
告别AI“金鱼记忆”:Claude-Mem如何为编程助手装上长期记忆系统
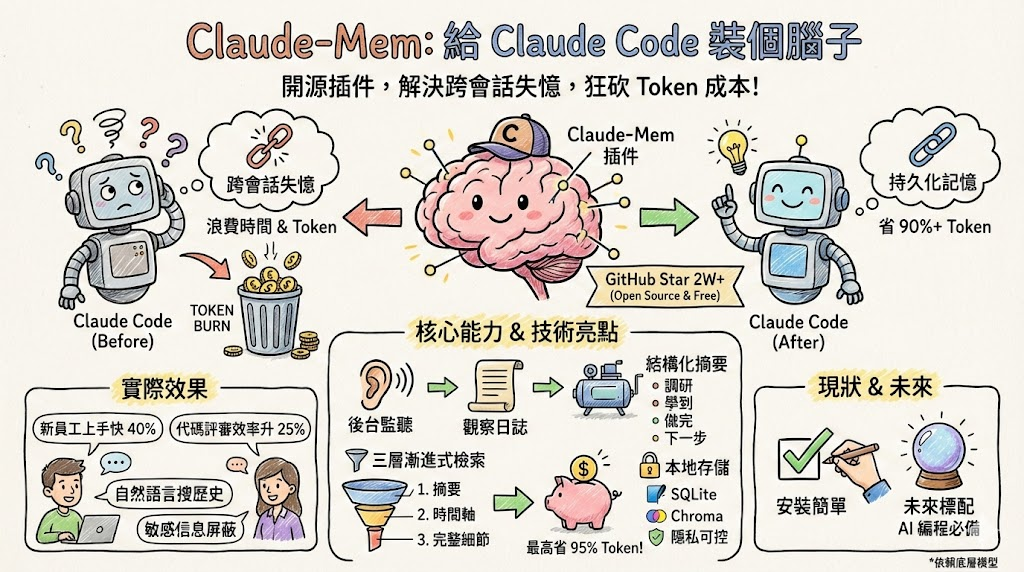
你是否厌倦了每次与AI编程助手对话,都像在教一个失忆的新人?Claude-Mem的出现,正试图解决这一核心痛点。这个开源项目通过创新的“三层渐进式披露”架构,为Claude Code注入了跨会话的长期记忆能力,将AI从“短期对话伙伴”升级为理解项目历史的“资深同事”。本文将深入解析其工作原理、工程价值及实践意义。
一、AI编程的“记忆之痛”:为何短期上下文远远不够
当前主流的AI编程助手,如Claude Code,普遍存在“会话级失忆”问题。其工作模式基于大型语言模型(LLM)的上下文窗口,一旦关闭会话,所有讨论过的架构设计、决策逻辑和代码修改历史便烟消云散。这本质上是短期记忆与长期项目需求之间的根本矛盾。
开发者面临的真实困境包括:
- 重复解释成本高:跨天或跨分支工作后,需反复向AI复述项目背景。
- 决策脉络断裂:长期演进的设计选择与“为什么这么做”的推理过程无法系统保留。
- 协作效率低下:新成员无法快速获取项目的历史上下文,依赖口口相传。
GitHub上涌现的各类自建记忆方案(如memory-mcp)印证了社区对此需求的迫切性。Claude-Mem正是在此背景下,提供了一个开箱即用、本地优先的解决方案。
正如社区所热议的:
用 Claude Code 写代码的人,终于不用每次开新会话都从头解释项目背景了。
二、Claude-Mem核心架构:从碎片到结构化记忆
Claude-Mem并非简单存储聊天记录,而是构建了一套事件驱动、混合存储、智能压缩的记忆系统。其核心目标是将人机协作的“操作流水账”转化为模型可高效利用的“长期记忆索引”。
1. 隐形的事件捕获
插件通过在Claude Code的生命周期中挂载钩子,自动捕获关键开发事件,形成“观察记录”(Observations)。这包括文件改动、命令执行、工具调用结果等,整个过程对用户透明,无需改变工作流。
| 钩子 | 触发时机 | 作用 |
|---|---|---|
| SessionStart | 会话启动 | 初始化检索和上下文准备 |
| UserPromptSubmit | 用户提交问题时 | 记录用户意图和上下文 |
| PostToolUse | 工具调用完成之后 | 捕获文件读写、代码改动等 |
| Stop | 任务暂停 | 保存中间状态 |
| SessionEnd | 会话结束 | 触发总结、压缩与入库 |
2. 务实的本地混合存储
为实现灵活检索,Claude-Mem采用了组合存储策略:
- SQLite + FTS5:存储结构化元数据(时间、路径、操作类型)并支持关键词全文检索。
- Chroma向量库:将文本摘要向量化,支持语义检索,应对“上周讨论的支付策略”这类模糊查询。
所有数据均存放于用户本地目录(~/.claude-mem/
3. 关键的记忆压缩
在会话结束时,系统会调用Claude Agent SDK,将零散的观察记录压缩成一份高度结构化的摘要,通常包含:调研内容、学习成果、已完成工作、后续步骤。这避免了将原始“流水账”直接塞给模型,为后续高效检索奠定了基础。
[AFFILIATE_SLOT_1]三、灵魂设计:三层渐进式披露与Token经济学
Claude-Mem最核心的创新在于其“三层渐进式披露”(Progressive Disclosure)机制。它巧妙地解决了长期记忆与有限上下文窗口及高昂Token成本之间的矛盾。
| 层级 | 主要内容 | Token 开销(大致) | 使用场景 |
|---|---|---|---|
| 第一层:Search | 摘要级索引与概要 | 约 50–100 / 结果 | 快速定位相关历史 |
| 第二层:Timeline | 会话 / 事件时间轴 | 中等开销 | 理解前后因果 |
| 第三层:Get_Observations | 完整观察记录详情 | 约 500–1000 / 结果 | 深挖实现细节、重现过程 |
该机制的工作流程如同一个智能过滤器:
- 摘要层检索:用户提问后,先在本地检索最相关的历史会话摘要。
- 时间线层扩展:若需要更多上下文,则拉取相关时间段的事件时间线。
- 细节层调取:仅在前两层不足时,才注入具体的操作记录(如某次Git Diff的完整内容)。
这种设计带来了显著的效率提升:
- Token节省高达90-95%:避免了暴力注入全部历史。
- 工具调用上限提升约20倍:释放的Token预算可用于更复杂的工具调用链。
- 体验更“智能”:AI仿佛能记住项目脉络,而非一堆杂乱信息。
简而言之,它让AI学会了“按需回忆”,而非“全盘背诵”。
四、多场景实战:从个人项目到企业协作
Claude-Mem的价值在不同规模的开发场景中得以凸显。
企业团队场景:在复杂项目中,它充当“团队记忆库”,持续记录架构演变、缺陷修复路径和决策逻辑。有团队反馈,这使新人上手时间缩短约40%,代码评审效率提升25%,有效降低了知识传承成本。
个人开发者场景:对于长线Side Project,它如同“自动笔记助手”。开发者可以用自然语言询问:“我上次优化登录流程用了什么鉴权策略?”系统能回溯相关讨论和代码改动。通过本地Web界面(http://localhost:37777
隐私敏感行业:其“本地优先”架构天然符合数据驻留要求。同时支持标签机制,可标记敏感内容“禁止记录”,在便利与合规间取得平衡。
五、安装、对比与理性看待局限
安装过程极为简单,通常只需一行命令:
/plugin marketplace add thedotmack/claude-mem
/plugin install claude-mem重启Claude Code后即可使用,无需改变现有工作流或部署额外服务。
与其他方案相比,Claude-Mem找到了一个巧妙的平衡点:
| 方案类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 传统 RAG 系统 | 功能强大,可接多种数据源 | 部署复杂,依赖额外基础设施 | 企业内部知识库 / 大型系统 |
| 简单文件注入 | 实现容易,维护成本低 | 缺乏智能检索,容易信息过载 | 小项目、一次性任务 |
| 手动复制粘贴 | 不需要额外工具 | 非常耗时,无法扩展 | 偶发需求,临时补充上下文 |
| Claude-Mem(现状) | 本地混合存储 + 渐进式披露 | 依赖 Claude Code 生态,需调阈值 | Claude 用户,日常持续开发项目 |
然而,它并非“万能记忆药丸”,存在以下局限:
- 摘要质量依赖底层模型:复杂场景下的自动摘要可能遗漏细节,关键决策仍需人工文档辅助。
- 存在生态依赖:作为Claude Code专用插件,需跟进IDE和插件版本的兼容性。
- 需要适度调参:在复杂项目中,需调整检索阈值、注入上限等参数,以避免上下文污染。
六、工程启示:Agent时代记忆系统的雏形
Claude-Mem的实践为AI Agent和工具链的发展提供了重要借鉴:
1. 记忆必须是分层的:如同人脑的回忆机制——先想起概要,再回忆过程,最后追溯细节。这种分层设计是构建高效记忆系统的关键。
2. “本地优先+可控隐私”是硬需求:证明了在IDE集成场景下,完全基于本地数据库和向量库的方案是可行且必要的,尤其对于受监管的行业。
3. 社区生态放大模型价值:模型厂商提供开放的插件接口,社区开发者创造高价值增强功能(如Claude-Mem),最终形成繁荣的生态正循环。这启示平台方,开放与赋能社区往往比闭门造车更有效。
七、实践建议:如何用好你的AI“记忆”
若你已开始使用Claude-Mem,建议:
- 从真实项目入手:选择一个周期超过一周、有历史改动的项目进行实测,观察其减少重复解释的效果。
- 尝试“记忆检索式”提问:例如:“总结一下过去为解决API超时试过的方案。”主动测试系统的召回能力。
- (针对团队)将其纳入流程:可将Claude-Mem的使用写入团队开发规范,并约定通用的“可检索问题模板”,使其成为协作基础设施的一部分。

正如项目所揭示的:
这是一个给 Claude Code 用的本地持久化记忆插件,通过事件驱动 + 混合存储 + 三层渐进式检索,把你和 AI 一起做过的事,压成结构化“长期记忆”,在后续会话中按需注入,同时大幅减少 Token 消耗。
结语
Claude-Mem的成功不在于运用了多前沿的技术,而在于它精准地识别了真实痛点,并用扎实的工程手段给出了优雅的解决方案。它标志着AI编程助手正从“拥有强大即时推理能力的临时工”,向“具备项目历史认知与延续性工作能力的长期伙伴”演进。对于开发者、AI工程师乃至所有智能工具的设计者而言,它提供了一个关于“如何让AI记住,并在正确时间想起正确事情”的宝贵范本。未来,长期记忆能力必将成为智能体的标配,而Claude-Mem为我们拼上了第一块关键的拼图。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号