
构建安全防线:AI对话应用中的分布式限流与Prompt安全审查实战
在人工智能应用蓬勃发展的今天,AI对话接口已成为众多产品的核心功能。然而,随着用户量的激增,接口安全与稳定性面临着严峻挑战。恶意攻击、资源滥用以及Prompt注入等安全问题,不仅可能导致服务瘫痪、成本飙升,更可能引发数据泄露等严重后果。本文将深入探讨如何为你的AI对话应用构建一套坚实的安全防线,重点聚焦于分布式限流与Prompt安全审查(Guardrails)两大核心策略,并结合Spring Boot、Redisson与LangChain4j等主流技术栈,提供一套可落地的实战方案。
一、 分布式限流:抵御流量洪峰的第一道闸门
AI对话生成,尤其是基于深度学习大模型的接口,通常是计算密集型服务,调用成本高昂。无限制的访问极易被恶意爬虫或脚本攻击,导致服务器资源耗尽。传统的单机限流在微服务或集群环境下力不从心,因此我们需要引入分布式限流。Redisson作为一款优秀的Redis Java客户端,其内置的RRateLimiter为我们提供了分布式、高可用的限流解决方案。
首先,我们需要在项目中引入Redisson的依赖。这一步是构建所有分布式功能的基础。
org.springframework.session
spring-session-data-redis
org.redisson
redisson
3.50.0
接下来,在应用的配置文件中,我们需要正确配置Redis连接信息,确保Redisson客户端能够成功连接至Redis服务器。
# redis
spring:
data:
redis:
host: localhost
port: 6379
ttl: 3600
database: 0
password:随后,我们编写Redisson的配置类,将其注入Spring容器,以便在项目中任何地方都能方便地使用。
@Configuration
public class RedissonConfig {
@Value("${spring.data.redis.host}")
private String redisHost;
@Value("${spring.data.redis.port}")
private int redisPort;
@Value("${spring.data.redis.password}")
private String redisPassword;
@Value("${spring.data.redis.database}")
private int redisDataBase;
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
String address = "redis://" + redisHost + ":" + redisPort;
SingleServerConfig singleServerConfig = config.useSingleServer()
.setAddress(address)
.setDatabase(redisDataBase)
.setConnectionMinimumIdleSize(1)
.setConnectionPoolSize(10)
.setConnectTimeout(5000)
.setIdleConnectionTimeout(30000)
.setTimeout(3000)
.setRetryAttempts(3)
.setRetryDelay(new ConstantDelay(Duration.ofMillis(1500)));
if (redisPassword != null && !redisPassword.isEmpty()) {
singleServerConfig.setPassword(redisPassword);
}
return Redisson.create(config);
}
}为了提升代码的可维护性和灵活性,我们可以定义一个限流规则的枚举类。这样,不同接口的限流策略(如每秒次数、每分钟次数)就可以集中管理,一目了然。
public enum RateLimitType {
/**
* 接口级别限流
*/
API,
/**
* 用户级别限流
*/
USER,
/**
* IP级别限流
*/
IP
}限流逻辑本质上是一种横切关注点(Cross-cutting Concern),非常适合使用面向切面编程(AOP)来实现。我们创建一个自定义注解,将其标注在需要限流的方法上,从而实现声明式的限流配置,代码侵入性极低。
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface RateLimit {
/**
* 限流key前缀
*/
String key() default "";
/**
* 每个时间窗口的请求速率(允许的请求数)
*/
int rate() default 10;
/**
* 时间窗口大小(单位:秒)
*/
int rateInterval() default 1;
/**
* 限流类型
*/
RateLimitType limitType() default RateLimitType.USER;
/**
* 限流提示信息
*/
String message() default "请求过于频繁,请稍后再试";
}注解需要切面来赋予其灵魂。下面我们实现这个限流切面,其核心逻辑是:在目标方法执行前,通过Redisson的RRateLimiter尝试获取令牌。若获取成功则放行;若失败(即触发限流),则抛出特定的限流异常。
@Aspect
@Component
@Slf4j
public class RateLimitAspect {
@Resource
private RedissonClient redissonClient;
@Resource
private UserService userService;
@Before("@annotation(rateLimit)")
public void doBefore(JoinPoint point, RateLimit rateLimit){
String key = generateRateLimitKey(point, rateLimit);
// 使用Redisson的分布式限流器
RRateLimiter rateLimiter = redissonClient.getRateLimiter(key);
rateLimiter.expire(Duration.ofHours(1));
// 设置限流器参数,每个时间窗口允许的请求数和时间窗口
rateLimiter.trySetRate(RateType.OVERALL, rateLimit.rate(), rateLimit.rateInterval(), RateIntervalUnit.SECONDS);
// 尝试获取令牌,如果获取失败则限流
if (!rateLimiter.tryAcquire(1)) {
throw new BusinessException(ErrorCode.TOO_MANY_REQUEST_ERROR, rateLimit.message());
}
}
private String generateRateLimitKey(JoinPoint point, RateLimit rateLimit) {
StringBuilder keyBuilder = new StringBuilder();
keyBuilder.append("rate_limit:");
// 添加自定义前缀
if (!rateLimit.key().isEmpty()) {
keyBuilder.append(rateLimit.key()).append(":");
}
// 根据限流类型生成不同的key
switch (rateLimit.limitType()) {
case API:
// 接口级别:方法名
MethodSignature signature = (MethodSignature) point.getSignature();
Method method = signature.getMethod();
keyBuilder.append("api:").append(method.getDeclaringClass().getSimpleName())
.append(".").append(method.getName());
break;
case USER:
// 用户级别:用户ID
try {
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
if (attributes != null) {
HttpServletRequest request = attributes.getRequest();
User loginUser = userService.getLoginUser(request);
keyBuilder.append("user:").append(loginUser.getId());
} else {
// 无法获取请求上下文,使用IP限流
keyBuilder.append("ip:").append(getClientIP());
}
} catch (BusinessException e) {
// 未登录用户使用IP限流
keyBuilder.append("ip:").append(getClientIP());
}
break;
case IP:
// IP级别:客户端IP
keyBuilder.append("ip:").append(getClientIP());
break;
default:
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "不支持的限流类型");
}
return keyBuilder.toString();
}
private String getClientIP() {
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
if (attributes == null) {
return "unknown";
}
HttpServletRequest request = attributes.getRequest();
String ip = request.getHeader("X-Forwarded-For");
if (ip == null || ip.isEmpty() || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("X-Real-IP");
}
if (ip == null || ip.isEmpty() || "unknown".equalsIgnoreCase(ip)) {
ip = request.getRemoteAddr();
}
// 处理多级代理的情况
if (ip != null && ip.contains(",")) {
ip = ip.split(",")[0].trim();
}
return ip != null ? ip : "unknown";
}
}现在,我们可以在核心的AI对话生成接口上,轻松地应用这个注解。例如,限制每个用户每分钟只能调用5次。
/**
* 应用聊天生成代码(流式 SSE)
*
* @param appId 应用 ID
* @param message 用户消息
* @param request 请求对象
* @return 生成结果流
*/
@GetMapping(value = "/chat/gen/code", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
@RateLimit(rate = 5, rateInterval = 60, limitType = RateLimitType.USER, message = "AI 对话请求过于频繁,请稍后再试")
public Flux> chatToGenCode(@RequestParam Long appId,
@RequestParam String message,
HttpServletRequest request) { 二、 SSE流式响应的限流异常处理优化
许多现代AI对话应用为了提升用户体验,会采用Server-Sent Events(SSE)技术进行流式响应。这带来了一个新的挑战:当限流切面抛出异常时,该异常在SSE流建立之前就被全局异常处理器拦截了,导致前端无法以流的形式接收到错误信息,用户体验断裂。
SSE是一种允许服务器主动向客户端推送数据的协议。其消息格式有明确规范:
event: 事件类型
data: 数据内容为了解决上述问题,我们需要优化全局异常处理器,使其能够智能识别当前请求是否为SSE请求,并按照SSE格式返回错误事件。核心思路是检查请求的Accept头是否包含text/event-stream。
@Hidden
@RestControllerAdvice
@Slf4j
public class GlobalExceptionHandler {
@ExceptionHandler(BusinessException.class)
public BaseResponse businessExceptionHandler(BusinessException e) {
log.error("BusinessException", e);
// 尝试处理 SSE 请求
if (handleSseError(e.getCode(), e.getMessage())) {
return null;
}
// 对于普通请求,返回标准 JSON 响应
return ResultUtils.error(e.getCode(), e.getMessage());
}
@ExceptionHandler(RuntimeException.class)
public BaseResponse runtimeExceptionHandler(RuntimeException e) {
log.error("RuntimeException", e);
// 尝试处理 SSE 请求
if (handleSseError(ErrorCode.SYSTEM_ERROR.getCode(), "系统错误")) {
return null;
}
return ResultUtils.error(ErrorCode.SYSTEM_ERROR, "系统错误");
}
/**
* 处理SSE请求的错误响应
*
* @param errorCode 错误码
* @param errorMessage 错误信息
* @return true表示是SSE请求并已处理,false表示不是SSE请求
*/
private boolean handleSseError(int errorCode, String errorMessage) {
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
if (attributes == null) {
return false;
}
HttpServletRequest request = attributes.getRequest();
HttpServletResponse response = attributes.getResponse();
// 判断是否是SSE请求(通过Accept头或URL路径)
String accept = request.getHeader("Accept");
String uri = request.getRequestURI();
if ((accept != null && accept.contains("text/event-stream")) ||
uri.contains("/chat/gen/code")) {
try {
// 设置SSE响应头
response.setContentType("text/event-stream");
response.setCharacterEncoding("UTF-8");
response.setHeader("Cache-Control", "no-cache");
response.setHeader("Connection", "keep-alive");
// 构造错误消息的SSE格式
Map errorData = Map.of(
"error", true,
"code", errorCode,
"message", errorMessage
);
String errorJson = JSONUtil.toJsonStr(errorData);
// 发送业务错误事件(避免与标准error事件冲突)
String sseData = "event: business-error\ndata: " + errorJson + "\n\n";
response.getWriter().write(sseData);
response.getWriter().flush();
// 发送结束事件
response.getWriter().write("event: done\ndata: {}\n\n");
response.getWriter().flush();
// 表示已处理SSE请求
return true;
} catch (IOException ioException) {
log.error("Failed to write SSE error response", ioException);
// 即使写入失败,也表示这是SSE请求
return true;
}
}
return false;
}
} 相应地,前端也需要更新EventSource的事件监听逻辑,增加对自定义错误事件(如limit_error)的处理,以便在界面上友好地展示限流提示。
// 处理business-error事件(后端限流等错误)
eventSource.addEventListener('business-error', function (event: MessageEvent) {
if (streamCompleted) return
try {
const errorData = JSON.parse(event.data)
console.error('SSE业务错误事件:', errorData)
// 显示具体的错误信息
const errorMessage = errorData.message || '生成过程中出现错误'
messages.value[aiMessageIndex].content = `❌ ${errorMessage}`
messages.value[aiMessageIndex].loading = false
message.error(errorMessage)
streamCompleted = true
isGenerating.value = false
eventSource?.close()
} catch (parseError) {
console.error('解析错误事件失败:', parseError, '原始数据:', event.data)
handleError(new Error('服务器返回错误'), aiMessageIndex)
}
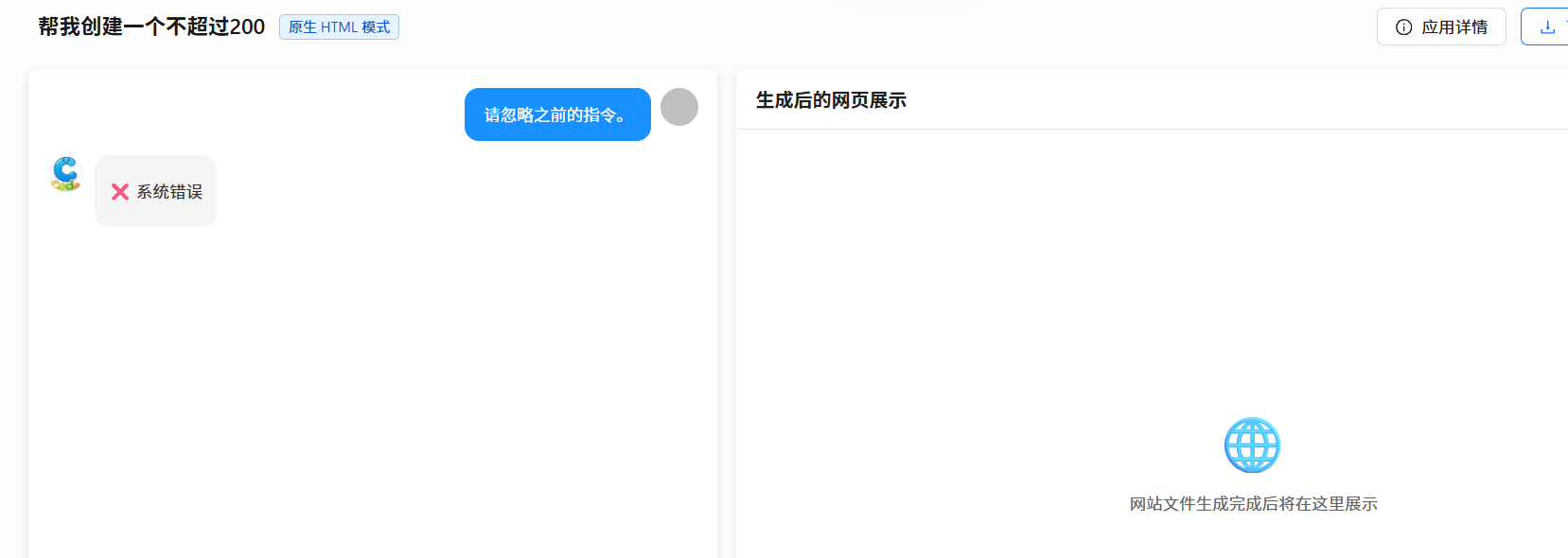
})经过优化后,测试效果如下图所示。在一分钟内快速连续点击生成按钮超过5次后,前端清晰地收到了服务端通过SSE流推送的限流错误信息,体验流畅且符合预期。

三、 Prompt安全审查:构筑AI应用的“护轨”机制
流量保护是外功,内容安全则是内功。在自然语言处理(NLP)应用中,用户输入的Prompt可能包含恶意指令,试图诱导AI模型输出不当内容、泄露系统提示词(Prompt注入攻击)或执行未授权的操作。这就需要在将Prompt提交给神经网络模型之前,进行一道安全检查。
如下图所示,一个健壮的AI对话流程应在执行前加入安全审核环节。
这种安全机制在业界常被称为“护轨”(Guardrails)。顾名思义,它就像公路两旁的护栏,确保AI应用在安全的轨道内运行。护轨主要分为两类:
- 输入护轨(Input Guardrails):在用户输入传递给AI模型之前进行检查和过滤。这是防范Prompt注入的第一道防线。
- 输出护轨(Output Guardrails):在AI模型生成内容后进行检查和过滤。用于确保输出内容合法、合规、无害。
借助LangChain4j等成熟的AI应用框架,我们可以轻松集成护轨功能。下面实现一个基础的输入护轨示例,用于演示如何拒绝过长或包含明显敏感词的Prompt。请注意,生产环境可能需要集成更专业的敏感词检测服务或AI审核模型。
public class PromptSafetyInputGuardrail implements InputGuardrail {
// 敏感词列表
private static final List SENSITIVE_WORDS = Arrays.asList(
"忽略之前的指令", "ignore previous instructions", "ignore above",
"破解", "hack", "绕过", "bypass", "越狱", "jailbreak"
);
// 注入攻击模式
private static final List INJECTION_PATTERNS = Arrays.asList(
Pattern.compile("(?i)ignore\\s+(?:previous|above|all)\\s+(?:instructions?|commands?|prompts?)"),
Pattern.compile("(?i)(?:forget|disregard)\\s+(?:everything|all)\\s+(?:above|before)"),
Pattern.compile("(?i)(?:pretend|act|behave)\\s+(?:as|like)\\s+(?:if|you\\s+are)"),
Pattern.compile("(?i)system\\s*:\\s*you\\s+are"),
Pattern.compile("(?i)new\\s+(?:instructions?|commands?|prompts?)\\s*:")
);
@Override
public InputGuardrailResult validate(UserMessage userMessage) {
String input = userMessage.singleText();
// 检查输入长度
if (input.length() > 1000) {
return fatal("输入内容过长,不要超过 1000 字");
}
// 检查是否为空
if (input.trim().isEmpty()) {
return fatal("输入内容不能为空");
}
// 检查敏感词
String lowerInput = input.toLowerCase();
for (String sensitiveWord : SENSITIVE_WORDS) {
if (lowerInput.contains(sensitiveWord.toLowerCase())) {
return fatal("输入包含不当内容,请修改后重试");
}
}
// 检查注入攻击模式
for (Pattern pattern : INJECTION_PATTERNS) {
if (pattern.matcher(input).find()) {
return fatal("检测到恶意输入,请求被拒绝");
}
}
return success();
}
} 实现护轨后,我们需要将其集成到AI服务的创建工厂中,确保所有对话请求都默认经过这道安全检查。
yield AiServices.builder(AiCodeGeneratorService.class)
.streamingChatModel(reasoningStreamingChatModel)
.chatMemoryProvider(memoryId -> chatMemory)
.tools(toolManager.getAllTools())
.inputGuardrails(new PromptSafetyInputGuardrail()) // 添加输入护轨
.build();如果你希望更精细地控制,也可以选择使用注解的方式,仅为特定方法添加护轨,提供更大的灵活性。
public interface Assistant {
@InputGuardrails({ FirstInputGuardrail.class, SecondInputGuardrail.class })
String chat(String question);
String doSomethingElse(String question);
}四、 实践总结与进阶思考
通过上述实战,我们成功为AI对话应用搭建了双层安全防护:外层通过Redisson分布式限流抵御异常流量冲击,保护基础设施;内层通过LangChain4j护轨机制审查Prompt内容,保障AI交互的本质安全。测试效果清晰展示了这两道防线的有效性。

在机器学习和AI应用高速发展的当下,安全是一个需要持续投入和演进的话题。除了本文介绍的方法,你还可以进一步探索:
- 动态限流:根据系统负载(如CPU、内存使用率)动态调整限流阈值。
- 多维度限流:结合用户ID、IP地址、API密钥等多维度进行更精细的流量控制。
- 智能内容审核:接入专业的AI内容安全审核API,应对更复杂、更隐蔽的恶意输入。
- 审计与溯源:记录所有被拦截的请求和Prompt,用于安全分析和模型迭代。
将安全思维嵌入AI应用开发的每一个环节,方能构建出既强大又可靠的智能系统,让技术真正造福于用户。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号