
正则表达式
正则表达式的三大功能
1.匹配,2:提取,3:替换(sub)
一.普通字符(a-z)
二.元字符(特殊字符)有7类:
1.字符集(以单个字符划分)以[]表示,[abf]:或者a或者b或者f
[a-z]:匹配a-z之间的字符
[^a-z]:匹配不在a-z之间的字符。
2.概括字符集:
\d :匹配数字;[0-9]
\w:表示该位置上的字母,数字或者下划线; == [A-Za-z0-9_ ]
\s:表示该位置上是不可见字符(空格、制表符\t、垂直制 表符\v、回车符\r、换行符\n、换页符\f)== [\f\n\t\r\v]
. 匹配任意字符,不包括换行符。
3.数量词有{3}:该字符出现三次/ {3-8}:该字符出现3-8次;
限定符(可作为数量词来记忆):
+(1-n):+前面的字符可以出现多次;eg:可以匹配 runoob、runooob、runoooooob 等,+ 号代表前面的字符必须至少出现一次(1次或多次)
?(0-1):?前的字符不出现或者只出现一次;eg:colou?r 可以匹配 color 或者 colour,? 问号代表前面的字符最多只可以出现一次(0次、或1次)。
*(0-n):*前面的字符出现0次或者出现多次;eg:runoo*b,可以匹配 runob、runoob、runoooooob 等,* 号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次)。
. :在默认模式,匹配除了换行的任意字符。如果指定了标签 DOTALL ,它将匹配包括换行符的任意字符 .* :表示匹配除换行符外的任意字符 * , + :是贪婪的。在他们的后面加上?就可以实现最小匹配,即非贪婪。
4.组:提取其中某一连续的满足 某个条件的字符串
(\d+),增加了()
5.match:在用match方法的时候有一个需要注意的地方,很重要,非常容易导致出错,
match方法是从content第一个字符开始去匹配\d,如果未匹配到,直接就返回None。这里因为content第一个字符不是数字,所以直接返回None
6.贪婪跟非贪婪
.*?表示非贪婪模式:是尽可能少地去匹配字符/匹配的越少,得到的结果越多
.*表示贪婪模式,尽可能多的去匹配字符,python默认采取的是贪婪模式/匹配的越多得到的结果越少
7.search方法和sub方法与match方法的比较:
使用match方法,会从content的开头去匹配\d,没有匹配到就直接返回None 了。
而search方法也是从头开始匹配,只要匹配到有一个字符符合\d,就直接返回了,不会继 续往下匹配。
sub方法:替换。
sub方法设计的精妙之处,就是sub的第二个参数可以是一个函数。就在于当你拿到匹配结果的时候,不一定要将它替换成固定的字符串,
你可以传递一个函数,在函数中对匹配结果进行逻辑处理,这样主动权就交到了用户手上,用 户可以随便处理
8.\ :表示转义字符,将一个字符标记为特殊的字符,例如n匹配n,\n匹配换行符
9:
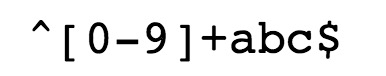
^ 为匹配输入字符串的开始位置。
[0-9]+匹配多个数字, [0-9] 匹配单个数字,+ 匹配一个或者多个。
abc$匹配字母 abc 并以 abc 结尾,$ 为匹配输入字符串的结束位置。
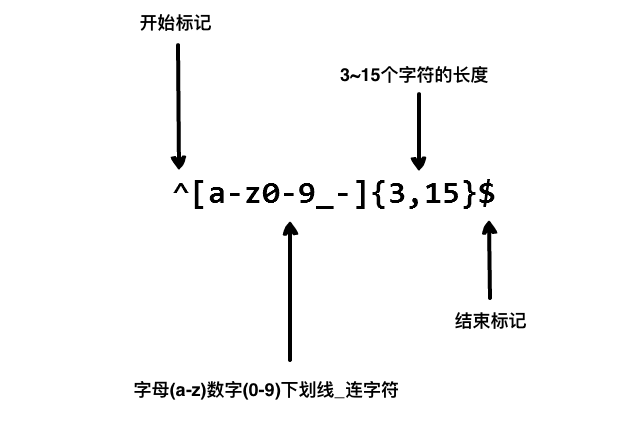
10:定位符
^ : 匹配输入字符开始的位置,在中括号内则表示非的意思。
$ :匹配输入字符结束的位置。
注意:不能将限定符与定位符一起使用。
三:注意
1.正则表达式中的or有两种表达方法:1: | ,2:[]后面可以与其他字符串连接。
2.[0-9]等价于[0123456789]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号