作业①
from bs4 import BeautifulSoup
import urllib.request
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
html = urllib.request.urlopen(url) #打开url网址
html = html.read() #读取网站内容
html = html.decode() #二进制数据html转为字符串
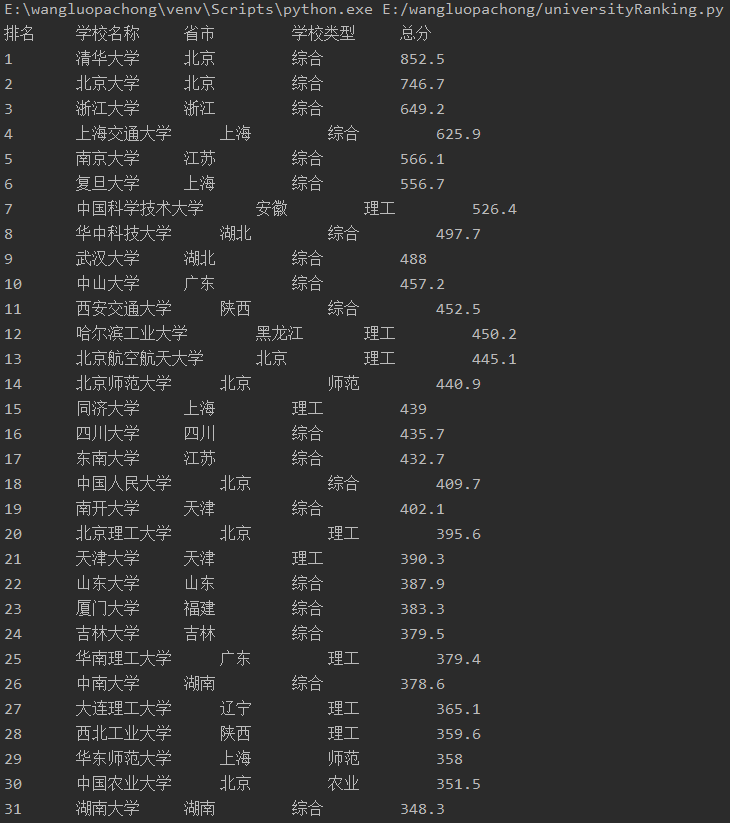
print("排名\t学校名称\t\t省市\t\t学校类型\t\t总分")
soup = BeautifulSoup(html, "html.parser")
trs = soup.select("tbody tr") #查找文档中<tbody>结点下所有<tr>结点
for tr in trs:
element = tr.find_all("td") #查找所有<td>元素
print(element[0].text.strip()+"\t\t"+element[1].text.strip()+"\t\t"+element[2].text.strip()+"\t\t"+element[3].text.strip()+"\t\t"+element[4].text.strip())
输出信息
(2)、心得体会
写的第一个爬虫代码,现在看起来蛮简单的但是写了好久。刚开始find和select会搞混。爬虫其实就是找到特定标签里的内容,结合网页F12键显示html编码,再根据标签树形结构找到相应标签。
作业②
(1)、要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
# 爬取的代码
import requests
from bs4 import BeautifulSoup
url =" https://list.jd.com/list.html?cat=737 ,794,798"
prices = []
titles = []
hd = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
r = requests.get(url,headers=hd,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding #把获取到的页面信息 替换成utf-8信息,这样就不会乱码
html = r.text
soup = BeautifulSoup(html, "html.parser")
lis= soup.find_all("li",attrs={"class":"gl-item"})
# 在<li>标签下寻找商品名和价格
for li in lis:
title = li.find("div", attrs={"class":"p-name"}).find("em")
titles.append(title.text.strip()) #把爬取到的商品加入商品列表
price = li.find("div", attrs={"class":"p-price"}).find("strong")
prices.append(price.text.strip()) #把爬取到的价格加入价格列表
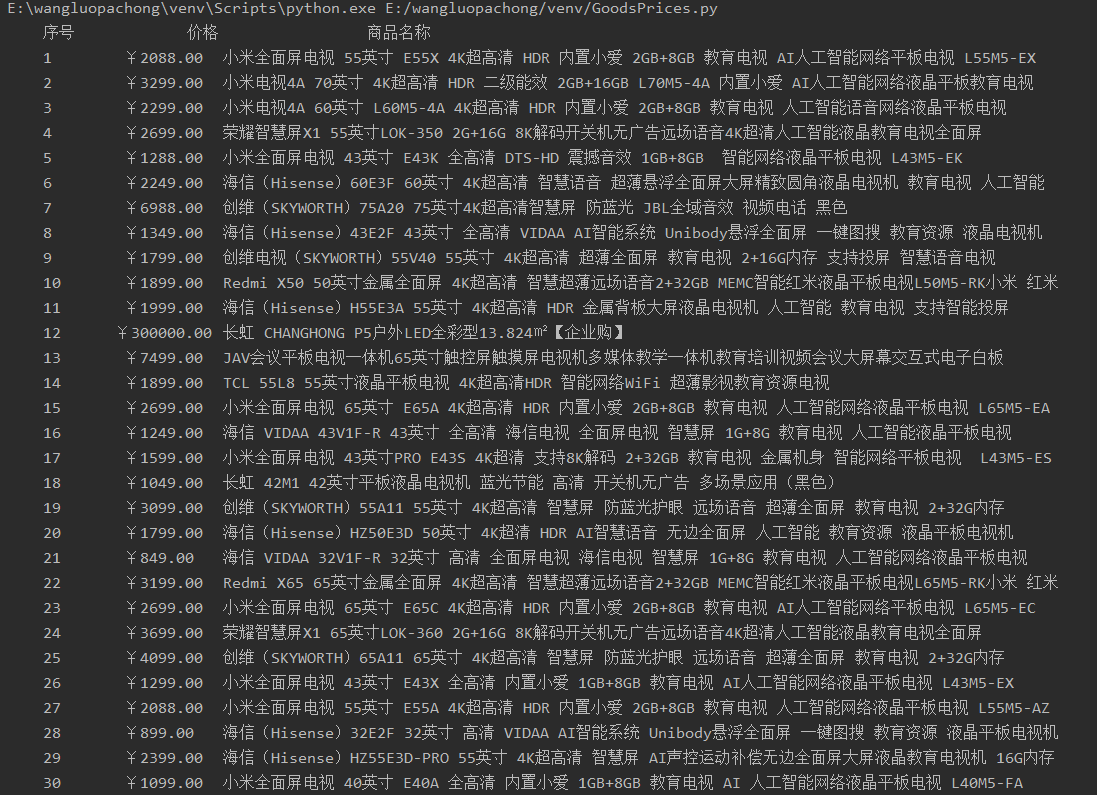
tplt = "{:^10}\t{:^10}\t{:^20}" # 设定一个print模板,用大括号{}来定义槽函数
print(tplt.format("序号", "价格","商品名称"))
count=0
for i in range(len(titles)):
count = count + 1
print(tplt.format(count,prices[i],titles[i]))
输出信息
(2)、心得体会
刚开始爬取的是淘宝的页面,但是因为淘宝反爬虫机制所以改用京东。因为用正则表达式有点复杂所以选择了对我来说比较轻松的find方法。感觉对爬虫的掌握熟悉了一些,但是很多时候还是会有一种无从下手的感觉,所以一定要多加练习。
作业③
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
#爬取网址上的图片
def imageSpider(start_url):
try:
urls = []
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "html.parser")
images = soup.select("img")
for image in images:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
print(url)
download(url)
except Exception as err:
print(err)
except Exception as err:
print(err)
# 下载图像文件
def download(url):
global count
try:
count = count + 1
if url[len(url) - 4] == ".":
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("E:\\images\\" + str(count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded" + str(count) + ext)
except Exception as err:
print(err)
start_url = "http://xcb.fzu.edu.cn/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count = 0
imageSpider(start_url)
输出信息

(2)、心得体会
是根据书上的代码改编的。爬取图片首先要找到图片的url(被爬取网页的url加上具体内容),然后再下载图像文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号