
从分类到推理:基于Qwen3-VL与LLaMA-Factory的人脸情绪识别多模态实战
人脸情绪识别(FER)作为计算机视觉与情感计算交叉领域的热点,正从实验室走向广阔的应用场景。然而,传统基于CNN的模型在真实复杂环境下面临严峻挑战。本文将深入探讨如何利用多模态大语言模型(MLLM)的语义理解与推理能力,通过Qwen3-VL与LLaMA-Factory框架,将传统分类任务重构为多模态推理任务,从而显著提升模型的鲁棒性与准确率。
一、传统方法的局限与多模态的破局之道
长期以来,人脸情绪识别主要依赖于卷积神经网络(CNN)及其轻量化变体。这类模型在FER-2013、CK+等标准数据集上能取得优异表现,其本质是将输入的人脸图像映射到离散的情绪标签(如高兴、悲伤、愤怒等),是一个典型的封闭集分类问题。
然而,现实世界远非实验室般理想。光照的剧烈变化、部分面部遮挡、非正面拍摄角度、微妙的微表情以及个体表达差异,都让依赖单一像素级视觉特征的模型捉襟见肘。模型的泛化能力成为瓶颈。这类似于在编程中,一个只在特定输入下工作的函数(比如用Python写的硬编码逻辑),一旦遇到边界情况就容易崩溃。
多模态大语言模型(MLLM)的兴起带来了全新的思路。以Qwen3-VL为代表的模型,不仅具备强大的视觉编码能力,更融合了深度的语言理解与生成能力。它将图像和文本投射到统一的语义空间,使得模型能够进行“看-想-说”的连贯推理。这意味着,情绪识别不再仅仅是“这张脸像高兴”,而是可以结合场景上下文、面部肌肉运动的语义描述(如“嘴角上扬,眼角出现皱纹”)进行综合判断,极大地增强了模型的解释性和鲁棒性。

二、核心思路:任务重构与模型微调
本项目的核心在于两个关键转变:数据格式的重构与模型能力的定向微调。
1. 从“图像-标签”到“图像-指令-答案”
FER-2013数据集原始格式是(图像, 分类标签)。为了适配MLLM,我们必须将其转化为多模态问答格式。这个过程可以借助一个简单的脚本完成(想象一下用JavaScript处理JSON数据或Go处理结构化数据一样)。重构后的每条数据样本包含:
- 图像:人脸图片。
- 指令(Instruction):一个描述任务的文本提示,例如:“请分析这张图中人物的面部表情,判断其情绪状态。”
- 答案(Output):对应的情绪标签,如“高兴”。
这种重构本质上是将分类任务转换为了视觉问答(VQA)任务,迫使模型调用其语言理解能力来“推理”出答案,而非单纯进行模式匹配。

2. 高效微调:利用LLaMA-Factory释放模型潜力
预训练的Qwen3-VL是一个通用模型,并非专精于情绪识别。我们需要在其强大的基础能力上进行针对性微调。LLaMA-Factory框架为此提供了极大便利。它集成了多种高效微调技术(如LoRA、QLoRA),能大幅降低显存消耗,使得在单张消费级GPU上进行大模型微调成为可能。其配置化、模块化的设计,让开发者能像调用Java库一样,快速搭建训练流程,专注于任务本身而非工程细节。
三、实战演练:一步步实现微调与评估
下面我们概述在Lab4AI平台上的关键操作步骤。整个流程清晰明了,即便是初学者也能跟随完成。
Step1:环境准备与项目启动
在平台中找到对应项目“LLaMA-Factory微调Qwen3-VL进行人脸情感识别”并启动。建议选择至少1卡GPU资源,预计需要数小时完成训练。
Step2:激活运行环境
根据项目文档指引,在终端中激活预设的Python环境。这通常只需执行一条简单的命令,确保所有依赖库就位。
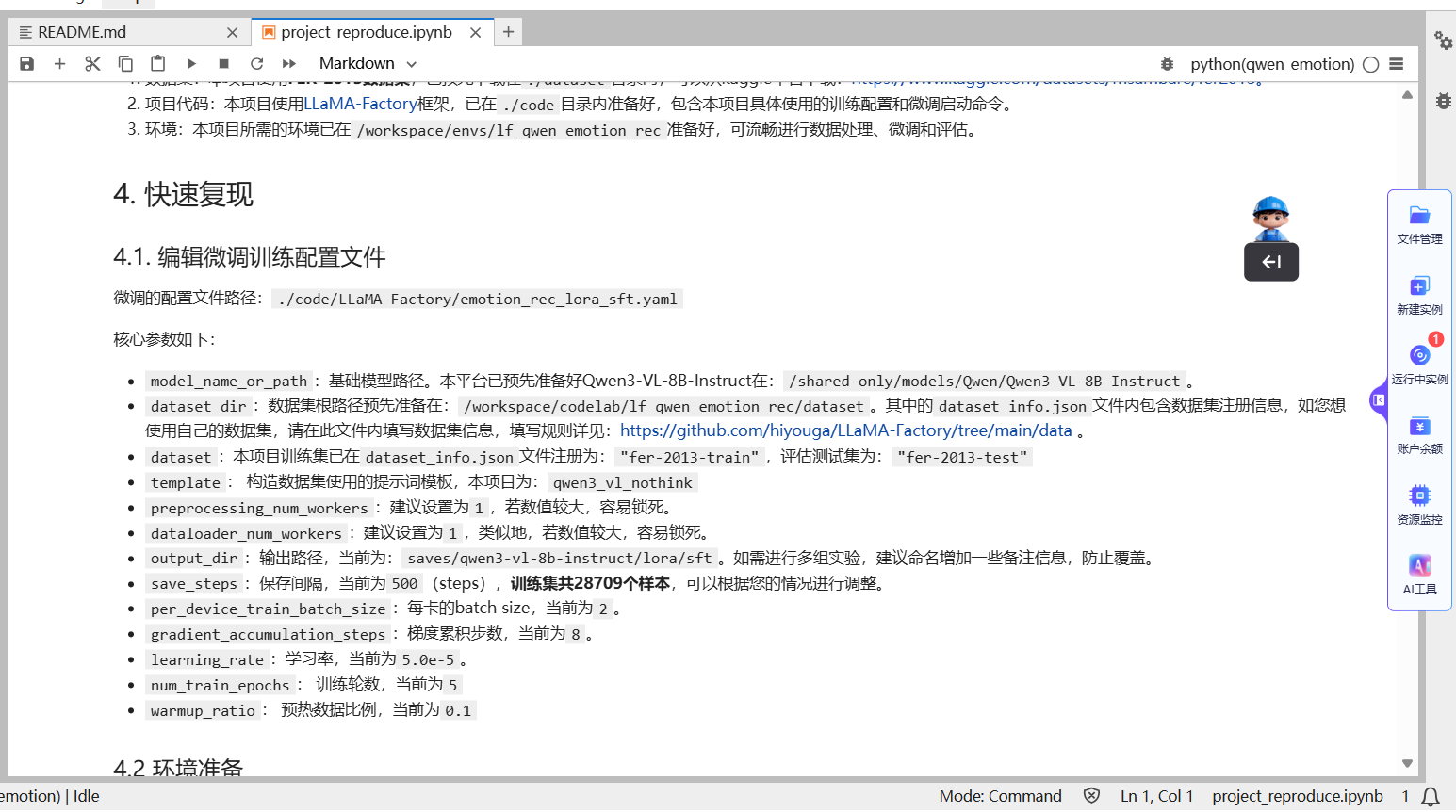
Step3:执行微调训练
运行训练脚本。LLaMA-Factory会自动加载我们预处理好的FER-2013数据,并开始对Qwen3-VL模型进行微调。你可以通过日志观察损失(Loss)值的下降情况。
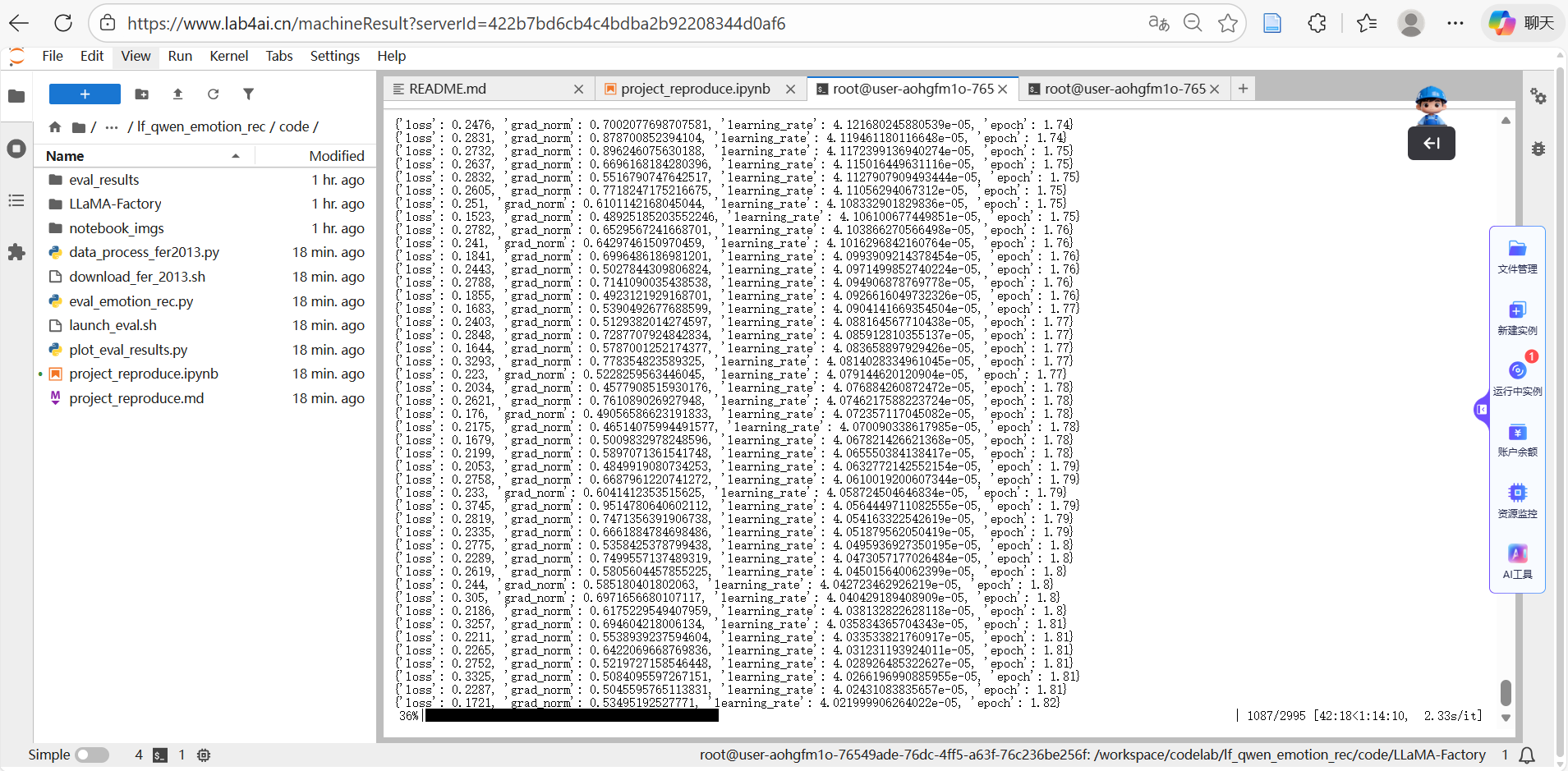
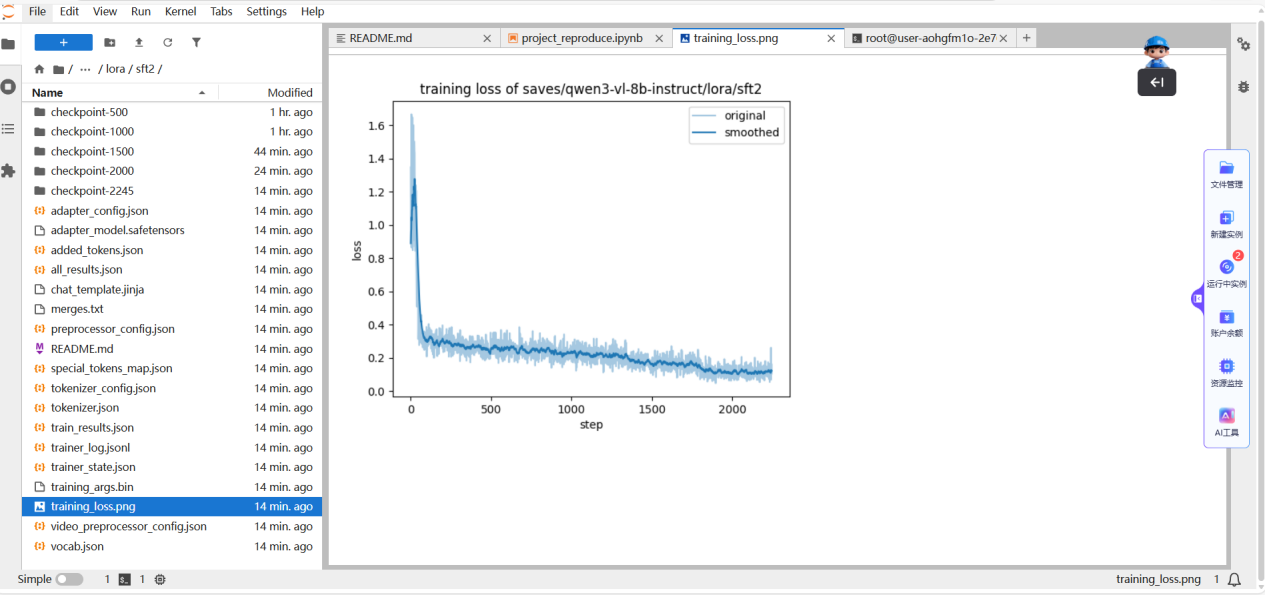
训练结束后,会在指定目录生成模型检查点(Checkpoints)和训练记录。查看损失曲线是分析训练过程是否正常的关键。
Step4:模型性能评估与可视化
训练不是终点,评估才是检验效果的标尺。运行项目提供的评估脚本,它会在测试集上计算微调后模型的准确率。
更直观的是,项目提供了可视化工具,可以绘制不同检查点对应的准确率变化曲线,帮助我们确定最佳模型。
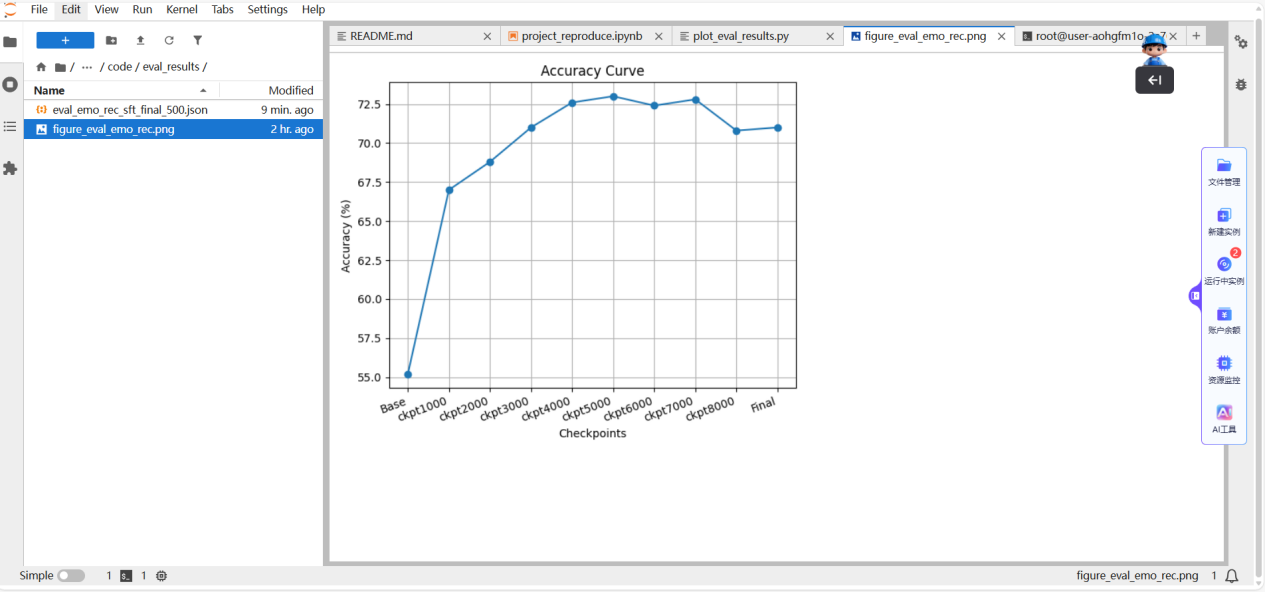
性能提升分析
根据实验结果,微调后的Qwen3-VL在FER-2013测试集上的准确率从基线模型的约55.2%提升至73%,绝对提升幅度达到17.8个百分点。这有力地证明了多模态推理路径的有效性。如果你熟悉传统CV模型,这个提升幅度是相当可观的,相当于对某个C++算法进行了一次关键优化。
四、延伸思考与最佳实践建议
本次实战为我们打开了思路,但仍有优化空间:
- 提示词工程:指令(Instruction)的设计直接影响模型表现。尝试更详细、更具引导性的提示词,如“请重点关注人物的眼睛、嘴巴和眉毛形态,综合判断其情绪”,可能带来进一步增益。
- 数据增强:尽管FER-2013是经典数据集,但数据量有限。可以考虑使用合成数据或结合其他FER数据集进行混合训练,以提升模型多样性。
- 超参数调优:学习率、训练轮数、LoRA秩等超参数对结果有细微影响。可以像网格搜索优化
Python机器学习模型那样,进行小范围调优。 - 模型量化与部署:训练后的模型可以使用LLaMA-Factory或其它工具进行量化(如INT4),大幅降低推理所需资源,为实际部署到端侧或边缘设备创造条件。
⚠️ 注意事项:情绪识别涉及伦理隐私。任何实际应用都必须严格遵守数据隐私法规,获得用户知情同意,并避免用于不道德的监控与评判。
[AFFILIATE_SLOT_2]五、总结与展望
本项目成功演示了利用Qwen3-VL和LLaMA-Factory框架,将传统人脸情绪分类任务革新为多模态推理任务的完整流程。通过数据重构和高效微调,我们不仅显著提升了模型在标准数据集上的性能,更重要的是为模型注入了语义理解和推理能力,这对其在真实复杂场景中的鲁棒性至关重要。
这套方法论的价值远不止于情绪识别。它为我们处理其他复杂视觉任务(如场景理解、细粒度图像分类、视觉推理)提供了可复用的范式:即通过多模态提示,将传统感知任务升级为感知与认知结合的任务。随着多模态模型能力的持续进化,其与高效微调工具的结合,必将催生出更多智能化、人性化的应用。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号