


二、函数
1.调用函数
abs(100) abs(-20) max(1,2) max(2,3,1,-5)
数据类型转换
int('123') int(12.34) float('12.34') str(1.23) str(100) bool(1)
2.定义函数
return是返回值,一般放在函数的最后,一旦执行到return时,函数就执行完毕并将结果返回,且return语句块结束之后后面的代码是不执行的,即一旦遇到return结束整个
函数。
def my_abs(x): if x>=0: return x else: return -x my_abs(-1) #1
如果没有return语句,函数执行完毕后也会返回结果,只是结果为none
返回多个值
def ret_demo1(): return 1,2,3,4 def ret_demo2(): return 1,['a','b'],3,4 ret1 = ret_demo1() ret2 = ret_demo2() print(ret1) print(ret2)
(1, 2, 3, 4) (1, ['a', 'b'], 3, 4)
def ret_demo2(): return 1,['a','b'],3,4 a, b, c, d = ret_demo2() print(a, b, c, d) #返回多个值,可以用一个或多个值来接收 print(a)
1 ['a', 'b'] 3 4 1
添加了参数检查的函数,数据类型检查可以用内置函数isinstance()实现
def my_abs(x): if not isinstance(x,(int,float)): raise TypeError('bad operand type') if x>=0: return x else: return -x
求根
import math math.sqrt(10)
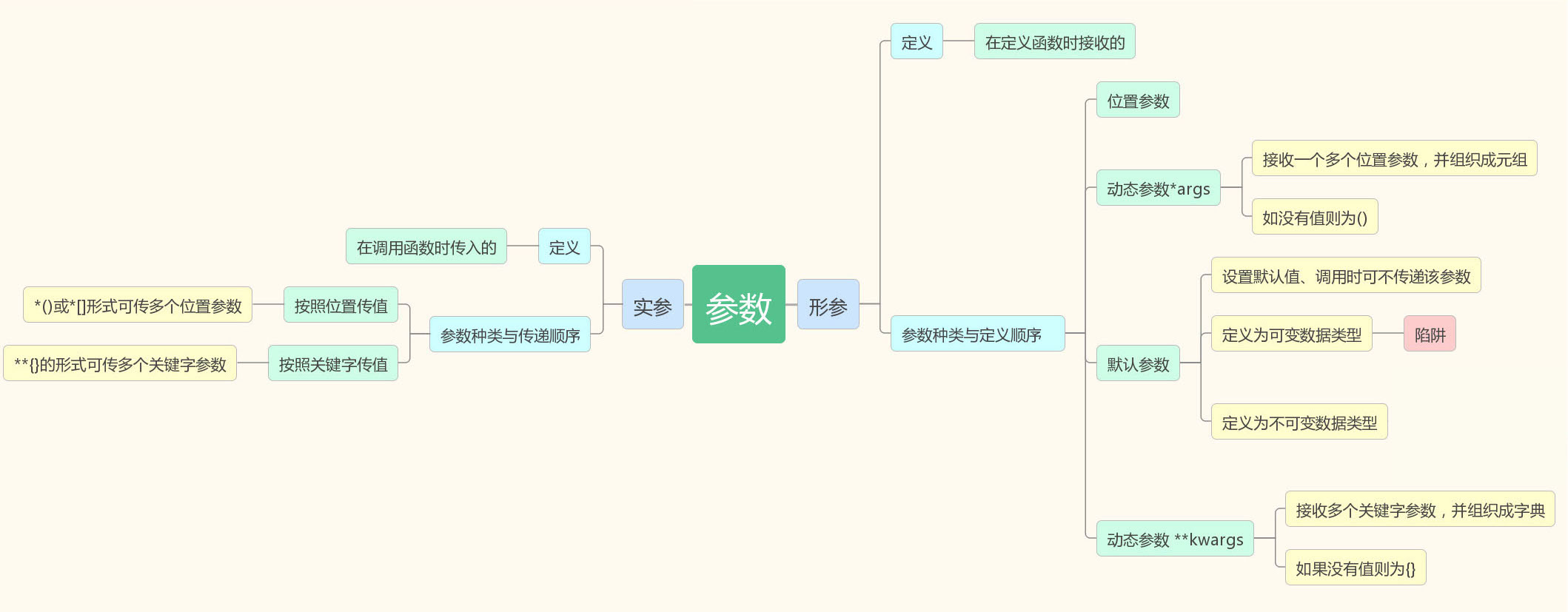
3.函数的参数
#定义函数 def mylen(): s1 = 'hello world' length = 0 for i in s1: length = length+1 return length #调用函数 str_len = mylen() print('str_len: %s'%str_len)
我们要告诉mylen函数要计算的字符串是谁,这个过程就叫做传递参数,简称传参。我们调用函数时传递的'hello world'和定义函数时的s1就是参数。
实参与形参
当我们调用函数传递的’hello world'被称作实际参数,因为这个是实际要交给函数的内容,简称实参
定义函数时的s1,只是一个变量的名字,被称作形式参数,因此在定义函数的时候它只是一个形式,表示这里有一个参数,简称形参。
位置参数
按位置传值,位置参数必须传值,位置参数必须在关键字参数的前面
def power(x): return x*x
def power(x,n):#x的n次方 s = 1 while n>0: n = n-1 s = s*x return s
默认参数
def power(x,n=2): #其中n=2是默认参数,x的平方 s = 1 while n>0: n = n-1 s = s*x return s
默认参数可以简化函数的调用:
1)、必选参数在前,默认参数在后,否则python的解释器会报错
2)、当函数有多个参数,把变化大的参数放前面,变化小的参数放后面,变化小的参数就可以作为默认参数
def enroll(name, gender, age=6, city='Beijing'): print('name:',name) print('gender:',gender) print('age:',age) print('city:',city) enroll('Bob','M',7) enroll('Bob','M',city='tianjing')
name: Bob gender: M age: 7 city: Beijing name: Bob gender: M age: 6 city: tianjing
def add_end(L=[]): L.append('END') return L add_end() add_end(L=[]) add_end(L=[1,2,3]) add_end([1,2,3,4])
['END'] ['END'] [1, 2, 3, 'END'] [1, 2, 3, 4, 'END']
多次循环add_end()END会逐次增加,原因在于:Python函数在定义的时候,默认参数L的值就被计算出来了,即[],因为默认参数L也是一个变量,它指向对象[],每次调
用该函数,如果改变了L的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了。更改如下,要用None这个不可变对象来实现。
def add_end(L=None): #这里的None也可以是任何其他的东西 if L is None: #这里的None所谓的常恒值 L = [] L.append('END') return L add_end(L=[]) def add_end(L=a): #比如,这里的None也可以是a if L is a: L = [] L.append('END') return L add_end() add_end([]) add_end([1,2,3])
可变参数
可变参数就是传入的参数的个数是可变的,可以是1,2,3,4...还可以是0个
def calc(numbers): #同理,numbers可以用其他的东西代替 sum = 0 for n in numbers: sum = sum + n * n #n方相加 return sum calc([1,2,3])#参数里面没有加*,那么只能是list或参数calc([1,2,3]),calc((1,2,3)) #14
def calc(*numbers): sum = 0 for n in numbers: sum = sum + n*n return sum calc(1,2,3)#加了参数,就可以直接是calc(1,2,3) #14
def calc(*numbers): sum = 0 for n in numbers: sum = sum + n*n return sum num = [1,2,3] calc(*num) #可以通过这样的方式直接将list的所有元素作为可变参数传进去 #14
可变参数都是加* 的,不加的话就要作为list或者tuple
关键字参数
可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple,而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内
部自动组装为一个dict
def person(name,age,**kw): print('name:',name,'age:',age,'other:',kw) person('Michael',30)#name,age为必选参数,kw为关键字参数,在调用该函数时,可以值传入必选参数 #结果:name: Michael age: 30 other: {}
也可以传入任意个数的关键字参数
def person(name,age,**kw): print('name:',name,'age:',age,'other:',kw) person('Bob',35,city='Beijing')#必须是A = 'B'的形式,可以是多个 person('Adam',45,gender='M',city='Tianjin')
name: Bob age: 35 other: {'city': 'Beijing'}
name: Adam age: 45 other: {'gender': 'M', 'city': 'Tianjin'}
用处:比如做一个用户注册的功能,除了用户和年龄是必填,其他选填,利用关键字参数来定义就可以满足
def person(name,age,**kw): print('name:',name,'age:',age,'other:',kw) #可以先组装出一个dict,然后把其转换成关键字参数传进去 extra = {'city':'Beijing','job':'Engineer'} person('Jack',24,city=extra['city'],job=extra['job']) #**必须是''=''的格式,之后变成了字典的形式
name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}
简化方法
person('Jack',24,**extra)
name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}
命名关键字参数
限制关键字参数的名字,就可以用命名关键字参数,例如,只接收city和job作为关键字段
def person(name,age,*,city,job): print(name,age,city,job) person('Jack',24,city='Beijing',job='Engineer') #Jack 24 Beijing Engineer #和上面的不一样,上面的是{}形式,这里只是字典的value值 person('Jack',24,city='Beijing',job='Engineer',sex='F') #SyntaxError: invalid character in identifier
如果函数定义中已经有了一个可变参数,后面跟着的就变成了命名关键字参数,此时就不再需要一个特殊分隔符*
def person(name,age,*args,city,job): print(name,age,args,city,job) person(12,23,24,'ddd','fff',city='Beijing',job='E')
12 23 (24, 'ddd', 'fff') Beijing E
由于命名关键字参数city具有默认值,调用时,可不传入city参数
def person(name,age,*,city='Beijing',job): print(name,age,city,job) person('Jack',24,job='Engineer')
Jack 24 Beijing Engineer
def f1(a,b,c=0,*args,**kw): print('a=',a,'b=',b,'c=',c,'args=',args,'kw=',kw) def f2(a,b,c=0,*,d,**kw): print('a=',a,'b=',b,'c=',c,'d=',d,'kw=',kw) f1(1,2) f1(1,2,c=3) f1(1,2,3,'a','b') f1(1,2,3,'a','b',x=99) f1(1,2,d=99,ext='None')
a= 1 b= 2 c= 0 args= () kw= {}
a= 1 b= 2 c= 3 args= () kw= {}
a= 1 b= 2 c= 3 args= ('a', 'b') kw= {}
a= 1 b= 2 c= 3 args= ('a', 'b') kw= {'x': 99}
a= 1 b= 2 c= 0 args= () kw= {'d': 99, 'ext': 'None'}
args = (1,2,3,4) kw = {'d':99,'x':'#'} def f1(a,b,c=0,*args,**kw): print('a=',a,'b=',b,'c=',c,'args=',args,'kw=',kw) f1(*args,**kw) args = (1,2,3) kw = {'d':88,'x':'#'} def f2(a,b,c=0,*,d,**kw): print('a=',a,'b=',b,'c=',c,'d=',d,'kw=',kw) f2(*args,**kw)
a= 1 b= 2 c= 3 args= (4,) kw= {'d': 99, 'x': '#'}
a= 1 b= 2 c= 3 d= 88 kw= {'x': '#'}
参数有很多种,如果涉及到多种参数的定义,应始终遵循未知参数,*args,默认参数,**kwargs顺序定义
4.递归函数
递归的定义:在一个函数里再调用这个函数本身
每一次函数调用都会产生一个属于自己的名称空间,如果一直调用下去,就会造成名称空间占用太多内存的问题,为了杜绝这种情况,强制的将递归层数控制在997
使用递归函数需要注意防止栈溢出,在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层帧,每当函数返回,栈就会减一
层栈帧,由于栈的大小不是无限的,所以,递归函数用的次数过多,会导致栈溢出。
def fact(n): if n==1: return 1 #如果return 1,整个函数就结束了 return n*fact(n-1) #因为引入了乘法表达式,所以不是尾递归
解决递归调用栈溢出的方法是通过尾递归优化,事实上尾递归和循环的效果是一样的,所以,把循环看作是一种特殊的尾递归也是可以的
尾递归是指,在函数返回的时候,调用自身本身,并且return语句不能包含表达式,这样,编译器或者解释器就可以把尾递归做优化,使递归本身无论调用多少次都只占用
一个栈帧,不会出现溢出情况
def fact(n): return fact_iter(n,1) def fact_iter(num,product): if num == 1: return product return fact_iter(num-1,num*product)#仅指递归函数本身,num-1和num*product在函数调用前就会被计算,不影响函数调用 #结果:阶乘
举例:alex比egon大两岁,egon比武sir大两岁,武sir比金鑫大两岁,金鑫40了
age(4) = age(3) + 2 age(3) = age(2) + 2 age(2) = age(1) + 2 age(1) = 40
def age(n): if n == 1: return 40 else: return age(n-1) + 2 print(age(4))
5.super()函数
super()函数是用于调用父类(超类) 的一个方法
super是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种
种问题
MRO就是类的方法解析顺序表,其实也就是继承父类方法时的顺序表
python3.x和python2.x的一个区别是:python3可以直接使用super().xxx代替super(Class,self).xxx
python3.x实例
class A: def add(self,x): y = x+1 print(y) class B(A): def add(self,x): super().add(x) b = B() b.add(3)
4
class A(object): def add(self,x): y = x+1 print(y) class B(A): def add(self,x): super(B,self).add(x) b = B() b.add(3)
4
实例
class FooParent(object): def __init__(self): self.parent = 'I am the parent' print('Parent') def bar(self,message): print('%s from parent'%message) class FooChild(FooParent): def __init__(self): super(FooChild,self).__init__()#super(FooChild,self)首先找到FooChild的父类(FooParent),然后把类FooChild的对象转换为类FooChild的对象 print('child') def bar(self,message): super(FooChild,self).bar(message) print('Child bar fuction') print(self.parent) if __name__ == '__main__': fooChild = FooChild() fooChild.bar('HelloWorld')
Parent child HelloWorld from parent Child bar fuction I am the parent
6.dir()函数
dir函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表,如果参数包含方法__dir__(),该方
法将被调用,如果参数不包含__dir__(),该方法将最大限度地收集参数信息
dir() # 获得当前模块的属性列表
['__builtins__', '__doc__', '__name__', '__package__', 'arr', 'myslice']
dir([ ]) # 查看列表的方法
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__delslice__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getslice__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__setslice__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号