
Ollama v0.16.3 深度解析:从模型底座到AI代理生态的全面进化
在本地大模型工具领域,Ollama 一直以其轻量化和易用性著称。近日发布的 v0.16.3 版本,标志着它从一个单纯的模型运行器,向一个综合性AI工具生态底座迈出了关键一步。本次更新不仅带来了对Gemma 3、Llama 3、Qwen 3等前沿架构的支持,更深度集成了Cline等智能编码代理,同时在性能、安全与交互体验上进行了全方位优化。对于使用 Python、Go 或 JavaScript/TypeScript 栈的开发者而言,这些改进意味着更高效、更强大的本地AI开发体验。
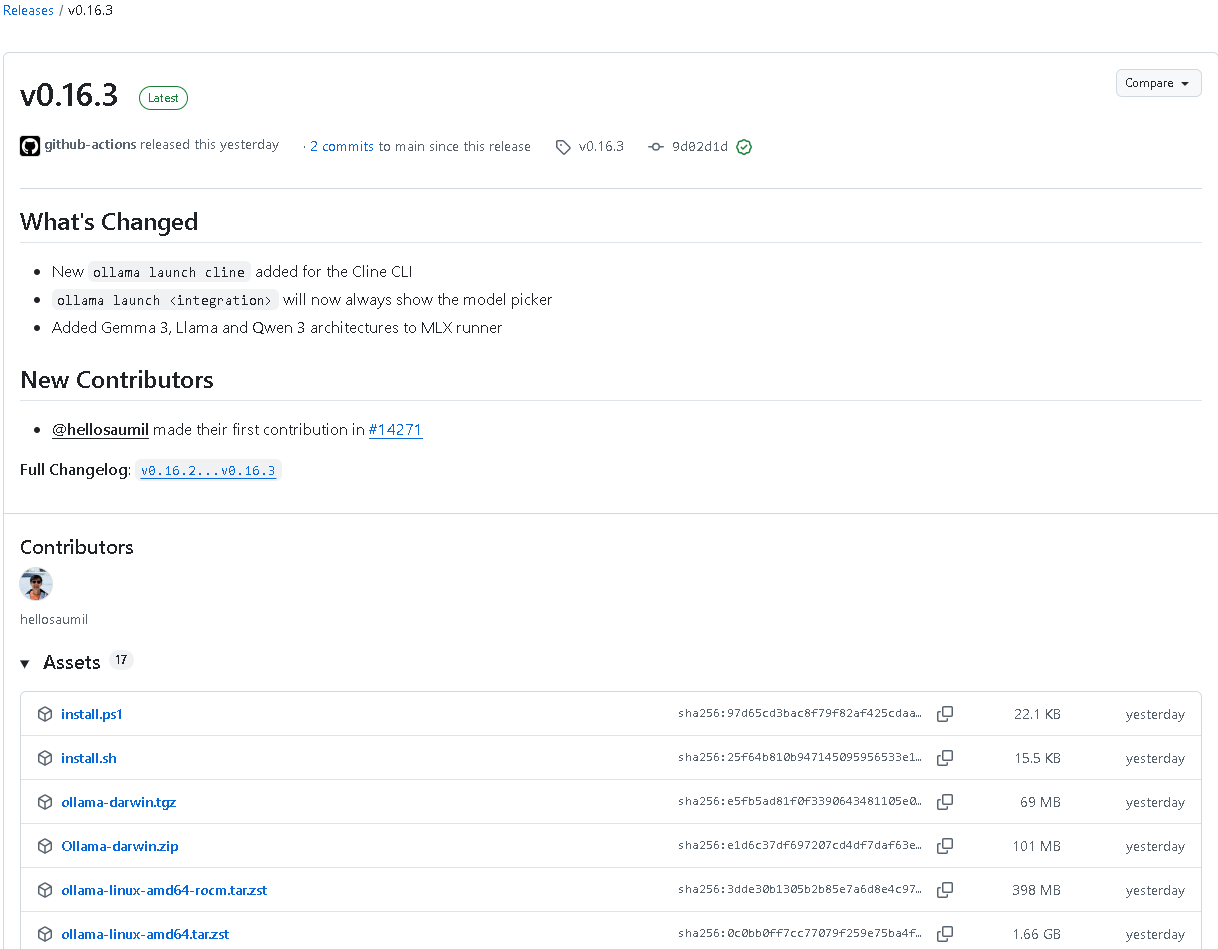
一、版本核心亮点:生态集成与模型扩展
Ollama v0.16.3 是一次覆盖广泛的全栈式更新。其核心亮点可以概括为两大方向:向外扩展生态集成,向内深化模型支持。
- 生态集成:正式引入对 Cline(自适应自主编码代理)的一键集成支持,并新增了 Pi 集成的官方文档。
- 模型架构:MLX Runner 新增对 Gemma 3、Llama 3 和 Qwen 3 三大主流架构的原生支持。
- 性能与安全:服务器端新增 Zstd 压缩解码支持以提升性能,安装脚本加入安全包装防止部分下载风险。
- 交互体验:命令行(CLI)和文本交互界面(TUI)全面重构,模型管理更加直观流畅。
这些更新共同指向一个目标:让 Ollama 成为连接各类AI模型与上层应用(如编码助手、智能代理)的核心枢纽。
二、重磅集成:无缝对接Cline智能编码代理
本次更新最引人注目的特性是深度集成 Cline。Cline 是一个具备多线程与并行执行能力的自主编码代理,而 Ollama 现在成为了其默认的模型后端。通过一个简单的命令即可完成绑定:
ollama launch cline集成过程实现了高度自动化:
- 自动检测与安装:命令会检查本地 Cline CLI (
npm install -g cline) 是否存在,缺失时提示安装。 - 配置自动化:系统会自动在 Cline 的配置文件 (
globalState.json) 中写入 Ollama 配置,如下所示:
{
"ollamaBaseUrl": "http://localhost:11434",
"actModeApiProvider": "ollama",
"planModeApiProvider": "ollama",
"actModeOllamaModelId": "kimi-k2.5:cloud",
"planModeOllamaModelId": "kimi-k2.5:cloud"
}这意味着 Cline 的“执行”与“规划”模式都将由 Ollama 托管的模型驱动。此外,GetCurrentModel 方法 (Cline.Models()) 能同步 Ollama 中的当前模型,实现生态内的模型状态统一。对于 Java 或 Go 后端开发者,这种开箱即用的代理集成能极大简化构建AI辅助开发工具的流程。[AFFILIATE_SLOT_1]
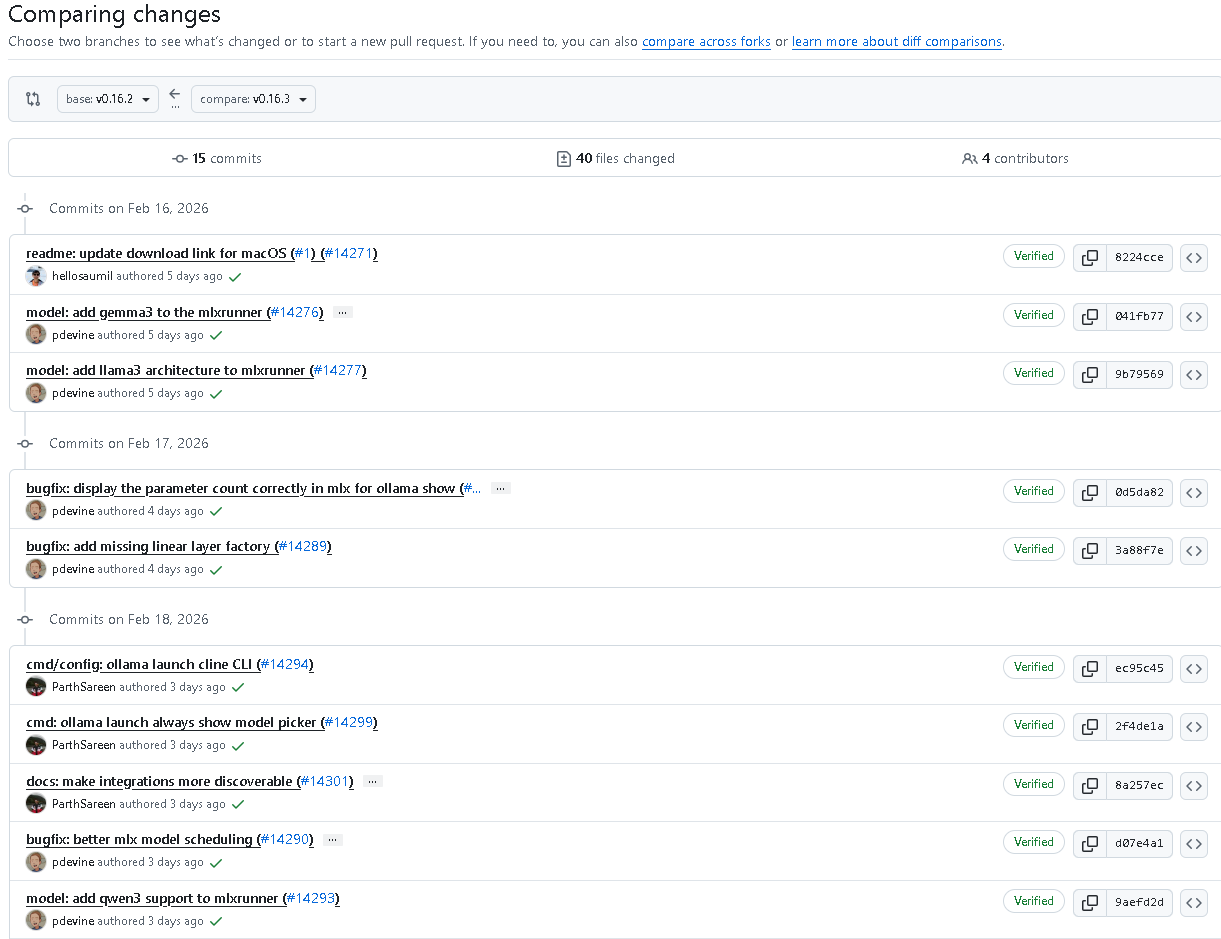
三、架构支持升级:拥抱Llama 3、Qwen 3与Gemma 3
为紧跟开源模型的发展步伐,v0.16.3 的 MLX Runner 新增了对三大新架构的支持。这不仅仅是添加名称,而是实现了深度的解析器集成。
在 server/mlx/parser.go (model/parsers/parsers.go) 中,新增了对应的解析函数,例如针对 Qwen 3 的解析器:
case "qwen3":
p = &Qwen3Parser{hasThinkingSupport: false, defaultThinking: false}
case "qwen3-thinking":
p = &Qwen3Parser{hasThinkingSupport: true, defaultThinking: true}
case "qwen3-coder":
p = &Qwen3CoderParser{}Qwen3Parser 的设计尤为精细,它能够:
- 解析思考链:准确提取模型内部的思考过程 (
<think>)。 - 识别工具调用:自动识别并结构化模型输出的工具调用JSON (
<tool_call>)。 - 处理流式输出:通过精心设计的状态机 (
),精确还原被拆分的流式响应内容。CollectingThinking → CollectingContent → CollectingToolContent → Done
这种底层解析能力的增强,确保了开发者在使用 Python 或 JavaScript 调用这些新模型时,能获得稳定、结构化的输出,为构建复杂AI应用奠定了基础。
四、交互体验革新:更智能的CLI与TUI
Ollama 一直重视命令行体验,v0.16.3 在这方面做了显著优化。首先,ollama run 命令 (ollama launch) 的行为被调整:无论是否设置默认模型,都会强制显示模型选择器,有效防止误操作。
关键的代码修改如下:
cmd: ollama launch always show model picker (#14299)其次,文本交互界面(TUI)经历了近乎重构的升级:
- 单选/多选模式:默认单选,按 Tab 键可切换多选模式,便于批量操作。
- 智能光标:
jumpToSelection函数 (cursorForCurrent()) 支持模糊匹配,能智能跳转到相似名称的模型项。 - 界面优化:默认模型用“默认”标签 (
(default)) 高亮,选择框动态渲染,列表按优先级排序。
这些改进让管理数十个模型的体验变得轻松,无论是 TypeScript 全栈开发者还是专注于数据科学的 Python 用户,都能高效地进行模型切换和测试。
五、性能与安全加固:Zstd压缩与安装防护
在服务器性能层面,v0.16.3 新增了对 Zstd (Zstandard) 压缩算法的支持。当客户端请求头中包含 Content-Encoding: zstd (Content-Encoding: zstd) 时,服务器中间件能自动识别并解压,显著降低网络传输开销,提升请求处理速度。
核心实现位于中间件中:
if c.GetHeader("Content-Encoding") == "zstd" {
reader, err := zstd.NewReader(c.Request.Body, zstd.WithDecoderMaxMemory(8<<20))
...
} 安全设计:解压内存被限制在8MB以内,有效防御潜在的DoS攻击。解压失败会安全地返回 BadRequest (400 Bad Request)。
⚠️ 另一方面,安装脚本的安全性也得到了加强。在 scripts/install.sh 中增加了安全包装:
# Wrap script in main function so that a truncated partial download doesn't end
# up executing half a script.
main() {
...
}
main这避免了脚本在下载不完整时被执行的风险,体现了 Ollama 对生产环境稳定性的重视。[AFFILIATE_SLOT_2]
六、生态完善与未来展望
除了 Cline,本次更新还正式将 Pi 集成纳入官方文档 (docs/integrations/pi.mdx),提供了清晰的配置指引。开发者可以通过 pip install pi (npm) 安装后,轻松将其后端配置为 Ollama。
配置示例:
ollama launch pi此外,版本还修复了多项底层问题,如 MLX 参数显示错误、调度逻辑优化,并更新了 Go 模块依赖 (github.com/klauspost/compress v1.18.3),确保了整个框架的健壮性。
总结
Ollama v0.16.3 是一次意义重大的迭代。它超越了单纯的版本更新,通过深度集成 Cline、支持最新模型架构、革新用户交互、加固安全性能,清晰地勾勒出其向“AI工具生态统一底座”进化的路线图。对于开发者而言,无论是想快速搭建一个本地的代码助手,还是需要为复杂的 Java 或 Go 微服务注入AI能力,这个版本都提供了更强大、更便捷的基础设施。随着生态的不断丰富,Ollama 正成为连接开源大模型与真实世界应用不可或缺的桥梁。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号