读一样。这种情况下,客户端对集群节点的角 色与变化透明。
对 zookeeper 来说,它采用的方式是写任意。通过增加机器,它的读吞吐能力和响应能力扩展性非常好,而 写,随着机器的增多吞吐能力肯定下降(这也是它建立 observer 的原因),而响应能力则取决于具体实现方 式,是延迟复制保持最终一致性,还是立即复制快速响应。
18、Zooke**eper 工作原理**
Zookeeper 的核心是原子广播,这个机制保证了各个 Server 之间的同步。实现这个机制的协议叫做 Zab 协议。Zab 协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃 后,Zab 就进入了恢复模式,当领导者被选举出来,且大多数 Server 完成了和 leader 的状态同步以后,恢复 模式就结束了。状态同步保证了 leader 和 Server 具有相同的系统状态。
19、ZooKeeper 的监听原理是什么?
在应用程序中,mian()方法首先会创建 zkClient,创建 zkClient 的同时就会产生两个进程,即Listener 进程(监听进程)和connect 进程(网络连接/传输进程),当zkClient 调用getChildren()等方法注册监视器时,connect 进程向 ZooKeeper 注册监听器,注册后的监听器位于ZooKeeper 的监听器列表中,监听器列表中记录了 zkClient 的 IP,端口号以及要监控的路径,一旦目标文件发生变化,ZooKeeper 就会把这条消息发送给对应的zkClient 的Listener()进程,Listener 进程接收到后,就会执行 process()方法,在 process()方法中针对发生的事件进行处理。
20、zookeeper 是如何保证事务的顺序一致性 的?
zookeeper 采用了递增的事务 Id 来标识,所有的 proposal(提议)都在被提出的时候加上了 zxid,zxid 实际 上是一个 64位的数字,高 32 位是 epoch(时期; 纪元; 世; 新时代)用来标识 leader 是否发生改变,如果有 新的 leader 产生出来,epoch 会自增,低 32 位用来递增计数。当新产生 proposal 的时候,会依据数据库的 两阶段过程,首先会向其他的 server 发出事务执行请求,如果超过半数的机器都能执行并且能够成功,那么就 会开始执行。
21、分布式集群中为什么会有Master?
在分布式环境中,有些业务逻辑只需要集群中的某一台机器进行执行,其他的机器可以共享这个结果,这样可以大大减少重复计算,提高性能,于是就需要进行leader选举。
22、Zookeeper 下 Server 工作状态
服务器具有四种状态,分别是LOOKING、FOLLOWING、LEADING、OBSERVING。
-
LOOKING:寻找Leader状态。当服务器处于该状态时,它会认为当前集群中没有Leader,因此需要进入Leader选举状态。
-
FOLLOWING:跟随者状态。表明当前服务器角色是Follower。
-
LEADING:领导者状态。表明当前服务器角色是Leader。
-
OBSERVING:观察者状态。表明当前服务器角色是Observer。
23、zookeeper 是如何选取主 leader 的?
当 leader 崩溃或者 leader 失去大多数的 follower,这时 zk 进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的 Server 都恢复到一个正确的状态。Zk 的选举算法有两种:一种是基于 basic paxos 实现 的,另外一种是基于 fast paxos 算法实现的。系统默认的选举算法为 fast paxos。
1、Zookeeper 选主流程(basic paxos)
-
选举线程由当前 Server 发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
-
选举线程首先向所有 Server 发起一次询问(包括自己);
-
选举线程收到回复后,验证是否是自己发起的询问(验证 zxid 是否一致),然后获取对方的 id(myid),并存 储到当前询问对象列表中,最后获取对方提议的 leader 相关信息(id,zxid),并将这些信息存储到当次选举的投 票记录表中;
-
收到所有 Server 回复以后,就计算出 zxid 最大的那个 Server,并将这个 Server 相关信息设置成下一次 要投票的 Server;
-
线程将当前 zxid 最大的 Server 设置为当前 Server 要推荐的 Leader,如果此时获胜的 Server 获得 n/2 + 1 的 Server 票数,设置当前推荐的 leader 为获胜的 Server,将根据获胜的 Server 相关信息设置自己的状 态,否则,继续这个过程,直到 leader 被选举出来。通过流程分析我们可以得出:要使 Leader 获得多数Server 的支持,则 Server 总数必须是奇数 2n+1,且存活的 Server 的数目不得少于 n+1. 每个 Server 启动后 都会重复以上流程。在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的 server 还会从磁盘快照中恢复数据和会话信息,zk 会记录事务日志并定期进行快照,方便在恢复时进行状态恢复。
2、Zookeeper 选主流程(basic paxos)
fast paxos 流程是在选举过程中,某 Server 首先向所有 Server 提议自己要成为 leader,当其它 Server 收到提 议以后,解决 epoch 和 zxid 的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流程,最后一定能选举出 Leader。
24、Zookeeper 同步流程
选完 Leader 以后,zk 就进入状态同步过程。
-
Leader 等待 server 连接;
-
Follower 连接 leader,将最大的 zxid 发送给 leader;
-
Leader 根据 follower 的 zxid 确定同步点;
-
完成同步后通知 follower 已经成为 uptodate 状态;
-
Follower 收到 uptodate 消息后,又可以重新接受 client 的请求进行服务了。
25、分布式通知和协调
对于系统调度来说:操作人员发送通知实际是通过控制台改变某个节点的状态,然后 zk 将这些变化发送给注册 了这个节点的 watcher 的所有客户端。对于执行情况汇报:每个工作进程都在某个目录下创建一个临时节点。并携带工作的进度数据,这样汇总的进 程可以监控目录子节点的变化获得工作进度的实时的全局情况。
26、机器中为什么会有 leader?
在分布式环境中,有些业务逻辑只需要集群中的某一台机器进行执行,其他的机器可以共享这个结果,这样可 以大大减少重复计算,提高性能,于是就需要进行 leader 选举。
27、zk 节点宕机如何处理?
Zookeeper 本身也是集群,推荐配置不少于 3 个服务器。Zookeeper 自身也要保证当一个节点宕机时,其他 节点会继续提供服务。
如果是一个 Follower 宕机,还有 2 台服务器提供访问,因为 Zookeeper 上的数据是有多个副本的,数据并不 会丢失;
如果是一个 Leader 宕机,Zookeeper 会选举出新的 Leader。
ZK 集群的机制是只要超过半数的节点正常,集群就能正常提供服务。只有在 ZK 节点挂得太多,只剩一半或不 到一半节点能工作,集群才失效。 所以:
-
3 个节点的 cluster 可以挂掉 1 个节点(leader 可以得到 2 票>1.5)
-
2 个节点的 cluster 就不能挂掉任何 1 个节点了(leader 可以得到 1 票<=1)
28、zookeeper 负载均衡和 nginx 负载均衡 区别
zk 的负载均衡是可以调控,nginx 只是能调权重,其他需要可控的都需要自己写插件;但是 nginx 的吞吐量比zk 大很多,应该说按业务选择用哪种方式。
29、Zookeeper有哪几种几种部署模式?
部署模式:单机模式、伪集群模式、集群模式。
30、 集群最少要几台机器,集群规则是怎样的?
集群规则为2N+1台,N>0,即3台。
31、集群如果有3台机器,挂掉一台集群还能工作吗?**挂掉两台呢?**
记住一个原则:过半存活即可用。
32、集群支持动态添加机器吗?
其实就是水平扩容了,Zookeeper在这方面不太好。两种方式:
-
全部重启:关闭所有Zookeeper服务,修改配置之后启动。不影响之前客户端的会话。
-
逐个重启:在过半存活即可用的原则下,一台机器重启不影响整个集群对外提供服务。这是比较常用的方式。
3.5版本开始支持动态扩容。
33、Zookeeper对节点的watch监听通知是永久的吗?**为什么不是永久的?**
不是。官方声明:一个Watch事件是一个一次性的触发器,当被设置了Watch的数据发生了改变的时候,则服务器将这个改变发送给设置了Watch的客户端,以便通知它们。
为什么不是永久的,举个例子,如果服务端变动频繁,而监听的客户端很多情况下,每次变动都要通知到所有的客户端,给网络和服务器造成很大压力。 一般是客户端执行getData(“/节点A”,true),如果节点A发生了变更或删除,客户端会得到它的watch事件,但是在之后节点A又发生了变更,而客户端又没有设置watch事件,就不再给客户端发送。
在实际应用中,很多情况下,我们的客户端不需要知道服务端的每一次变动,我只要最新的数据即可。
34、ZAB协议是什么?
ZAB协议是一种专门为zookeeper设计的一种支持崩溃回复的原子广播协议,是一种通用的分布式一致性算法,基于该协议,zookeeper实现了一种主备模式的系统架构来保持集群中各副本之间数据的一致性。具体来说,zookeeper使用一个单一的主进程来接收并处理客户端的所有事务请求,并采用ZAB的原子广播协议,将服务器数据的状态变更为以事务的形式广播到所有的副本进程上去,该协议的这个主备模式架构保证了同一时刻集群中只能够有一个主进程来广播服务器的状态变更。
简言之,该协议核心就是定义了对于那些会改变zookeeper服务器数据状态的事务请求的处理方式,所有事务请求都必须由一个全局唯一的服务器来协调处理,即leader服务器。
35、Zookeeper的典型应用场景
Zookeeper是一个典型的发布/订阅模式的分布式数据管理与协调框架,开发人员可以使用它来进行分布式数据的发布和订阅。
通过对Zookeeper中丰富的数据节点进行交叉使用,配合Watcher事件通知机制,可以非常方便的构建一系列分布式应用中年都会涉及的核心功能,如:
-
数据发布/订阅
-
负载均衡
-
命名服务
-
分布式协调/通知
-
集群管理
-
Master选举
-
分布式锁
-
分布式队列
1. 数据发布/订阅
介绍
数据发布/订阅系统,即所谓的配置中心,顾名思义就是发布者发布数据供订阅者进行数据订阅。
目的
-
动态获取数据(配置信息)
-
实现数据(配置信息)的集中式管理和数据的动态更新
设计模式
-
Push 模式
-
Pull 模式
数据(配置信息)特性:
-
数据量通常比较小
-
数据内容在运行时会发生动态更新
-
集群中各机器共享,配置一致
如:机器列表信息、运行时开关配置、数据库配置信息等
基于Zookeeper的实现方式
-
数据存储:将数据(配置信息)存储到Zookeeper上的一个数据节点
-
数据获取:应用在启动初始化节点从Zookeeper数据节点读取数据,并在该节点上注册一个数据变更Watcher
-
数据变更:当变更数据时,更新Zookeeper对应节点数据,Zookeeper会将数据变更通知发到各客户端,客户端接到通知后重新读取变更后的数据即可。
2. 负载均衡
zk的命名服务
命名服务是指通过指定的名字来获取资源或者服务的地址,利用zk创建一个全局的路径,这个路径就可以作为一个名字,指向集群中的集群,提供的服务的地址,或者一个远程的对象等等。
分布式通知和协调
对于系统调度来说:操作人员发送通知实际是通过控制台改变某个节点的状态,然后zk将这些变化发送给注册了这个节点的watcher的所有客户端。 对于执行情况汇报:每个工作进程都在某个目录下创建一个临时节点。并携带工作的进度数据,这样汇总的进程可以监控目录子节点的变化获得工作进度的实时的全局情况。
zk的命名服**务(文件系统)**
命名服务是指通过指定的名字来获取资源或者服务的地址,利用zk创建一个全局的路径,即是唯一的路径,这个路径就可以作为一个名字,指向集群中的集群,提供的服务的地址,或者一个远程的对象等等。
zk的配置管理(文件系统、通知机制)
程序分布式的部署在不同的机器上,将程序的配置信息放在zk的znode下,当有配置发生改变时,也就是znode发生变化时,可以通过改变zk中某个目录节点的内容,利用watcher通知给各个客户端,从而更改配置。
Zookeeper集群管理(文件系统、通知机制)
所谓集群管理无在乎两点:是否有机器退出和加入、选举master。 对于第一点,所有机器约定在父目录下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除,于是,所有人都知道:它上船了。 新机器加入也是类似,所有机器收到通知:新兄弟目录加入,highcount又有了,对于第二点,我们稍微改变一下,所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为master就好。
Zookeeper分布式锁(文件系统、通知机制)
有了zookeeper的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
对于第一类,我们将zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除掉自己创建的distribute_lock 节点就释放出锁。
对于第二类, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选master一样,编号最小的获得锁,用完删除,依次方便。
Zookeeper队列管理(文件系统、通知机制)
两种类型的队列:
-
同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
-
队列按照 FIFO 方式进行入队和出队操作。
第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。在特定的目录下创建PERSISTENT_SEQUENTIAL节点,创建成功时Watcher通知等待的队列,队列删除序列号最小的节点用以消费。此场景下Zookeeper的znode用于消息存储,znode存储的数据就是消息队列中的消息内容,SEQUENTIAL序列号就是消息的编号,按序取出即可。由于创建的节点是持久化的,所以不必担心队列消息的丢失问题。
Zookeeper获取分布式锁流程
见下题。
** **
36、Zookeeper是如何实现分布式锁的?
基于Zookeeper的分布式锁都是依赖于zk节点路径唯一的机制来实现的.
什么意思呢?
就是在zk中,在分布式锁的场景下 对于同一个路径,只能有一个客户端能创建成功,其它的都创建失败.(这个不难理解,在平时系统中也没见过有哪2个文件地址完全相同)
下面就说一下zk分布式锁2种实现,没错 本篇就是干的不能再干的干货!!!
第一种分布式锁
具体流程
第一种实现是利用的zk的临时节点, 在争抢锁的时候,所有的客户端都尝试创建一个临时节点(代表锁住的资源),只有一个客户端会创建成功,创建成功的客户端得到锁,其它的客户端则监听(利用zk的watch)该节点的状态改变并且进入阻塞,节点改变后 zk server 会通知剩下的客户端,剩下的客户端停止阻塞并且重新争抢锁.
zk中有持久节点和临时节点,为什么使用临时节点呢?
如果使用的是持久节点,则这个节点在客户端下线后,依旧会一直存在,不会自动删除,导致 其它客户端一直无法争抢到锁 .如果使用的是临时节点的话, 在客户端下线后zk会删除与其相关的临时节点,这样其它客户端就能重新争抢锁 .
代码实现
@Override
public void lock() {
// 如果获取不到锁,阻塞等待
if (!tryLock()) {
// 没获得锁,阻塞自己
waitForLock();
// 再次尝试
lock();
}
}
@Override
public boolean tryLock() { // 不会阻塞
// 创建节点
try {
// 创建临时节点,zk中的节点(路径)唯一,只有一个会创建成功
// 为什么使用临时节点: 客户端掉线后会自动删除节点(释放锁)
client.createEphemeral(lockPath);
} catch (ZkNodeExistsException e) {
return false;
}
return true;
}
/**
*争抢不到锁的话,等待锁的释放
*/
private void waitForLock() {
CountDownLatch cdl = new CountDownLatch(1);
IZkDataListener listener = new IZkDataListener() {
@Override
public void handleDataDeleted(String dataPath) throws Exception {
System.out.println("收到节点被删除的消息,停止等待,重新争夺锁");
cdl.countDown();
}
@Override
public void handleDataChange(String dataPath, Object data)
throws Exception {
}
};
// 监听
client.subscribeDataChanges(lockPath, listener);
// 判断锁节点是否存在,存在的话表明有别人
if (this.client.exists(lockPath)) {
try {
// 等待接收到消息后,继续往下执行
cdl.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 取消监听消息
client.unsubscribeDataChanges(lockPath, listener);
}
总结一下
实现简单,但是会有 羊群效应 ,节点的删除都会通知所有的客户端,并且所有的客户端会 取消监听 + 重新一起争夺锁 + 争夺失败 + 再次开启监听 ,如此循环,资源耗费多,并且这种耗费是可以避免的,那么如何避免呢?就是下面第二种的 改进版分布式锁 .
第二种分布式锁
这一种分布式锁的实现是利用zk的临时顺序节点,每一个客户端在争夺锁的时候都由zk分配一个顺序号(sequence),客户端则按照这个顺序去获取锁.
具体流程
lock跟前面的一样,不过lockPath(锁住的资源)是一个持久节点,客户端在该持久节点下面创建临时顺序节点,获取到顺序号后,根据自己是否是最小的顺序号来获取锁,顺序号最小则获取锁,序号不为最小则监听(watch)前一个顺序号,当前一个顺序号被删除的时候表明锁被释放了,则会通知下一个客户端.
代码实现
下面贴出跟第一种实现不同的代码
/**
* 尝试加锁
*
* @return
*/
@Override
public boolean tryLock() {
// 创建临时顺序节点
if (this.currentPath == null) {
// 在lockPath节点下面创建临时顺序节点
currentPath = this.client.createEphemeralSequential(LockPath + "/", "aaa");
}
// 获得所有的子节点
List<String> children = this.client.getChildren(LockPath);
// 排序list
Collections.sort(children);
// 判断当前节点是否是最小的,如果是最小的节点,则表明此这个client可以获取锁
if (currentPath.equals(LockPath + "/" + children.get(0))) {
return true;
} else {
// 如果不是当前最小的sequence,取到前一个临时节点
// 1.单独获取临时节点的顺序号
// 2.查找这个顺序号在children中的下标
// 3.存储前一个节点的完整路径
int curIndex = children.indexOf(currentPath.substring(LockPath.length() + 1));
beforePath = LockPath + "/" + children.get(curIndex - 1);
}
return false;
}
private void waitForLock() {
CountDownLatch cdl = new CountDownLatch(1);
// 注册watcher
IZkDataListener listener = new IZkDataListener() {
@Override
public void handleDataDeleted(String dataPath) throws Exception {
System.out.println("监听到前一个节点被删除了");
cdl.countDown();
}
@Override
public void handleDataChange(String dataPath, Object data) throws Exception {
}
};
// 监听前一个临时节点
client.subscribeDataChanges(this.beforePath, listener);
// 前一个节点还存在,则阻塞自己
if (this.client.exists(this.beforePath)) {
try {
// 直至前一个节点释放锁,才会继续往下执行
cdl.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 醒来后,表明前一个临时节点已经被删除,此时客户端可以获取锁 && 取消watcher监听
client.unsubscribeDataChanges(this.beforePath, listener);
}
总结一下
实现比第一种复杂一点,但是更加的合理,少做了很多不必要的操作,只唤醒了后面一个客户端.
总结
由zk自身的设计,zk不适合高并发写,需要在使用zk分布式锁前先做一定过滤操作,先过滤掉部分请求,再进行锁争夺.
分布式锁当然不止zk的实现,各个实现都有其适用的场景,在分布式系统中,没有最完美的方案,只有最合适的方案,往往都是取舍问题.
Dubbo
Dubbo是阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成。
Dubbo是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
因此Dubbo的应用非常广泛,也在互联网公司的应用中起到非常重要的角色,只要你的简历上有Dubbo的字眼,面试官一定会问你Dubbo的问题,所以,今天码之初就为大家带来的Dubbo的高频面试题整理,望乡亲们喜欢,关注、转发、在看。
*1、Dubbo 是什么?*
Dubbo 是一个分布式、高性能、透明化的 RPC 服务框架,提 供服务自动注册、自动发现等高效服务治理方案, 可以和Spring 框架无缝集成。
** **
*2、Dubbo 的主要应用场景?*
-
透明化的远程方法调用,就像调用本地方法一样调用远程方法,只需简单配置,没有任何 API 侵入。
-
软负载均衡及容错机制,可在内网替代 F5 等硬件负载均衡器, 降低成本,减少单点。
-
服务自动注册与发现,不再需要写死服务提供方地址,注册中心 基于接口名查询服务提供者的 IP 地址,并且能够平滑添加或删 除服务提供者。
3、Dubbo 支持哪些协议,每种协议的应用场景,优缺点?
-
dubbo: 单一长连接和 NIO 异步通讯,适合大并发小数据量的服务调用, 以及消费者远大于提供者。传输协议 TCP,异步,Hessian 序列化;
-
rmi: 采用 JDK 标准的 rmi 协议实现,传输参数和返回参数对象需要实现Serializable 接口,使用 java 标准序列化机制,使用阻塞式短连接,传输数 据包大小混合,消费者和提供者个数差不多,可传文件,传输协议 TCP。多个短连接,TCP 协议传输,同步传输,适用常规的远程服务调用和 rmi 互 操作。在依赖低版本的 Common-Collections 包,java 序列化存在安全漏 洞;
-
webservice: 基于 WebService 的远程调用协议,集成 CXF 实现,提供和 原生 WebService 的互操作。多个短连接,基于 HTTP 传输,同步传输,适 用系统集成和跨语言调用;
-
http: 基于 Http 表单提交的远程调用协议,使用 Spring 的 HttpInvoke 实 现。多个短连接,传输协议 HTTP,传入参数大小混合,提供者个数多于消 费者,需要给应用程序和浏览器 JS 调用;
-
hessian: 集成 Hessian 服务,基于 HTTP 通讯,采用 Servlet 暴露服务,Dubbo 内嵌 Jetty 作为服务器时默认实现,提供与 Hession 服务互操作。多 个短连接,同步 HTTP 传输,Hessian 序列化,传入参数较大,提供者大于 消费者,提供者压力较大,可传文件;
-
memcache: 基于 memcached 实现的 RPC 协议
-
redis: 基于 redis 实现的 RPC 协议
*4、dubbo 推荐用什么协议?*
默认使用 dubbo 协议
*5、Dubbo 超时时间怎样设置?*
Dubbo 超时时间设置有两种方式:
-
服务提供者端设置超时时间,在 Dubbo 的用户文档中,推荐如果能在服务 端多配置就尽量多配置,因为服务提供者比消费者更清楚自己提供的服务特性。
-
服务消费者端设置超时时间,如果在消费者端设置了超时时间,以消费者端 为主,即优先级更高。因为服务调用方设置超时时间控制性更灵活。如果消 费方超时,服务端线程不会定制,会产生警告。
*6、Dubbo 有些哪些注册中心?*
-
Multicast 注册中心: Multicast 注册中心不需要任何中心节点,只要广播地 址,就能进行服务注册和发现。基于网络中组播传输实现;
-
Zookeeper 注册中心: 基于分布式协调系统 Zookeeper 实现,采用Zookeeper 的 watch 机制实现数据变更;
-
redis 注册中心: 基于 redis 实现,采用 key/Map 存储,住 key 存储服务名 和类型,Map 中 key 存储服务 URL,value 服务过期时间。基于 redis 的发 布/订阅模式通知数据变更;
-
Simple 注册中心
*7、Dubbo 默认采用注册中心?*
采用 Zookeeper
8、Dubbo 集群的负载均衡有哪些策略 **
**
Dubbo 提供了常见的集群策略实现,并预扩展点予以自行实现。
-
Random LoadBalance: 随机选取提供者策略,有利于动态调整提供者权 重。截面碰撞率高,调用次数越多,分布越均匀;
-
RoundRobin LoadBalance: 轮循选取提供者策略,平均分布,但是存在请 求累积的问题;
-
LeastActive LoadBalance: 最少活跃调用策略,解决慢提供者接收更少的 请求;
-
ConstantHash LoadBalance: 一致性 Hash 策略,使相同参数请求总是发 到同一提供者,一台机器宕机,可以基于虚拟节点,分摊至其他提供者,避 免引起提供者的剧烈变动。
*9、Dubbo 的核心功能?*
主要就是如下 3 个核心功能:
-
Remoting:网络通信框架,提供对多种NIO框架抽象封装,包括 “同步转异步”和“请求-响应”模式的信息交换方式。
-
Cluster:服务框架,提供基于接口方法的透明远程过程调用,包括多 协议支持,以及软负载均衡,失败容错,地址路由,动态配置等集群 支持。
-
Registry:服务注册,基于注册中心目录服务,使服务消费方能动态 的查找服务提供方,使地址透明,使服务提供方可以平滑增加或减少 机器。
10、Dubbo的核心组件和核心配置?
核心组件:
核心配置:
配置之间关系如下图:
11、在 Provider 上可以配置的 Consumer 端的属性有哪些?
-
timeout:方法调用超时
-
retries:失败重试次数,默认重试 2 次
-
loadbalance:负载均衡算法,默认随机
-
actives 消费者端,最大并发调用限制
12、Dubbo启动时如果依赖的服务不可用会怎样?
Dubbo 缺省会在启动时检查依赖的服务是否可用,不可用时会抛出异常,阻止 Spring 初始化完成,默认 check="true",可以通过 check="false" 关闭检查。
13、服务提供者能实现失效踢出是什么原理?
答:服务失效踢出基于 zookeeper 的临时节点原理。
14、服务上线怎么不影响旧版本?
答:采用多版本开发,不影响旧版本。在配置中添加version来作为版本区分
15、如何解决服务调用链过长的问题?
答:可以结合 zipkin 实现分布式服务追踪。
*16、Dubbo 服务注册与发现的流程?*
流程说明:
-
Provider(提供者)绑定指定端口并启动服务
-
指供者连接注册中心,并发本机IP、端口、应用信息和提供服务信息发送至注册中心存储
-
Consumer(消费者),连接注册中心 ,并发送应用信息、所求服务信息至注册中心
-
注册中心根据 消费 者所求服务信息匹配对应的提供者列表发送至Consumer 应用缓存。
-
Consumer 在发起远程调用时基于缓存的消费者列表择其一发起调用。
-
Provider 状态变更会实时通知注册中心、在由注册中心实时推送至
-
Consumer
设计的原因:
-
Consumer 与 Provider 解偶,双方都可以横向增减节点数。
-
注册中心对本身可做对等集群,可动态增减节点,并且任意一台宕掉后,将自动切换到另一台
-
去中心化,双方不直接依懒注册中心,即使注册中心全部宕机短时间内也不会影响服务的调用
-
服务提供者无状态,任意一台宕掉后,不影响使用
*17、Dubbo需要 Web 容器吗?*
不需要,如果硬要用 Web 容器,只会增加复杂性,也浪费资源。
*18、Dubbo内置了哪几种服务容器?*
-
Spring Container
-
Jetty Container
-
Log4j Container
Dubbo 的服务容器只是一个简单的 Main 方法,并加载一个简单的 Spring 容器,用于暴露服务。
*19、Dubbo 的整体架构设计有哪些分层?*
-
接口服务层(Service):该层与业务逻辑相关,根据 provider 和 consumer 的业务设计对应的接口和实现
-
配置层(Config):对外配置接口,以 ServiceConfig 和 ReferenceConfig 为中心
-
服务代理层(Proxy):服务接口透明代理,生成服务的客户端 Stub 和 服务端的 Skeleton,以 ServiceProxy 为中心,扩展接口为 ProxyFactory
-
服务注册层(Registry):封装服务地址的注册和发现,以服务 URL 为中心,扩展接口为 RegistryFactory、Registry、RegistryService
-
路由层(Cluster):封装多个提供者的路由和负载均衡,并桥接注册中心,以Invoker 为中心,扩展接口为 Cluster、Directory、Router和LoadBlancce
-
监控层(Monitor):RPC调用次数和调用时间监控,以 Statistics 为中心,扩展接口为 MonitorFactory、Monitor和MonitorService
-
远程调用层(Protocal):封装 RPC 调用,以 Invocation 和 Result 为中心,扩展接口为 Protocal、Invoker和Exporter
-
信息交换层(Exchange):封装请求响应模式,同步转异步。以 Request 和 Response 为中心,扩展接口为 Exchanger、ExchangeChannel、ExchangeClient和ExchangeServer
-
网络传输层(Transport):抽象 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为Channel、Transporter、Client、Server和Codec
-
数据序列化层(Serialize):可复用的一些工具,扩展接口为Serialization、 ObjectInput、ObjectOutput和ThreadPool
*20、Dubbo 的服务调用流程?*
*20、Dubbo 用到哪些设计模式?*
Dubbo框架在初始化和通信过程中使用了多种设计模式,可灵活控制类加载、权限控制等功能。
工厂模式
Provider在export服务时,会调用ServiceConfig的export方法。ServiceConfig中有个字段:
private static final Protocol protocol = ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();
Dubbo里有很多这种代码。这也是一种工厂模式,只是实现类的获取采用了JDK SPI的机制。这么实现的优点是可扩展性强,想要扩展实现,只需要在classpath下增加个文件就可以了,代码零侵入。另外,像上面的Adaptive实现,可以做到调用时动态决定调用哪个实现,但是由于这种实现采用了动态代理,会造成代码调试比较麻烦,需要分析出实际调用的实现类。
装饰器模式
Dubbo在启动和调用阶段都大量使用了装饰器模式。以Provider提供的调用链为例,具体的调用链代码是在ProtocolFilterWrapper的buildInvokerChain完成的,具体是将注解中含有group=provider的Filter实现,按照order排序,最后的调用顺序是:
EchoFilter -> ClassLoaderFilter -> GenericFilter -> ContextFilter -> ExecuteLimitFilter -> TraceFilter -> TimeoutFilter -> MonitorFilter -> ExceptionFilter
更确切地说,这里是装饰器和责任链模式的混合使用。例如,EchoFilter的作用是判断是否是回声测试请求,是的话直接返回内容,这是一种责任链的体现。而像ClassLoaderFilter则只是在主功能上添加了功能,更改当前线程的ClassLoader,这是典型的装饰器模式。
观察者模式
Dubbo的Provider启动时,需要与注册中心交互,先注册自己的服务,再订阅自己的服务,订阅时,采用了观察者模式,开启一个listener。注册中心会每5秒定时检查是否有服务更新,如果有更新,向该服务的提供者发送一个notify消息,provider接受到notify消息后,即运行NotifyListener的notify方法,执行监听器方法。
动态代理模式
Dubbo扩展JDK SPI的类ExtensionLoader的Adaptive实现是典型的动态代理实现。Dubbo需要灵活地控制实现类,即在调用阶段动态地根据参数决定调用哪个实现类,所以采用先生成代理类的方法,能够做到灵活的调用。生成代理类的代码是ExtensionLoader的createAdaptiveExtensionClassCode方法。代理类的主要逻辑是,获取URL参数中指定参数的值作为获取实现类的key。
*21、为什么需要服务治理?*
-
过多的服务URL配置困难
-
负载均衡分配节点压力过大的情况下也需要部署集群
-
服务依赖混乱,启动顺序不清晰
-
过多服务导致性能指标分析难度较大,需要监控
22、Dubbo 的注册中心集群挂掉,发布者和订阅者之间还能通信么?
可以的,启动 dubbo 时,消费者会从 zookeeper 拉取注册的生产者 的地址接口等数据,缓存在本地。
每次调用时,按照本地存储的地址进行调用。
23、Dubbo 与 Spring 的关系?
Dubbo 采用全 Spring 配置方式,透明化接入应用,对应用没有任何API 侵入,只需用 Spring 加载 Dubbo 的配置即可,Dubbo 基于Spring 的 Schema 扩展进行加载。
24、Dubbo有哪几种负载均衡策略,默认是哪种?
25、注册了多个同一样的服务,如果测试指定的某一个服务呢?
可以配置环境点对点直连,绕过注册中心,将以服务接口为单位,忽略注册中心的提供者列表。
26、Dubbo支持服务多协议吗?
Dubbo 允许配置多协议,在不同服务上支持不同协议或者同一服务上同时支持多种协议。
27、当一个服务接口有多种实现时怎么做?
当一个接口有多种实现时,可以用 group 属性来分组,服务提供方和消费方都指定同一个 group 即可。
28、服务上线怎么兼容旧版本?
可以用版本号(version)过渡,多个不同版本的服务注册到注册中心,版本号不同的服务相互间不引用。这个和服务分组的概念有一点类似。
29、Dubbo可以对结果进行缓存吗?
可以,Dubbo 提供了声明式缓存,用于加速热门数据的访问速度,以减少用户加缓存的工作量。
30、默认使用的是什么通信框架,还有别的选择吗?
答:默认也推荐使用 netty 框架,还有 mina。
31、Dubbo服务之间的调用是阻塞的吗?
默认是同步等待结果阻塞的,支持异步调用。
Dubbo 是基于 NIO 的非阻塞实现并行调用,客户端不需要启动多线程即可完成并行调用多个远程服务,相对多线程开销较小,异步调用会返回一个 Future 对象。
异步调用流程图如下。
32、Dubbo支持分布式事务吗?
答:目前暂时不支持,可与通过 tcc-transaction框架实现
介绍:tcc-transaction是开源的TCC补偿性分布式事务框架
Git地址:https://github.com/changmingxie/tcc-transaction
TCC-Transaction 通过 Dubbo 隐式传参的功能,避免自己对业务代码的入侵。
33、Dubbo 的集群容错方案有哪些?
34、Dubbo 的默认集群容错方案?
Failover Cluster
35、Dubbo 支持哪些序列化方式?
默认使用 Hessian 序列化,还有 Duddo、FastJson、Java 自带序列 化。
36、服务调用超时问题怎么解决?
dubbo 在调用服务不成功时,默认是会重试两次的。
37、Dubbo 在安全机制方面是如何解决?
Dubbo 通过 Token 令牌防止用户绕过注册中心直连,然后在注册中 心上管理授权。Dubbo 还提供服务黑白名单,来控制服务所允许的调 用方。
38、Dubbo 和 Dubbox 之间的区别?
dubbox 基于 dubbo 上做了一些扩展,如加了服务可 restful 调 用,更新了开源组件等。
39、Dubbo支持服务降级吗?
Dubbo 2.2.0 以上版本支持。
40、Dubbo如何优雅停机?
Dubbo 是通过 JDK 的 ShutdownHook 来完成优雅停机的,所以如果使用 kill -9 PID 等强制关闭指令,是不会执行优雅停机的,只有通过 kill PID 时,才会执行。
41、服务提供者能实现失效踢出是什么原理?
服务失效踢出基于 Zookeeper 的临时节点原理。
42、如何解决服务调用链过长的问题?
Dubbo 可以使用 Pinpoint 和 Apache Skywalking(Incubator) 实现分布式服务追踪,当然还有其他很多方案。
43、服务读写推荐的容错策略是怎样的?
-
读操作建议使用 Failover 失败自动切换,默认重试两次其他服务器。
-
写操作建议使用 Failfast 快速失败,发一次调用失败就立即报错。
44、Dubbo必须依赖的包有哪些?
Dubbo 必须依赖 JDK,其他为可选。
45、Dubbo的管理控制台能做什么?
管理控制台主要包含:路由规则,动态配置,服务降级,访问控制,权重调整,负载均衡,等管理功能。
46、说说 Dubbo 服务暴露的过程。
Dubbo 会在 Spring 实例化完 bean 之后,在刷新容器最后一步发布 ContextRefreshEvent 事件的时候,通知实现了 ApplicationListener 的 ServiceBean 类进行回调 onApplicationEvent 事件方法,Dubbo 会在这个方法中调用 ServiceBean 父类 ServiceConfig 的 export 方法,而该方法真正实现了服务的(异步或者非异步)发布。
47、Dubbo 和 Spring Cloud 的区别?
最大的区别:Dubbo 底层是使用 Netty 这样的 NIO 框架,是基于TCP 协议传输的,配合以 Hession 序列化完成 RPC 通信。
而 SpringCloud 是基于 Http 协议+Rest 接口调用远程过程的通信, 相对来说,Http 请求会有更大的报文,占的带宽也会更多。但是REST 相比 RPC 更为灵活,服务提供方和调用方的依赖只依靠一纸契约,不存在代码级别的强依赖。
参考文章:https://blog.csdn.net/azhegps/article/details/99104880
参考文章:https://blog.csdn.net/t4i2b10x4c22nf6a/article/details/89530201
参考文章:https://blog.csdn.net/yanpenglei/article/details/88363884
Netty
Netty 是一款基于 NIO(Nonblocking I/O,非阻塞IO)开发的网络通信框架,对比于 BIO(Blocking I/O,阻塞IO),他的并发性能得到了很大提高。难能可贵的是,在保证快速和易用性的同时,并没有丧失可维护性和性能等优势。
Netty 的应用也是比较广泛的,比如阿里巴巴开源的 Dubbo 和 Sofa-Bolt 框架底层网络通讯都是基于 Netty 来实现的。本文将带大家通过netty的高频面试题来了解Netty框架并掌握Netty的一些重要知识点。
申明:本人对Netty没有过深入了解,只知道一点皮毛,本文的著作权不归本人所有,只是在整理面试系列,故借花献佛,因为不知道文章出处,所以特此说明,如果有幸被原作者看到,感谢您的无心插柳帮助到这么多有需要的人!如果侵权,请联系码之初立即删除,如果有需要转载的朋友,也请附上申明这段话,让我们一起尊重原作者的著作权和知识产权,谢谢配合!
下面让我们一起来看看Netty的高频面试题。
1、BIO、NIO 和 AIO 的区别?
BIO:一个连接一个线程,客户端有连接请求时服务器端就需要启动一个线程进行处理。线 程开销大。
伪异步 IO:将请求连接放入线程池,一对多,但线程还是很宝贵的资源。NIO:一个请求一个线程,但客户端发送的连接请求都会注册到多路复用器上,多路复用 器轮询到连接有 I/O 请求时才启动一个线程进行处理。AIO:一个有效请求一个线程,客户端的 I/O 请求都是由 OS 先完成了再通知服务器应用去 启动线程进行处理,
BIO 是面向流的,NIO 是面向缓冲区的;BIO 的各种流是阻塞的。而 NIO 是非阻塞的;BIO的 Stream 是单向的,而 NIO 的 channel 是双向的。
NIO 的特点:事件驱动模型、单线程处理多任务、非阻塞 I/O,I/O 读写不再阻塞,而是返 回 0、基于 block 的传输比基于流的传输更高效、更高级的 IO 函数 zero-copy、IO 多路复用 大大提高了 Java 网络应用的可伸缩性和实用性。基于 Reactor 线程模型。
在 Reactor 模式中,事件分发器等待某个事件或者可应用或个操作的状态发生,事件分发 器就把这个事件传给事先注册的事件处理函数或者回调函数,由后者来做实际的读写操 作。如在 Reactor 中实现读:注册读就绪事件和相应的事件处理器、事件分发器等待事 件、事件到来,激活分发器,分发器调用事件对应的处理器、事件处理器完成实际的读操 作,处理读到的数据,注册新的事件,然后返还控制权。
2、NIO 的组成?
Buffer:与 Channel 进行交互,数据是从 Channel 读入缓冲区,从缓冲区写入 Channel 中的。
flip方法 : 反转此缓冲区,将position给limit,然后将position置为0,其实就是切换读 写模式。 clear 方法 :清除此缓冲区,将 position 置为 0,把 capacity 的值给 limit。 rewind 方法 : 重绕此缓冲区,将 position 置为 0
DirectByteBuffer 可减少一次系统空间到用户空间的拷贝。但 Buffer 创建和销毁的成本更 高,不可控,通常会用内存池来提高性能。直接缓冲区主要分配给那些易受基础系统的本 机 I/O 操作影响的大型、持久的缓冲区。如果数据量比较小的中小应用情况下,可以考虑 使用 heapBuffer,由 JVM 进行管理。
Channel:表示 IO 源与目标打开的连接,是双向的,但不能直接访问数据,只能与Buffer进行交互。通过源码可知,FileChannel 的 read 方法和 write 方法都导致数据复制了两次!
Selector 可使一个单独的线程管理多个 Channel,open 方法可创建 Selector,register 方法向 多路复用器器注册通道,可以监听的事件类型:读、写、连接、accept。注册事件后会产 生一个 SelectionKey:它表示 SelectableChannel 和 Selector 之间的注册关系,wakeup 方 法:使尚未返回的第一个选择操作立即返回,唤醒的原因是:注册了新的 channel 或者事 件;channel 关闭,取消注册;优先级更高的事件触发(如定时器事件),希望及时处理。
Selector 在 Linux 的实现类是 EPollSelectorImpl,委托给 EPollArrayWrapper 实现,其中三个native 方法是对 epoll 的封装,而 EPollSelectorImpl. implRegister 方法,通过调用 epoll_ctl向 epoll 实例中注册事件,还将注册的文件描述符(fd)与 SelectionKey 的对应关系添加到fdToKey 中,这个 map 维护了文件描述符与 SelectionKey 的映射。
fdToKey 有时会变得非常大,因为注册到 Selector 上的 Channel 非常多(百万连接);过期 或失效的 Channel 没有及时关闭。fdToKey 总是串行读取的,而读取是在 select 方法中进行 的,该方法是非线程安全的。
Pipe:两个线程之间的单向数据连接,数据会被写到 sink 通道,从 source 通道读取。
NIO 的服务端建立过程:Selector.open():打开一个 Selector;ServerSocketChannel.open(): 创建服务端的 Channel;bind():绑定到某个端口上。并配置非阻塞模式;register():注册Channel 和关注的事件到 Selector 上;select()轮询拿到已经就绪的事件。
3、Netty 的特点?
-
一个高性能、异步事件驱动的 NIO 框架,它提供了对 TCP、UDP 和文件传输的支持
-
使用更高效的 socket 底层,对 epoll 空轮询引起的 cpu 占用飙升在内部进行了处理,避免 了直接使用 NIO 的陷阱,简化了 NIO 的处理方式。
-
采用多种 decoder/encoder 支持,对 TCP 粘包/分包进行自动化处理
-
可使用接受/处理线程池,提高连接效率,对重连、心跳检测的简单支持
-
可配置IO线程数、TCP参数, TCP接收和发送缓冲区使用直接内存代替堆内存,通过内存 池的方式循环利用 ByteBuf
-
通过引用计数器及时申请释放不再引用的对象,降低了 GC 频率 使用单线程串行化的方式,高效的 Reactor 线程模型
-
大量使用了 volitale、使用了 CAS 和原子类、线程安全类的使用、读写锁的使用
4、Netty 的线程模型?
Netty 通过 Reactor 模型基于多路复用器接收并处理用户请求,内部实现了两个线程池,boss 线程池和 work 线程池,其中 boss 线程池的线程负责处理请求的 accept 事件,当接收 到 accept 事件的请求时,把对应的 socket 封装到一个 NioSocketChannel 中,并交给 work线程池,其中 work 线程池负责请求的 read 和 write 事件,由对应的 Handler 处理。
-
单线程模型:所有 I/O 操作都由一个线程完成,即多路复用、事件分发和处理都是在一个Reactor 线程上完成的。既要接收客户端的连接请求,向服务端发起连接,又要发送/读取请 求或应答/响应消息。一个 NIO 线程同时处理成百上千的链路,性能上无法支撑,速度 慢,若线程进入死循环,整个程序不可用,对于高负载、大并发的应用场景不合适。
-
多线程模型:有一个NIO 线程(Acceptor) 只负责监听服务端,接收客户端的TCP 连接 请求;NIO 线程池负责网络IO 的操作,即消息的读取、解码、编码和发送;1 个NIO 线 程可以同时处理N 条链路,但是1 个链路只对应1 个NIO 线程,这是为了防止发生并发 操作问题。但在并发百万客户端连接或需要安全认证时,一个Acceptor 线程可能会存在性 能不足问题。
-
主从多线程模型:Acceptor 线程用于绑定监听端口,接收客户端连接,将 SocketChannel从主线程池的Reactor 线程的多路复用器上移除,重新注册到Sub 线程池的线程上,用于处理 I/O 的读写等操作,从而保证 mainReactor 只负责接入认证、握手等操作。
5、TCP 粘包/拆包的原因及解决方法?
TCP 是以流的方式来处理数据,一个完整的包可能会被 TCP 拆分成多个包进行发送,也可 能把小的封装成一个大的数据包发送。
TCP 粘包/分包的原因:
应用程序写入的字节大小大于套接字发送缓冲区的大小,会发生拆包现象,而应用程序写 入数据小于套接字缓冲区大小,网卡将应用多次写入的数据发送到网络上,这将会发生粘 包现象;
进行 MSS 大小的 TCP 分段,当 TCP 报文长度-TCP 头部长度>MSS 的时候将发生拆包 以太网帧的 payload(净荷)大于 MTU(1500 字节)进行 ip 分片。
解决方法:
消息定长:FixedLengthFrameDecoder 类 包尾增加特殊字符分割:行分隔符类:LineBasedFrameDecoder 或自定义分隔符类 :DelimiterBasedFrameDecoder将消息分为消息头和消息体:LengthFieldBasedFrameDecoder 类。分为有头部的拆包与粘 包、长度字段在前且有头部的拆包与粘包、多扩展头部的拆包与粘包。
6、了解哪几种序列化协议?
序列化(编码)是将对象序列化为二进制形式(字节数组),主要用于网络传输、数据持久 化等;而反序列化(解码)则是将从网络、磁盘等读取的字节数组还原成原始对象,主要 用于网络传输对象的解码,以便完成远程调用。
影响序列化性能的关键因素:序列化后的码流大小(网络带宽的占用)、序列化的性能 (CPU 资源占用);是否支持跨语言(异构系统的对接和开发语言切换)。
-
Java 默认提供的序列化:无法跨语言、序列化后的码流太大、序列化的性能差
-
XML,优点:人机可读性好,可指定元素或特性的名称。缺点:序列化数据只包含数据本 身以及类的结构,不包括类型标识和程序集信息;只能序列化公共属性和字段;不能序列 化方法;文件庞大,文件格式复杂,传输占带宽。适用场景:当做配置文件存储数据,实 时数据转换。
-
JSON,是一种轻量级的数据交换格式,优点:兼容性高、数据格式比较简单,易于读写、 序列化后数据较小,可扩展性好,兼容性好、与 XML 相比,其协议比较简单,解析速度比 较快。缺点:数据的描述性比 XML 差、不适合性能要求为 ms 级别的情况、额外空间开销 比较大。适用场景(可替代XML):跨防火墙访问、可调式性要求高、基于 Web browser 的 Ajax 请求、传输数据量相对小,实时性要求相对低(例如秒级别)的服务。
-
Fastjson,采用一种“假定有序快速匹配”的算法。优点:接口简单易用、目前 java 语言中 最快的 json 库。缺点:过于注重快,而偏离了“标准”及功能性、代码质量不高,文档不 全。适用场景:协议交互、Web 输出、Android 客户端
-
Thrift,不仅是序列化协议,还是一个 RPC 框架。优点:序列化后的体积小, 速度快、支持 多种语言和丰富的数据类型、对于数据字段的增删具有较强的兼容性、支持二进制压缩编 码。缺点:使用者较少、跨防火墙访问时,不安全、不具有可读性,调试代码时相对困 难、不能与其他传输层协议共同使用(例如 HTTP)、无法支持向持久层直接读写数据,即 不适合做数据持久化序列化协议。适用场景:分布式系统的 RPC 解决方案
-
Avro,Hadoop 的一个子项目,解决了 JSON 的冗长和没有 IDL 的问题。优点:支持丰富的 数据类型、简单的动态语言结合功能、具有自我描述属性、提高了数据解析速度、快速可 压缩的二进制数据形式、可以实现远程过程调用 RPC、支持跨编程语言实现。缺点:对于 习惯于静态类型语言的用户不直观。适用场景:在 Hadoop 中做 Hive、Pig 和 MapReduce的持久化数据格式。
-
Protobuf,将数据结构以.proto 文件进行描述,通过代码生成工具可以生成对应数据结构的POJO 对象和 Protobuf 相关的方法和属性。优点:序列化后码流小,性能高、结构化数据存 储格式(XML JSON 等)、通过标识字段的顺序,可以实现协议的前向兼容、结构化的文档 更容易管理和维护。缺点:需要依赖于工具生成代码、支持的语言相对较少,官方只支持Java 、C++ 、python。适用场景:对性能要求高的RPC调用、具有良好的跨防火墙的访问 属性、适合应用层对象的持久化
其它
-
protostuff 基于 protobuf 协议,但不需要配置 proto 文件,直接导包即可
-
Jboss marshaling 可以直接序列化 java 类, 无须实 java.io.Serializable 接口
-
Message pack 一个高效的二进制序列化格式
-
Hessian 采用二进制协议的轻量级 remoting onhttp 工具
-
kryo 基于 protobuf 协议,只支持 java 语言,需要注册(Registration),然后序列化 (Output),反序列化(Input)
7、如何选择序列化协议?
具体场景
对于公司间的系统调用,如果性能要求在 100ms 以上的服务,基于 XML 的 SOAP 协议是一 个值得考虑的方案。
基于 Web browser 的 Ajax,以及 Mobile app 与服务端之间的通讯,JSON 协议是首选。对于 性能要求不太高,或者以动态类型语言为主,或者传输数据载荷很小的的运用场景,JSON也是非常不错的选择。
对于调试环境比较恶劣的场景,采用 JSON 或 XML 能够极大的提高调试效率,降低系统开 发成本。
当对性能和简洁性有极高要求的场景,Protobuf,Thrift,Avro 之间具有一定的竞争关系。对于 T 级别的数据的持久化应用场景,Protobuf 和 Avro 是首要选择。如果持久化后的数据 存储在 hadoop 子项目里,Avro 会是更好的选择。
对于持久层非 Hadoop 项目,以静态类型语言为主的应用场景,Protobuf 会更符合静态类 型语言工程师的开发习惯。由于 Avro 的设计理念偏向于动态类型语言,对于动态语言为主 的应用场景,Avro 是更好的选择。
如果需要提供一个完整的 RPC 解决方案,Thrift 是一个好的选择。如果序列化之后需要支持不同的传输层协议,或者需要跨防火墙访问的高性能场景,Protobuf 可以优先考虑。
protobuf 的数据类型有多种:bool、double、float、int32、int64、string、bytes、enum、message。protobuf的限定符:required: 必须赋值,不能为空、optional:字段可以赋值,也 可以不赋值、repeated: 该字段可以重复任意次数(包括 0 次)、枚举;只能用指定的常量 集中的一个值作为其值;
protobuf 的基本规则:每个消息中必须至少留有一个 required 类型的字段、包含 0 个或多 个 optional 类型的字段;repeated 表示的字段可以包含 0 个或多个数据;[1,15]之内的标识 号在编码的时候会占用一个字节(常用),[16,2047]之内的标识号则占用 2 个字节,标识号 一定不能重复、使用消息类型,也可以将消息嵌套任意多层,可用嵌套消息类型来代替 组。
protobuf 的消息升级原则:不要更改任何已有的字段的数值标识;不能移除已经存在的required 字段,optional 和 repeated 类型的字段可以被移除,但要保留标号不能被重用。新添加的字段必须是 optional 或 repeated。因为旧版本程序无法读取或写入新增的required 限定符的字段。
编译器为每一个消息类型生成了一个.java 文件,以及一个特殊的 Builder 类(该类是用来创 建消息类接口的)。如:UserProto.User.Builder builder = UserProto.User.newBuilder();builder.build();
Netty 中的使用:ProtobufVarint32FrameDecoder 是用于处理半包消息的解码类;ProtobufDecoder(UserProto.User.getDefaultInstance())这是创建的 UserProto.java 文件中的解 码类;ProtobufVarint32LengthFieldPrepender 对 protobuf 协议的消息头上加上一个长度为32 的整形字段,用于标志这个消息的长度的类;ProtobufEncoder 是编码类将 StringBuilder 转换为 ByteBuf 类型:copiedBuffer()方法
8、Netty 的零拷贝实现?
Netty 的接收和发送 ByteBuffer 采用 DIRECT BUFFERS,使用堆外直接内存进行 Socket 读 写,不需要进行字节缓冲区的二次拷贝。堆内存多了一次内存拷贝,JVM 会将堆内存Buffer 拷贝一份到直接内存中,然后才写入 Socket 中。ByteBuffer 由 ChannelConfig 分配, 而 ChannelConfig 创建 ByteBufAllocator 默认使用 Direct Buffer
CompositeByteBuf 类可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf, 避免了传统通过 内存拷贝的方式将几个小 Buffer 合并成一个大的 Buffer。addComponents 方法将 header与 body 合并为一个逻辑上的 ByteBuf, 这两个 ByteBuf 在 CompositeByteBuf 内部都是单 独存在的, CompositeByteBuf 只是逻辑上是一个整体
通过 FileRegion 包装的 FileChannel.tranferTo 方法 实现文件传输, 可以直接将文件缓冲区 的数据发送到目标 Channel,避免了传统通过循环 write 方式导致的内存拷贝问题。
通过 wrap 方法, 我们可以将 byte[] 数组、ByteBuf、ByteBuffer 等包装成一个 Netty ByteBuf 对象, 进而避免了拷贝操作。
Selector BUG:若 Selector 的轮询结果为空,也没有 wakeup 或新消息处理,则发生空轮 询,CPU 使用率 100%,
Netty 的解决办法:对 Selector 的 select 操作周期进行统计,每完成一次空的 select 操作进 行一次计数,若在某个周期内连续发生 N 次空轮询,则触发了 epoll 死循环 bug。重建Selector,判断是否是其他线程发起的重建请求,若不是则将原 SocketChannel 从旧的Selector 上去除注册,重新注册到新的 Selector 上,并将原来的 Selector 关闭。
9、Netty 的高性能表现在哪些方面?
-
心跳,对服务端:会定时清除闲置会话 inactive(netty5),对客户端:用来检测会话是否断 开,是否重来,检测网络延迟,其中 idleStateHandler 类 用来检测会话状态
-
串行无锁化设计,即消息的处理尽可能在同一个线程内完成,期间不进行线程切换,这样 就避免了多线程竞争和同步锁。表面上看,串行化设计似乎 CPU 利用率不高,并发程度不 够。但是,通过调整 NIO 线程池的线程参数,可以同时启动多个串行化的线程并行运行, 这种局部无锁化的串行线程设计相比一个队列-多个工作线程模型性能更优。
-
可靠性,链路有效性检测:链路空闲检测机制,读/写空闲超时机制;内存保护机制:通过 内存池重用 ByteBuf;ByteBuf 的解码保护;优雅停机:不再接收新消息、退出前的预处理操 作、资源的释放操作。
-
Netty安全性:支持的安全协议:SSL V2和V3,TLS,SSL单向认证、双向认证和第三方CA认证。
-
高效并发编程的体现:volatile 的大量、正确使用;CAS 和原子类的广泛使用;线程安全容 器的使用;通过读写锁提升并发性能。IO 通信性能三原则:传输(AIO)、协议(Http)、线 程(主从多线程)
-
流量整型的作用(变压器):防止由于上下游网元性能不均衡导致下游网元被压垮,业务流中断;防止由于通信模块接受消息过快,后端业务线程处理不及时导致撑死问题。
-
TCP 参数配置:SO_RCVBUF 和 SO_SNDBUF:通常建议值为 128K 或者 256K;SO_TCPNODELAY:NAGLE 算法通过将缓冲区内的小封包自动相连,组成较大的封包,阻止 大量小封包的发送阻塞网络,从而提高网络应用效率。但是对于时延敏感的应用场景需要 关闭该优化算法;
10、NIOEventLoopGroup 源码?
NioEventLoopGroup(其实是 MultithreadEventExecutorGroup) 内部维护一个类型为EventExecutor children [], 默认大小是处理器核数 * 2, 这样就构成了一个线程池,初始化EventExecutor 时 NioEventLoopGroup 重载 newChild 方法,所以 children 元素的实际类型为NioEventLoop。
线程启动时调用 SingleThreadEventExecutor 的构造方法,执行 NioEventLoop 类的 run 方 法,首先会调用 hasTasks()方法判断当前 taskQueue 是否有元素。如果 taskQueue 中有元 素,执行 selectNow() 方法,最终执行 selector.selectNow(),该方法会立即返回。如果taskQueue 没有元素,执行 select(oldWakenUp) 方法
select ( oldWakenUp) 方法解决了 Nio 中的 bug,selectCnt 用来记录 selector.select 方法的 执行次数和标识是否执行过 selector.selectNow(),若触发了 epoll 的空轮询 bug,则会反复 执行selector.select(timeoutMillis),变量selectCnt 会逐渐变大,当selectCnt 达到阈值(默 认 512),则执行 rebuildSelector 方法,进行 selector 重建,解决 cpu 占用 100%的 bug。
rebuildSelector方法先通过openSelector方法创建一个新的selector。然后将old selector的selectionKey 执行 cancel。最后将 old selector 的 channel 重新注册到新的 selector 中。rebuild 后,需要重新执行方法 selectNow,检查是否有已 ready 的 selectionKey。
接下来调用 processSelectedKeys 方法(处理 I/O 任务),当 selectedKeys != null 时,调用processSelectedKeysOptimized方法,迭代 selectedKeys 获取就绪的 IO 事件的selectkey存 放在数组 selectedKeys 中, 然后为每个事件都调用 processSelectedKey 来处理它,processSelectedKey 中分别处理 OP_READ;OP_WRITE;OP_CONNECT 事件。
最后调用 runAllTasks 方法(非 IO 任务),该方法首先会调用 fetchFromScheduledTaskQueue方法,把 scheduledTaskQueue 中已经超过延迟执行时间的任务移到 taskQueue 中等待被执 行,然后依次从 taskQueue 中取任务执行,每执行 64 个任务,进行耗时检查,如果已执行 时间超过预先设定的执行时间,则停止执行非 IO 任务,避免非 IO 任务太多,影响 IO 任务 的执行。
每个 NioEventLoop 对应一个线程和一个 Selector,NioServerSocketChannel 会主动注册到某 一个 NioEventLoop 的 Selector 上,NioEventLoop 负责事件轮询。
Outbound 事件都是请求事件, 发起者是 Channel,处理者是 unsafe,通过 Outbound 事 件进行通知,传播方向是 tail到head。Inbound 事件发起者是 unsafe,事件的处理者是Channel, 是通知事件,传播方向是从头到尾。
内存管理机制,首先会预申请一大块内存 Arena,Arena 由许多 Chunk 组成,而每个 Chunk默认由 2048 个 page 组成。Chunk 通过 AVL 树的形式组织 Page,每个叶子节点表示一个Page,而中间节点表示内存区域,节点自己记录它在整个 Arena 中的偏移地址。当区域被 分配出去后,中间节点上的标记位会被标记,这样就表示这个中间节点以下的所有节点都 已被分配了。大于 8k 的内存分配在 poolChunkList 中,而 PoolSubpage 用于分配小于 8k 的 内存,它会把一个 page 分割成多段,进行内存分配。
ByteBuf 的特点:支持自动扩容(4M),保证 put 方法不会抛出异常、通过内置的复合缓冲 类型,实现零拷贝(zero-copy);不需要调用 flip()来切换读/写模式,读取和写入索引分开;方法链;引用计数基于 AtomicIntegerFieldUpdater 用于内存回收;PooledByteBuf 采用 二叉树来实现一个内存池,集中管理内存的分配和释放,不用每次使用都新建一个缓冲区 对象。UnpooledHeapByteBuf 每次都会新建一个缓冲区对象。
Kafka
“你用过消息中间件吗?用过哪些?”
这是在面试过程中面试官必问的一个问题,但是我真的听过很多人说没用过,也有人说用过但也仅仅知道怎么调用,其他的问题一概不知,在消息中间件在项目中发挥着中流砥柱作用的今天,仅仅知道调用显然是不够的的了,为了能让乡亲们多点底气,今天为大家带来Kafka的高频面试题(kafka我用的比较多)。
1、为什么要使用 kafka,为什么要使用消息队列?
-
缓冲和削峰:上游数据时有突发流量,下游可能扛不住,或者下游没有足够多的机器来保证冗余,kafka在中间可以起到一个缓冲的作用,把消息暂存在kafka中,下游服务就可以按照自己的节奏进行慢慢处理。
-
解耦和扩展性:项目开始的时候,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流程。只需要遵守约定,针对数据编程即可获取扩展能力。
-
冗余:可以采用一对多的方式,一个生产者发布消息,可以被多个订阅topic的服务消费到,供多个毫无关联的业务使用。
-
健壮性:消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行。
-
异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
2、Kafka的常用组件有哪些?
producer:消息的生产者, 自己决定哪个 partions 中生产消息, 两种机制:hash 与 轮询。
consumer:通过 zookeeper 进行维护消费者偏移量, consumer有自己的消费组,不同组之间维护同一个 topic 数据,互不影响.相同组的不同 consumer消费同一个 topic,这个 topic相同的数据只被消费一次。
broker:broker 组成 kafka 集群的节点,之间没有主从关系, 依赖 zookeeper进行协调, broker 负责消息的读写与存储, 一个 broker可以管理读个
partionstopic:一类消息的总称/消息队里, topic是由 partions组成, 一个 topic 由多台 server 里的 partions 组成。zookeeper 协调 kafka broker,存储元数据, consumer的 offset+ broker 信息 +topic信息+ partions信息partions 组成 topic 的单元, 每个 topic有副本(创建 topic 指定), 每个 partions 只能有有个 broker管理
3、数据传输的事物定义有哪三种?
数据传输的事务定义通常有以下三种级别:
-
最多一次: 消息不会被重复发送,最多被传输一次,但也有可能一次不传输。
-
最少一次: 消息不会被漏发送,最少被传输一次,但也有可能被重复传输。
-
精确的一次(Exactly once): 不会漏传输也不会重复传输,每个消息都传输被一次而 且仅仅被传输一次,这是大家所期望的。
4、ZooKeeper在Kafka中的作用是什么?
Apache Kafka是一个使用Zookeeper构建的分布式系统。虽然,Zookeeper的主要作用是在集群中的不同节点之间建立协调。但是,如果任何节点失败,我们还使用Zookeeper从先前提交的偏移量中恢复,因为它做周期性提交偏移量工作。
5、没有ZooKeeper可以使用Kafka吗?
zookeeper 是一个分布式的协调组件,早期版本的kafka用zk做meta信息存储,consumer的消费状态,group的管理以及 offset的值。考虑到zk本身的一些因素以及整个架构较大概率存在单点问题,新版本中逐渐弱化了zookeeper的作用。新的consumer使用了kafka内部的group coordination协议,也减少了对zookeeper的依赖。但是broker依然依赖于ZK,zookeeper 在kafka中还用来选举controller 和 检测broker是否存活等等。
6、Kafka 判断一个节点是否还活着有那两个条件?
-
节点必须可以维护和 ZooKeeper 的连接,Zookeeper 通过心跳机制检查每个节点的连接。
-
如果节点是个 follower,他必须能及时的同步 leader 的写操作,延时不能太久。
7、解释偏移的作用。
给分区中的消息提供了一个顺序ID号,我们称之为偏移量。因此,为了唯一地识别分区中的每条消息,我们使用这些偏移量。
8、producer 是否直接将数据发送到 broker 的 leader(主节点)?
producer 直接将数据发送到 broker 的 leader(主节点),不需要在多个节点进行分发,为了 帮助 producer 做到这点,所有的 Kafka 节点都可以及时的告知:哪些节点是活动的,目标topic 目标分区的 leader 在哪。这样 producer 就可以直接将消息发送到目的地了。
9、Kafa consumer 是否可以消费指定分区消息?
Kafa consumer 消费消息时,向 broker 发出"fetch"请求去消费特定分区的消息,consumer指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,customer 拥有 了 offset 的控制权,可以向后回滚去重新消费之前的消息,这是很有意义的。
10、Kafka 存储在硬盘上的消息格式是什么?
消息由一个固定长度的头部和可变长度的字节数组组成。头部包含了一个版本号和 CRC32校验码。
-
消息长度: 4 bytes (value: 1+4+n)
-
版本号: 1 byte
-
CRC 校验码: 4 bytes
-
具体的消息: n bytes
11、kafka follower如何与leader同步数据?
Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。完全同步复制要求All Alive Follower都复制完,这条消息才会被认为commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,Follower异步的从Leader复制数据,数据只要被Leader写入log就被认为已经commit,这种情况下,如果leader挂掉,会丢失数据,kafka使用ISR的方式很好的均衡了确保数据不丢失以及吞吐率。Follower可以批量的从Leader复制数据,而且Leader充分利用磁盘顺序读以及send file(zero copy)机制,这样极大的提高复制性能,内部批量写磁盘,大幅减少了Follower与Leader的消息量差。
12、Kafka 高效文件存储设计特点:
-
Kafka 把 topic 中一个 parition 大文件分成多个小文件段,通过多个小文件段,就容易定 期清除或删除已经消费完文件,减少磁盘占用。
-
通过索引信息可以快速定位 message 和确定 response 的最大大小。
-
通过 index 元数据全部映射到 memory,可以避免 segment file 的 IO 磁盘操作。
-
通过索引文件稀疏存储,可以大幅降低 index 文件元数据占用空间大小。
13、Kafka 与传统消息系统之间有三个关键区别
-
Kafka 持久化日志,这些日志可以被重复读取和无限期保留
-
Kafka 是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过复制数据 提升容错能力和高可用性
-
Kafka 支持实时的流式处理
14、Kafka为什么那么快?
-
Cache Filesystem Cache PageCache缓存
-
顺序写 由于现代的操作系统提供了预读和写技术,磁盘的顺序写大多数情况下比随机写内存还要快。
-
Zero-copy 零拷技术减少拷贝次数
-
Batching of Messages 批量量处理。合并小的请求,然后以流的方式进行交互,直顶网络上限。
-
Pull 拉模式 使用拉模式进行消息的获取消费,与消费端处理能力相符。
15、什么情况下一个 broker 会从 isr中踢出去?
leader会维护一个与其基本保持同步的Replica列表,该列表称为ISR(in-sync Replica),每个Partition都会有一个ISR,而且是由leader动态维护 ,如果一个follower比一个leader落后太多,或者超过一定时间未发起数据复制请求,则leader将其重ISR中移除 。
16、kafka producer如何优化打入速度?
-
增加线程
-
提高 batch.size
-
增加更多 producer 实例
-
增加 partition 数
-
设置 acks=-1 时,如果延迟增大:可以增大 num.replica.fetchers(follower 同步数据的线程数)来调解;
-
跨数据中心的传输:增加 socket 缓冲区设置以及 OS tcp 缓冲区设置。
17、kafka producer 打数据,ack 为 0, 1, -1 的时候代表啥(ack机制), 设置 -1 的时候,什么情况下,leader 会认为一条消息 commit了?
-
1(默认) 数据发送到Kafka后,经过leader成功接收消息的的确认,就算是发送成功了。在这种情况下,如果leader宕机了,则会丢失数据。
-
0 生产者将数据发送出去就不管了,不去等待任何返回。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
-
-1 producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。当ISR中所有Replica都向Leader发送ACK时,leader才commit,这时候producer才能认为一个请求中的消息都commit了。
18、Kafka中的消息是否会丢失和重复消费?
要确定Kafka的消息是否丢失或重复,从两个方面分析入手:消息发送和消息消费。
1、消息发送
Kafka消息发送有两种方式:**同步(sync)和异步(async)**,默认是同步方式,可通过producer.type属性进行配置。Kafka通过配置request.required.acks属性来确认消息的生产:
-
0---表示不进行消息接收是否成功的确认;
-
1---表示当Leader接收成功时确认;
-
-1---表示Leader和Follower都接收成功时确认;
综上所述,有6种消息生产的情况,下面分情况来分析消息丢失的场景:
(1)acks=0,不和Kafka集群进行消息接收确认,则当网络异常、缓冲区满了等情况时,消息可能丢失;
(2)acks=1、同步模式下,只有Leader确认接收成功后但挂掉了,副本没有同步,数据可能丢失;
2、消息消费
Kafka消息消费有两个consumer接口,Low-level API和High-level API:
-
Low-level API:消费者自己维护offset等值,可以实现对Kafka的完全控制;
-
High-level API:封装了对parition和offset的管理,使用简单;
如果使用高级接口High-level API,可能存在一个问题就是当消息消费者从集群中把消息取出来、并提交了新的消息offset值后,还没来得及消费就挂掉了,那么下次再消费时之前没消费成功的消息就“诡异”的消失了;
解决办法:
-
针对消息丢失:同步模式下,确认机制设置为-1,即让消息写入Leader和Follower之后再确认消息发送成功;异步模式下,为防止缓冲区满,可以在配置文件设置不限制阻塞超时时间,当缓冲区满时让生产者一直处于阻塞状态;
-
针对消息重复:将消息的唯一标识保存到外部介质中,每次消费时判断是否处理过即可。
消息重复消费及解决参考:https://www.javazhiyin.com/22910.html
19、为什么Kafka不支持读写分离?
在 Kafka 中,生产者写入消息、消费者读取消息的操作都是与 leader 副本进行交互的,从 而实现的是一种主写主读的生产消费模型。
Kafka 并不支持主写从读,因为主写从读有 2 个很明 显的缺点:
-
数据一致性问题。数据从主节点转到从节点必然会有一个延时的时间窗口,这个时间 窗口会导致主从节点之间的数据不一致。某一时刻,在主节点和从节点中 A 数据的值都为 X, 之后将主节点中 A 的值修改为 Y,那么在这个变更通知到从节点之前,应用读取从节点中的 A 数据的值并不为最新的 Y,由此便产生了数据不一致的问题。
-
延时问题。类似 Redis 这种组件,数据从写入主节点到同步至从节点中的过程需要经 历网络→主节点内存→网络→从节点内存这几个阶段,整个过程会耗费一定的时间。而在 Kafka 中,主从同步会比 Redis 更加耗时,它需要经历网络→主节点内存→主节点磁盘→网络→从节 点内存→从节点磁盘这几个阶段。对延时敏感的应用而言,主写从读的功能并不太适用。
20、Kafka中是怎么体现消息顺序性的?
kafka每个partition中的消息在写入时都是有序的,消费时,每个partition只能被每一个group中的一个消费者消费,保证了消费时也是有序的。
整个topic不保证有序。如果为了保证topic整个有序,那么将partition调整为1.
21、消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1?
offset+1
22、kafka如何实现延迟队列?
Kafka并没有使用JDK自带的Timer或者DelayQueue来实现延迟的功能,而是基于时间轮自定义了一个用于实现延迟功能的定时器(SystemTimer)。JDK的Timer和DelayQueue插入和删除操作的平均时间复杂度为O(nlog(n)),并不能满足Kafka的高性能要求,而基于时间轮可以将插入和删除操作的时间复杂度都降为O(1)。时间轮的应用并非Kafka独有,其应用场景还有很多,在Netty、Akka、Quartz、Zookeeper等组件中都存在时间轮的踪影。
底层使用数组实现,数组中的每个元素可以存放一个TimerTaskList对象。TimerTaskList是一个环形双向链表,在其中的链表项TimerTaskEntry中封装了真正的定时任务TimerTask.
Kafka中到底是怎么推进时间的呢?Kafka中的定时器借助了JDK中的DelayQueue来协助推进时间轮。具体做法是对于每个使用到的TimerTaskList都会加入到DelayQueue中。Kafka中的TimingWheel专门用来执行插入和删除TimerTaskEntry的操作,而DelayQueue专门负责时间推进的任务。再试想一下,DelayQueue中的第一个超时任务列表的expiration为200ms,第二个超时任务为840ms,这里获取DelayQueue的队头只需要O(1)的时间复杂度。如果采用每秒定时推进,那么获取到第一个超时的任务列表时执行的200次推进中有199次属于“空推进”,而获取到第二个超时任务时有需要执行639次“空推进”,这样会无故空耗机器的性能资源,这里采用DelayQueue来辅助以少量空间换时间,从而做到了“精准推进”。Kafka中的定时器真可谓是“知人善用”,用TimingWheel做最擅长的任务添加和删除操作,而用DelayQueue做最擅长的时间推进工作,相辅相成。
参考文章:https://blog.csdn.net/u013256816/article/details/80697456
参考文章:https://blog.csdn.net/qq_28900249/article/details/90346599
kafka怎么处理消息顺序、重复发送、重复消费、消息丢失
Kafka在什么情况下会出现消息丢失及解决方案?
-
消息发送
-
ack=0,不重试 producer发送消息完,不管结果了,如果发送失败也就丢失了。
-
ack=1,leader crash producer发送消息完,只等待lead写入成功就返回了,leader crash了,这时follower没来及同步,消 息丢失。
-
unclean.leader.election.enable 配置true 允许选举ISR以外的副本作为leader,会导致数据丢失,默认为false。producer发送异步消息完,只等待 lead写入成功就返回了,leader crash了,这时ISR中没有follower,leader从OSR中选举,因为OSR 中本来落后于Leader造成消息丢失。
解决方案:
-
配置:ack=all / -1,tries > 1,unclean.leader.election.enable : false producer发送消息完,等待follower同步完再返回,如果异常则重试。副本的数量可能影响吞吐量。
不允许选举ISR以外的副本作为leader。
-
配置:min.insync.replicas > 1
副本指定必须确认写操作成功的最小副本数量。如果不能满足这个最小值,则生产者将引发一个异常(要么是 NotEnoughReplicas,要么是NotEnoughReplicasAfterAppend)。 min.insync.replicas和ack更大的持久性保证。确保如果大多数副本没有收到写操作,则生产者将引发异 常。
-
失败的offset单独记录 producer发送消息,会自动重试,遇到不可恢复异常会抛出,这时可以捕获异常记录到数据库或缓存,进行 单独处理。
-
-
消费
先commit再处理消息。如果在处理消息的时候异常了,但是offset 已经提交了,这条消息对于该消费者来 说就是丢失了,再也不会消费到了。
-
broker的刷盘
减小刷盘间隔
Kafka是pull?push?优劣势分析
pull模式:
-
根据consumer的消费能力进行数据拉取,可以控制速率
-
可以批量拉取、也可以单条拉取
-
可以设置不同的提交方式,实现不同的传输语义
缺点:如果kafka没有数据,会导致consumer空循环,消耗资源
解决:通过参数设置,consumer拉取数据为空或者没有达到一定数量时进行阻塞
push模式:不会导致consumer循环等待
优点:不会导致consumer循环等待
缺点:速率固定、忽略了consumer的消费能力,可能导致拒绝服务或者网络拥塞等情况
Kafka中zk的作用
/brokers/ids:临时节点,保存所有broker节点信息,存储broker的物理地址、版本信息、启动时间 等,节点名称为brokerID,broker定时发送心跳到zk,如果断开则该brokerID会被删除
/brokers/topics:临时节点,节点保存broker节点下所有的topic信息,每一个topic节点下包含一个固 定的partitions节点,partitions的子节点就是topic的分区,每个分区下保存一个state节点、保存着当 前leader分区和ISR的brokerID,state节点由leader创建,若leader宕机该节点会被删除,直到有新的 leader选举产生、重新生成state节点
/consumers/[group_id]/owners/[topic]/[broker_id-partition_id]:维护消费者和分区的注册关系
/consumers/[group_id]/offsets/[topic]/[broker_id-partition_id]:分区消息的消费进度Offset
client通过topic找到topic树下的state节点、获取leader的brokerID,到broker树中找到broker的物理 地址,但是client不会直连zk,而是通过配置的broker获取到zk中的信息
简述kafka的rebalance机制
consumer group中的消费者与topic下的partion重新匹配的过程
何时会产生rebalance:
-
consumer group中的成员个数发生变化
-
consumer消费超时
-
group订阅的topic个数发生变化
-
group订阅的topic的分区数发生变化
coordinator:通常是partition的leader节点所在的broker,负责监控group中consumer的存活, consumer维持到coordinator的心跳,判断consumer的消费超时
-
coordinator通过心跳返回通知consumer进行rebalance
-
consumer请求coordinator加入组,coordinator选举产生leader consumer
-
leader consumer从coordinator获取所有的consumer,发送syncGroup(分配信息)给到 coordinator
-
coordinator通过心跳机制将syncGroup下发给consumer
-
完成rebalance
leader consumer监控topic的变化,通知coordinator触发rebalance
如果C1消费消息超时,触发rebalance,重新分配后、该消息会被其他消费者消费,此时C1消费完成提 交offset、导致错误
解决:coordinator每次rebalance,会标记一个Generation给到consumer,每次rebalance该 Generation会+1,consumer提交offset时,coordinator会比对Generation,不一致则拒绝提交
Kafka的性能好在什么地方
kafka不基于内存,而是硬盘存储,因此消息堆积能力更强
顺序写:利用磁盘的顺序访问速度可以接近内存,kafka的消息都是append操作,partition是有序的, 节省了磁盘的寻道时间,同时通过批量操作、节省写入次数,partition物理上分为多个segment存储, 方便删除
传统:
-
读取磁盘文件数据到内核缓冲区
-
将内核缓冲区的数据copy到用户缓冲区
-
将用户缓冲区的数据copy到socket的发送缓冲区
-
将socket发送缓冲区中的数据发送到网卡、进行传输
零拷贝:
-
直接将内核缓冲区的数据发送到网卡传输
-
使用的是操作系统的指令支持
kafka不太依赖jvm,主要理由操作系统的pageCache,如果生产消费速率相当,则直接用pageCache 交换数据,不需要经过磁盘IO
MQ
MQ是什么
https://www.zhihu.com/question/54152397?sort=created
简述RabbitMQ的架构设计
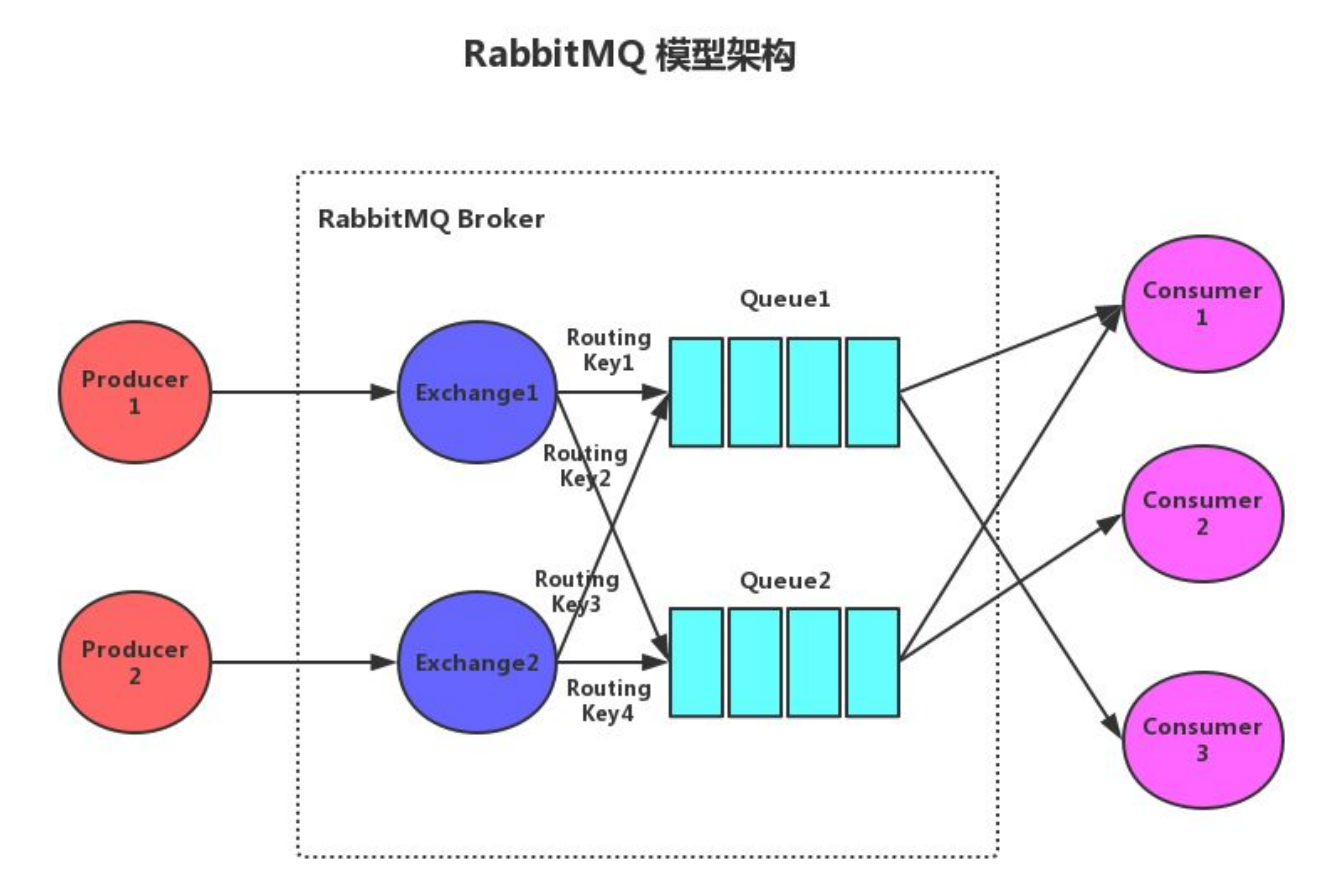
Broker:rabbitmq的服务节点
Queue:队列,是RabbitMQ的内部对象,用于存储消息。RabbitMQ中消息只能存储在队列中。生产者投递消息到队列,消费者从队列中获取消息并消费。多个消费者可以订阅同一个队列,这时队列中的 消息会被平均分摊(轮询)给多个消费者进行消费,而不是每个消费者都收到所有的消息进行消费。(注 意:RabbitMQ不支持队列层面的广播消费,如果需要广播消费,可以采用一个交换器通过路由Key绑 定多个队列,由多个消费者来订阅这些队列的方式。
Exchange:交换器。生产者将消息发送到Exchange,由交换器将消息路由到一个或多个队列中。如果路由不到,或返回给生产者,或直接丢弃,或做其它处理。
RoutingKey:路由Key。生产者将消息发送给交换器的时候,一般会指定一个RoutingKey,用来指定 这个消息的路由规则。这个路由Key需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效。 在交换器类型和绑定键固定的情况下,生产者可以在发送消息给交换器时通过指定RoutingKey来决定消息流向哪里。
Binding:通过绑定将交换器和队列关联起来,在绑定的时候一般会指定一个绑定键,这样RabbitMQ 就可以指定如何正确的路由到队列了。
交换器和队列实际上是多对多关系。就像关系数据库中的两张表。他们通过BindingKey做关联(多对多 关系表)。在投递消息时,可以通过Exchange和RoutingKey(对应BindingKey)就可以找到相对应的队列。
信道:信道是建立在Connection 之上的虚拟连接。当应用程序与Rabbit Broker建立TCP连接的时候, 客户端紧接着可以创建一个AMQP 信道(Channel) ,每个信道都会被指派一个唯一的D。RabbitMQ 处理的每条AMQP 指令都是通过信道完成的。信道就像电缆里的光纤束。一条电缆内含有许多光纤束,允许所有的连接通过多条光线束进行传输和接收。
RabbitMQ如何确保消息发送 ? 消息接收?
发送方确认机制:
信道需要设置为 confirm 模式,则所有在信道上发布的消息都会分配一个唯一 ID。
一旦消息被投递到queue(可持久化的消息需要写入磁盘),信道会发送一个确认给生产者(包含消息唯一 ID)。
如果 RabbitMQ 发生内部错误从而导致消息丢失,会发送一条 nack(未确认)消息给生产者。
所有被发送的消息都将被 confirm(即 ack) 或者被nack一次。但是没有对消息被 confirm 的快慢做 任何保证,并且同一条消息不会既被 confirm又被nack
发送方确认模式是异步的,生产者应用程序在等待确认的同时,可以继续发送消息。当确认消息到达生产者, 生产者的回调方法会被触发。
ConfirmCallback接口:只确认是否正确到达 Exchange 中,成功到达则回调
ReturnCallback接口:消息失败返回时回调
接收方确认机制:
消费者在声明队列时,可以指定noAck参数,当noAck=false时,RabbitMQ会等待消费者显式发回ack信号 后才从内存(或者磁盘,持久化消息)中移去消息。否则,消息被消费后会被立即删除。
消费者接收每一条消息后都必须进行确认(消息接收和消息确认是两个不同操作)。只有消费者确认了消息, RabbitMQ 才能安全地把消息从队列中删除。
RabbitMQ不会为未ack的消息设置超时时间,它判断此消息是否需要重新投递给消费者的唯一依据是消费该 消息的消费者连接是否已经断开。这么设计的原因是RabbitMQ允许消费者消费一条消息的时间可以很长。保 证数据的最终一致性;
如果消费者返回ack之前断开了链接,RabbitMQ 会重新分发给下一个订阅的消费者。(可能存在消息重复消 费的隐患,需要去重)
RabbitMQ事务消息
通过对信道的设置实现
-
channel.txSelect();通知服务器开启事务模式;服务端会返回Tx.Select-Ok
-
channel.basicPublish;发送消息,可以是多条,可以是消费消息提交ack
-
channel.txCommit()提交事务;
-
channel.txRollback()回滚事务;
消费者使用事务:
-
autoAck=false,手动提交ack,以事务提交或回滚为准;
-
autoAck=true,不支持事务的,也就是说你即使在收到消息之后在回滚事务也是于事无补的,队 列已经把消息移除了
如果其中任意一个环节出现问题,就会抛出IoException异常,用户可以拦截异常进行事务回滚,或决 定要不要重复消息。
事务消息会降低rabbitmq的性能
RabbitMQ死信队列、延时队列
-
消息被消费方否定确认,使用 channel.basicNack 或 channel.basicReject ,并且此时 requeue 属性被设置为 false 。
-
消息在队列的存活时间超过设置的TTL时间。
-
消息队列的消息数量已经超过最大队列长度。
那么该消息将成为“死信”。“死信”消息会被RabbitMQ进行特殊处理,如果配置了死信队列信息,那么该 消息将会被丢进死信队列中,如果没有配置,则该消息将会被丢弃
为每个需要使用死信的业务队列配置一个死信交换机,这里同一个项目的死信交换机可以共用一个,然 后为每个业务队列分配一个单独的路由key,死信队列只不过是绑定在死信交换机上的队列,死信交换 机也不是什么特殊的交换机,只不过是用来接受死信的交换机,所以可以为任何类型【Direct、 Fanout、Topic】
TTL:一条消息或者该队列中的所有消息的最大存活时间
如果一条消息设置了TTL属性或者进入了设置TTL属性的队列,那么这条消息如果在TTL设置的时间内没 有被消费,则会成为“死信”。如果同时配置了队列的TTL和消息的TTL,那么较小的那个值将会被使用。
只需要消费者一直消费死信队列里的消息
RabbitMQ镜像队列机制
镜像queue有master节点和slave节点。master和slave是针对一个queue而言的,而不是一个node作 为所有queue的master,其它node作为slave。一个queue第一次创建的node为它的master节点,其 它node为slave节点。
无论客户端的请求打到master还是slave最终数据都是从master节点获取。当请求打到master节点时, master节点直接将消息返回给client,同时master节点会通过GM(Guaranteed Multicast)协议将 queue的最新状态广播到slave节点。GM保证了广播消息的原子性,即要么都更新要么都不更新。
当请求打到slave节点时,slave节点需要将请求先重定向到master节点,master节点将将消息返回给 client,同时master节点会通过GM协议将queue的最新状态广播到slave节点。
如果有新节点加入,RabbitMQ不会同步之前的历史数据,新节点只会复制该节点加入到集群之后新增 的消息。
简述kafka架构设计
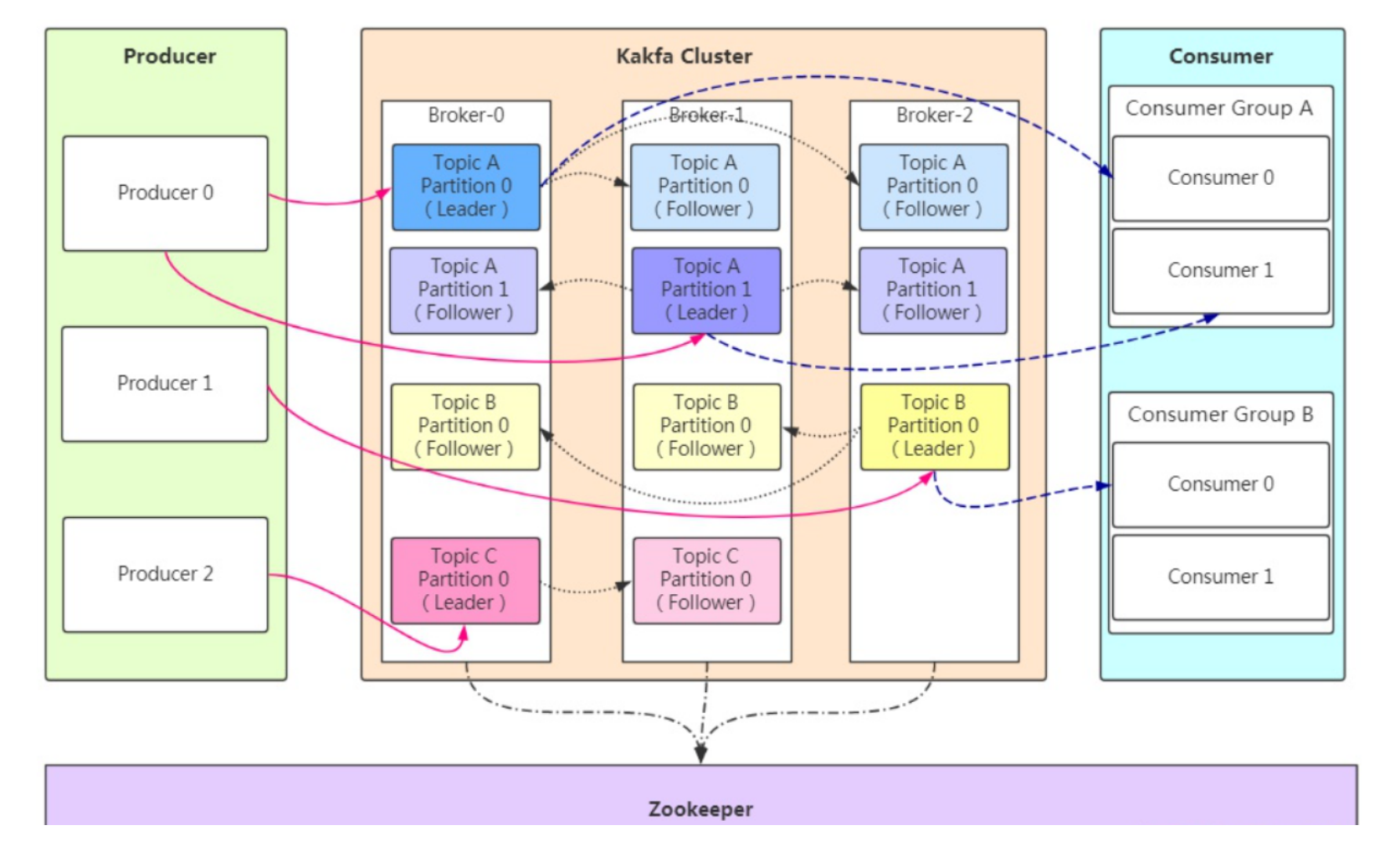
Consumer Group:消费者组,消费者组内每个消费者负责消费不同分区的数据,提高消费能力。逻 辑上的一个订阅者。
Topic:可以理解为一个队列,Topic 将消息分类,生产者和消费者面向的是同一个 Topic。
Partition:为了实现扩展性,提高并发能力,一个Topic 以多个Partition的方式分布到多个 Broker 上,每个 Partition 是一个 有序的队列。一个 Topic 的每个Partition都有若干个副本(Replica),一个 Leader 和若干个 Follower。生产者发送数据的对象,以及消费者消费数据的对象,都是 Leader。 Follower负责实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 还会成为新的 Leader。
Offset:消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉再重新恢复的时候,可以从 消费位置继续消费。
Zookeeper:Kafka 集群能够正常工作,需要依赖于 Zookeeper,Zookeeper 帮助 Kafka 存储和管理 集群信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号