作业①
(1)、要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
编写爬虫程序
import scrapy
from ..items import BookItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider"
key = 'SpringBoot'
source_url='http://search.dangdang.com/'
def start_requests(self):
url = MySpider.source_url+"?key="+MySpider.key
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price =li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date =li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
# detail有时没有,结果None
item = BookItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
# 最后一页时link为None
link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next'] / a / @ href").extract_first()
if link:
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
编写数据项目类items.py
import scrapy
class BookItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()
编写数据管道处理类pipelines.py
import pymysql
class BookPipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
passwd = "root", db = "mydb", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "本书籍")
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
if self.opened:
self.cursor.execute("insert into books (bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values(%s,%s,%s,%s,%s,%s)",
(item["title"],item["author"],item["publisher"],
item["date"],item["price"],item["detail"]))
self.count += 1
except Exception as err:
print(err)
配置settings.py
ITEM_PIPELINES = {
'stocks.pipelines.StocksPipeline': 300,
}
输出信息

(2)、心得体会:熟悉了数据库的使用
作业②
(1)、要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
爬取的代码
编写爬虫程序
import scrapy
from ..items import StocksItem
from selenium import webdriver
class StocksdemoSpider(scrapy.Spider):
name = 'mySpider'
start_urls=['http://quote.eastmoney.com/center/gridlist.html']
def parse(self, response):
browser = webdriver.Chrome(r'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
browser.get("http://quote.eastmoney.com/center/gridlist.html")
browser.implicitly_wait(10)
trs = browser.find_elements_by_xpath("//table[@class='table_wrapper-table']/tbody/tr")
for tr in trs:
item = StocksItem()
item["number"] = tr.find_elements_by_xpath("./td")[0].text
item["daima"] = tr.find_elements_by_xpath("./td")[1].text
item["name"] = tr.find_elements_by_xpath("./td")[2].text
item["new"] = tr.find_elements_by_xpath("./td")[4].text
item["zangfu"] = tr.find_elements_by_xpath("./td")[5].text
item["e"] = tr.find_elements_by_xpath("./td")[6].text
item["chengjiao"] = tr.find_elements_by_xpath("./td")[7].text
item["jiaoe"] = tr.find_elements_by_xpath("./td")[8].text
item["zhenfu"] = tr.find_elements_by_xpath("./td")[9].text
item["max"] = tr.find_elements_by_xpath("./td")[10].text
item["min"] = tr.find_elements_by_xpath("./td")[11].text
item["today"] = tr.find_elements_by_xpath("./td")[12].text
item["ye"] = tr.find_elements_by_xpath("./td")[13].text
yield item
browser.close()
编写数据项目类items.py
import scrapy
class StocksItem(scrapy.Item):
# define the fields for your item here like:
number = scrapy.Field()
daima = scrapy.Field()
name = scrapy.Field()
new = scrapy.Field()
zangfu = scrapy.Field()
e = scrapy.Field()
chengjiao = scrapy.Field()
jiaoe = scrapy.Field()
zhenfu = scrapy.Field()
max = scrapy.Field()
min = scrapy.Field()
today = scrapy.Field()
ye = scrapy.Field()
编写数据管道处理类pipelines.py
import pymysql
class StocksPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
passwd="root", db="mydb", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "个股票")
def process_item(self, item, spider):
try:
print(item["number"])
print(item["daima"])
print(item["name"])
print(item["new"])
print(item["zangfu"])
print(item["e"])
print(item["chengjiao"])
print(item["jiaoe"])
print(item["zhenfu"])
print(item["max"])
print(item["min"])
print(item["today"])
print(item["ye"])
print()
self.count += 1
self.cursor.execute(
"insert into stocks (序号,代码,名称,最新价格,涨跌额,涨跌幅,成交量,成交额,振幅,最高,最低,今开,昨收) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",(item["number"],item["daima"], item["name"], item["new"], item["zangfu"], item["e"],item["chengjiao"], item["jiaoe"], item["zhenfu"], item["max"], item["min"], item["today"], item["ye"]))
print("__________________________________________________________________________________")
except Exception as err:
print(err)
return item
配置settings.py
ITEM_PIPELINES = {
'stocks.pipelines.StocksPipeline': 300,
}
输出信息
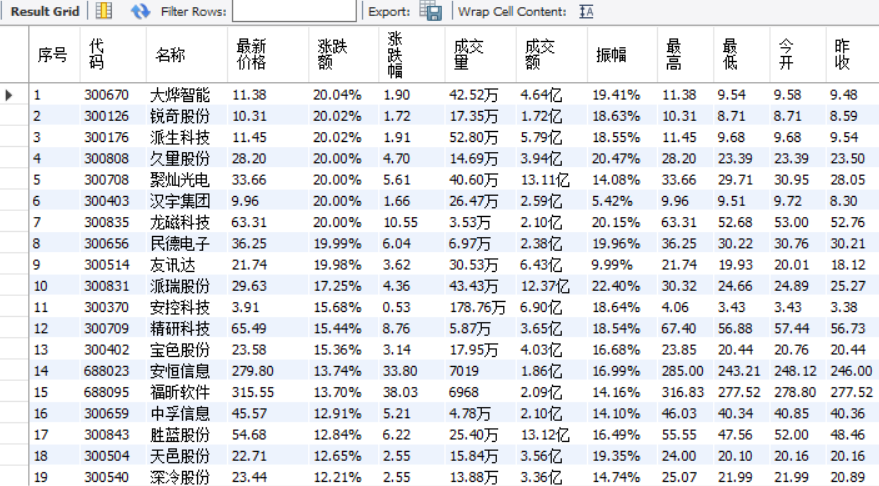
(2)、心得体会:
运用selenium框架爬取动态网页,出现了selenium.common.exceptions.WebDriverException: Message: unknown error: Failed to create a Chrome process.的错误,去网上搜了一下,大体都是chromedriver版本不对应,配置错误等等,但是改完后还是不正确。最后找到了原因,因为chorme浏览器的安装是不允许更改位置的找到selenium的源码,进入selenium/webdriver/chrome/options.py 进行编辑,找到options.py 里边的self._binary_location = '' ,我们这时就需要将我们安装Chrome.exe文件的路径填在这里。
作业③
(1)、要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
编写爬虫程序
import scrapy
from ..items import HuilvItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider"
start_urls=['http://fx.cmbchina.com/hq/']
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
tds = selector.xpath("//table[@class='data']//tr")
for td in tds[1:]:
Currency = td.xpath("./td[position()=1]/text()").extract_first()
TSP =td.xpath("./td[position()=4]/text()").extract_first()
CSP = td.xpath("./td[position()=5]/text()").extract_first()
TBP =td.xpath("./td[position()=6]/text()").extract_first()
CBP = td.xpath("./td[position()=7]/text()").extract_first()
Time = td.xpath("./td[position()=8]/text()").extract_first()
item = HuilvItem()
item["Currency"] = Currency.strip() if Currency else ""
item["TSP"] = TSP.strip() if TSP else ""
item["CSP"] = CSP.strip() if CSP else ""
item["TBP"] = TBP.strip() if TBP else ""
item["CBP"] = CBP.strip() if CBP else ""
item["Time"] = Time.strip() if Time else ""
yield item
except Exception as err:
print(err)
编写数据项目类items.py
import scrapy
class HuilvItem(scrapy.Item):
# define the fields for your item here like:
number=scrapy.Field()
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
Time = scrapy.Field()
编写数据管道处理类pipelines.py
import pymysql
class StocksPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
passwd="root", db="mydb", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "个股票")
def process_item(self, item, spider):
try:
print(item["number"])
print(item["daima"])
print(item["name"])
print(item["new"])
print(item["zangfu"])
print(item["e"])
print(item["chengjiao"])
print(item["jiaoe"])
print(item["zhenfu"])
print(item["max"])
print(item["min"])
print(item["today"])
print(item["ye"])
print()
self.count += 1
self.cursor.execute(
"insert into stocks (序号,代码,名称,最新价格,涨跌额,涨跌幅,成交量,成交额,振幅,最高,最低,今开,昨收) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",(item["number"],item["daima"], item["name"], item["new"], item["zangfu"], item["e"],item["chengjiao"], item["jiaoe"], item["zhenfu"], item["max"], item["min"], item["today"], item["ye"]))
print("__________________________________________________________________________________")
except Exception as err:
print(err)
return item
配置settings.py
ITEM_PIPELINES = {
'stocks.pipelines.StocksPipeline': 300,
}
输出信息
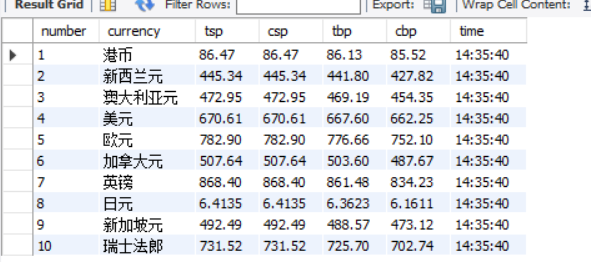
(2)、心得体会
同第一题,出现了'utf-8' codec can't decode byte 0xd5 in position 248: invalid continuation byte的问题,改robots.txt里robotstxt_body = robotstxt_body.decode('gbk')即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号