第三次作业
作业①
(1)、要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网( http://www.weather.com.cn )。分别使用单线程和多线程的方式爬取。
单线程:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
def imageSpider(start_url):
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"html.parser")
images = soup.select("img")
for image in images:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
print(url)
download(url)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url):
global count
try:
count=count+1
#提取文件后缀扩展名
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
fobj=open("E:\\wangluopachong_3\\images\\"+str(count)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded "+str(count)+ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count=0
imageSpider(start_url)
输出信息
多线程:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
def imageSpider(start_url):
global threads
global count
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup = BeautifulSoup(data, "html.parser")
images = soup.select("img")
for image in images:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
print(url)
count = count + 1
T = threading.Thread(target=download, args=(url, count))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err: print(err)
def download(url,count):
try:
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
fobj=open("E:\\wangluopachong_3\\images_2\\"+str(count)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded "+str(count)+ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre)\
Gecko/2008072421 Minefield/3.0.2pre"}
count=0
threads=[]
imageSpider(start_url)
for t in threads:
t.join()
print("The End")
输出信息
(2)、心得体会:
用多线程加高了效率和可靠性
作业②
(1)、要求:使用scrapy框架复现作业①。
爬取的代码
编写爬虫程序
import scrapy
from ..items import TianqiItem
class MySpider(scrapy.spiders.Spider):
name="MySpider"#定义爬虫名
allowed_domains=["weather.com"] #搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页
start_urls=["http://www.weather.com.cn/"]
#该函数名不能改变,因为Scrapy源码中默认callback函数的函数名就是parse
def parse(self, response):
href_list = response.xpath('//@src').extract()
for src in href_list:
item = TianqiItem()
item['image_url']=[src]
yield item
编写数据项目类
import scrapy
class TianqiItem(scrapy.Item):
# define the fields for your item here like:
image_url=scrapy.Field()
配置settings
ITEM_PIPELINES = {
# 'tianqi_scrapy.pipelines.TianqiScrapyPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline':1
}
IMAGES_STORE='E:\wangluopachong_3\images_scrapy'
IMAGES_URLS_FIELD='image_url'
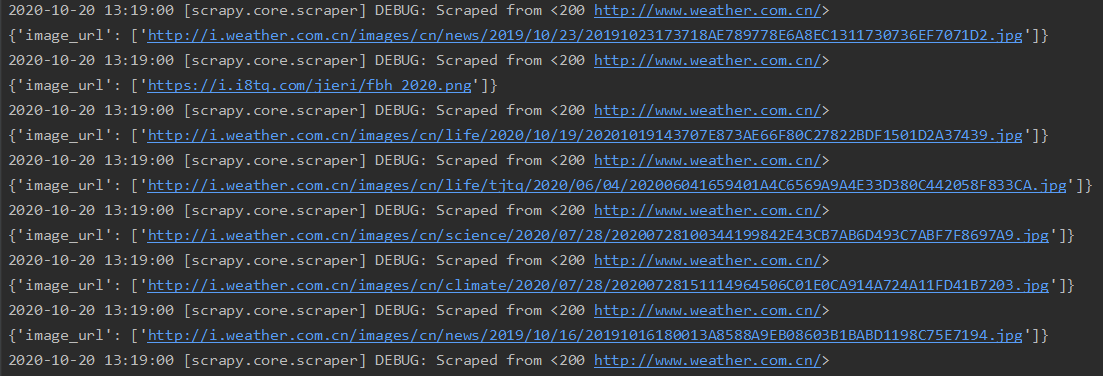
输出信息
(2)、心得体会:
初步了解了scrapy框架,在编写过程中对setting.py,MySpider.py,items.py,pipelines.py这四个不同文件的作用与如何编写掌握更加深刻,也体会到了scrapy功能的强大
作业③
(1)、要求:使用scrapy框架爬取股票相关信息。
编写爬虫程序
import json
import scrapy
from ..items import gupiaoItem
class gupiao(scrapy.Spider):
name = 'gupiao'
start_urls = ["http://82.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112404444853921220622_1603172260738&pn=1&pz=20&po=1&np=1&"
"ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields="
"f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1603172260739"]
def parse(self, response):
data = json.loads(response.text.lstrip('jQuery112404444853921220622_1603172260738(').rstrip(');'))#去除头部json杂质
for i in data['data']['diff']:
item = gupiaoItem()
item["daima"] = i['f12']
item["name"] = i['f14']
item["new"] = i['f2']
item["zangfu"] =i['f3']
item["e"] = i['f4']
item["chengjiao"] = i['f5']
item["jiaoe"]=i['f6']
item["zhenfu"] = i['f7']
item["max"] =i['f15']
item["min"] = i['f16']
item["today"] = i['f17']
item["ye"] = i['f18']
yield item
print("finish!!!")
编写数据项目类
import scrapy
class gupiaoItem(scrapy.Item):
# define the fields for your item here like:
daima = scrapy.Field()
name = scrapy.Field()
new = scrapy.Field()
zangfu = scrapy.Field()
e = scrapy.Field()
chengjiao = scrapy.Field()
jiaoe = scrapy.Field()
zhenfu = scrapy.Field()
max = scrapy.Field()
min = scrapy.Field()
today = scrapy.Field()
ye = scrapy.Field()
pass
编写数据管道处理类
import csv
class ScrapyGupiaoPipeline(object):
with open('gu.csv', 'a', encoding='utf-8', newline='')as file:
writer = csv.writer(file)
writer.writerow(["代码", "名称", "最新价格", "涨跌额", "涨跌幅", "成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收"])
def process_item(self, item, spider):
with open('gu.csv', 'a', encoding='utf-8', newline='')as file:
writer = csv.writer(file)
writer.writerow([item["daima"], item["name"], item["new"], item["zangfu"], item["e"],
item["chengjiao"], item["jiaoe"], item["zhenfu"], item["max"], item["min"], item["today"], item["ye"]])
return item
配置setting
ITEM_PIPELINES = {
'demo.pipelines.ScrapyGupiaoPipeline': 300,
}
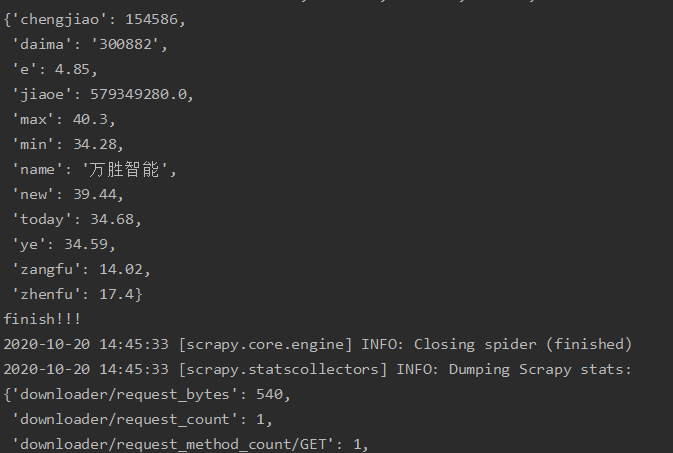
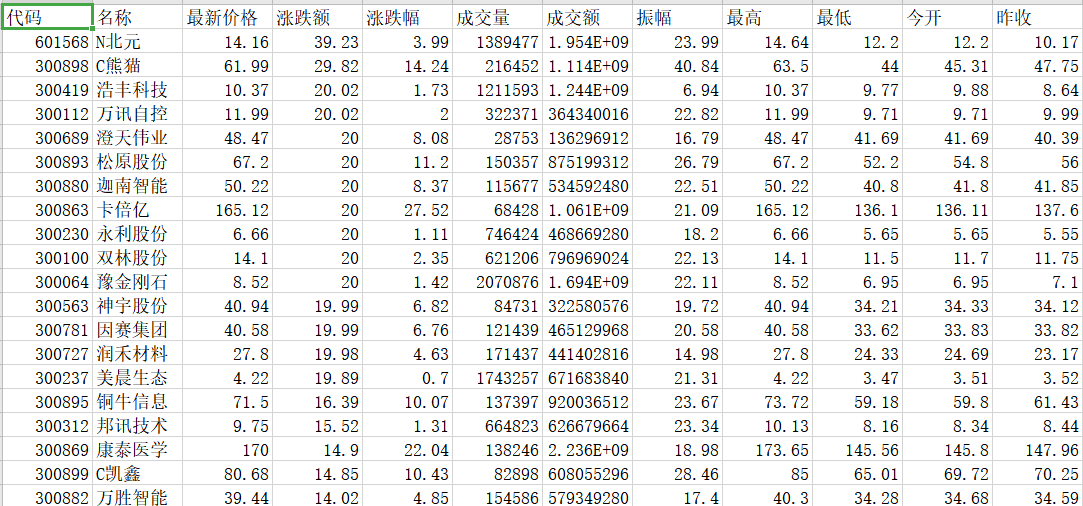
输出信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号