


数据库
#操作数据库 #增:create database db1; #查:show databases; #改:alter database db1 charset latin1; #删:drop database db1; #操作表: use database; #增:create table t1(id int,name char); #查:show tables; #改:alter table t1 modify name char(3); alter table t1 change name name1 char(3); #删:drop table t1; #操作文件中的内容: #增:insert into t1(id,name) values(1,'egon'),(2,'egon1'),(3,'egon2'); #查:select * from t1; #改:update t1 set name='sb' where id=2; #删:delete from t1 where id=1; #清空表:delete from t1; truncate table t1;
关系型数据库:sqllite、db2、oracle、access、sql sever、mysql
非关系型数据库:mongodb、redis、memcache
create database staff; --创建数据库 use staff; --使用数据库 create table staff_info(id int primary key auto_increment,name varchar(50),age int(3),sex enum('male','female'),phone bigint(11),job varchar(11)); --创建表,enum是枚举 show tables; --展示staff数据库中的表,表名字 desc staff_info; --查看表结构,字段及类型等 insert into staff_info(id,name,age,sex,phone,job) values(1,'Alex',83,'female',13623457890,'IT'); --插入数据 --int(10)与int(11)的区别: --int占四个字节,一个字节8位,即可以表示的个数为2的32次方,int默认是十位的长度,加入int(3),那么就前面补0直到有十位的长度,可知int(10)与int(11)只是显示长度不同而已,在计算机中都是占四个字节三十二位,运用int(M,unsigned,zerofill)中,unsigned表示正数,zerofill会在前面用0填充,int(M)中的M指最大显示宽度,最大有效显示宽度为255,且最大的位数不超过M,只用于显示,不影响存储 insert into staff_info(id,name,age,sex,phone,job) values(2,'egon',26,'male',12345679878,'Teacher'); insert into staff_info(id,name,age,sex,phone,job) values(3,'哪吒',25,'male',78945645646,'haha');
mysql支持的数据类型
数值类型
包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL、NUMERIC),以及近似数值数据类型(FLOAT、REAL和DOUBLE PRECISION)
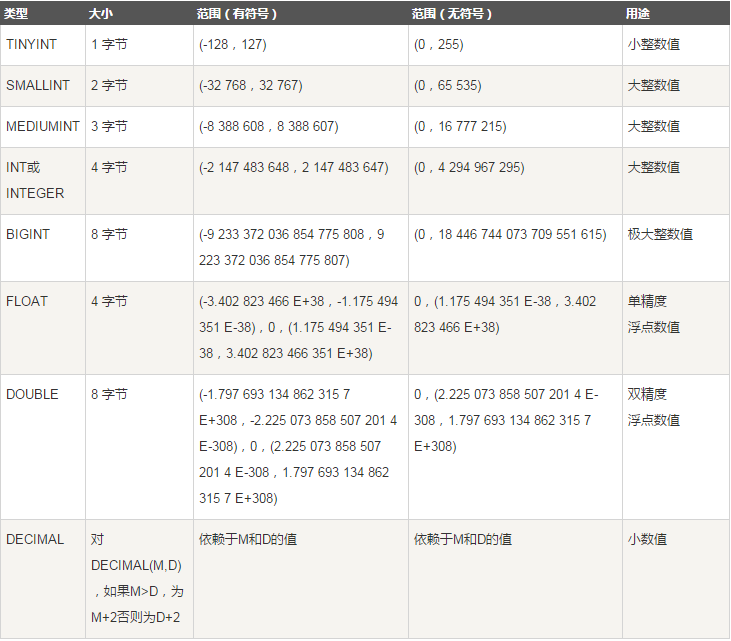
int(M)中M并不代表我可以输入多少位数,代表的是数据在显示时显示的最小长度,当输入的数字的长度大于M时,没有任何影响,只要不超过数值类型限制的范围;当位数小于M时,只有在设置了zerofill用0来填充,才能看到效果,没有zerofill,M值就是无用的。具体的取值范围参见上表。
create table t1(id1 int,id2 int(5)); insert into t1 values(1,1) --或insert into t1(id1,id2) valuses(1,1) insert into t1 values(111111,111111) --未报错 --创建表的三个字段分别是float,double和decimal参数表示一共显示5位,小数部分占两位,小数点不算位数 create table t2 (id1 float(5,2),id2 double(5,2),id3 decimal(5,2)); insert into t2 values(1.23,1.23,1.23); --1.23,1.23,1.23 insert into t2 values(1.1234,1.234,1.234); --1.23,1.23,1.23 insert into t2 values(1.235,1.235,1.235) --1.24,1.24,1.24 --float默认是加起来不超过6位,double小数位很多,decimal(10,0)四舍五入 create table t3(id1 float,id2 double,id3 decimal) insert into t3 values(1.235555555555,1.23555555555,1.235555555)--1.23556,1.23555555555555,1
日期和时间类型
表示时间值的日期时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR
每个时间类型有一个有效值范围和一个‘零’值,当指定不合法的mysql不能表示的值使用‘零’值

/...date/time/datetime.../示例 create table t4(d date,t time,dt datetime); insert into t4 values(now(),now(),now());--2019-12-20,14:29:25,2019-12-20 14:29:25 select * from t4; insert into t4 values('2020-01-01',null,null); --正确,不加引号是错误 insert into t4 values('2020-1-1',null,null); --正确,可以不加0 insert into t4 values('1',null,null); --错误 /...timestamp示例.../ create table t5(id1 timestamp); insert into t5 values('20201214123001');--插入时间 insert into t5 values('2038-01-19 11:14:08'); --插入时间,下限为19700101080000,上限为20380119111407 /...year示例.../ create table t7(y year); insert into t7 values(201); --报错 insert into t7 values(2019); --正常 /...datetime示例.../ create table t8(dt datetime); insert into t8 values('2019-12-20 15:00:00'); insert into t8 values('2019/12/20 15+00+00'); insert into t8 values('20191220150000'); insert into t8 values(20191220150000);
字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET
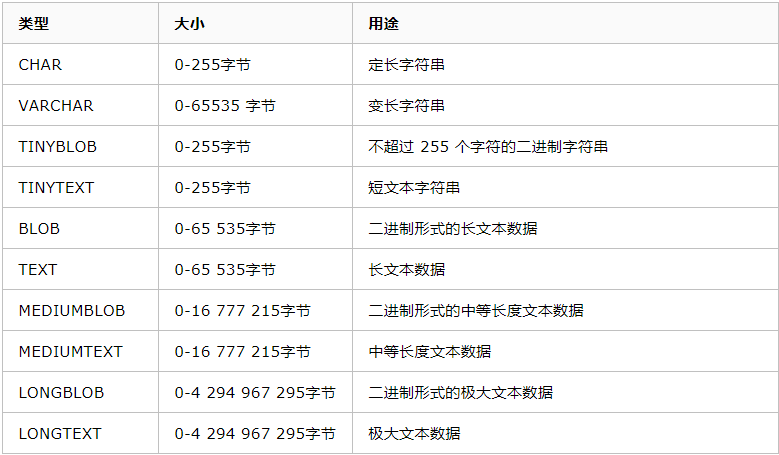
create table t9(v varchar(4),c char(4));--无论是varchar还是char都不能超过M,但是都可以小于M,若char小于M然后在右边用空格补齐,varchar不用补齐,varchar比char更节省空间,但是效率低一些,即空间换效率 insert into t9 values('ab','ba'); concat函数:将多个字符串连接成一个字符串,如果有任何一个参数为null,返回值为null select concat(id,name,score) as info from tt2; select concat(id,',',name,',',score) as info from tt2;--加一个逗号分隔符,相当于select concat_ws(',',id,name,score) as info from tt2; select name,group_concat(id order by id desc separator '-') --分组并排展示 https://baijiahao.baidu.com/s?id=1595349117525189591&wfr=spider&for=pc
ENUM和SET类型
ENUM中文名称叫枚举类型,它的取值范围需要在创建表时通过枚举方式显示,ENUM只允许从值集合中选取单个值,而不能一次取多个值
SET和ENUM非常相似,也是一个字符串对象,里面可以包含0-64个成员,根据成员的不同,存储上也有所不同,SET类型可以允许值集合中任意选择一个或多个元素进行组合,对超出范围的内容将不允许注入,而对重复的值将进行自动去重
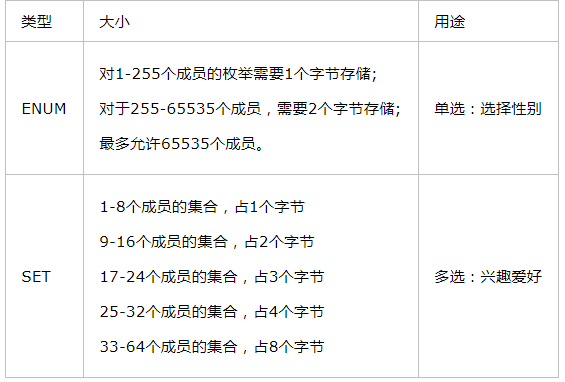
create table t10(name char(20),gender enum('female','male')); insert into t10 values('哪吒',male'); insert into t10 values('哪吒','male,female'); --错误 create table t11(name char(20),hobby set('抽烟','喝酒','烫头','翻车')); insert into t11 values('yuan','烫头,喝酒,烫头'); --正确 insert into t11 values('抽烟','蹦迪'); --错误
文件中的操作
#增: insert into 表名 values(值1,值2,值3...); insert into 表名(字段1,字段2,字段3...,) values(值1,值2,值3...); insert into 表名 values(值1,值2,值3),(值4,值5,值6),(值7,值8,值9); #更新: update 表名 set 字段1 = 值1,字段2 = 值2 where condition;
单表查询
create table employee( id int not null unique auto_increment, emp_name varchar(20) not null, sex enum('male','female') not null default 'male', #大部分是男的 age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, #一个部门一个屋子 depart_id int ); insert into employee(emp_name,sex,age,hire_date,post,salary,office,depart_id) values ('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部 ('alex','male',78,'20150302','teacher',1000000.31,401,1), ('wupeiqi','male',81,'20130305','teacher',8300,401,1), ('yuanhao','male',73,'20140701','teacher',3500,401,1), ('liwenzhou','male',28,'20121101','teacher',2100,401,1), ('jingliyang','female',18,'20110211','teacher',9000,401,1), ('jinxin','male',18,'19000301','teacher',30000,401,1), ('成龙','male',48,'20101111','teacher',10000,401,1), ('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门 ('丫丫','female',38,'20101101','sale',2000.35,402,2), ('丁丁','female',18,'20110312','sale',1000.37,402,2), ('星星','female',18,'20160513','sale',3000.29,402,2), ('格格','female',28,'20170127','sale',4000.33,402,2), ('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门 ('程咬金','male',18,'19970312','operation',20000,403,3), ('程咬银','female',18,'20130311','operation',19000,403,3), ('程咬铜','male',18,'20150411','operation',18000,403,3), ('程咬铁','female',18,'20140512','operation',17000,403,3) ;
单表查询语法:
select distinct 字段1,字段2...from 表名 where 条件 group by . .having..order by..limit()
关键字执行的优先级:
from---->where---->group by---->select---->distinct---->having---->order by---->limit---->结果
CONCAT
select concat('姓名:',emp_name,'年薪:',salary*12) as annual_salary from employee; --将其拼接起来
select concat_ws(':',emp_name,salary*12) as annual_salary from employee;
select post,group_concat(emp_name) from employee group by post; --按照岗位分组,并查看组内成员名
CASE
mysql case 列名 when then case when then 的区别:
简单case函数:case 列名 when 条件1 then 选项1 when 条件2 then 选项2 else 默认值 end
case搜索函数:case when 列名=条件1 then 选项1 when 列名=条件2 then 选项2 else 默认值 end
简单case函数可能会有一定的限制,case函数可能只返回第一个满足条件的值,剩下的case部分会被自动忽略,应该是满足了前面的后面的默认就排除了筛选。对于简单case函数来说就需要从头开始筛选,else是除了前几个
select (case when emp_name = 'jingliyang' then emp_name when emp_name = 'alex' then concat(emp_name,'_bigsb') else concat(emp_name,'sb') end) as new_name from employee;
IS NULL
select emp_name,post_comment from employee where post_comment is null;
IN
select emp_name,salary from employee where salary not in (3000,3500,4000,9000);
LIKE
select * from employee where emp_name like 'eg%';
GROUP BY
select post,group_concat(emp_name) from employee group by post; --按照岗位分组,并查看组内成员名 select post,count(id) as count from employee group by post; --按照岗位分组,并查看每组有多少人
HAVING
having与where不一样的地方在于:
1)where发生在分组group by之前,因而where中可以有任意字段,但是绝对不能使用聚合函数
2)having发生在分组group by之后,因而having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数,即选出来的才能筛选
ORDER BY
select * from employee order by age,salary desc; --先按age排序,默认是升序,如果年纪相同,则按照薪资排序,此处是降序
LIMIT
select * from employee order by salary desc limit 0,5; --从0的下一条开始提取,提取五条
多表连接查询
笛卡尔积
select * from employee,department; --例如employee:a,b;department:1,2,结果:a1,a2,b1,b2;employee和department换顺序:1a,1b,2a,2b
左连接:优先显示左表全部记录,右边的值相对于左边有重复时,左边会增多
右连接:优先显示右表全部记录,如果两边都有重复的话,一下子会增加很多,要保证不漏
内连接:只连接匹配的行
子查询
子查询是将一个查询语句嵌套在另一个查询语句中
内层查询语句的查询结果可以为外层查询语句提供查询条件
子查询中可以包含:in、not、any、all、exists和not exists等关键字,还可以包含比较运算符:=、!=、>、<等
带IN关键字的子查询
select id,name from department where id in (select dep_id from employee group by dep_id having avg(age)>25); select name from employee where dep_id in (select id from department where name='技术’); select name from department where id not in (select distinct dep_id from employee);
带比较运算符的子查询
select name,age from emp where age>(select avg(age) from emp); select t1.name,t1.age from emp t1 inner join (select dep_id,avg(age) avg_age from emp group by dep_id) t2 on t1.dep_id = t2.dep_id where t1.age > t2.avg_age;
带EXISTS关键字的子查询
EXISTS关键字表示存在,在使用EXISTS关键字时,内层查询语句不返回查询的记录,而是返回一个真假值,True或False,当返回True时,外层查询语句将进行查询,当返回False时,外层查询语句不进行查询
select * from employee where exists (select id from department where id = 200); select * from employee where exists (select id from department where id =204);
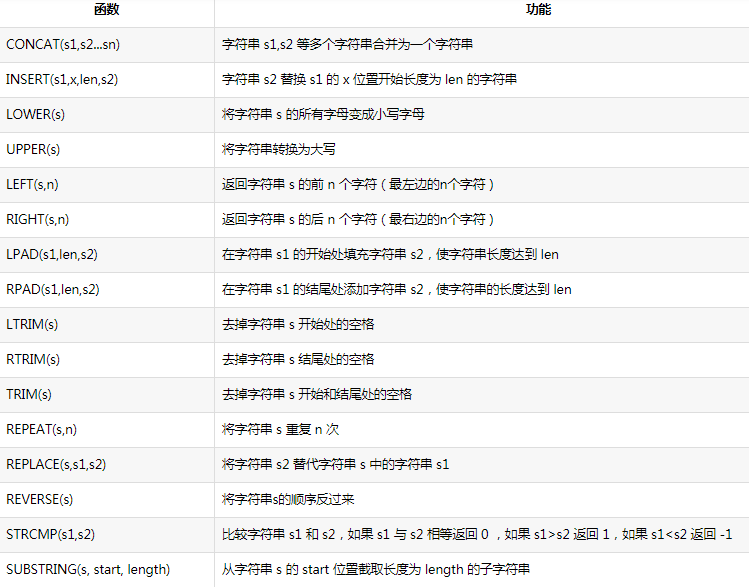
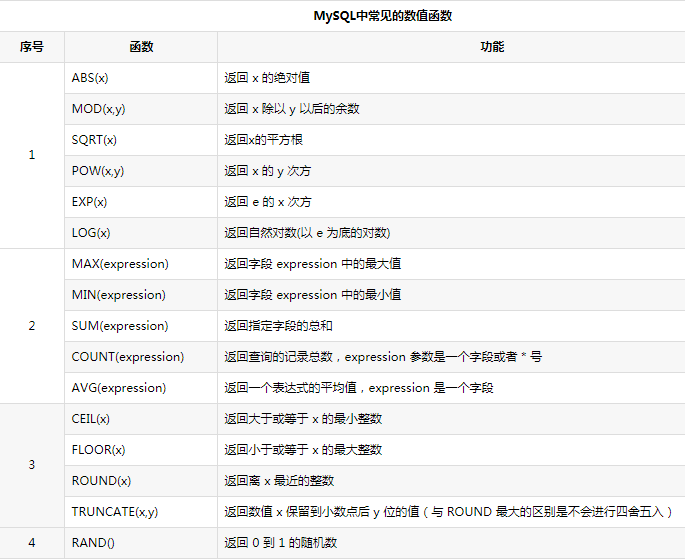
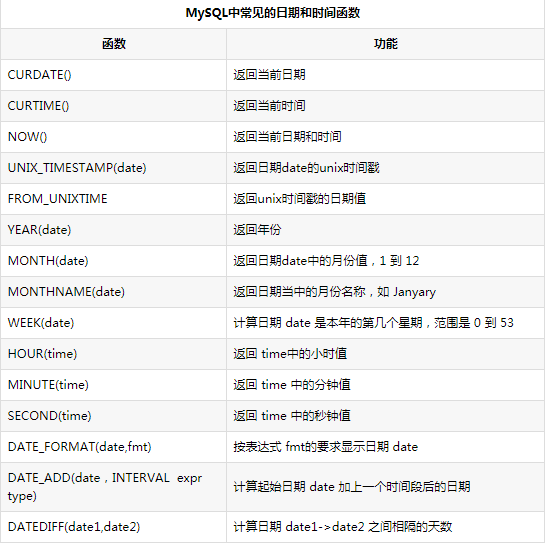
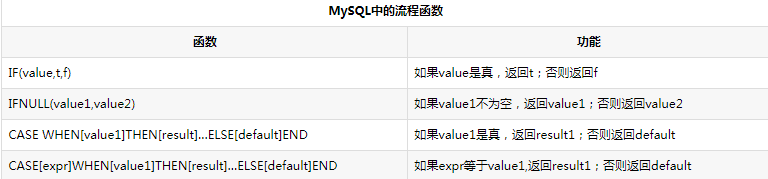
mysql中常见的函数
索引
本质:通过不断缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,可以总是用同一种查找方式来锁定数据
树状图是一种数据结构,它是由n个有限结点组成一个具有层次关系的集合,特点:每个结点有零个或多个子结点;每个非根结点有且只有一个父结点;除根节点外,每个子结点可以分为多个不想交的子树
B +树是通过二叉查找数,再由平衡二叉树,B树演化而来
mysql索引的功能就是加速查找,mysql中的primary key,unique,联合唯一也都是索引,这些索引除了加速查找之外,还有约束功能
普通索引:INDEX,加速查找
唯一索引:主键索引:PRIMARY KEY,加速查找+约束(不为空,不能重复)
唯一索引UNIQUE,加速索引+约束(不能重复)
联合索引:PRIMARY KEY(id,name),联合主键索引
UNIQUE(id,name),联合唯一索引
INDEX(id,name),联合普通索引
创建索引
create index ix_age on t1(age); --ix_age:索引名,t1:表名,age:列名 create table t1(id int,name char,job char,unique key uid_1(id),index ix_age(name),index(job)); alter table t1 add index ix_sex(sex); alter table t1 add index(sex);
一定是为搜索条件的字段创建索引,比如select * from s1 where id = 3333;就需要为id加上索引
在表中已经有大量数据的情况下,建索引会很慢,且占用磁盘空间,但是建完后查询速度加快

 浙公网安备 33010602011771号
浙公网安备 33010602011771号