

CUDA
44843849@qq.com &C*tYkiiJ7Bv_8E
CUDA在首次操作,如设置Device,copymemory时会耗时久,再次操作不会,所以应该把它封装成一对象。
程序遵循以下流程:
主机端准备数据 -> 数据复制到GPU内存中 -> GPU执行核函数 -> 数据由GPU取回到主机
当然,你得设计好Block数与维度,以及每个Block里头的Thread数与维度
float 4字节,1024字节等于1KB,1M约等于256000长度的float数组。
kernel<<<Dg,Db, Ns, S>>>(param list);
本机GPU传输速度约为10M/s
Dg: int型或者dim3类型(x,y,z)。 用于定义一个grid中的block是如何组织的。 int型则直接表示为1维组织结构。
Db: int型或者dim3类型(x,y,z)。 用于定义一个block中的thread是如何组织的。 int型则直接表示为1维组织结构。
Ns: size_t类型,可缺省,默认为0。 用于设置每个block除了静态分配的共享内存外,最多能动态分配的共享内存大小,单位为byte。 0表示不需要动态分配。
S: cudaStream_t类型,可缺省,默认为0。 表示该核函数位于哪个流。
线程结构
关于CUDA的线程结构,有着三个重要的概念: Grid, Block, Thread
GPU工作时的最小单位是 thread。
多个 thread 可以组成一个 block,但每一个 block 所能包含的 thread 数目是有限的。因为一个block的所有线程最好应当位于同一个处理器核心上,同时共享同一块内存。 于是一个 block中的所有thread可以快速进行同步的动作而不用担心数据通信壁垒。
执行相同程序的多个 block,可以组成 grid。 不同 block 中的 thread 无法存取同一块共享的内存,无法直接互通或进行同步。因此,不同 block 中的 thread 能合作的程度是比较低的。不过,利用这个模式,可以让程序不用担心显示芯片实际上能同时执行的 thread 数目限制。例如,一个具有很少量执行单元的显示芯片,可能会把各个 block 中的 thread 顺序执行,而非同时执行。不同的 grid 则可以执行不同的程序(即 kernel)。
chapter 1:
计算机性能提升历程
1.提升主频
2.提升核数
早期OpenGL和DirectX是与GPU交互的唯一方式
2006年CUDA问世,NVIDIA推出它是为了使GPU不仅能执行传统的图形计算,还能高效地执行通用计算。随后又推出了CUDA C语言以及相应编译器
与传统在CPU上运行的应用程序相比,在NVIDIA上运行的单位能耗低的多。
chapter 3 CUDA C简介:
将CPU以及系统的内存称为主机,而将GPU及其内存称为设备。在GPU设备上执行的函数通常称为 核函数。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
__global__ void kernel(void)
{
}
int main(void)
{
kernel<<<1,1>>>();
printf("hello world! \n ");
return 0;
}
#include <iostream>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
// 接口函数: 主机代码调用GPU设备实现矢量加法 c = a + b
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
// 核函数:每个线程负责一个分量的加法
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
c[0], c[1], c[2], c[3], c[4]);
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
// CUDA设备重置,以便其它性能检测和跟踪工具的运行,如Nsight and Visual Profiler to show complete traces.traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
system("pause");
return 0;
}
// Helper function for using CUDA to add vectors in parallel.
// 接口函数实现: 主机代码调用GPU设备实现矢量加法 c = a + b
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
//选择程序运行在哪块GPU上
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
// 依次为 c = a + b三个矢量在GPU上开辟内存 .
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
// 将矢量a和b依次copy进入GPU内存中
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
// 运行核函数,运行设置为1个block,每个block中size个线程
addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
// Check for any errors launching the kernel
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
// 停止CPU端线程的执行,直到GPU完成之前CUDA的任务,包括kernel函数、数据拷贝等
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
// 将计算结果从GPU复制到主机内存
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}
__global__修饰符。这个修饰符将告诉编译器,函数应该编译为在设备上而不是主机上运行。因此,在这个例子总,函数kernel()将被交给编译设备代码的
编译器,main()函数将被交给主机编译器。尖括号表示要将一些参数传递给运行时系统。这些参数并不是传递给设备代码的参数,而是告诉运行时如何启动设备代码。第一个参数表示设备在执行核函数时使用的并行线程块的数量。
例如,如果kernek<<<2,1>>>(),那么可以认为运行时将创建核函数的两个副本,并以并行方式来运行他们。当启动核函数时,我们将并行线程快的数量指定为2。这个并行线程块集合也称为一个线程格(Grid)。这是告诉运行时,我们想要一个一维的线程格,其中包含2个线程块。在启动线程块数组时,数组每一位的最大数量都不能超过65535
线程格->线程块->线程
kernel<<<128,128>>>();使用128个线程块,并且每个线程块包含128个线程,
关键点:
可以像调用C函数那样将参数传递给核函数
当设备执行任何有用的操作时,都需要分配内存。
设备指针利用cudaMalloc()分配内存创建。
程序员不能在主机代码中对设备指针解引用。
可以将设备指针传递给主机上执行的函数。
不能再主机代码中使用设备指针进行内存读/写操作
主机指针只能访问主机代码中的内存,而设备指针也只能访问设备代码中的内存。
设备指针的使用方式与标准C中指针的使用方式完全一样。
chapter4 CUDA C并行编程
chapter5 线程协作
CUDA运行是允许启动一个二维线程格(gridDim),并且线程格中的每个线程块(blockDim)都是一个三维的线程数组。
blockDim.x //每个线程块中的线程数量
gridDim.x//每个线程格中线程块的数量
cuda document
重要函数
global, __syncthreads,host,device
使用 global 限定符可将函数声明为内核。此类函数:在设备上执行,仅可通过主机调用
host,在主机上执行,仅可通过主机调用
device,在设备上执行,仅可通过设备调用。
属性:
threadIdx,blockIdx,blockDim,threadDim.
SIMT:单指令多线程
CPU和GPU之间浮点能力差异背后的原因是GPU专门用于计算密集型,高度并行计算 - 正是图形渲染的关键 - 因此设计使得更多晶体管用于数据处理而不是数据缓存和流控制,
CUDA核心是三个关键的抽象 - 线程组,共享存储器和屏障同步的层次结构 - 它们只是作为最小的语言扩展集向程序员公开
Streaming Multiprocessors (SMs)
GPU是围绕一系列流式多处理器(SM)构建的。多线程程序被划分为彼此独立执行的线程块,因此具有更多多处理器的GPU将在比具有更少多处理器的GPU更短的时间内自动执行程序。
2.Programming Model
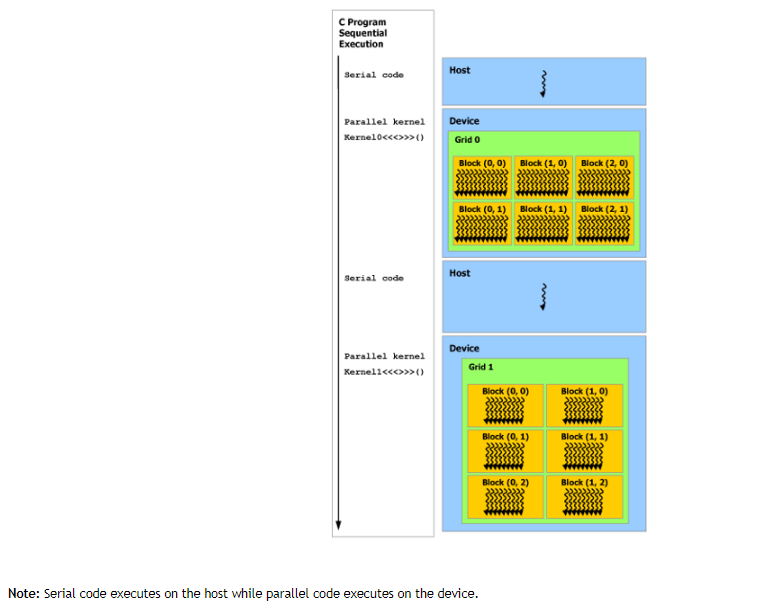
CUDA C通过允许程序员定义称为kernel的 C函数来扩展C,这些函数在被调用时由N个不同的CUDA线程并行执行N次,而不是像常规C函数那样只执行一次。
kernel是一C函数
kernel是由__global__声明
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads,1个Block,Nx1个线程
VecAdd<<<1, N>>>(A, B, C);
...
}
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads.一个block,block里头有NxN个线程
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);//线程块大小为16x16(256个线程),虽然在这种情况下是任意的,但却是常见的选择。
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
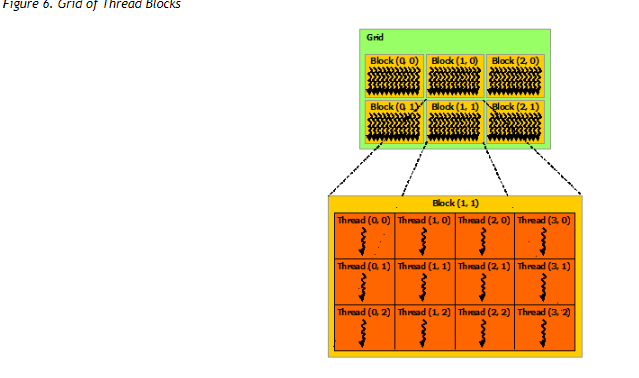
这是二维Grid,二维Block图
Grid->block->thread
多个线程块(至多三维)->线程块(至多三维)->线程
多个线程块称为Grid
一个线程块称为block
多个线程称为线程块
目前一个线程块所包含的线程数上限为1024.一个线程块可以是1,2,3维的(即线程的分布)
blockIdx 是Block在Grid的位置
threadIdx是thread在Block的位置
线程块之间需要是独立执行:必须能够以任何顺序,并行或串行执行它们。这种独立性要求允许线程块以任意顺序在任意数量的内核上进行调度,使程序员能够编写随内核数量扩展的代码。
同个Block内的线程可以通过共享内存从而共享数据来形成合作。 __syncthreads() 作为一个障碍,在任何允许继续进行之前,块中的所有线程必须等待
为了有效合作,共享内存应该是每个处理器内核附近的低延迟内存(很像L1缓存)和 __syncthreads() 预计将是轻量级的。
2.3 Memory Hierarchy
每个线程都有私有本地内存。每个线程块都具有对块的所有线程可见的共享内存,并且具有与块相同的生存期。所有线程都可以访问相同的全局内存。
所有线程都可以访问两个额外的只读内存空间:常量和纹理内存空间。全局,常量和纹理内存空间针对不同的内存使用进行了优化
2.4Heterogeneous Programming
Unified Memory提供managed memory以桥接主机和设备内存空间.可以从系统中的所有CPU和GPU访问managed memory
2.5.Compute Capability
设备的计算能力由版本号表示,有时也称为“SM版本”。此版本号标识GPU硬件支持的功能,并由运行时的应用程序用于确定当前GPU上可用的硬件功能和/或指令
计算能力包括主修订号X和次修订号Y,并由X,Y表示。
具有相同主要修订号的设备具有相同的核心体系结构。基于Volta架构的设备的主要版本号为7,基于Pascal架构的设备为6,基于 Maxwell架构的设备为5
3.Programming Interface
可以使用称为PTX的CUDA指令集架构来编写Kernel,然而,使用诸如C的高级编程语言通常更有效。在这两种情况下,必须通过NVCC将内核编译成二进制代码。 在设备上执行
应用程序在运行时加载的任何PTX代码都由设备驱动程序进一步编译为二进制代码。这称为 即时编译。
主机代码支持完整的C ++。但是设备代码仅支持C ++的一个子集。
设备存储器可以分配为线性存储器或CUDA阵列
CUDA数组是不透明的内存布局,针对纹理提取进行了优化。
通常使用cudaMalloc() 分配线性存储器 ,并使用 cudaFree()释放 ,主机存储器和设备存储器之间的数据传输通常使用 cudaMemcpy()
共享内存预计比全局内存快得多
GPU,CPU矩阵乘法运算
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "cublas_v2.h"
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <math.h>
#include <time.h>
#include <windows.h>
using namespace std;
#define BLOCK_SIZE 16
#define A_Row 10000
#define A_Col 2000
#define B_Col 5000
typedef struct {
int width;
int height;
float* elements;
} Matrix;
class stop_watch
{
public:
stop_watch()
: elapsed_(0)
{
QueryPerformanceFrequency(&freq_);
}
~stop_watch(){}
public:
void start()
{
QueryPerformanceCounter(&begin_time_);
}
void stop()
{
LARGE_INTEGER end_time;
QueryPerformanceCounter(&end_time);
elapsed_ += (end_time.QuadPart - begin_time_.QuadPart) * 1000000 / freq_.QuadPart;
}
void restart()
{
elapsed_ = 0;
start();
}
//微秒
double elapsed()
{
return static_cast<double>(elapsed_);
}
//毫秒
double elapsed_ms()
{
return elapsed_ / 1000.0;
}
//秒
double elapsed_second()
{
return elapsed_ / 1000000.0;
}
private:
LARGE_INTEGER freq_;
LARGE_INTEGER begin_time_;
long long elapsed_;
};
__global__ void MatMulKernel(const Matrix, const Matrix, Matrix);
void MatMul(const Matrix A, const Matrix B, Matrix C)
{
// Load A and B to device memory
Matrix d_A;
d_A.width = A.width; d_A.height = A.height;
size_t size = A.width * A.height * sizeof(float);
cudaMalloc(&d_A.elements, size);
cudaMemcpy(d_A.elements, A.elements, size,
cudaMemcpyHostToDevice);
Matrix d_B;
d_B.width = B.width; d_B.height = B.height;
size = B.width * B.height * sizeof(float);
cudaMalloc(&d_B.elements, size);
cudaMemcpy(d_B.elements, B.elements, size,
cudaMemcpyHostToDevice);
// Allocate C in device memory
Matrix d_C;
d_C.width = C.width; d_C.height = C.height;
size = C.width * C.height * sizeof(float);
cudaMalloc(&d_C.elements, size);
// Invoke kernel
stop_watch watch;
watch.start();
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C);
watch.stop();
cout<<"Time:"<<watch.elapsed_ms()<<endl;
// Read C from device memory
cudaMemcpy(C.elements, d_C.elements, size,
cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A.elements);
cudaFree(d_B.elements);
cudaFree(d_C.elements);
}
__global__ void MatMulKernel(Matrix A, Matrix B, Matrix C)
{
// Each thread computes one element of C
// by accumulating results into Cvalue
float Cvalue = 0;
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if(row<A_Row && col<B_Col)
{
for (int e = 0; e < A.width; ++e)
Cvalue += A.elements[row * A.width + e]
* B.elements[e * B.width + col];
C.elements[row * C.width + col] = Cvalue;
}
}
void Matrix_Cpu(const Matrix A,const Matrix B, Matrix C)
{
float fTemp=0;
for(int i = 0 ;i <C.height;i++)//row
for(int j=0;j<C.width;j++)//col
{
for(int k=0;k<A.width;k++)
{
fTemp+=A.elements[i*A.width+k]*B.elements[k+j*B.height];
}
C.elements[i*C.width+j]=fTemp;
fTemp=0;
}
C;
}
void ts_Matrix_Mul()
{
Matrix A,B,C;
A.height=A_Row;
A.width=A_Col;
A.elements = new float[A.height*A.width];
B.height=A_Col;
B.width=B_Col;
B.elements = new float[B.height*B.width];
C.height=A_Row;
C.width=B_Col;
C.elements = new float[C.height*C.width];
for(int i = 0;i<A.height*A.width;i++)
{
A.elements[i]=1;
}
for(int i = 0 ;i <B.height*B.width;i++)
{
B.elements[i]=2;
}
stop_watch watch;
//watch.start();
MatMul(A,B,C);
// watch.stop();
// cout<<"Time::"<<watch.elapsed_second()<<endl;
}
int main(void){
// 定义状态变量
ts_Matrix_Mul();
system("pause");
}
//更好的GPU方法是采用共享内存,具体看CUDA文档
用页面锁定主机(page-lock memory)内存有几个好处:
页面锁定主机内存和设备内存之间的副本可以与某些设备的内核执行同时执行,如异步并发执行中所述。
在某些设备上,页锁定主机内存可以映射到设备的地址空间,无需将其复制到设备内存或从设备内存复制,如映射内存中所述。
在具有前端总线的系统上,如果主机存储器被分配为页面锁定,则主机存储器和设备存储器之间的带宽更高,如果另外将其分配为写入组合存储器中描述的写入组合,则更高。
直接从内核访问主机内存有几个优点:
无需在设备存储器中分配块并在该块与主机存储器中的块之间复制数据; 内核根据需要隐式执行数据传输;
不需要使用流(参见并发数据传输)来与内核执行重叠数据传输; 内核发起的数据传输自动与内核执行重叠。
//映射内存
__global__ void MatMulKernel(const Matrix, const Matrix, Matrix);
void MatMul(const Matrix A, const Matrix B, Matrix C)
{
// Load A and B to device memory
Matrix d_A;
d_A.width = A.width; d_A.height = A.height;
size_t size = A.width * A.height * sizeof(float);
cudaMalloc(&d_A.elements, size);
cudaMemcpy(d_A.elements, A.elements, size,
cudaMemcpyHostToDevice);
stop_watch watch;
watch.start();
Matrix d_B;
d_B.width = B.width; d_B.height = B.height;
size = B.width * B.height * sizeof(float);
cudaMalloc(&d_B.elements, size);
cudaMemcpy(d_B.elements, B.elements, size,
cudaMemcpyHostToDevice);
watch.stop();
cout<<"Time::"<<watch.elapsed_ms()<<endl;
// Allocate C in device memory
Matrix d_C;
d_C.width = C.width; d_C.height = C.height;
size = C.width * C.height * sizeof(float);
cudaMalloc(&d_C.elements, size);
// Invoke kernel
//cudaHostGetDevicePointer((void **)&d_B.elements, (void *)B.elements, 0);
//cudaHostGetDevicePointer((void **)&d_A.elements, (void *)A.elements, 0);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C);
// Read C from device memory
cudaMemcpy(C.elements, d_C.elements, size,
cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A.elements);
cudaFree(d_B.elements);
cudaFree(d_C.elements);
}
开闭内存耗时,可否提前开闭空间?
对CUDA架构而言,主机端的内存被分为两种,一种是可分页内存(pageable memroy)和页锁定内存(page-lock或 pinned)。可分页内存是由操作系统API malloc()在主机上分配的,页锁定内存是由CUDA函数cudaHostAlloc()在主机内存上分配的,页锁定内存的重要属性是主机的操作系统将不会对这块内存进行分页和交换操作,确保该内存始终驻留在物理内存中。在GPU上分配的内存默认都是锁页内存。CPU上则是可分页内存,CPU仍然可以访问上述锁页内存。
GPU知道页锁定内存的物理地址,可以通过“直接内存访问(Direct Memory Access,DMA)”技术直接在主机和GPU之间复制数据,速率更快。由于每个页锁定内存都需要分配物理内存,并且这些内存不能交换到磁盘上,所以页锁定内存比使用标准malloc()分配的可分页内存更消耗内存空间。
在主机上分配锁页内存有以下两种方式:
a 使用特殊的cudaHostAlloc函数,对用的释放内存使用cudaFreeHost函数进行内存释放
b 使用常规的malloc函数,然后将其注册为(cudaHostRegister)锁页内存,注册为锁页内存只是设置一些内部标志位以确保内存不被换出,并告诉CUDA驱动程序,该内存为锁页内存,可以直接使用而不需要使用临时缓冲区
特点:
使用cudaHostAlloc函数分配内存,其内的内容需要从普通内存拷贝到锁页内存中,因此会存在:这种拷贝会带来额外的CPU内存拷贝时间开销,CPU需要把数据从可分页内存拷贝到锁页,但是采用cudaHostRegister把普通内存改为锁页内存,则不会带来额外的cpu内存拷贝时间开销,因为cudaHostAlloc的做法是先分配锁页内存,这时里面是没有数据的,那么需要将一般的内存拷贝过来,而对于cudaHostRegister内存,他是之前就使用malloc分配好的,cudaHostRegister只是设置一些内部标志位以确保其不被换出,相当于只是更改了一些标志位,就不存在前面说的数据拷贝
计算时间
float elapsedTime;
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
..real code
cudaEventRecord(stop, 0);
cudaEventSynchronize(start);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
使用函数cudaMallocManaged()开辟一块存储空间,无论是在Kernel函数中还是main函数中,都可以使用这块内存,达到了统一寻址的目的
//查询卡信息
int deviceCount;
cudaGetDeviceCount(&deviceCount);
int device;
for (device = 0; device < deviceCount; ++device) {
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, device);
printf("Device %d has compute capability %d.%d.\n",
device, deviceProp.major, deviceProp.minor);
}
CUDA不保证线程执行顺序,除非显式__syncthreads()
void * malloc(size_t size);
void free(void * ptr);
从全局内存中的固定大小的堆动态分配和释放内存。
直接从GPU创建工作的能力可以减少在主机和设备之间传输执行控制和数据的需要,
统一内存空间意味着不再需要在主机和设备之间进行显式内存传输。在托管内存空间中创建的任何分配都会自动迁移到需要的位置。
统一内存尝试通过将数据迁移到正在访问它的设备(即,如果CPU正在访问它,则将数据移动到主机内存,如果GPU将访问它,则将数据移动到设备内存)来优化内存性能
计算能力低于6.x的GPU架构不支持按需将托管数据细粒度移动到GPU。每当启动GPU内核时,所有托管内存通常都必须转移到GPU内存,以避免内存访问出错。
计算能力低于6.x的设备无法分配比GPU内存的物理大小更多的托管内存。
GPU计算:
评估->并行化->优化->部署
主机和设备之间的差异:
1.线程资源。
CPU只有十几个,顶多几十个线程。而现代GPU每个处理器可同时支持上百,甚至上千个线程,在多处理器的GPU上,线程数将破万
2.线程
CPU线程交互是缓慢且昂贵的。
CPU内核的设计目的 每次最小化一个或两个线程的延迟,而GPU设计用于处理大量并发轻量级线程,以便最大化吞吐量
3.内存
CPU与GPU有各自的内存空间
简单说,可以将主机和设备一起视为一个内聚的异构系统,其中每个处理单元都可以利用它做的最佳工作:主机上的顺序工作和设备上的并行工作。
为了获得最佳性能,设备上运行的相邻线程在内存访问方面应该保持一致。
要使用CUDA,必须沿PCI Express(PCIe)总线将数据值从主机传输到设备。这些转移在性能方面成本很高,应尽量减少。
操作的复杂性应证明将数据移入和移出设备的成本是合理的。传输数据以供少量线程短暂使用的代码将很少或没有性能优势。理想的情况是许多线程执行大量工作。数据应尽可能长时间保存在设备上。因为传输应该最小化,所以在相同数据上运行多个内核的程序应该支持在内核调用之间将数据保留在设备上,而不是将中间结果传输到主机,然后将它们发送回设备以进行后续计算。
带宽
带宽 - 数据传输的速率 - 是性能最重要的因素之一
为了准确地测量性能,计算理论和有效带宽很有用。当后者远低于前者时,设计或实现细节可能会减少带宽,并且应该是后续优化工作的主要目标,以增加带宽。
理论带宽计算
可以使用产品文献中提供的硬件规格计算理论带宽。例如NVIDIA Tesla M2090 uses GDDR5 (double data rate) RAM with a memory clock rate of 1.85 GHz and a 384-bit-wide memory interface.那么NVIDIA Tesla M2090的峰值理论内存带宽为177.6 GB / s:
(1.85*109*384/8*2)/109=177.6GB/s
有效带宽
((Br+Bw)/10^9)/time .这里Br是每个内核读取的字节数,Bw是每个内核写入的字节数,时间以秒为单位。
如2048x2048矩阵复制。有效带宽=(2048^2 x 2 x 4)/10^9 (4 bytes for a float)
内存优化是性能最重要的领域。目标是通过最大化带宽来最大化硬件的使用。使用尽可能多的快速内存和尽可能少的慢速访问内存可以最好地实现带宽。
设备内存和GPU之间的峰值理论带宽要比主机内存和设备内存之间的峰值理论带宽(PCIe x16 Gen2上的8 GB / s)高得多(例如,NVIDIA Tesla M2090为177.6 GB / s) 。因此,为了获得最佳的整体应用程序性能,最大限度地减少主机和设备之间的数据传输非常重要,即使这意味着在GPU上运行的内核与在主机CPU上运行它们相比没有表现出任何加速。使用页锁定(或固定)存储器时,主机和设备之间的带宽更高。由于与每次传输相关的开销,将许多小型传输批处理到一个较大的传输比单独进行每次传输要好得多,即使这样做需要将非连续的内存区域打包到连续的缓冲区中,然后在传输后解包。
设备内存分配和解除分配 cudaMalloc() 和 cudaFree() 这是昂贵的操作。所以设备内存应该重用
为了计算占用率,每个线程使用的寄存器数量是关键因素之
//由于两个kernel执行在两个不同的流,因此这两个核可以同时运行(设备支持的话)。达到提速的效果
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
kernel1<<<grid, block, 0, stream1>>>(data_1);
kernel2<<<grid, block, 0, stream2>>>(data_2);
每个块的线程数应该是32个线程的倍数,因为这样可以提供最佳的计算效率并促进合并。
grid中的block数应大于多处理器的数量,以便所有多处理器至少具有一个块来执行。
每个块的线程应该是warp大小的倍数,以避免在未充满变形的warp上浪费计算并促进合并。
应该使用每个块至少64个线程,并且仅当每个多处理器有多个并发块时。
每个块128到256个线程是更好的选择,并且具有不同块大小的实验的良好初始范围。
如果延迟影响性能,则使用多个(3到4个)较小的线程块而不是每个多处理器一个大线程块。这对经常调用 __syncthreads()的内核特别有用
尽肯能使用共享内存而不是全局内存。
性能优化围绕三个基本策略:
最大化并行执行
优化内存使用以实现最大内存带宽
优化指令使用以实现最大指令吞吐量
最大化并行执行的第一步是以尽可能多地暴露数据并行性的方式构造算法。一旦暴露了算法的并行性,就需要尽可能有效地映射到硬件。这是通过仔细选择每个内核启动的执行配置来完成的。应用程序还应通过流显式地在设备上公开并发执行,以及最大化主机和设备之间的并发执行,从而最大限度地提高更高级别的并行执行。
优化内存使用从最小化主机和设备之间的数据传输开始,因为这些传输的带宽比内部设备数据传输低得多。还应通过最大限度地使用设备上的共享内存来最小化对全局内存的内核访问。有时,最好的优化甚至可能是首先通过在需要时重新计算数据来避免任何数据传输
cublas
cublas是BLAS在CUDA上的实现。
CUDA 6.0开始,cuBLAS库公开了两组API:
CUBLAS API,和CUBLASXT API
要使用cuBLAS API,应用程序必须在GPU内存空间中分配所需的矩阵和向量,用数据填充它们,调用所需的cuBLAS函数序列,然后将结果从GPU内存空间上传回主机。cuBLAS API还提供辅助函数,用于从GPU写入和检索数据。
要使用CUBLASXT API,应用程序必须将数据保留在主机上,并且库将负责将操作分派给系统中存在的一个或多个GPU,具体取决于用户请求。
从版本4.0开始,除现有的旧版API外,cuBLAS库还提供了一个新的A
可以通过包含头文件“cublas_v2.h”来使用新的cuBLAS库API
可以通过包含头文件"cublas.h"来使用传统的cuBLAS API,
cublasHandle_t handle;
status = cublasCreate(&handle);//使用cublas必须先初始化
cublasDestroy(&handle);//释放cublas
不建议多个线程共享相同的CUBLAS handle
CUDA有自身的vector,并且可以用在host代码里头
支持多CPU多GPU混合编程(cuda openMP 例子)、
__syncthreads,等待同一个Block内的线程完成,不同Block之间无法同步
Nsight可以调试CUDA代码,查看变量值
cublas是列优先的
cuda并行性有两类,1:Kernel level.即一个kernel由多个线程执行。2.Grid level 多个kernel 在一个device上同时执行
cudaDeviceReset();释放CUDA资源。
CUDA本身大多数操作是异步的, cudaMemcpy是阻塞的
1个GPU有个SM(Streaming MultiProcess ).一个Kernel有可能在不同的SM上运行,但同一个Block的Thread必然在同一个SM中。
wrap是SM的基本执行单位
一个wrap包含32个并行thread
CUDA支持传统的,C-style显示控制流结构
cudaDeviceSynchronize可以用来阻塞CPU,直至CUDA中的操作完成
kernel可以调用kernel
shared Memory是在同一Block中的,获取shared Memory的数据前必须先用__syncthreads()同步
zero-copy memory是处于host的,但是GPU thread可以直接访问
cusparse是行优先的
异步函数和stream是grid level并行的基石
可以将数据传输和kernel执行放在不同的stream函数,以提高效率
cusparse支持1或0开头索引,支持dense,sparse类型。
cusparse慢,GPU不适合稀疏矩阵运算。
50005000的矩阵A.AA矩阵相乘得到,CPU时间约为5s,GPU为300ms

 浙公网安备 33010602011771号
浙公网安备 33010602011771号