【编译原理】代码在编译器中的完整处理过程
语言处理器
常见的语言处理器分为两种,一种是编译器,另一种是解释器。
编译器的本质是一个程序,他的作用就是将一种语言所编写的代码翻译成另一种语言,比如汇编,代码届的DeepL了属于是。当然,它也具有在翻译过程中找到源代码错误的功能。
而另一种语言处理器则是解释器,像我们常用的Python就是典型的解释型语言,它不需要预先将源代码进行编译形成汇编,他的编译是实时的,将源代码放入解释器,解释器逐行对源码进行翻译并运行。
一般来说,编译器编译出的程序运行速度更快,因为编译后的程序一般是CPU可以直接理解的,而解释器运行的时候需要先翻译,在运行,因此就会略慢。不过,解释器执行的过程中更直观,对开发者更为友好,就需要我们做出相应的取舍了。
除此之外,我们也会将两者结合起来,比如Java语言。我们首先使用javac编译器将Java源代码翻译成相对容易理解的字节码语言,在运行的时候通过JVM虚拟机这一解释器对字节码进行翻译运行,这样效率会比单独的解释器更高,同时也相对容易理解。
编译器
编译器:(相当于一次性翻译完,将译文直接记录下来留底,方便下次直接使用)
程序设计语言是向人以及计算机描述计算过程的记号。但是,在一个程序可以运行之前,它首先需要被翻译成一种能够被计算机执行的形式。完成这项翻译工作的软件系统成为编译器(Compiler)。
简单地说,一个编译器就是一个程序,它可以阅读以某一种语言(源语言)编写的程序,并把程序翻译成为一个等价的、用另一种语言(目标语言)编写的程序。
编译器的重要任务之一是报告它在翻译过程中发现的源程序中的错误。
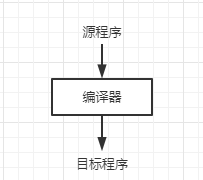
如果目标程序是一个可执行的机器语言程序,那么它就可以被用户调用,处理输入并产生输出。
解释器
解释器:(相当于同声传译,没有记录下来)
解释器(Interpreter)是另一种常见的语言处理器。它并不通过翻译的方式生成目标程序。从用户的角度看,解释器直接利用用户提供的输入执行源程序中指定的操作。
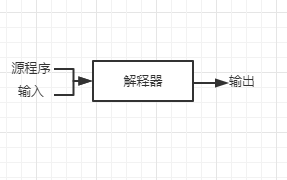
在把用户输入映射成为输出的过程中,由一个编译器产生的机器语言目标程序通常比一个解释器快很多。然而,解释器的错误诊断效果通常比编译器更好,因为它逐个语句地执行源程序。
Java语言处理器
Java语言处理器结合了编译和解释过程。
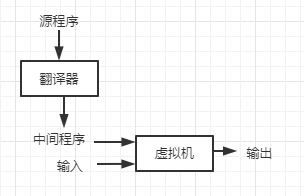
一个Java源程序首先被编译成一个成为字节码的中间表示形式。然后由一个虚拟机对得到的字节码加以解释运行。这样安排的好处之一是在一台机器上编译得到的字节码可以在另一台机器上解释执行。通过网络就可以完成机器之间的迁移。
为了更快的完成输入到输出的处理,有些被称为即时编译器的Java编译器在运行中间程序处理输入的前一刻把字节码翻译成为机器语言,然后再执行程序。
语言处理过程
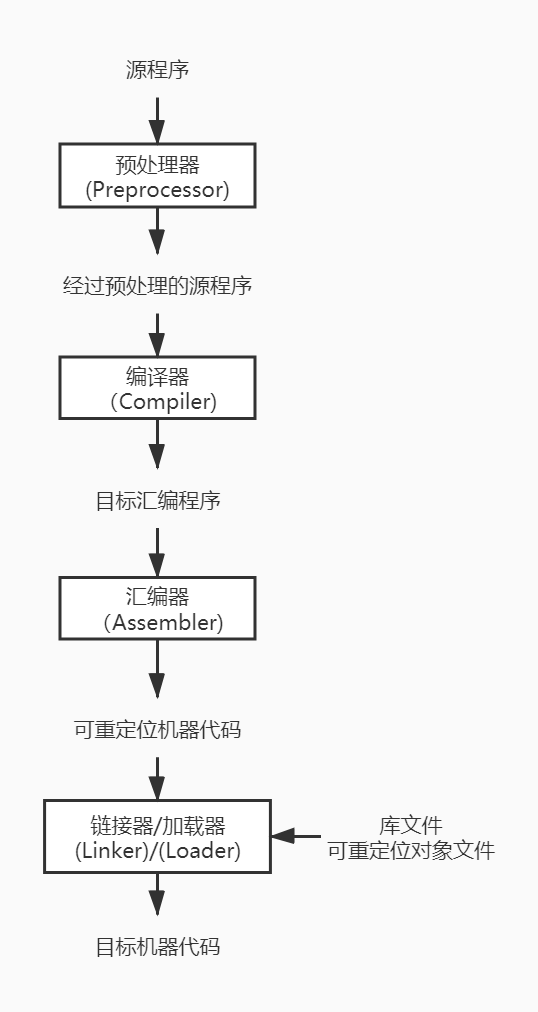
如上图所示,除了编译器之外,创建一个可执行的目标程序还需要一些其他程序。
- 一个源程序可能被分割成为多个模块,并存放于独立的文件中,把源文件聚合在一起的任务有时会由一个被称为预处理器(Preprocessor)的程序独立完成。预处理器还负责把那些称为宏的缩写形式转换为源语言的语句、删除注释等。
- 然后,将经过预处理的源程序作为输入传递给一个编译器(Compiler)。编译器可能产生一个汇编语言程序作为其输出,因为汇编语言比较容易输出和调试。
- 接着,这个汇编语言程序由称为汇编器(Assembler)的程序进行处理,并生成可重定位的机器代码。
- 大型程序经常被分成多个部分进行编译,因此,可重定位的机器代码有必要和其他可重定位的目标文件以及库文件连接到一起,形成真正在机器上运行的代码。一个文件的代码可能指向另一个文件中的位置,而链接器(Linker)能够解决外部内存地址的问题。
- 最后加载器(Loader)把所有的可执行目标文件放到内存中执行。
语言处理实例
由上面我们可以了解到语言处理的整个过程,那么放到实际的例子当中是怎么处理的呢?
下面我们以C语言打印Hello,World!为例子。
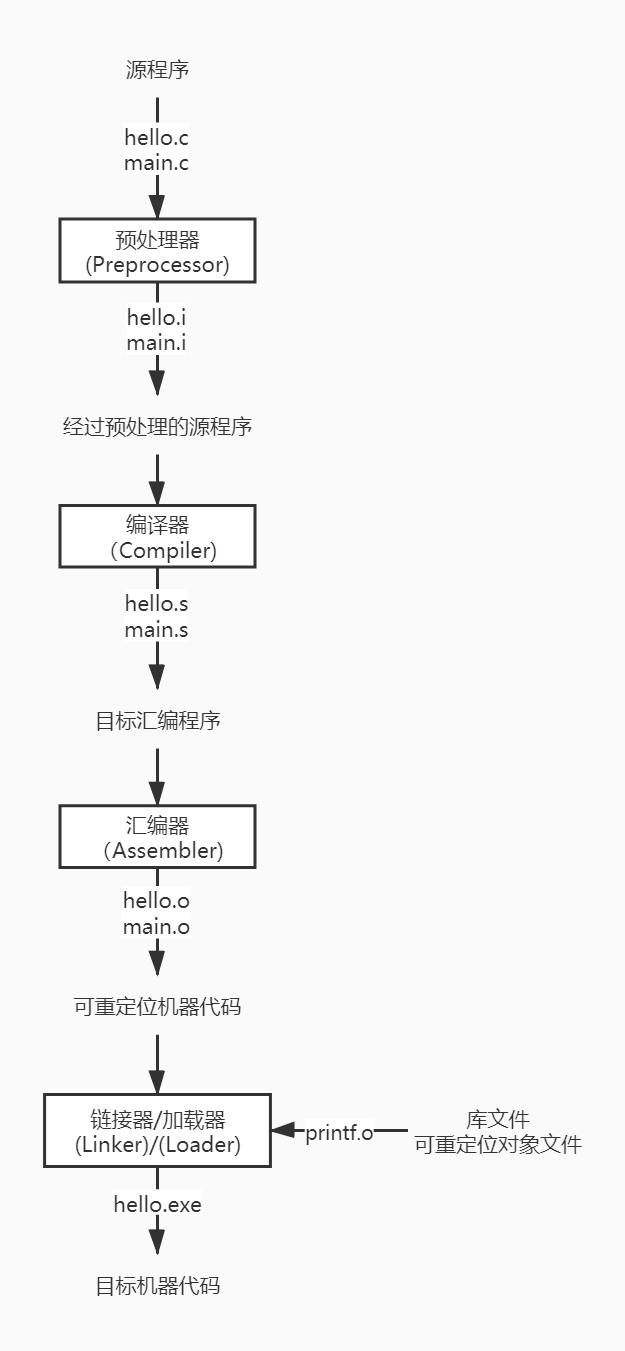
预处理→编译→汇编→链接
- 预处理阶段(.c→.i):编译器将C程序的头文件编译进来,还有宏的替换、删除注释等。
科普:头文件作为一种包含功能函数、数据接口声明的载体文件,主要用于保存程序的声明,而定义文件用于保存程序的实现。
- 编译(.i→.s):转换为汇编语言文件:这个阶段编译器主要做词法分析、语法分析、语义分析等,在检查无错误后,把代码翻译成汇编语言。
- 汇编阶段(.s→.o)得到机器语言:汇编器将hello.s翻译成机器语言保存在hello.o中(二进制文本形式)。
- 链接阶段(.s→.exe):printf函数存在于一个名为printf.o的单独预编译目标文件中。必须得将其并入到hello.o的程序中,链接器就是负责处理这两个的并入,结果得到hello.exe文件,他就是一个可执行的目标文件。
操作系统控制硬件的功能,都是通过一些小的函数集合体的形式来提供的。这些函数以及调用函数的行为称为系统调用,也就是通过应用进而调用操作系统的意思。在前面的程序中用到了 time() 以及 printf() 函数,这些函数内部也封装了系统调用。
C 语言等高级编程语言并不依存于特定的操作系统,这是因为人们希望不管是Windows 操作系统还是 Linux 操作系统都能够使用相同的源代码。因此,高级编程语言的机制就是,使用独自的函数名,然后在编译的时候将其转换为系统调用的方式(也有可能是多个系统调用的组合)。也就是说,高级语言编写的应用在编译后,就转换成了利用系统调用的本地代码。
编译器编译的过程
我们把编译器看作一个黑盒子,它能够把源程序映射为在语义上等价的目标程序。如果把黑盒子稍微打开一点,我们就会看到这个映射过程由两个部分组成:前端部分和后端部分。
-
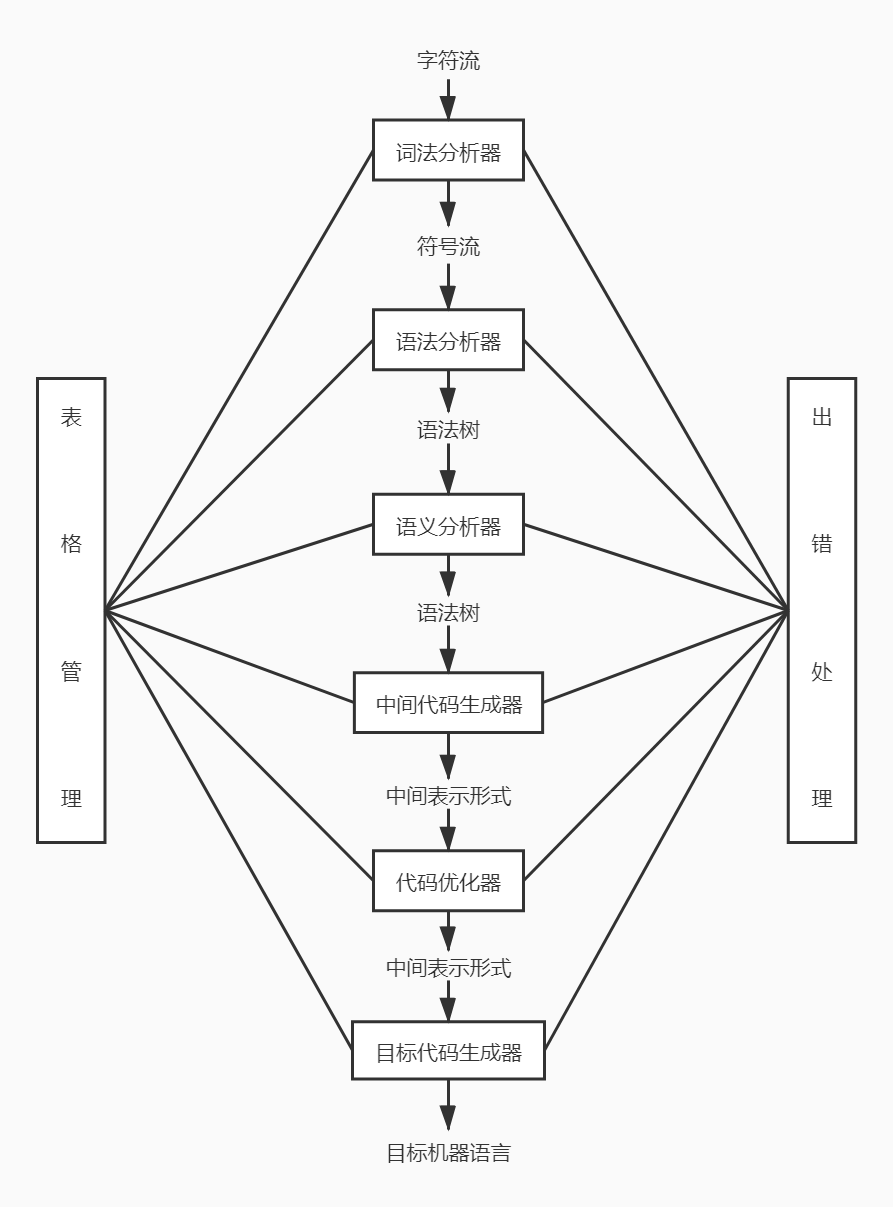
分析(analysis)部分:通常被称为编译器的前端(front end),它把源程序分解成为多个组成要素,并在这些要素之上加上语法结构。然后,它使用这个结构来创建该源程序的一个中间表示。如果分析部分检查出源程序没有按照正确的语法构成,或者语义上不一致,它就必须提供有用的信息,使得用户可以按此进行改正。分析部分还会收集有关源程序的信息,并把信息存放在一个成为符号表(symbol table)的数据结构中。符号表将和中间表示形式一起传送给综合部分。
-
综合(synthesis)部分:通常被称为编译器的后端(back end),它根据中间表示和符号表中的信息来构造用户期待的目标程序。
- 词法分析器:(也称为扫描器)词法分析是编译过程的基础,任务是扫描源程序,根据语言的词法规则分解和识别出每个单词,并把单词翻译成相应的机内表示。在识别单词的过程中同时也做词法检查。
- 语法分析器:(有时简称为分析器)语法分析是在词法分析的基础上进行的。任务是根据语言的语法规则把单词符号流分解成格内语法单位,如 表达式、语句等。通过语法分析确定整个输入符号流是否构成一个语法正确的程序。
- 语义分析器:****任务是对源程序进行语义检查,其目的是保证标识符和常数的正常使用,把必要的信息收集保存到符号表或中间代码程序中,并进行相应的处理。
- 中间代码生成器:必不可少的阶段,任务是在语法分析和语义分析基础上把语法成分的语义对其继续翻译,翻译的结果是某种中间代码形式,这种中间代码的结果简单,接近计算机的指令形式,能够很容易被翻泽成计算机指令,常用的中间代码有三元式、四元式和逆波兰式。
- 代码优化器:对程序代码进行等价(即 不改变程字的运行中间表示形式结果)变换。程序代码可以是中间代码(如 四元式代码),也可以是目标代码。等价的含义是使得交换后的代码运行结果与变换前代码运行结果相同,优化的含义是使最终生成的目标代码短(运行时间更知、占用空间更小),时空效率优化。原则上,优化可以在编译的各个阶段进行,但最主要的一类是对中间代码进行优化,这类优化不依赖于具体的计算机。
- 目标代码生成器:将中间代码或优化之后的中间代码转换为等价的目标代码,即 机器指令或汇编语言。由中间代码很容易生成目标程序(地址指令序列),这部分工作与机器关系密切,所以要根据机器进行。在做这部分工作时(要注意充分利用累加器),也可以进行优化处理。
- 表格管理:编译过程中源程序的各种信息被保留在种种不同的表格,编译各阶段的工作都涉及到构造、查找、或更新有关的表格。编译程序的公共辅助部分,对源程序中的各种量进行管理,登记在相应的表格。编译程序处理时通过查表得到所需的信息。
还记得Debug调试的时候观察变量值的变化的那个表格吗?
- 出错处理:如果编译过程中发现源程序有错误,编译程序应报告错误的性质和错误的发生的地点,并且将错误所造成的影响限制在尽可能小的范围内,使得源程序的其余部分能继续被编译下去,有些编译程序还能自动纠正错误,这些工作由错误处理程序完成。需要注意的是,一般编译器只做语法检查和最简单的语义检查,而不检查程序的逻辑。
特别注意:词法分析、语法分析:是流式的。lexer 按需喂 token,parser 边读边建语法树;token 不全部缓存。
不是等词法分析结束了,才开始语法分析。
词法分析器
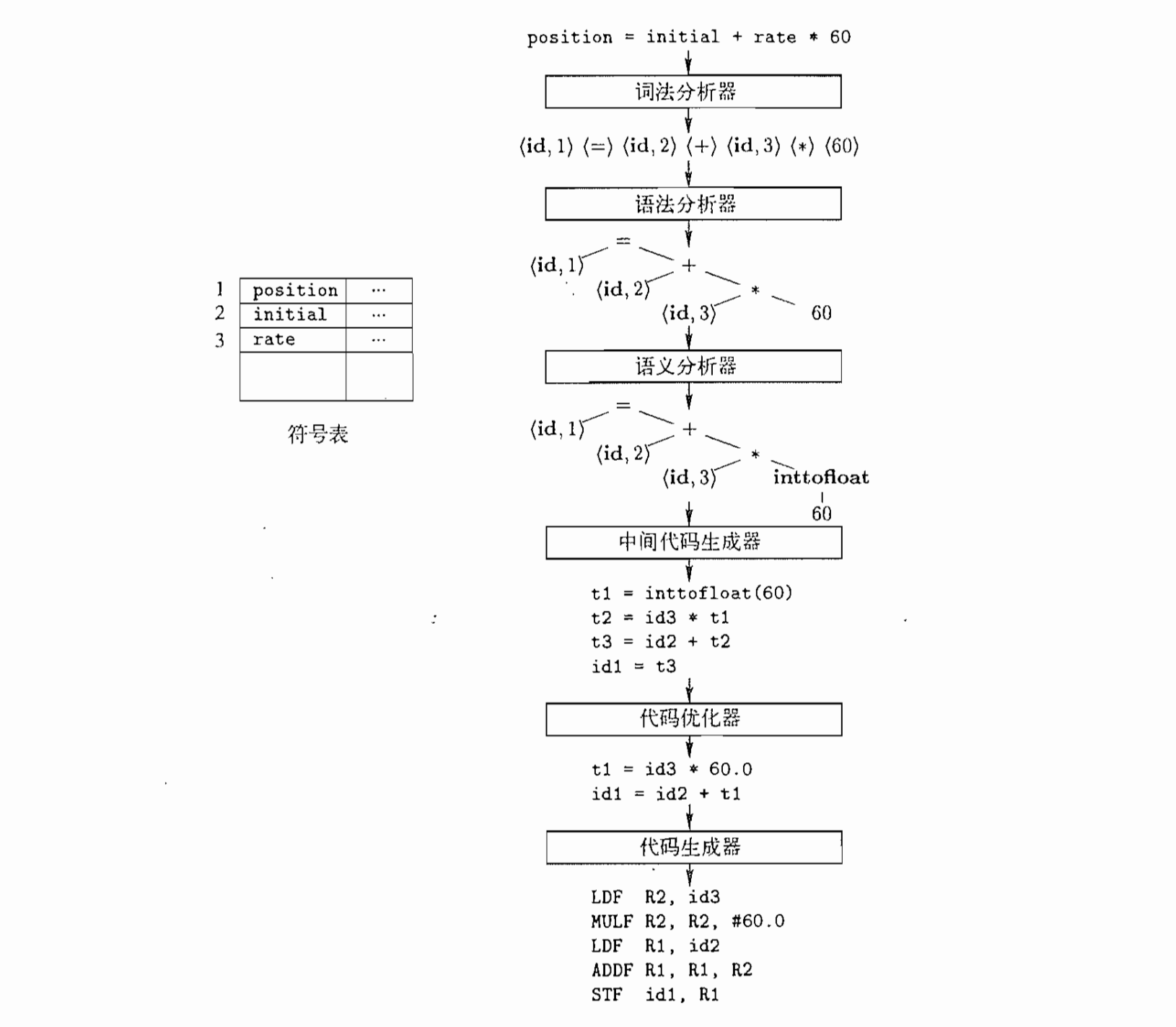
词法分析是编译器执行的第一步,又被称作扫描,它将源代码作为字符流读入,形成词素序列,并将词素通过词法分析器产生语法单元,其结构为<token,value>。其中,token是后续语法分析中所使用的抽象符号(可以理解为一个由词法分析器生成的ID),value为词法单元条目数,可以理解为符号表中的映射关系。我在以前讲C语言的时候就提到过,无论是符号,变量名,保留字,其在编译是都叫做词素。
比如以下C代码,
a=10+b;
利用词法单元进行表示就是<id,1><=><10><+><id,2>,同时,在符号表中,第一行内保存a,第二行内保存b,其用于保存对词素与语法单元的映射。
同时,由于等号不需要属性值,因此不需要将该词素保存到符号表中,而10则涉及到了数字词法单元的表示,此部分在第二三章中,因此这里不展开。
词法分析器的任务是将程序的字符流转换到记号流。
字符流:被编译的语言例如C、JAVA、ASCII、Inicode.
记号流:编译器内部定义的数据结构,编码所识别出的词法单元。
例如读入一个程序语句:
if (x>0)
y="NEMO"; //词法分析器设置成自动忽略空格,以下空格用\x20表示
词法分析器依次读入:i、f、\x20. (、x、)、0、)、\n、y、=、"NEMO"、;。
进行分析后得到:
IF LPARE IDENT(x) GT INT (0) RPAREN
IDENT(y) ASSIGN STRING ( "NEMO" ) SEMICOLON EOF
我们对这些“词语记号“进行数据结构定义:
enum type {IF. LPAREN. ID. INLIT,...}
struct token {
enum type k;
char *lexeme; //单词
}; //例如if (x>0), 我们就可以编程为: token{k= IF, lexeme =0};
token{k= LPAREN. lexeme=0}; token{k = ID, lexeme= “x”};
目前至少有两种实现方案:
- 手工编码实现法(相对复杂,且容易出错目前非常流行的GCC、LLVM 等);
- 词法分析器的生成器(自动的,可以快速原型、代码量较少,但是控制细节难)
语法分析器
我们通过词法分析将代码转换为了词法单元与符号表,接下来我们需要对其进行解析,一般最常见的,解析过程将第一步的词法单元转换为一颗语法树,树的每一个节点表示一种运算,子节点则为运算的分量。
因此,上面的赋值语句可以转换为以下树:
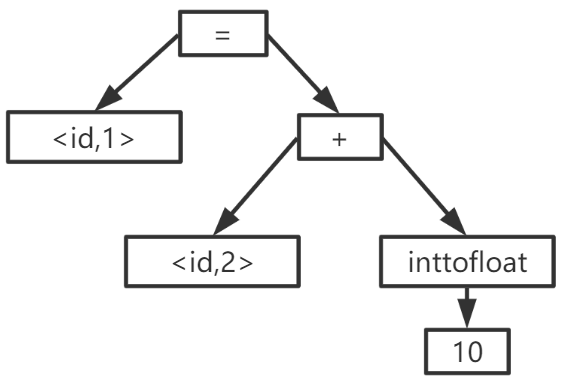
语法分析器的主要任务是对词法分析的输出结果记号流单词序列进行分析,识别合法的语法单元并将其转换输出为下一阶段可以识别的语法树。
实现方法:
- 手工方式:递归下降分析器
- 使用语法分析器的自动生成著: LL(1)、 LR(1)
两种方式在实际的编译器中都有广泛的应用,其中自动的方式更适合快速对系统进行原型开发,手工的方式更适台对系统进行调优。
语义分析器
在构建好语法树后,利用语义分析器对其与符号表中的信息检查经过解析后的语义是否与源代码一致。同时,还会对变量常量等类型进行收集,并将其存放到树或符号表中。
其中,类型检查是语法分析中一个重要的步骤,编译器会对每个运算符的分量进行检查,检查其运算分量是否合法、符合运算类型,如果不符合类型要求,比如在C语言中使用非整型变(常)量作为数组角标,如a['a'],语义分析器则会抛出相关错误。
同时,根据语言的不同,语言可能支持自动类型转换,语义分析器也负责将类型进行转换。比如浮点数与整数之间进行的运算,则会将双方转换为浮点数。
语法树(分析树)是句子结构的图形表示,它代表了句子的推导结果,有利于理解句子语法结构的层次。简单来说,语法树就是按照某一规则进行推导时所形成的树。和推导所用的顺序无关(最左、最右、其他)
特点:
- 树中每个内部节点代表非终结符
- 每个叶子节点代表终结符
- 每一步推导代表如何从双亲结点生成它的直接孩子节点
二义性:若对于一个文法的某一句子存在两颗不同的语法树,则该文法是二义性文法;否则是无二义性文法。(包含二义性的句子)
从编译器角度,二义性文法存在的问题:
同一个程序会有不同的含义,因此程序运行的结果不是唯一的。
解决方法:文法的重写
中间代码生成
中间表示是一个源代码被翻译为另一个源代码的过程中,采用的一种中间状态代码形式。上面提到的语法树就是一种中间表示形式。
除了语法树外,很多编译器会生成一个明确的低级或类机器语言的中间表示,它不是我们最终要生成的代码翻译,但是可以理解为一个抽象的机器语言。
它应该具有易于生成,容易翻译成目标语言的特性。
这是个非常经典的问题。简单来说,编译器生成中间代码是为了“分工明确”和“复用”,而不是一步到位直接生成目标代码。下面我来详细解释一下:
IR(Intermediate Representation,中间表示)是编译器在源代码与目标机器码之间插入的一层“中间语言”。它的作用可以类比“翻译草稿”——先把源程序转成一种既保留足够语义信息、又便于优化和代码生成的格式,然后再从 IR 生成最终的汇编或机器码。
✅ 为什么需要中间代码?(不是“多此一举”,而是“必要之举”)
个人理解:其实很简单,我们的自定义代码需要找到一个所有机器都能理解的语言代码,才能够让所有机器都理解,实现跨平台,而这个能够让所有机器都理解的语言代码,其实就是中间代码。
注意:汇编语言是跟具体的机器相关的,并且汇编语言的抽象能力不够,很难作为中间代码来统一使用。
类比:Vue和React会在经过webpack编译打包后,变成HTML、CSS和JS,它们三个是能够被任何浏览器理解的。
- 前端和后端解耦:一次编译,多端输出
- 前端:负责理解源代码(比如 C、Python),生成中间代码(IR)。
- 后端:负责把中间代码转换成具体平台的机器码(x86、ARM、RISC-V 等)。
举个例子:LLVM 的 IR 让 Clang 可以同时支持生成 Windows、Linux、macOS 甚至嵌入式设备的代码,只需写一次前端,多个后端复用。
- 优化更容易在中间代码层面做
- 中间代码通常是平台无关的,优化器可以专注于算法层面的优化(比如常量折叠、死代码消除),不用关心底层寄存器或指令集细节。
- 如果直接生成机器码,优化器就得处理各种平台的“烂摊子”(比如 x86 的寄存器太少、ARM 的指令格式不同),复杂度高得爆炸。
- 调试和错误定位更方便
- 中间代码(如 LLVM IR)是人类可读的,可以打印出来检查哪里出问题。
- 如果直接跳转到机器码,调试器可能只能看到一堆十六进制指令,排查问题像大海捞针。
- 支持多语言复用
- 比如 LLVM 的中间代码被 Clang(C/C++)、Swift、Rust 共用,不同语言只需实现自己的前端,后端优化和代码生成直接复用。
❌ 那为什么不能“一步到位”?
理论上可以,但代价极高:
- 每增加一个语言(如 Python、Rust),就要重新实现整个编译器(包括目标平台的优化和代码生成)。
- 每增加一个目标平台(如 x86、ARM),所有语言的前端都要重写后端。
- 优化难度翻倍:机器码优化要考虑寄存器分配、指令调度、硬件特性,直接写等于让前端开发者同时是硬件专家。
🚗 举个现实例子
- GCC:早期直接生成机器码,后来也引入中间代码(GIMPLE/RTL),否则支持新架构会崩溃。
- LLVM:设计之初就强制用 IR,现在成了模块化编译器的标杆。
总结一句话
中间代码是编译器的“通用协议”,让前端专注理解语言,后端专注生成高效机器码,优化器在中间“自由发挥”。直接一步到位?现实会让开发者崩溃的。
代码优化生成
中间代码中可能拥有一些与机器指令无关的修饰代码,为了最终生成的目标语言代码能达到最快最优,代码优化器会首先对中间代码进行优化,删掉无实际含义的代码,转义一些可以在编译流程中简化的步骤,比如上面的将整型10转换的inttofloat,可以在这一步直接替换为10.0。
在完成优化后,将最简中间代码作为源程序,一一映射入目标语言,形成翻译后的代码。如果目标语言是机器码,在代码生成的时候还必须为每个变量指定寄存器或内存位置,因此,一个好的编译器应该合理地对内存进行分配。
符号表管理与步骤组合
除了以上过程之外,编译器还应记录源程序使用的变量名,并收集其相关的各种属性,包括类型,作用域,存储分配等,此外,还应包括参数类型、数量,传值与返回值等信息。这些信息都应存储在符号表中。
而对于编译流程,以上流程是一个完整编译器的逻辑组织方式,但是,特定情况下可以将多个步骤整合起来,形成为趟,这样,我们就可以针对特定情境编写编译器,并针对该组合进行特定优化。
笔者将不定期更新【考研或就业】的专业相关知识以及自身理解,希望大家能【关注】我。
如果觉得对您有用,请点击左下角的【点赞】按钮,给我一些鼓励,谢谢!
如果有更好的理解或建议,请在【评论】中写出,我会及时修改,谢谢啦!
本文来自博客园,作者:Nemo&
转载请注明原文链接:https://www.cnblogs.com/blknemo/p/12596098.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号