
告别环境地狱与检索高墙:用 uv 与 pyseekdb 构建极简高效的 RAG 开发流水线
在AI应用开发,尤其是RAG(检索增强生成)项目快速迭代的今天,开发者面临的挑战已从算法设计转向了工程落地。如何让团队协作丝滑顺畅,如何让数据检索与存储成本可控,成为决定项目成败的关键。本文将为你介绍一套黄金组合:uv 与 pyseekdb,它们分别从环境管理和检索存储两端入手,旨在将RAG项目的启动与协作成本降至最低。
一、AI开发者的新基建:从算法到工程
过去,AI团队的核心战场是模型算法。然而,随着大模型生态的成熟,工程侧的“摩擦力”日益凸显。这主要体现在两个方面:
- 环境依赖的“地狱”:一个典型的RAG项目依赖栈可能包括 PyTorch、Transformers、LangChain、LlamaIndex 等。团队成员使用不同的操作系统(Windows, macOS, Linux)、不同的包管理器(pip, conda),甚至不同的Python版本,导致“在我机器上能跑”成为常态。这种环境不一致性严重拖慢了CI/CD流程和团队协作效率。
- 数据检索的“高墙”:从原始文本到可检索的知识库,需要经过分块、向量化、索引构建、查询优化等一系列步骤。选择和维护一个高性能、易用的向量数据库,并集成到应用流程中,本身就有不小的学习和部署成本。
因此,现代AI开发者需要的不再是单一的强大工具,而是一套能打通从环境到数据全链路的“基建”方案。这正是 uv 与 pyseekdb 组合的价值所在。
二、uv:重塑Python开发工作流的“快刀”
什么是 uv?简单说,它是一个用Rust编写的、极速的Python包管理器和项目工作流工具。它的目标不是增加功能,而是通过极致的速度和严格的一致性,来优化和简化整个Python项目管理流程。
在Python生态中,我们拥有众多优秀的语言如 Go 的简洁、JavaScript/TypeScript 的活跃生态、C++ 的性能,但Python在包管理和环境隔离上一直存在痛点。uv 的出现,正是为了彻底解决这些问题:
- 统一工作流:它用一个命令行工具替代了以往需要 pip, virtualenv/venv, pip-tools 等多个工具组合才能完成的工作。项目初始化、依赖安装、虚拟环境管理、锁版本、运行脚本,全部收敛。
- 锁死一致性:uv 围绕
pyproject.toml管理依赖声明,并用uv.lock文件锁定所有依赖包及其递归依赖的确切版本。这确保了在任何机器、任何时间,uv sync都能还原出完全一致的环境。 - 闪电速度:得益于Rust的高性能实现,uv 在依赖解析和包安装速度上远超传统工具,为开发者节省大量等待时间。
它的核心命令非常简单:uv init 创建项目,uv add 添加依赖,uv sync 同步环境,uv run 执行脚本。这种设计哲学让团队协作和项目复现变得前所未有的简单。
三、pyseekdb:面向应用的轻量级检索引擎SDK
如果说 uv 解决了“环境怎么搭”的问题,那么 pyseekdb 则致力于解决“数据怎么存和查”的问题。它是一个面向 pip+venv 与 OceanBase AI Search 的Python SDK,其设计理念是让开发者能以最小的代价,为应用集成强大的检索能力。
与直接操作底层向量索引库(如 Faiss)相比,pyseekdb 提供了更高层级的抽象:
- 以集合(Collection)为中心:数据组织和检索逻辑都围绕 Collection 进行,更符合应用开发者的思维模型。
- 开箱即用的混合检索:支持向量检索、全文检索以及两者的混合检索(Hybrid Search),无需开发者手动拼接和调权。
- 灵活的部署模式:这是其一大亮点。
- 嵌入式模式:数据以文件形式持久化在本地指定路径。无需启动任何外部服务,适合本地开发、测试、Demo验证以及轻量级应用部署。这极大地降低了入门和实验门槛。
- 远程模式:连接至远程的 seekdb 服务或 OceanBase 集群,用于生产环境,满足高并发和分布式需求。
这种设计使得开发者可以先用嵌入式模式快速完成原型开发和功能验证,待业务规模增长后,几乎无需修改代码即可平滑迁移至远程集群模式。
四、强强联合:为什么 pyseekdb 需要 uv?
你可能会问,pyseekdb 本身似乎并不复杂,为何特别需要 uv?关键在于依赖组合与协作场景。
在实际的RAG项目中,pyseekdb 很少单独使用。它通常会与 LangChain、LlamaIndex、Dify 等框架,以及各种Embedding模型、LLM调用库组合,形成一个复杂的依赖图。此时,环境管理问题便会指数级放大。
uv 在这里扮演了“稳定器”和“加速器”的角色:
- 锁定复杂依赖:通过
uv.lock文件,确保整个复杂的依赖栈(包括 pyseekdb 及其间接依赖)被精确锁定。无论是分享给同事,还是在CI服务器上构建,都能100%复现。 - 简化协作流程:你只需要在项目中提供
pyproject.toml和uv.lock文件。协作者只需执行uv sync,即可一键获得完全相同的环境,彻底告别“依赖冲突”的噩梦。 - 赋能快速演示:pyseekdb 的嵌入式特性意味着整个知识库可以包含在项目目录中。配合 uv 的轻量、可复现环境,你可以将整个可运行的RAG Demo(包括环境配置、数据、代码)打包,对方在几分钟内就能看到效果,极大提升了技术传播和方案验证的效率。
这种组合,让开发者能真正专注于RAG的应用逻辑本身,而非纠缠于环境配置和数据基础设施的搭建。
五、实战:5分钟构建你的本地RAG知识库
让我们通过一个实际例子,感受一下 uv + pyseekdb 的便捷性。我们将基于 pyseekdb 官方Demo,在本地快速构建一个具备图形界面的RAG问答系统。
前置准备:确保系统已安装 Python 3.11+ 和 uv。准备一个LLM API Key(如OpenAI或国内大模型)用于最终答案生成。
步骤1:一键准备环境
首先,使用 uv 创建并同步项目环境。以下命令会处理所有依赖:
git clone https://github.com/oceanbase/pyseekdb.git
cd demo/rag
uv sync如果你的项目需要使用本地模型(例如 sentence-transformers),则需要额外安装相关依赖:
uv sync --extra local步骤2:简易配置
在项目根目录创建 .env 文件进行配置。对于首次体验,建议使用默认的Embedding模型,无需额外API Key:
cp .env.example .env这里的关键配置是 EMBEDDING_TYPE:
default:使用内置的ONNX模型,自动下载,最适合快速验证流程。api:使用OpenAI等在线Embedding服务,需配置EMBEDDING_*等相关信息。local:使用本地模型,需配置SENTENCE_TRANSFORMERS_*并确保已安装--extra local等依赖。
我们选择 default 以继续:
EMBEDDING_FUNCTION_TYPE=default
OPENAI_API_KEY=sk-your-key
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_MODEL_NAME=qwen-plus
SEEKDB_DIR=./data/seekdb_rag
SEEKDB_NAME=test
COLLECTION_NAME=embeddings步骤3:导入你的知识文档
现在,可以将你的文档导入并构建为可检索的知识库。导入单个文件:
uv run python seekdb_insert.py ../../README.md执行后,你将看到类似下面的输出,显示文档分块和导入的进度:
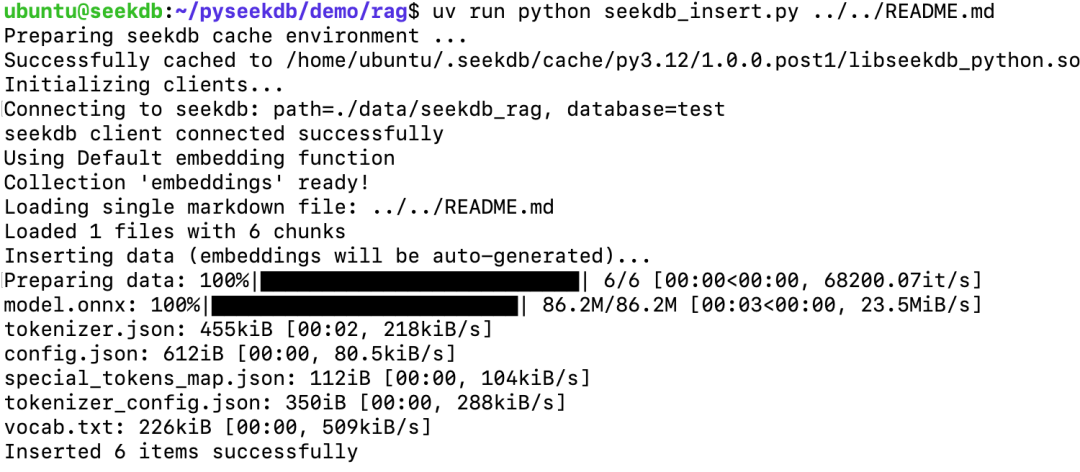
你也可以导入整个目录下的所有文档:
uv run python seekdb_insert.py path/to/your_dir所有数据将被向量化并持久化存储在你指定的 SEEKDB_DIR 目录中。
步骤4:启动交互界面并提问
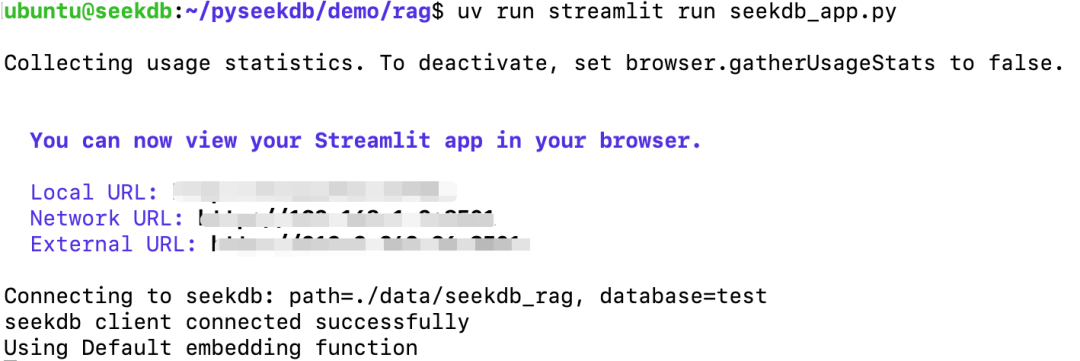
最后,启动内置的Web UI界面:
uv run streamlit run seekdb_app.py成功启动后,终端会提示访问地址:
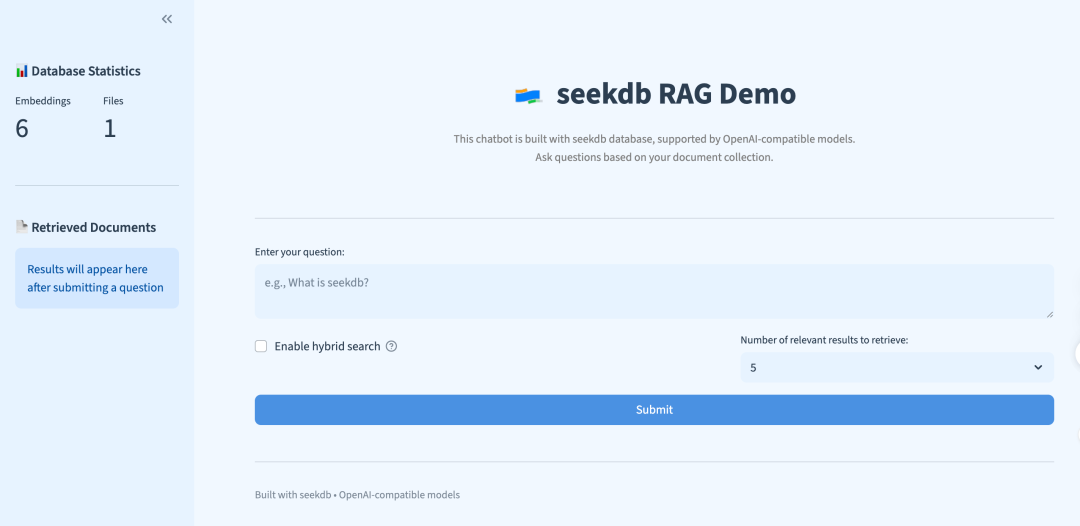
打开浏览器,你就能看到一个简洁的问答界面。输入问题后,系统会:1)从本地知识库中检索出相关文本片段;2)结合你配置在 .env 中的LLM,生成最终答案并展示。
至此,一个功能完整的本地RAG应用就在几分钟内搭建完毕,全程无需关心复杂的依赖冲突或数据库服务部署。
[AFFILIATE_SLOT_2]六、总结:回归高效开发的本质
在AI应用开发日益工程化的今天,选择正确的工具链就是最重要的生产力决策之一。**uv 与 pyseekdb 的组合,为我们提供了一种“极简主义”的高效开发范式**:
- uv 通过极致的速度和铁一般的环境一致性,消除了团队协作和项目交付中最大的摩擦点——环境依赖,让开发者能像使用 Go 或 Rust 的工具链那样高效、可靠地管理Python项目。
- pyseekdb 则通过嵌入式与远程一体化的设计,以及面向应用的高层API,大幅降低了为应用集成检索能力的门槛和初期成本。它让开发者能像使用本地SQLite一样轻松地开始使用向量检索。
将两者结合,你获得的是一条从“零环境”到“可检索知识库”再到“交互式应用”的快速通道。这套方案特别适合创业团队快速原型验证、个人开发者学习探索、以及企业内部分享和演示技术方案。它让我们能够更专注于AI应用本身要解决的实际问题,而非浪费精力在繁琐的工程细节上。这,或许就是工具进化的真正意义。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号